batch_normalize=1 # 是否做BN
代码链接
环境配置
没有Anaconda的话可以安装下
首先创建虚拟环境,名称随意,版本3.9.我觉得挺好的
激活虚拟环境
conda activate 刚刚创建的环境名称
切换到requirements.txt目录下,直接vscode打开yolov3文件夹后,右键requirements.txt,复制路径
cd 路径即可(ps,先切换磁盘,for example,d:)再cd
按照requirements.txt安装环境后,直接运行train.py,你应该只会遇到two problem(我当初是doge),因为没记录下来,这里就不赘述了
yolov3.yaml
# YOLOv3 🚀 by Ultralytics, AGPL-3.0 license# Parameters
nc: 80 # 要检测的类的数量
depth_multiple: 1.0 # 控制或缩放模型层的深度
width_multiple: 1.0 # 用于控制或缩放图层的通道数
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# 这些数字成对排列,每对代表锚框的宽度和高度,如第一个锚框宽为10,高为13
# 原始模型,只有三个检测层,因此对应三组初始化Anchor值。当输入图像尺寸为640X640时
# P3/8 对应的检测层大小为80X80大小,可以用来检测大小在8X8以上的目标。
# P4/16对应的检测层大小为40X40大小,可以用来检测大小在16X16以上的目标。
# P5/32对应的检测层大小为20X20大小,可以用来检测32X32以上的目标# darknet53 backbone
backbone:# [from, number, module, args]# from是从哪里接,-1就是代表上一层,-2就是上上层,具体数字就是具体哪一层# number就是重复来几次,8, Bottleneck就是重复8次Bottleneck,和resnet里面的残差类似# 实际中的重复次数=number*depth_multiple# args就是module的参数,filters、size、stride# 瓶颈层(Bottleneck):我们知道它是由:# 1x1 卷积层:应用 1x1 卷积来降低输入的维度。这降低了计算成本并有助于压缩信息# 3x3 卷积层:该层捕获降维内的空间特征# 1x1 卷积层(扩展):应用另一个 1x1 卷积将维度扩展回原始大小。这是瓶颈部分,因为它在再次扩展之前通过狭窄的层“挤压”信息# 64表示的是滤波器的个数[[-1, 1, Conv, [32, 3, 1]], # 0层 1[-1, 1, Conv, [64, 3, 2]], # 1-P1/2 2[-1, 1, Bottleneck, [64]], #4[-1, 1, Conv, [128, 3, 2]], # 3-P2/4 5[-1, 2, Bottleneck, [128]], #5+2*2[-1, 1, Conv, [256, 3, 2]], # 5-P3/8 10[-1, 8, Bottleneck, [256]], #10+2*8[-1, 1, Conv, [512, 3, 2]], # 7-P4/16 27[-1, 8, Bottleneck, [512]], #27+2*8[-1, 1, Conv, [1024, 3, 2]], # 9-P5/32 44[-1, 4, Bottleneck, [1024]], # 10 44+2*4=52+FC=53]# YOLOv3 head
# 其实是Neck+head
# [-1, 1, Bottleneck, [1024, False]
# False其实这就是关闭了shortcut的选项
head:[[-1, 1, Bottleneck, [1024, False]],[-1, 1, Conv, [512, 1, 1]],[-1, 1, Conv, [1024, 3, 1]],[-1, 1, Conv, [512, 1, 1]],[-1, 1, Conv, [1024, 3, 1]], # 15 (P5/32-large)[-2, 1, Conv, [256, 1, 1]],# nn.Upsample表示上采样,# None表示没有特定的输出大小,即输出大小将由输入大小和上采样因子确定# nearest表示使用最近邻插值来进行上采样 [-1, 1, nn.Upsample, [None, 2, 'nearest']], # -1 表示从当前层往前数的第一个元素。# 8 表示这个元素的索引为 8,可能是指前面网络中的第 8 层。# 1 表示该元素的输出通道数为 1。# Concat 表示使用拼接(concatenate)操作。# [1] 表示拼接的方向,这里是沿着通道轴进行拼接[[-1, 8], 1, Concat, [1]], # cat backbone P4[-1, 1, Bottleneck, [512, False]],[-1, 1, Bottleneck, [512, False]],[-1, 1, Conv, [256, 1, 1]],[-1, 1, Conv, [512, 3, 1]], # 22 (P4/16-medium)[-2, 1, Conv, [128, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P3[-1, 1, Bottleneck, [256, False]],[-1, 2, Bottleneck, [256, False]], # 27 (P3/8-small)[[27, 22, 15], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]train.py
# 权重文件,选择你想使用的pt权重文件
parser.add_argument('--weights', type=str, default=ROOT / 'yolov3-tiny.pt', help='initial weights path')
# yaml文件,主要保存的是包含有关模型架构、超参数和训练配置的信息(这里默认使用的是yolov3-tiny.yaml,你可以根据自己需要更换)
parser.add_argument('--cfg', type=str, default='', help='model.yaml path')
# 选择你的训练数据集
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
run
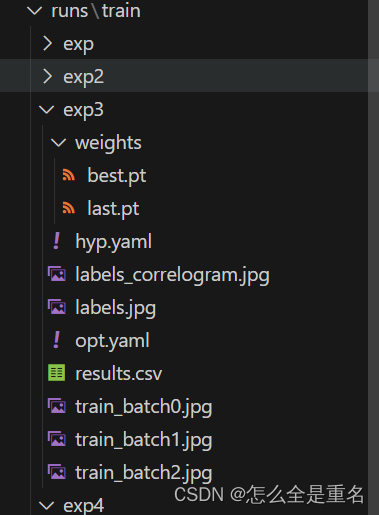
运行后,会生成run文件夹,run\exp\weights\best.pt,这是我们根据我们训练生成的pt文件,保存的是训练过程中在验证集上表现最好的模型权重,当然还有个last.pt,顾名思义,保存的是最后一次训练迭代结束后的模型权重
里面还有一堆其他的,如resluts.csv文件,我们可以根据该文件来绘制图表,此处亦不再赘述
detect.py
在detect部分呢,还是上述三行代码,我们可以把pt权重文件换成best.pt
数据集
coco128数据集
同样的,运行后会再run下生成detect文件

与面试Linux命令大全】)
)






)


)


)


)

