






这里写的有点抽象,所以具体的可以参照下面代码块中的注释:
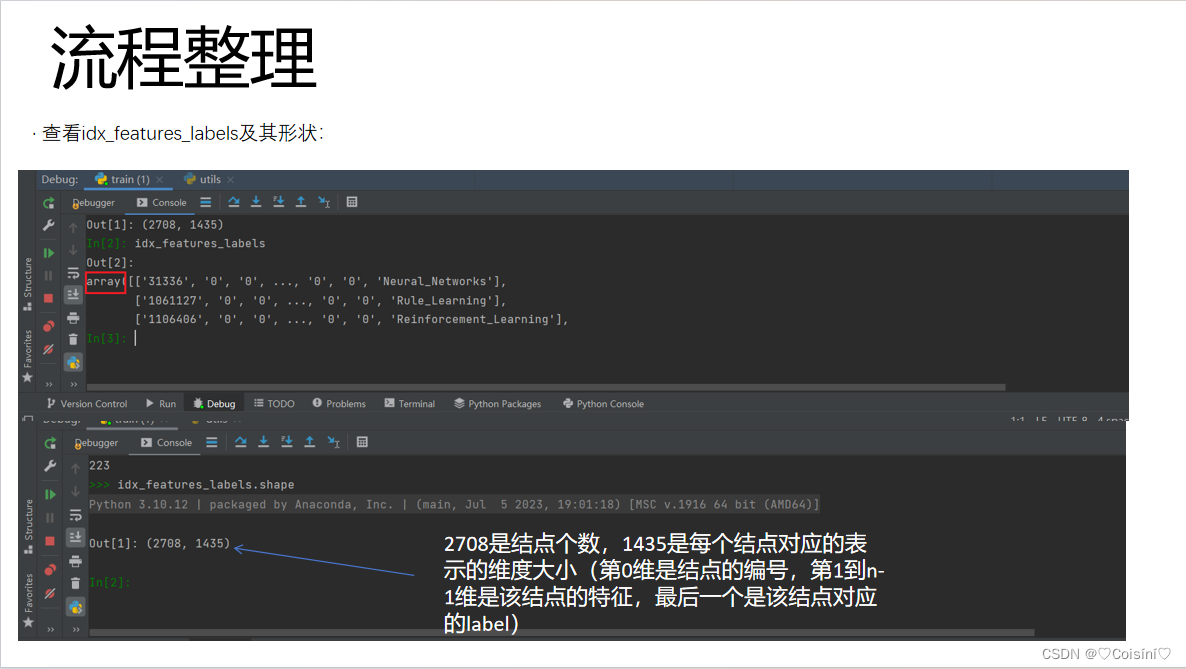
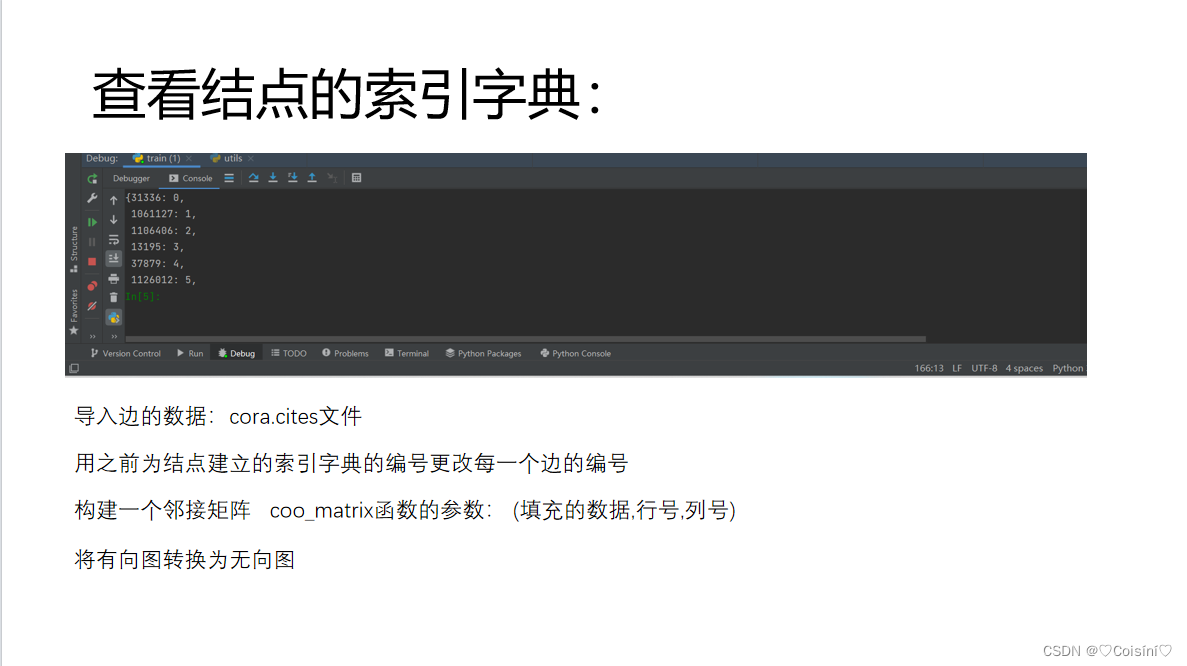
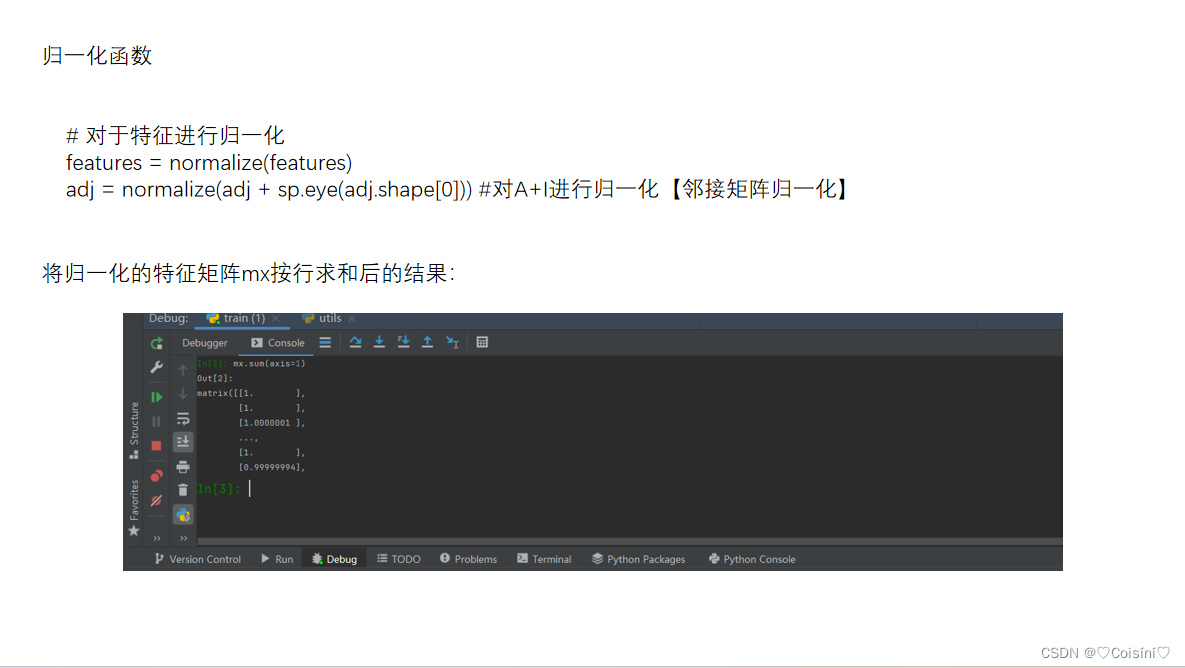
def load_data(path="../data/cora/", dataset="cora"):"""Load citation network dataset (cora only for now)"""print('Loading {} dataset...'.format(dataset))"导入cora.content"idx_features_labels = np.genfromtxt("{}{}.content".format(path, dataset),dtype=np.dtype(str))# 第1维到倒数第2维是该结点对应的特征features = sp.csr_matrix(idx_features_labels[:, 1:-1], dtype=np.float32)labels = encode_onehot(idx_features_labels[:, -1])# labels是它最后一个维度 所有结点的最后一个维度# 建立图# 取出该结点对应的索引值idx = np.array(idx_features_labels[:, 0], dtype=np.int32)# 构造结点的索引字典---》利用索引值重新构造图idx_map = {j: i for i, j in enumerate(idx)}# 导入边的数据edges_unordered = np.genfromtxt("{}{}.cites".format(path, dataset),dtype=np.int32)# 用之前为结点建立的索引字典的编号更改每一个边的编号edges = np.array(list(map(idx_map.get, edges_unordered.flatten())),dtype=np.int32).reshape(edges_unordered.shape)# 构建一个邻接矩阵 (填充的数据,行号,列号)adj = sp.coo_matrix((np.ones(edges.shape[0]), (edges[:, 0], edges[:, 1])),shape=(labels.shape[0], labels.shape[0]),dtype=np.float32)# 将有向图转换为无向图adj = adj + adj.T.multiply(adj.T > adj) - adj.multiply(adj.T > adj)# 对于特征进行归一化features = normalize(features)adj = normalize(adj + sp.eye(adj.shape[0])) #对A+I进行归一化【邻接矩阵归一化】# 划分训练集、测试集以及验证集样本idx_train = range(140)idx_val = range(200, 500)idx_test = range(500, 1500)# 将numpy的数据转换成torch中的Tensor格式features = torch.FloatTensor(np.array(features.todense()))labels = torch.LongTensor(np.where(labels)[1])adj = sparse_mx_to_torch_sparse_tensor(adj)idx_train = torch.LongTensor(idx_train)idx_val = torch.LongTensor(idx_val)idx_test = torch.LongTensor(idx_test)# 返回的结果:邻接矩阵(已经进行过归一化)、特征值、标签、训练集和测试集以及验证集对应的索引return adj, features, labels, idx_train, idx_val, idx_test
Debug部分
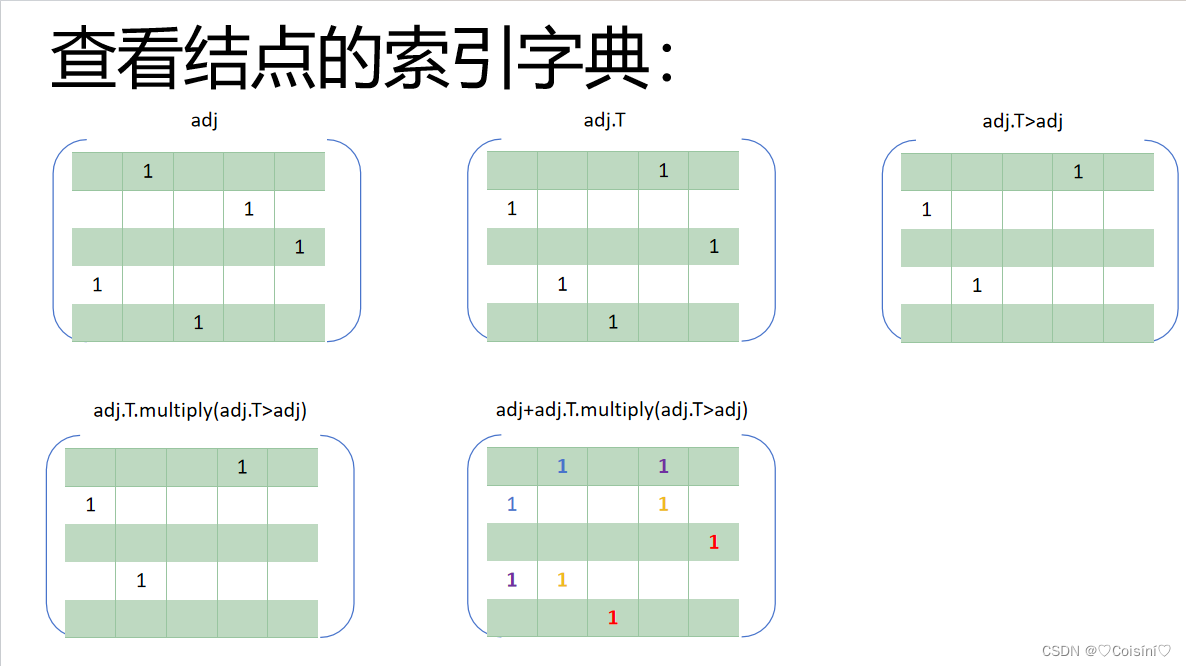
对于代码中如何将无向图变成有向图的公式是十分重要的,这里也简单地举了一个小栗子:



注意:这里是有softmax()函数的哦~


)




)


)










)