1、软件环境
1.1 大数据组件环境
| 大数据组件 | 版本 |
|---|---|
| Hive | 3.1.2 |
| Spark | spark-3.0.0-bin-hadoop3.2 |
1.2 操作系统环境
| OS | 版本 |
|---|---|
| MacOS | Monterey 12.1 |
| Linux - CentOS | 7.6 |
2、大数据组件搭建
2.1 Hive环境搭建
1)Hive on Spark说明
Hive引擎包括:默认
mr、spark、Tez。
Hive on Spark:Hive既作为存储元数据又负责SQL的解析优化,语法是HQL语法,执行引擎变成了Spark,Spark负责采用RDD执行。
Spark on Hive : Hive只作为存储元数据,Spark负责SQL解析优化,语法是Spark SQL语法,Spark负责采用RDD执行。
2)Hive on Spark配置
(1)兼容性说明
注意:官网下载的Hive3.1.2和Spark3.0.0默认是不兼容的。因为Hive3.1.2支持的Spark版本是2.4.5,所以需要我们重新编译Hive3.1.2版本。
编译步骤:官网下载Hive3.1.2源码,修改pom文件中引用的Spark版本为3.0.0,如果编译通过,直接打包获取jar包。如果报错,就根据提示,修改相关方法,直到不报错,打包获取jar包。
(2)在Hive所在节点部署Spark
如果之前已经部署了Spark,则该步骤可以跳过。
Spark官网下载jar包地址
http://spark.apache.org/downloads.html
上传并解压解压spark-3.0.0-bin-hadoop3.2.tgz
[postman@cdh01 software]$ tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module/
[postman@cdh01 software]$ mv /opt/module/spark-3.0.0-bin-hadoop3.2 /opt/module/spark
(3)配置SPARK_HOME环境变量
[postman@cdh01 software]$ sudo vim /etc/profile.d/my_env.sh
添加如下内容。
# SPARK_HOME
export SPARK_HOME=/opt/module/spark
export PATH=$PATH:$SPARK_HOME/bin
使其生效:
source ${环境变量文件}
# For MacOS
[postman@cdh01 software]$ source ~/.zshrc# For CentOS
[postman@cdh01 software]$ source /etc/profile.d/my_env.sh
(4)在hive中创建spark配置文件
[postman@cdh01 software]$ vim /opt/module/hive/conf/spark-defaults.conf
添加如下内容(在执行任务时,会根据如下参数执行)。
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://cdh01:8020/spark-history
spark.executor.memory 1g
spark.driver.memory 1g
在HDFS创建如下路径,用于存储历史日志。
[postman@cdh01 software]$ hadoop fs -mkdir /spark-history
(5)向HDFS上传Spark无 hadoop+hive 依赖的纯净jar包
- 说明1:由于Spark3.0.0非纯净版默认支持的是hive2.3.7版本,直接使用会和安装的Hive3.1.2出现兼容性问题。所以采用Spark纯净版jar包,不包含hadoop和hive相关依赖,避免冲突。
- 说明2:Hive任务最终由Spark来执行,Spark任务资源分配由Yarn来调度,该任务有可能被分配到集群的任何一个节点。所以需要将Spark的依赖上传到HDFS集群路径,这样集群中任何一个节点都能获取到。
上传并解压spark-3.0.0-bin-without-hadoop.tgz
[postman@cdh01 software]$ tar -zxf /opt/software/spark-3.0.0-bin-without-hadoop.tgz
上传Spark纯净版jar包到HDFS
[postman@cdh01 software]$ hadoop fs -mkdir -p /spark-jars
[postman@cdh01 software]$ hadoop fs -put spark-3.0.0-bin-without-hadoop/jars/* /spark-jars
(6)修改hive-site.xml文件
[postman@cdh01 ~]$ vim /opt/module/hive/conf/hive-site.xml
添加如下内容。
<!--Spark依赖位置(注意:端口号8020必须和namenode的端口号一致)-->
<property><name>spark.yarn.jars</name><value>hdfs://cdh01:8020/spark-jars/*</value>
</property><!--Hive执行引擎-->
<property><name>hive.execution.engine</name><value>spark</value>
</property>
7)修改 $SPARK_HOME/conf/spark-env.sh 文件
[postman@cdh01 ~]$ vim $SPARK_HOME/conf/spark-env.sh
添加如下内容。
export SPARK_DIST_CLASSPATH=$(hadoop classpath)
否则将报各类hadoop依赖包缺失的异常,如log4j、Hadoop的Configuration等包缺失。
2.2 Hive on Spark测试
(1)启动hive客户端
[postman@cdh01 hive]$ bin/hive
(2)创建一张测试表
hive (default)> create table user(id int, name string);
(3)通过insert测试效果
hive (default)> insert into table user values(1001,'zhangsan');
若结果如下,则说明配置成功。
hive (default)> insert into table user values(1001,'zhangsan');
Query ID = user_20231108165919_9908b655-96a7-4ccb-bb62-4dde28df9394
Total jobs = 1
Launching Job 1 out of 1
In order to change the average load for a reducer (in bytes):set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:set mapreduce.job.reduces=<number>
Running with YARN Application = application_1699425455296_0013
Kill Command = /opt/module/hadoop-3.1.3/bin/yarn application -kill application_1699425455296_0013
Hive on Spark Session Web UI URL: http://192.168.1.1:60145Query Hive on Spark job[0] stages: [0, 1]
Spark job[0] status = RUNNING
Job Progress Format
CurrentTime StageId_StageAttemptId: SucceededTasksCount(+RunningTasksCount-FailedTasksCount)/TotalTasksCount
2023-11-08 16:59:35,314 Stage-0_0: 0/1 Stage-1_0: 0/1
2023-11-08 16:59:37,331 Stage-0_0: 1/1 Finished Stage-1_0: 0/1
2023-11-08 16:59:39,363 Stage-0_0: 1/1 Finished Stage-1_0: 1/1 Finished
Spark job[0] finished successfully in 6.09 second(s)
Loading data to table default.user
OK
col1 col2
Time taken: 20.569 seconds
hive (default)> select * from user;
OK
user.id user.name
1001 zhangsan
3、安装过程中的错误
3.1 M1芯片下 zstd 库文件错误
当执行 MR 类 sql 如 ”insert into table user values(1001,‘zhangsan’); “ 时,程序在 Console 上长时间卡住,但无错误日志输出,此时日志格式为:
hive (default)> insert into table student values(1,'abc');
Query ID = davidliu_20231108163620_eb8fabe4-b615-4d12-9dba-56ead5946a98
Total jobs = 1
Launching Job 1 out of 1
In order to change the average load for a reducer (in bytes):set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:set mapreduce.job.reduces=<number>
Running with YARN Application = application_1699425455296_0010
Kill Command = /opt/module/hadoop-3.1.3/bin/yarn application -kill application_1699425455296_0010
Hive on Spark Session Web UI URL: http://192.168.154.240:56101Query Hive on Spark job[0] stages: [0, 1]
Spark job[0] status = RUNNING
Job Progress Format
CurrentTime StageId_StageAttemptId: SucceededTasksCount(+RunningTasksCount-FailedTasksCount)/TotalTasksCount
2023-11-08 16:36:36,031 Stage-0_0: 0/1 Stage-1_0: 0/1
2023-11-08 16:36:39,089 Stage-0_0: 1/1 Finished Stage-1_0: 0(+1)/1
2023-11-08 16:36:42,148 Stage-0_0: 1/1 Finished Stage-1_0: 0(+1)/1
2023-11-08 16:36:45,201 Stage-0_0: 1/1 Finished Stage-1_0: 0(+1)/1
2023-11-08 16:36:48,270 Stage-0_0: 1/1 Finished Stage-1_0: 0(+1)/1
2023-11-08 16:36:51,331 Stage-0_0: 1/1 Finished Stage-1_0: 0(+1)/1
2023-11-08 16:36:54,385 Stage-0_0: 1/1 Finished Stage-1_0: 0(+1)/1
2023-11-08 16:36:57,435 Stage-0_0: 1/1 Finished Stage-1_0: 0(+1)/1
2023-11-08 16:37:00,478 Stage-0_0: 1/1 Finished Stage-1_0: 0(+1)/1
2023-11-08 16:37:03,517 Stage-0_0: 1/1 Finished Stage-1_0: 0(+1)/1
2023-11-08 16:37:06,572 Stage-0_0: 1/1 Finished Stage-1_0: 0(+1)/1
2023-11-08 16:37:09,606 Stage-0_0: 1/1 Finished Stage-1_0: 0(+1)/1
2023-11-08 16:37:12,653 Stage-0_0: 1/1 Finished Stage-1_0: 0(+1)/1
2023-11-08 16:37:15,700 Stage-0_0: 1/1 Finished Stage-1_0: 0(+1)/1
2023-11-08 16:37:18,737 Stage-0_0: 1/1 Finished Stage-1_0: 0(+1)/1
2023-11-08 16:37:21,790 Stage-0_0: 1/1 Finished Stage-1_0: 0(+1)/1
2023-11-08 16:37:24,832 Stage-0_0: 1/1 Finished Stage-1_0: 0(+1)/1
2023-11-08 16:37:27,874 Stage-0_0: 1/1 Finished Stage-1_0: 0(+1)/1
2023-11-08 16:37:30,914 Stage-0_0: 1/1 Finished Stage-1_0: 0(+1)/1
...
...
2023-11-08 16:37:33,974 Stage-0_0: 1/1 Finished Stage-1_0: 0(+1)/1
Interrupting... Be patient, this might take some time.
Press Ctrl+C again to kill JVM
Exiting the JVM
在“Ctrl + C”取消 sql 执行之前,去 yarn 控制页面查看了一下程序运行的结果:
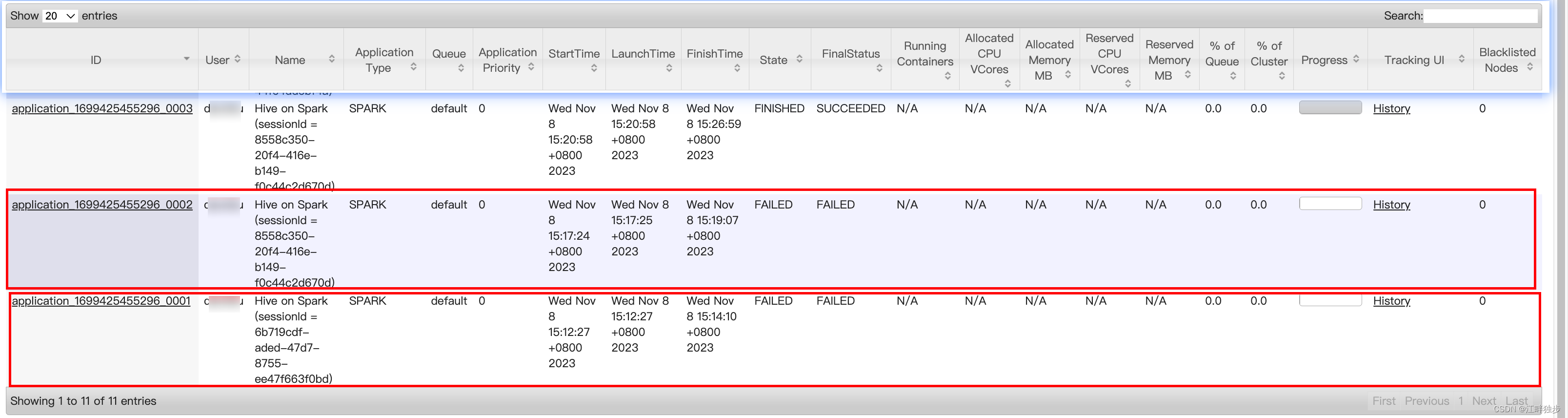
在WebUI 页面上从某次失败 Application 的某次 MR 任务的执行 log 中,发现有如下错误:
Caused by: java.lang.UnsatisfiedLinkError: no zstd-jni in java.library.path
Unsupported OS/arch, cannot find /darwin/aarch64/libzstd-jni.dylib or load zstd-jni from system libraries. Please try building from source the jar or providing libzstd-jni in your system.at java.lang.Runtime.loadLibrary0(Runtime.java:1011)at java.lang.System.loadLibrary(System.java:1657)at com.github.luben.zstd.util.Native.load(Native.java:85)at com.github.luben.zstd.util.Native.load(Native.java:55)at com.github.luben.zstd.Zstd.<clinit>(Zstd.java:13)at com.github.luben.zstd.Zstd.decompressedSize(Zstd.java:579)
同时在 Hadoop ResourceManager 的运行日志中也发现了关于这块的报错日志。
从上述 log 中可以看出zstd 软件库包(作用:文件压缩)在 M1 芯片下 不能很高的被支持,结合 Hive On Spark 运行的库包路径查找比对,最终在上传到HDFS集群路径/spark-jars 下 Hive on Spark的依赖jar 包中发现了 zstd jar 包:
- zstd-jni-1.4.4-3.jar
经查,此前已有开发者在 zstd 的github项目 下上报过这个问题,且有网友反馈在"1.4.9-1"版本中已修复了该问题。
于是在 mvnrepository 网站 上下载版本的 jar 包:
- zstd-jni-1.4.9-1.jar
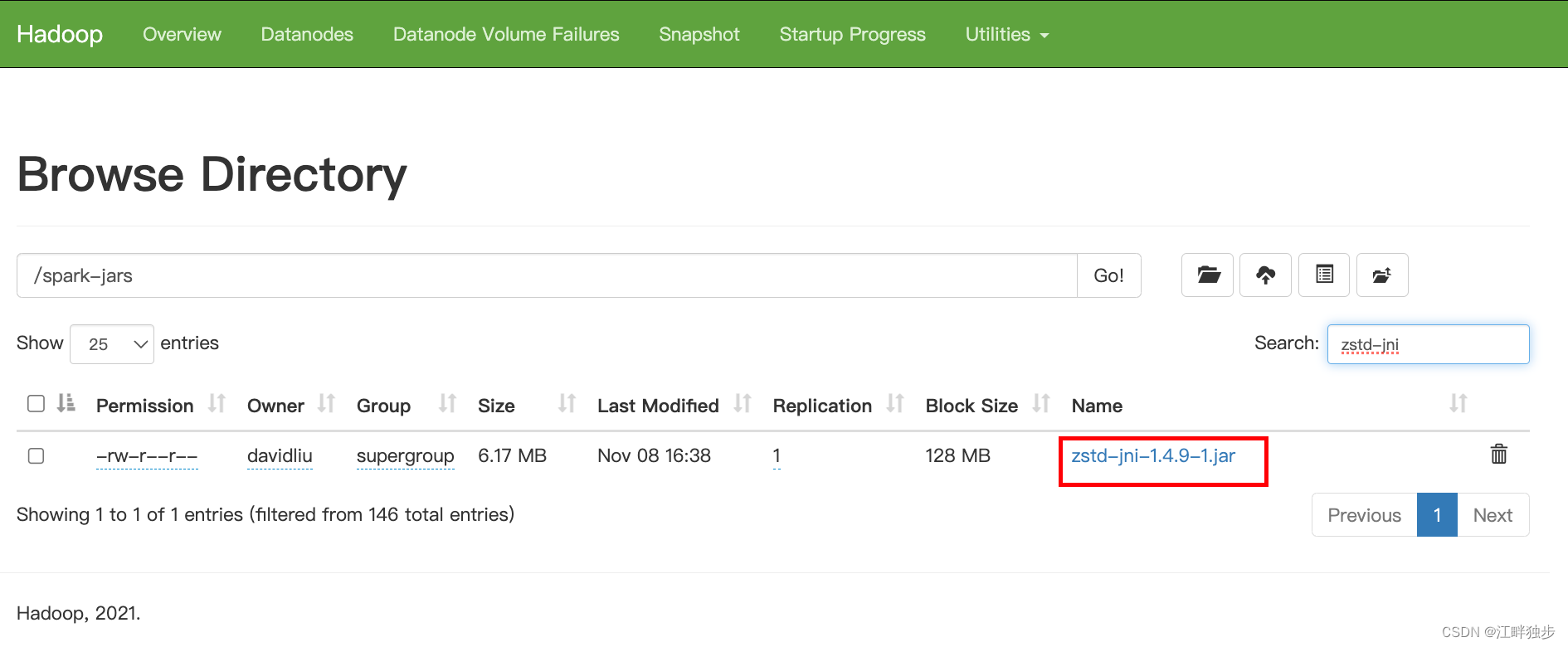
之后,将 HDFS 路径“hdfs://cdh01:8020/spark-jars/*”下的原始 “zstd-jni-1.4.4-3.jar” 删除,并替换为 “zstd-jni-1.4.9-1.jar” 后(如上图所示),经再度测试,该问题就解决了。






)












