论文标题:MemGPT: Towards LLMs as Operating Systems
论文作者:Charles Packer, Vivian Fang, Shishir G. Patil, Kevin Lin, Sarah Wooders, Joseph E. Gonzalez (UC Berkeley)
论文原文:https://arxiv.org/abs/2310.08560
论文出处:–
论文被引:–(10/31/2023)
论文代码:https://memgpt.ai/
Summary
为了更好的本文参考OS中虚拟存的思想,可以先了解一下相关知识。
MemGPT 与 OS 虚拟内存的对应关系
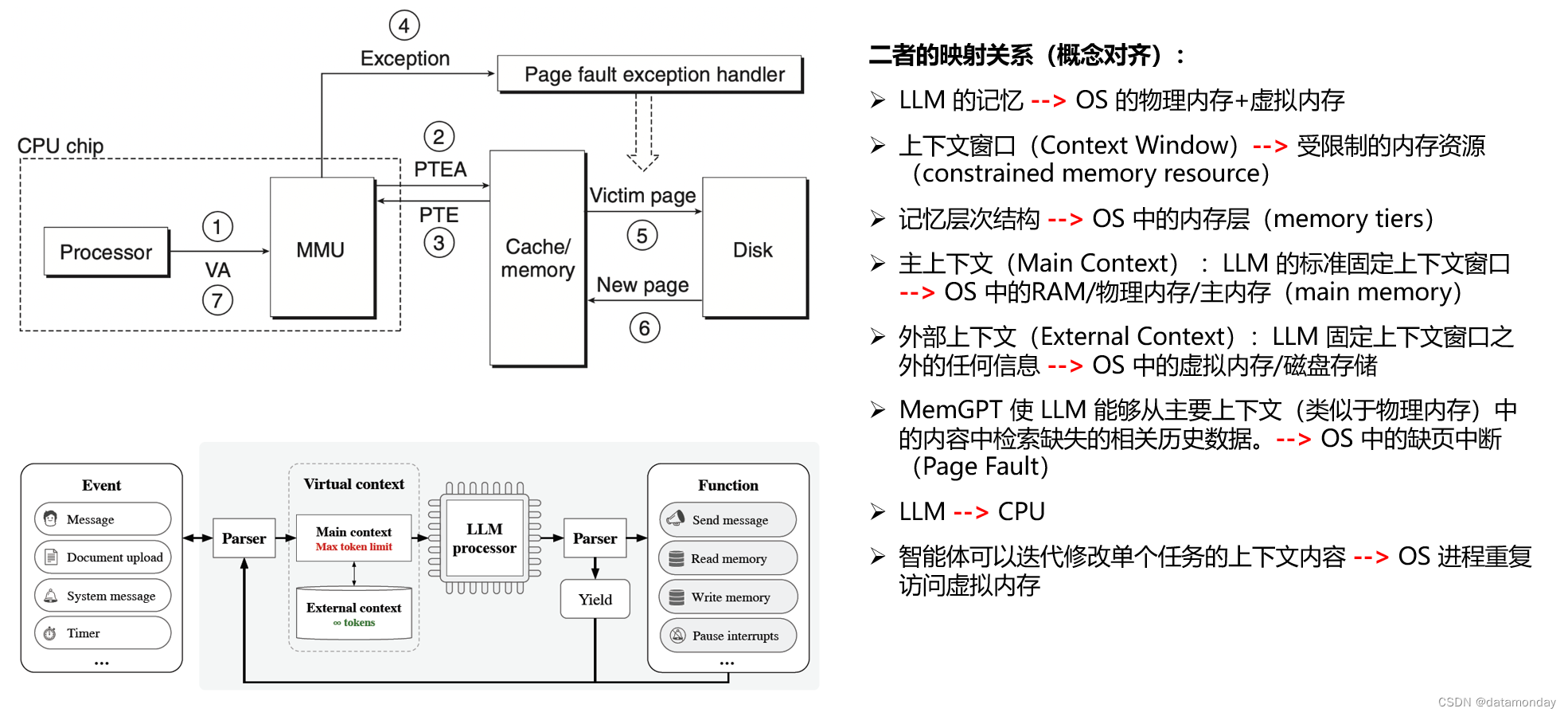
左上角的缺业中断时CPU的处理流程的详细解释可以参考文章:CSAPP 读书笔记:虚拟内存
思维导图

Abstract
大型语言模型(LLM)给人工智能带来了革命性的变化,但受限于有限的上下文窗口,妨碍了它们在扩展对话和文档分析等任务中的应用。为了使上下文的使用超越有限的上下文窗口,我们提出了虚拟上下文管理(virtual context management),这是一种从传统操作系统中的分层内存系统(hierarchical memory systems)中汲取灵感的技术。利用这种技术,我们提出了 MemGPT(Memory-GPT)系统,它能智能地管理不同的记忆层(memory tiers),以便在 LLM 的有限上下文窗口内有效地提供扩展上下文,并利用中断(interrupts)来管理自身与用户之间的控制流。我们在两个领域评估了受操作系统启发的设计,在这两个领域中,现代 LLM 的有限上下文窗口严重影响了它们的性能:
- 文档分析(document analysis):MemGPT 能够分析远远超出底层 LLM 上下文窗口的大型文档;
- 多会话聊天(multi-session chat):MemGPT 能够创建会话智能体(agent),通过与用户的长期互动进行记忆(remember),反思(reflect)和动态进化(evolve dynamically)。
1 Introduction
近年来,大型语言模型(LLMs)及其底层Transformer架构已成为对话式人工智能的基石,并带来了一系列广泛的消费者和企业应用。尽管取得了这些进步,但 LLM 使用的有限固定长度上下文窗口极大地阻碍了它们对长对话或长文档推理的适用性。例如,最广泛使用的开源 LLM(Llama 2,2023)在超过其最大输入长度之前,只能支持几十条来回信息或推理一个短文档。
由于Transformer架构的自注意力机制,如果只是单纯地增加Transformer的上下文长度会导致计算时间和内存成本的会呈二次方增长,因此设计新的长上下文架构成为了一项紧迫的研究挑战。虽然开发更长的模型是一个活跃的研究领域,但即使我们能克服上下文扩展的计算挑战,最近的研究也表明,长上下文模型很难有效利用额外的上下文。因此,考虑到训练最先进的 LLM 所需的大量资源以及上下文缩放的明显收益递减,我们亟需替代技术来支持长上下文。
在本文中,我们研究了如何在继续使用固定上下文模型的同时提供无限上下文的错觉(illusion)。我们的方法借鉴了虚拟内存分页的理念,该理念是为了让应用程序能够处理远远超出可用内存的数据集而开发的。我们利用最近在 LLM 智能体的函数调用能力方面取得的进展,设计了用于虚拟上下文管理的受操作系统启发的 LLM 系统 MemGPT。我们从传统操作系统的分层内存管理中汲取灵感,在上下文窗口(类似于操作系统中的主内存(main memory))和外部存储之间有效地 “分页(page)” 进出信息。MemGPT 管理记忆管理(memory management),LLM 处理模块和用户之间的控制流。这种设计允许在单个任务中重复修改上下文,使智能体能够更有效地利用其有限的上下文。
在 MemGPT 中,我们将上下文窗口视为受限制的内存资源,并为 LLM 设计了一个记忆层次结构,类似于传统操作系统中使用的内存层(Patterson 等人,1988 年)。传统操作系统中的应用程序与虚拟内存交互,虚拟内存提供了一种错觉,即物理内存(即主内存)中实际可用的内存资源要多于虚拟内存,因为操作系统会将溢出数据分页到磁盘,并在应用程序访问时将数据(通过page fault)取回内存。为了提供更长上下文长度(类似于虚拟内存)的类似假象,我们允许 LLM 通过 “LLM 操作系统” 管理放置在其自身上下文(类似于物理内存)中的内容,我们称之为 MemGPT。MemGPT 使 LLM 能够从置于上下文中的内容中检索缺失的相关历史数据,类似于操作系统的 page fault(缺页中断/缺页故障)。此外,智能体还可以迭代修改单个任务的上下文内容,就像进程可以重复访问虚拟内存一样。图 1 展示了 MemGPT 的组成部分。
补充说明
缺页中断(Page Fault):指的是当软件试图访问已映射在虚拟地址空间中,但是目前并未被加载在物理内存中的一个分页时,由CPU的内存管理单元所发出的中断。通常情况下,用于处理此中断的程序是OS的一部分。如果操作系统判断此次访问是有效的,那么操作系统会尝试将相关的分页从硬盘上的虚拟内存文件中调入内存。而如果访问是不被允许的,那么操作系统通常会结束相关的进程。
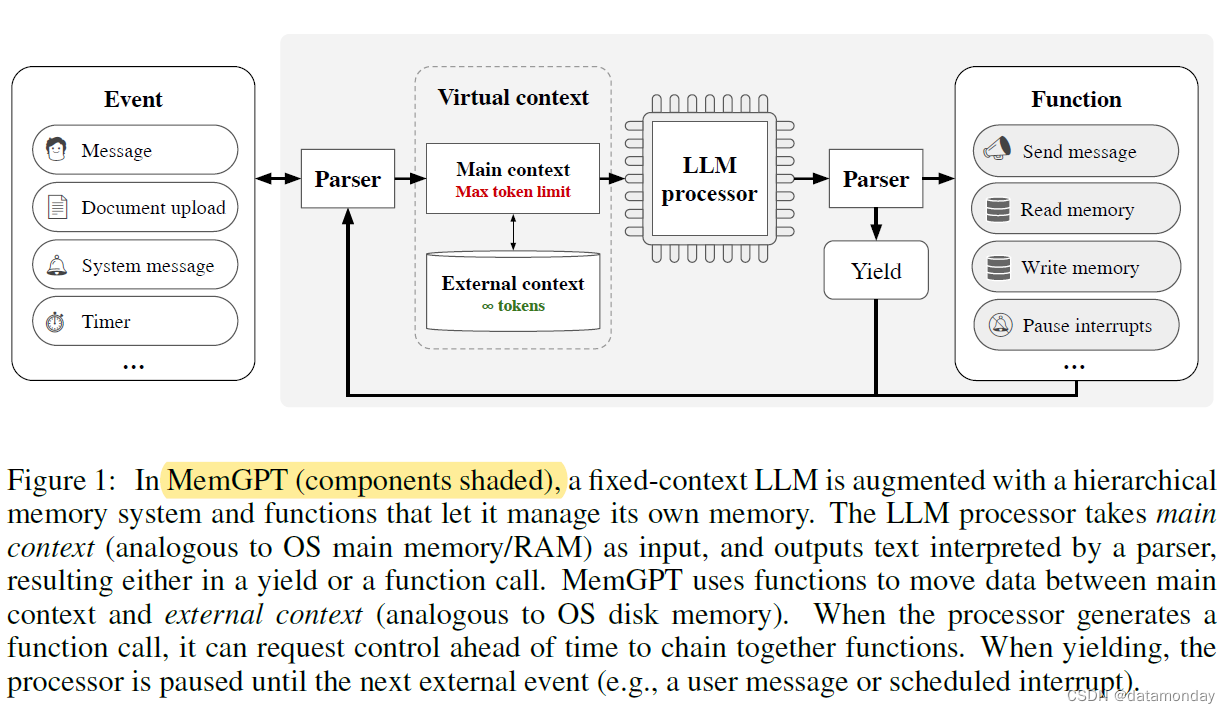
结合使用内存层次结构,操作系统功能和基于事件的控制流,MemGPT 可以使用具有有限上下文窗口的 LLM 处理无限制上下文。为了证明受操作系统启发的新 LLM 系统的实用性,我们在两个领域对 MemGPT 进行了评估,在这两个领域中,现有 LLM 的性能受到有限上下文的严重限制:文档分析和对话智能体,前者的标准文本文件长度可能很快超过现代 LLM 的输入容量,后者的 LLM 受限于有限的对话窗口,在扩展对话中缺乏上下文意识、角色一致性和长期记忆。在这两种情况下,MemGPT 都能克服有限上下文的限制,表现优于现有的基于 LLM 的方法。
2 Memory-GPT (MemGPT)
在本节中,我们将概述 MemGPT 的实现过程,这是一个受操作系统启发的 LLM 系统,它教会 LLM 管理自己的记忆,以实现无限制的上下文。MemGPT 的多级记忆架构划分了两种主要记忆类型:主上下文(类似于主内存/物理内存/RAM)和外部上下文(类似于磁盘内存/磁盘存储)。主上下文是现代语言模型中的标准固定上下文窗口–主上下文中的任何内容都被视为在上下文中,可由 LLM 处理器在推理过程中访问。外部上下文指的是在 LLM 固定上下文窗口之外的任何信息。这种外部上下文数据必须始终显式地移入主上下文,才能在推理过程中传递给 LLM 处理器。MemGPT 提供了函数调用,LLM 处理器可以利用这些函数调用管理自己的记忆,而无需用户干预。
2.1 Main Context
在 MemGPT 中,我们将 LLM 输入(受输入token最大数量的限制)称为系统的主上下文(Main Context)。在基于 LLM 的对话式智能体中,主上下文token的很大一部分通常用于保存系统信息或预提示(preprompt),它决定了系统交互的性质,而其余的token则可用于保存对话数据。这种预提示是使系统在不需要对基础模型进行微调的情况下采用各种不同角色的主要方法;根据不同的使用情况,预提示的范围可以从基本的引导语(如 You are a helpful assistant.)到包含数千个标记的复杂指令(如 a fictional character card that includes the character's background and example dialogue)。除对话智能体外,当 LLM 被用于解决复杂任务时,大量的前置句也很常见,这些任务需要长指令和/或包含许多上下文示例的指令(Liu 等人,2023b)。

由于预提示在决定系统行为方面的重要性,预提示消耗超过一千个token是很常见的,这意味着在许多现代 LLM 中,用户和系统只需来回发送几十条信息,就能耗尽整个上下文窗口。例如,在使用 llama-2 或 gpt-3.5-turbo 等 4K 上下文模型时,1000 个token的预提示(与我们实验中 MemGPT 的预提示大小相当)仅能容纳 60 条剩余信息(更多示例请参见表 1)。在用户需要与系统频繁交流的情况下(例如,虚拟伴侣或个性化助手),即使是具有 100K 上下文窗口的模型,也很容易在几天(或可能几小时)内超过最大对话长度。递归总结(Wu 等人,2021b)是解决上下文窗口溢出问题的一种简单方法,但递归总结本身是有损的,最终会导致系统记忆出现大漏洞(正如我们在第 3 节中所演示的那样)。这就促使我们需要一种更全面的方法来管理需要长期使用的对话系统的记忆。
在多会话聊天和文档分析实验中,我们将主上下文进一步划分为三个部分:
- 系统指令(保存基本 LLM 指令,例如描述 MemGPT 功能和 LLM 控制流的信息)
- 对话上下文(保存最近事件历史(例如智能体和用户之间的消息)的先进先出队列)
- 工作上下文(作为智能体的工作内存抓取板)。
系统指令是只读的,并固定在主上下文中(在 MemGPT 智能体的生命周期内不会改变);对话上下文是只读的,并有特殊的驱逐策略(如果队列达到一定大小,前面的一部分会被截断或通过递归总结进行压缩);工作上下文可由 LLM 处理器通过函数调用来写入。主上下文的三个部分加在一起不能超过底层 LLM 处理器的最大上下文大小,而在实际应用中,我们将对话上下文和工作上下文的大小限制为一个固定常数,该常数由处理器的上下文窗口和系统指令长度决定。
2.2 External Context
外部上下文指的是位于 LLM 处理器上下文窗口之外的外部存储,类似于操作系统中的磁盘存储器(即磁盘存储)。LLM 处理器无法立即看到外部上下文中的信息,但可以通过适当的函数调用将其引入主上下文。在实践中,外部上下文中的底层存储可以采取多种形式,并可针对特定任务进行配置:例如,对于会话智能体,可能需要存储用户与智能体之间的完整聊天记录(MemGPT 可在稍后访问);对于文档分析,可在外部上下文中存储大型文档集,MemGPT 可通过对磁盘的分页函数调用将其带入受限的主上下文。
在使用 MemGPT 进行多会话聊天和文档分析的实验中,我们使用数据库来存储文本文档和嵌入/向量,并为 LLM 处理器提供了几种查询外部上下文的方法:
- 基于时间戳的搜索
- 基于文本的搜索
- 基于嵌入的搜索
我们将外部上下文区分为两种类型:
- 一种是调用存储(recall storage),用于存储 LLM 处理器处理过的事件的全部历史记录(实质上是活动内存中未压缩的完整队列);
- 另一种是归档存储(archival storage),用于通用读写数据存储,智能体可将其用作上下文读写核心内存的溢出(overflow)。
在对话式智能体方面,
- 归档存储允许 MemGPT 在主上下文的严格标记限制之外存储智能体或用户的事实、经验、偏好等信息;
- 搜索调用存储允许 MemGPT 查找与特定查询或特定时间段内相关的过往交互。
在文档分析方面,归档存储可用于搜索(并添加到)庞大的文档数据库。
2.3 Self-Directed Editing and Retrieval


MemGPT 通过 LLM 处理器生成的函数调用协调主要上下文和外部上下文之间的数据移动。记忆编辑和检索完全是自导向的:MemGPT 根据当前上下文自主更新和搜索自己的记忆。例如,它可以决定何时在上下文之间移动内容(图 2)并修改其主要上下文,以更好地反映其对当前目标和职责的演变理解(图 4)。
我们通过提供预提示中的显式指令来实现自定向编辑和检索,该指令引导系统如何与其内存系统交互。这些指令包括两个主要组件:
- 1)记忆层次结构及其各自的实用程序的详细描述;
- 2)系统可以调用访问或修改其记忆的函数schema(用他们的自然语言描述完成)。

在每个推理周期中,LLM 处理器将主上下文(串联成一个字符串)作为输入,并生成一个输出字符串。MemGPT 对输出字符串进行解析,以确保其正确性,如果解析器验证了函数参数,则执行该函数。然后,MemGPT 会将结果,包括任何运行时发生的错误(例如,在主上下文已达到最大容量时试图向其添加内容)反馈给处理器。通过这种反馈回路,系统可以从自己的行为中吸取经验教训,并相应地调整自己的行为。对上下文限制的认识是使自我编辑机制有效发挥作用的一个关键方面,为此,MemGPT 会向处理器发出标记限制警告,以指导其内存管理决策(图 3)。此外,我们的记忆检索机制在设计上也考虑到了这些token限制,并实施了分页处理,以防止检索调用(retrieval calls)溢出上下文窗口。
2.4 Control Flow and Function Chaining
事件触发 LLM 推理:事件是 MemGPT 的通用输入,可包括
- 用户消息(在聊天应用中)
- 系统消息(如主上下文容量警告)
- 用户交互(如用户刚登录的提示,或用户完成上传文档的提示)
- 按固定时间表运行的定时事件(允许 MemGPT 在无用户干预的情况下 “无提示” 运行)。
MemGPT 使用解析器处理事件,将其转换为纯文本信息,这些信息可附加到主上下文中,并最终作为输入输入到 LLM 处理器中。
许多实际任务需要依次调用多个函数,例如,浏览单个查询结果的多个页面,或整理来自不同文档的数据,这些数据来自不同查询的主上下文。函数链允许 MemGPT 在将控制权返回给用户之前依次执行多个函数调用。在 MemGPT 中,调用函数时可以使用一个特殊标志,要求在请求的函数执行完毕后立即将控制权返回给处理器。如果该标志存在,MemGPT 将把函数输出添加到主上下文(而不是暂停处理器执行)。如果该标志不存在(a yield),MemGPT 将不运行 LLM 处理器,直到下一个外部事件触发(如用户信息或计划中断)。
3 Experiments
我们在两个长上下文领域对 MemGPT 进行了评估:对话智能体和文档分析。
- 在对话智能体方面,我们扩展了现有的多会话聊天数据集 Xu 等人(2021 年),并引入了两个新的对话任务,以评估智能体在长时间对话中保留知识的能力。
- 在文档分析方面,我们以 Liu 等人(2023a)的现有任务为基准,对 MemGPT 进行了测试,以评估其在冗长文档中的问题解答和键值检索能力。我们还提出了一个新的嵌套键值检索任务,需要整理多个数据源的信息,这考验了智能体整理来自多个数据源的信息(多跳检索)的能力。我们公开发布了我们的增强 MSC 数据集、嵌套键值检索数据集和 2,000 万维基百科文章的嵌入数据集,以促进未来的研究。
3.1 MemGPT for Conversational Agents
虚拟伴侣和个性化助手等对话智能体旨在与用户进行自然、长期的互动,时间可能长达数周、数月甚至数年。这给具有固定长度上下文的模型带来了挑战,因为它们只能参考有限的对话历史。无限上下文智能体应无缝处理无边界或无重置的连续交流。在与用户对话时,这样的智能体必须满足两个关键标准:
- 一致性(Consistency)–智能体应保持对话的一致性。提及的新事实、偏好和事件应与用户和智能体之前的陈述保持一致。
- 参与性(Engagement)–智能体应利用有关用户的长期知识来个性化回复。参考先前的对话可使对话更自然、更吸引人。
因此,我们根据这两个标准来评估我们提出的模型 MemGPT:
- MemGPT 能否利用其记忆来提高对话的一致性?它能否记住过去互动中的相关事实、偏好和事件以保持连贯性?
- MemGPT 是否能利用记忆优势产生更吸引人的对话?它是否会自发地将用户的长期信息融入到个性化信息中?
通过对一致性和参与度进行评估,我们可以确定与固定上下文基线相比,MemGPT 在应对长期对话交互挑战方面的能力如何。它满足这些标准的能力将证明无限制上下文是否能为对话智能体带来有意义的好处。
3.1.1 Dataset
我们在 Xu 等人(2021 年)推出的多会话聊天(Multi-Session Chat,MSC)数据集上评估了 MemGPT 和我们的固定上下文基线,该数据集包含由人类标签生成的多会话聊天记录,每个标签都被要求在所有会话期间扮演一个一致的角色。MSC 中的每个多会话聊天总共有五个会话,每个会话由大约十几条消息组成。作为一致性实验的一部分,我们创建了一个新会话(Session 6),该会话包含相同两个角色之间的一对问答。
3.1.2 Deep Memory Retrieval Task (Consistency)
在这项任务中,代智能体会被问到一个与之前对话(session 1-5 )中讨论过的话题相关的具体问题。根据黄金回答对智能体的回答进行评分。

我们在 MSC 数据集的基础上引入了一项新的深度记忆检索(Deep Memory Retrieval,DMR)任务,旨在测试对话智能体的一致性。在 DMR 中,用户会向会话智能体提出一个问题,这个问题会明确回溯到之前的对话,而且预期答案范围非常窄(示例见图 5)。我们使用一个单独的 LLM 生成 DMR 问答(QA)对,该 LLM 被要求编写一个用户向另一个用户提出的问题,只有使用从过去会话中获得的知识才能正确回答该问题(详见附录)。
我们使用 ROUGE-L 分数(Lin,2004 年)和 LLM judge 对照黄金回答(gold response)来评估生成回答的质量,LLM judge 指示评估生成的回答是否与黄金回答一致(GPT-4 已被证明与人类评估者具有很高的一致性)。在实践中,我们注意到生成的回答(来自 MemGPT 和基线)通常比黄金回答更冗长;ROUGE-L(用于测量生成文本和参考文本之间的最长公共子序列)对正确回答中的这种语义变化具有鲁棒性,因为它能评估生成答案中是否存在黄金答案中的单词。我们还报告了用于计算 ROUGE-L (F1) 分数的精确度和召回率。
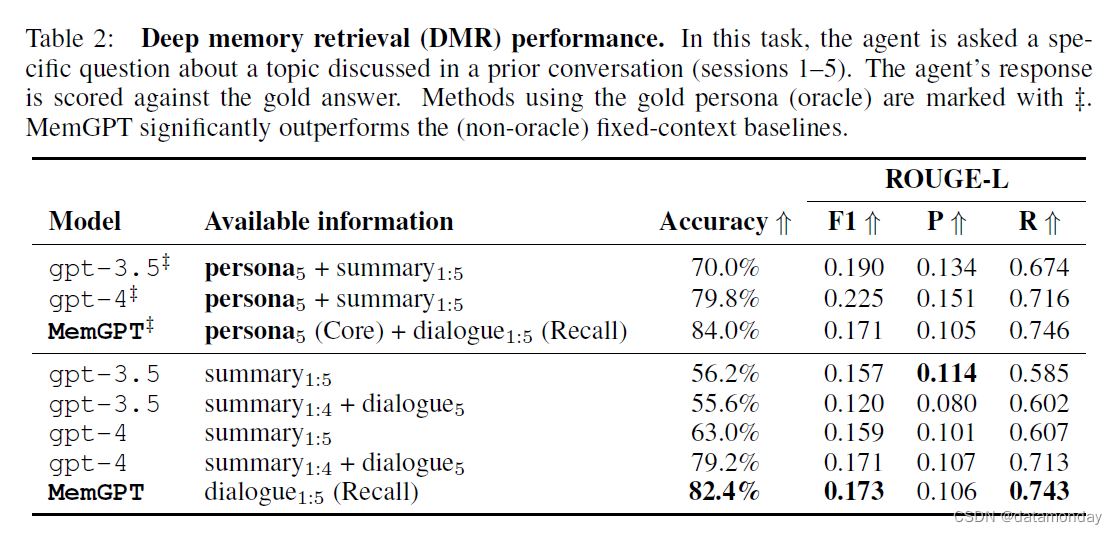
MemGPT 利用记忆保持一致性:表 2 显示了 MemGPT 与固定记忆基线的性能对比。我们将其与固定上下文基线的三种变化进行了比较:
- 一种智能体能看到过去五次对话的递归摘要(summary1:5)
- 一种智能体能看到前四次对话的递归摘要(summary1:4),前一次对话的确切内容(dialogue 5 被置于活动记忆中)
- 还有一种智能体能看到黄金角色(gold persona,两个聊天参与者)和递归摘要。
我们使用 GPT-3.5 和 GPT-4 对这些上下文变化进行了实验。
所有的黄金角色(Persona)基线都表现得近乎完美:这是因为在 MSC 数据集中,人工标注的黄金角色都很详细,而且是对之前所有聊天中的所有角色信息的简明总结。换句话说,一个写得好的黄金角色应该包含对 DMR 问题的回答。
- 在非算法固定上下文基线(non-oracle fixed-context baselines)中,GPT-4 的性能明显优于 GPT-3.5,而在这两种模型中,能够访问活动记忆中完整的先前对话的变体性能略好。
- 从 summary1:4 + dialogue5 到 summary1:5 的性能下降是意料之中的,因为后者包含的信息应该比前者少得多(假设有一个完美的摘要器,并限制摘要的长度)。
- MemGPT 在 LLM 判断准确率和 ROUGE-L 分数上都明显优于 GPT-4 和 GPT-3.5:MemGPT 不依赖递归摘要来扩展上下文,而是能够在其 Recall Memory 中查询过去的对话历史来回答 DMR 问题。
补充说明
角色(Persona):是对属于某个(交叉)人口群体的想象个体(imagined individual)的自然语言描述。这种方法受到了 [1] 的启发,在该研究中,作者通过获取人类对我们所使用的相同提示(prompt)的书面回答来揭示种族刻板印象。[2]
黄金数据集(Golden Dataset):这应该能代表你期望 LLM 评估看到的数据类型。黄金数据集应具有 Ground Truth 标签,以便我们衡量 LLM 评估模板(LLM eval template)的性能。这种标签通常来自于人类的反馈。[3]
评估模板(Eval Template):对核心组件进行基准测试以帮助改进组件。
[1] Surfacing racial stereotypes through identity portrayal. 2022.
[2] Marked Personas: Using Natural Language Prompts to Measure Stereotypes in Language Models. 2023.
[3] LLM Evaluation: The Definitive Guide:https://arize.com/blog-course/llm-evaluation-the-definitive-guide/
LLM eval template例子:
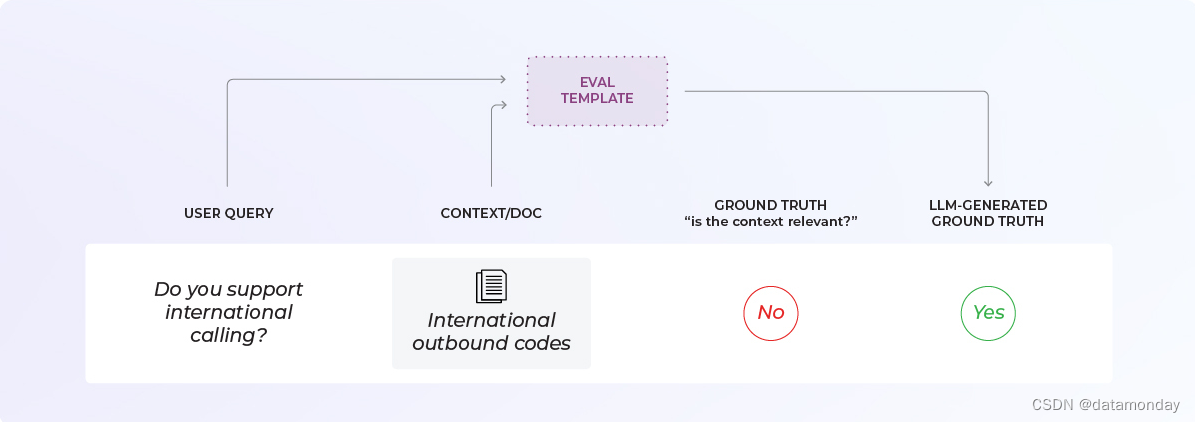
Relevance Eval Template:
You are comparing a reference text to a question and trying to determine if the reference text contains information relevant to answering the question. Here is the data:
[BEGIN DATA]
************
[Question]: {query}
************
[Reference text]: {reference}
[END DATA]Compare the Question above to the Reference text. You must determine whether the Reference text
contains information that can answer the Question. Please focus on whether the very specific
question can be answered by the information in the Reference text.
Your response must be single word, either “relevant” or “irrelevant”,
and should not contain any text or characters aside from that word.
“irrelevant” means that the reference text does not contain an answer to the Question.
“relevant” means the reference text contains an answer to the Question.
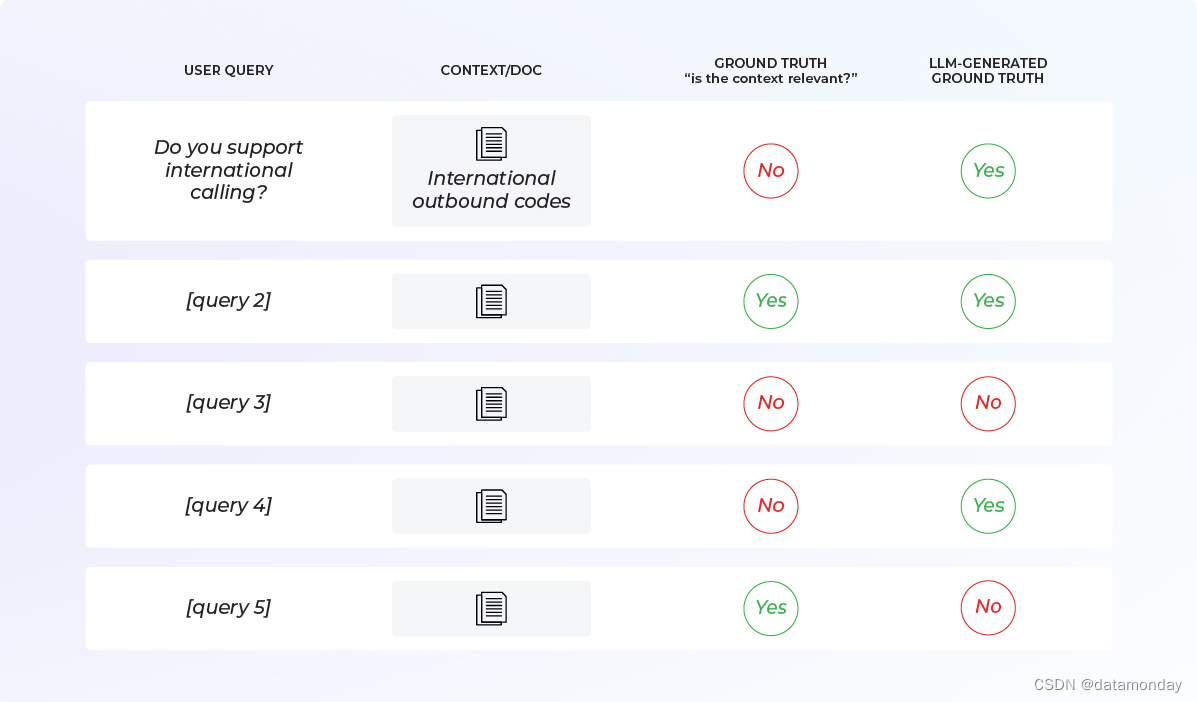
现在,我们要对核心组件进行基准测试和改进:评估模板(Eval Template)。如果使用的是 OpenAI 或 Phoenix 等现有库,则应从现有模板开始,看看该提示的性能如何。
图来自:[3]
如果想加入某个特定的细微差别,可以相应地调整模板或从头开始创建自己的模板。模板应具有清晰的结构。要明确以下几点:
- 输入内容是什么?示例中是检索到的文档/上下文和用户的查询。
- 我们在问什么?示例中要求 LLM 回答文档是否与查询相关。
- 可能的输出格式是什么?示例中是二分类,即相关/不相关,但也可以是多类(例如完全相关、部分相关、不相关)。
在黄金数据集上运行评估,可以生成指标(总体准确率、精确度、召回率、F1-分数等)来确定基准。重要的是,不能只看总体准确率。
如果对 LLM 评估模板的性能不满意,需要更改提示,使其性能更好。这是一个以硬指标为依据的迭代过程。与往常一样,重要的是避免模板与黄金数据集过拟合。确保有一个有代表性的保留集或运行 k 倍交叉验证。
图来自:[3]
3.1.3 Conversation Opener Task (Engagement)
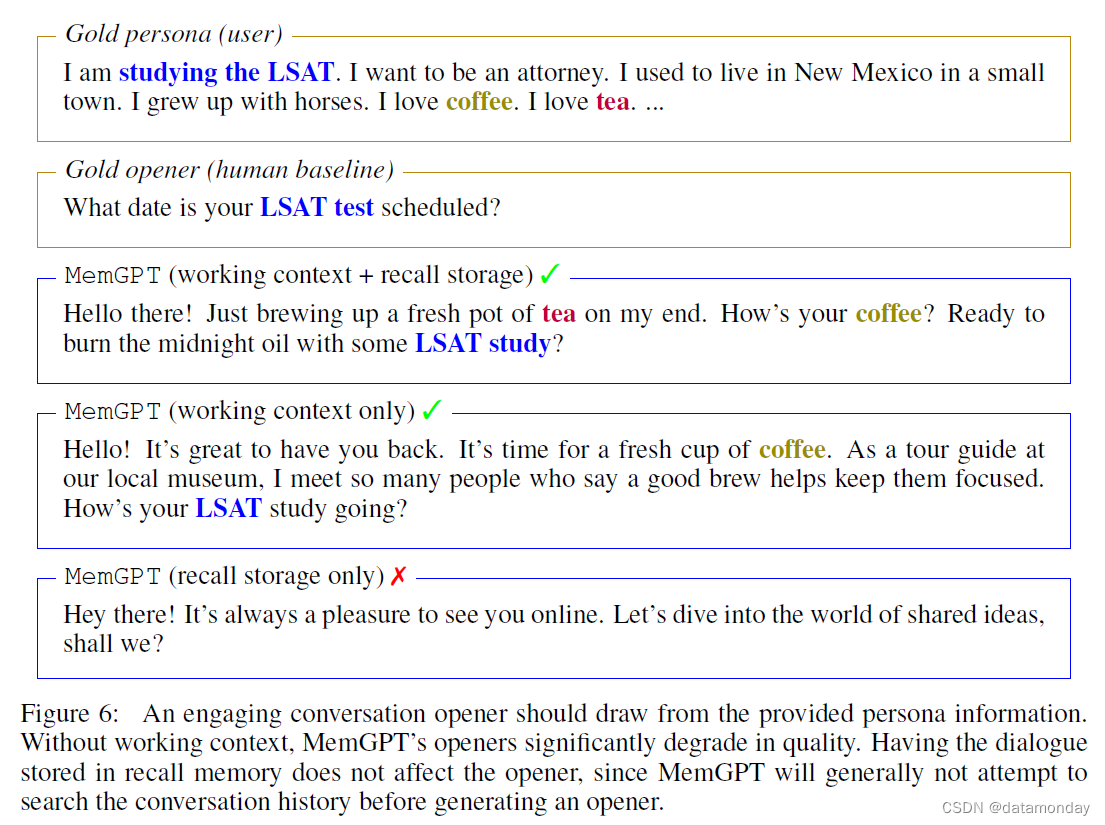
在对话开场白(Conversation Opener Task)任务中,我们要评估的是智能体能否利用先前对话中积累的知识,向用户发送引人入胜的信息。为了评估使用 MSC 数据集的对话开场白的 “吸引力(engagingness)”,我们将生成的开场白与黄金角色进行了比较:一个有吸引力的对话开场白应该从角色中包含的一个(或几个)数据点中提取,而在 MSC 中,这些数据点有效地总结了所有先前会话中积累的知识(示例见图 6)。我们还将其与人工生成的黄金开场白(即下一会话中的第一个回应)进行比较。由于对话开场白的质量并不一定受上下文长度的限制(递归总结或甚至是先前对话中的几个片段都足以制作出使用先前知识的开场白),因此我们使用这项任务来消除 MemGPT 的不同组成部分(而不是将其与固定上下文基线进行比较)。
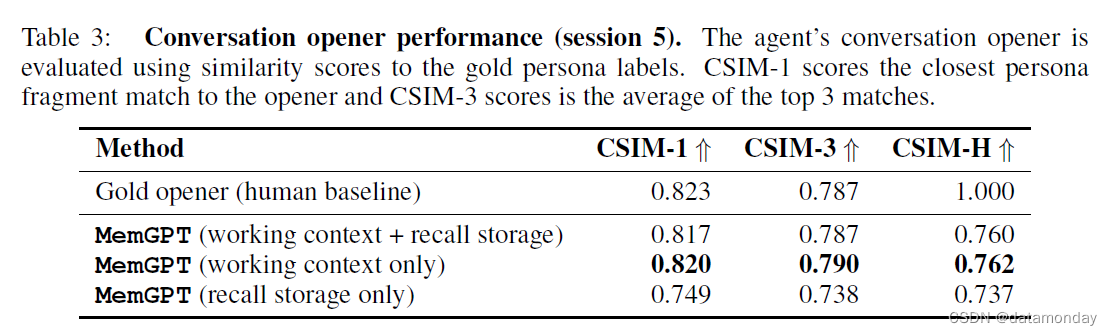
我们在表 3 中报告了 MemGPT 开场白的 CSIM 分数。我们测试了 MemGPT 的几种变体:
- 没有工作上下文(存储角色信息)、回忆存储(存储对话信息)的 MemGPT
- 没有工作上下文或没有回忆存储的 MemGPT
- 同时启用工作上下文和回忆存储的 MemGPT
MemGPT 利用记忆来提高参与度:如表 3 和图 6 所示,
- MemGPT 能够制作出引人入胜的开场白,其表现与人类手写开场白类似,有时甚至超过人类手写开场白。
- 我们观察到,与人类基线相比,MemGPT 制作的开场白往往更冗长,涵盖的角色信息也更多。
- 此外,我们还可以看到,在工作上下文中存储信息是生成吸引人的开场白的关键。如果没有工作上下文,MemGPT 的开场白质量就会明显下降;将对话存储在调用存储中不会影响开场白,因为 MemGPT 在生成开场白之前一般不会尝试搜索对话历史。
3.2 MemGPT for Document Analysis
由于当今 Transformer 模型的上下文窗口有限,文档分析也面临着挑战。例如,OpenAI 广受欢迎的 ChatGPT 消费者聊天机器人应用背后的(封闭)GPT 模型的输入字元限制为 32k,而最先进的开源 Llama 2 模型的输入字元限制仅为 4k(见表 1)。Anthropic 发布的(未开源)模型最多可处理 100k 标记,但许多文档都能轻松超过这一长度;斯蒂芬-金的畅销小说《闪灵》(The Shining)约有 15 万字,相当于约 20 万个标记(单词-标记因所使用的特定标记化器而异),而法律或财务文档(如年度报告(美国证券交易委员会 10-K 表))可以轻松超过百万标记大关。此外,许多实际的文档分析任务都需要在多个如此冗长的文档之间建立联系。考虑到这些情况,我们很难设想盲目扩大上下文规模来解决固定上下文问题。最近的研究(Liu 等人,2023a)也对简单扩展上下文的实用性提出了质疑,因为他们发现大型上下文模型的注意力分布不均衡(模型更有能力回忆上下文窗口开始或结束时的信息,而不是中间的标记)。为了实现跨文档推理,可能需要更灵活的内存架构,比如 MemGPT 中使用的架构。
3.2.1 Multi-Document Question-Answering (Doc-QA)
为了评估 MemGPT 分析文档的能力,我们在 Liu 等人(2023a)提出的检索器-阅读器文档问答(retriever-reader document QA)任务中,将 MemGPT 与固定上下文基线进行了比较。在这项任务中,我们从 NaturalQuestions-Open 数据集中选出一个问题,然后由检索器为该问题选择相关的维基百科文档。然后,一个读者模型(LLM)将这些文档作为输入,并被要求使用所提供的文档来回答问题。与 Liu 等人(2023a)类似,我们随着检索文档 K 数量的增加来评估阅读器的准确性。在我们的评估设置中,固定上下文基线和 MemGPT 都使用了相同的检索器,该检索器在 OpenAI 的 text-embedding-ada-002 嵌入上使用 Faiss 高效相似性搜索(相当于近似近邻搜索)来选择前 K 个文档。在 MemGPT 中,整个文档集被加载到档案存储中,检索器通过档案存储搜索功能(执行基于嵌入的相似性搜索)自然出现。在固定上下文基线中,top-K 文档是使用检索器独立于 LLM 推理获取的,这与最初的检索器-阅读器设置类似。我们使用了 2018 年末的维基百科数据,沿用了过去在 NaturalQuestions-Open (Izacard & Grave,2020;Izacard 等人,2021)上所做的工作。我们为图中的每个点随机抽取了 50 个问题的子集。
固定上下文基线的性能上限大致与检索器的性能相当,因为它们使用的是上下文窗口中显示的信息(例如,如果嵌入式搜索检索器未能使用所提供的问题显示出金牌文章(Golden Article),那么固定上下文基线则保证永远不会看到金牌文章)。相比之下,MemGPT 可以通过查询档案存储多次调用检索器,从而可以扩展到更大的有效上下文长度。MemGPT 会主动从存档存储中检索文档(并能反复翻阅结果),因此 MemGPT 可用的文档总数不再受 LLM 处理器上下文窗口中文档数量的限制。
由于基于嵌入的相似性搜索的局限性,文档QA任务对所有方法来说都具有挑战性。我们观察到,所选问题的黄金文档(由 NaturalQuestions-Open 标注)经常出现在前十几个检索结果之外,甚至更远。检索器的性能可直接转化为固定上下文基线结果:GPT-3.5 和 GPT-4 的准确率在检索到的文档较少的情况下相对较低,随着更多文档被添加到上下文窗口中,准确率会继续提高。虽然从理论上讲,MemGPT 不会受到次优检索器性能的限制(即使基于嵌入的排序存在噪声,只要完整的检索器排序包含黄金文档,那么通过分页法调用足够多的检索器,仍然可以找到黄金文档),但我们观察到,MemGPT 经常会在检索器数据库耗尽之前停止分页检索结果。例如,在筛选了几页不相关的结果(缺少黄金文档)后,MemGPT 会暂停分页,并要求用户帮助缩小查询范围,在我们的评估中,这些问题被算作失败答案,因为没有人在回路中回答 MemGPT。
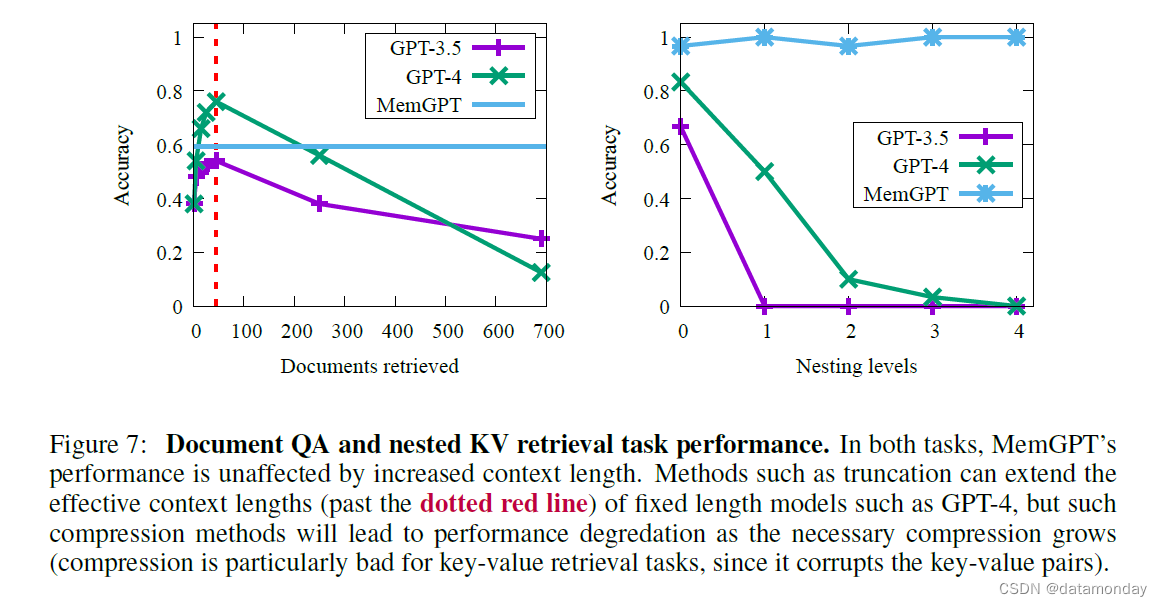
MemGPT 更复杂的操作也会对检索文档的容量造成影响:假设 MemGPT 的token预算与固定上下文基线(使用相同的 LLM)相同,那么 MemGPT 的token预算将有很大一部分被 MemGPT 的操作系统组件(例如用于内存管理的函数调用模式)所需的系统指令所消耗,这意味着 MemGPT 在任何给定时间内可保存的上下文文档总数都低于基线。从图 7 中可以看出这种权衡:MemGPT 的平均准确率低于 GPT-4(尽管高于 GPT-3.5),但可以轻松扩展到更大的文档数量。为了评估固定上下文基线与超过默认上下文长度的 MemGPT 的对比情况,我们截断了检索器返回的文档段,将相同数量的文档固定到可用上下文中。不出所料,随着文档的缩减,文档截断会降低准确率,因为相关片段(在黄金文档中)被遗漏的几率会增加。我们预计 MemGPT 在文档QA方面的性能可以通过附加任务指令得到进一步提高,这些指令可以降低 MemGPT 将控制权交还给用户的几率(例如暂停提问),并提高 MemGPT 阅读检索器排序的所有文档的几率。
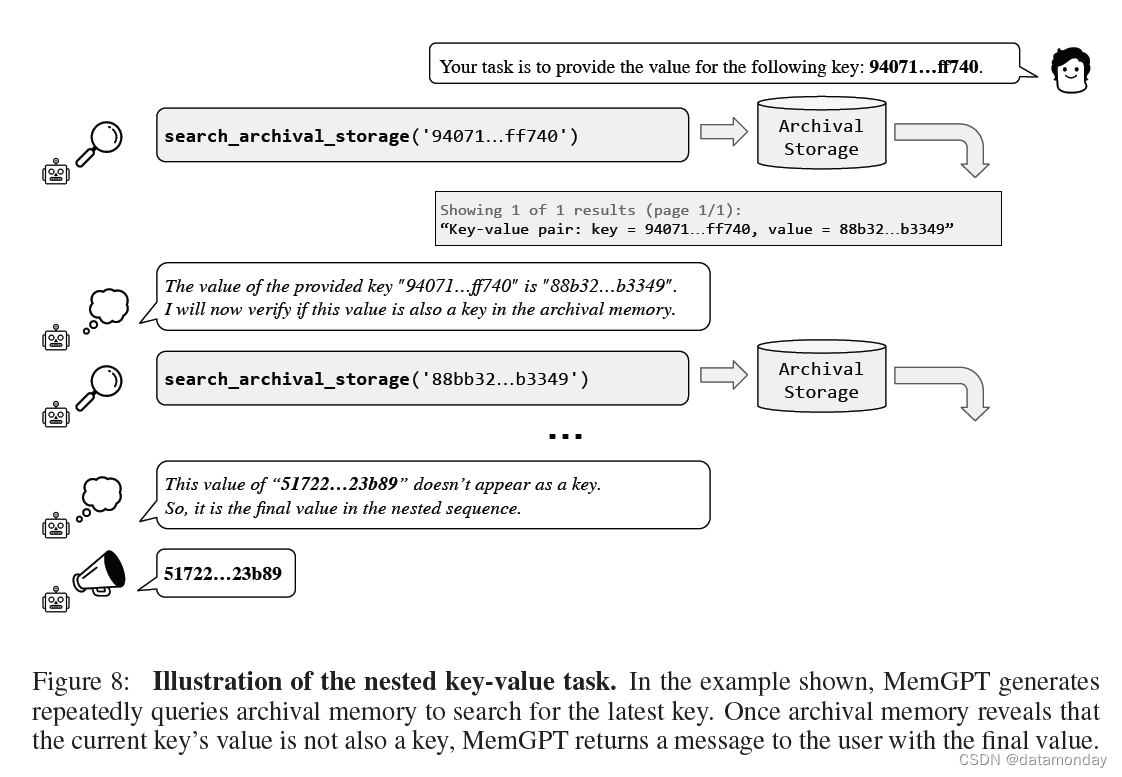
3.2.2 Nested Key-Value Retrieval (KV)
我们在先前工作(Liu 等人,2023a)中提出的合成键值检索(synthetic Key-Value retrieval)的基础上引入了一项新任务。这项任务的目标是展示 MemGPT 如何整理来自多个数据源的信息。在最初的 KV 任务中,作者生成了一个由键-值对组成的合成数据集,其中每个键和值都是 128 位 UUID(通用唯一标识符)。然后给智能体一个键,要求智能体返回键的相关值。我们创建了 KV 任务的一个版本–嵌套 KV 检索(nested KV retrieval),其中值本身可能就是键,因此需要智能体执行多跳查找(multi-hop lookup)。在我们的设置中,
- 我们将 UUID 对的总数固定为 140,大约相当于 8k 标记(GPT-4 基线的上下文长度)。
- 我们将嵌套层级的总数从 0(初始键值对的值不是键)到 4(即总共需要 4 次 KV 查找才能找到最终值)不等,并对 30 种不同的排序配置(包括初始键位置和嵌套键位置)进行了采样。
虽然 GPT-3.5 和 GPT-4 在原始 KV 任务中表现出色,但在嵌套 KV 任务中都很吃力。GPT-3.5 无法完成任务的嵌套变体,性能立即下降,在 1 个嵌套级别时准确率为 0%(我们观察到其主要失败模式是简单返回原始值)。GPT-4 优于 GPT-3.5,但也出现了类似的性能下降,在 4 个嵌套层时准确率为 0%。就 GPT-4 而言,我们观察到它经常无法超越特定嵌套层,而只是简单地返回前一嵌套层的嵌套值。而 MemGPT 则不受嵌套层数的影响,通过函数查询重复访问存储在主内存中的键值对,从而执行嵌套查找。MemGPT 在嵌套 KV 任务上的表现证明,它有能力结合多个查询来执行多跳查找。
4 Related Work
近期的研究工作包括:
- 改进每次调用 LLM 时可处理的上下文长度
- 改进检索增强生成(RAG)的搜索和检索
- 使用语言模型为交互式智能体提供动力
4.1 Long-Context LLMs
对于会话智能体而言,长上下文对于连贯和吸引人的对话至关重要,对于用于问题解答(QA)的 LLM 而言,长上下文对于证实和拼接来自不同来源的事实也至关重要。
- 解决固定长度上下文局限性的一种方法是递归总结(Wu 等人,2021a)。在递归总结中,LLM 通常会在一个滑动窗口中生成简洁的表述,以便将其纳入指定的标记长度内。这种总结过程本身是有损失的,可能会导致无意中丢失相关细节或微妙的细微差别。
- 鉴于上下文长度对许多基于 LLM 的应用的限制,人们对提高 LLM 处理较长序列的能力越来越感兴趣,如 Press 等人(2021 年);Guo 等人(2021 年);Dong 等人(2023 年);Beltagy 等人(2020 年)。
- MemGPT 利用并受益于上下文长度的改进,因为它可以在 MemGPT 的主存储器中存储更多信息(打个比方,随着 GPU 缓存的增大,处理器现在可以更快地完成计算,因为它可以从高缓存命中率中获益)。
4.2 Search and Retrieval
搜索和检索机制,尤其是**检索增强生成(retrieval-augmented generation,RAG)**范例,已被纳入对话智能体的任务中,从文档问题解答、客户支持,到更一般的娱乐聊天机器人,不一而足。这些机制通常利用外部数据库或内部对话日志来提供与上下文相关的回复。
- 例如,Lin 等人(2023 年)展示了如何在指令调整过程中训练检索器和 LLM,以提高文档召回率。
- 其他研究还包括独立优化检索器或 LLM 的研究:Ram 等人(2023 年);Borgeaud 等人(2022 年);Karpukhin 等人(2020 年);Lewis 等人(2020 年);Guu 等人(2020 年)。
- Trivedi 等人(2022 年)将检索与思维链推理交错使用,以改进多步骤问题解答。
在这项工作中,我们不考虑所使用的检索机制;在 MemGPT 中,各种检索机制可以轻松交换,甚至作为磁盘存储器的一部分进行组合。
4.3 LLMs as Agents
最近的研究探索了增强 LLM 的功能,使其在互动环境中充当智能体。
- Park 等人(2023 年)提议为 LLM 增加记忆,并将 LLM 用作规划器,他们在多智能体沙盒环境(受模拟人生视频游戏启发)中观察了新出现的社会行为,在该环境中,智能体可以执行基本活动,如做家务/爱好、上班以及与其他智能体对话。
- Nakano 等人(2021 年)训练模型在回答问题前进行网络搜索,并在他们的网络浏览环境中使用与 MemGPT 类似的分页概念来控制底层上下文的大小。
- Yao 等人(2022 年)的研究表明,交错思维链推理(Wei 等人,2022 年)能进一步提高基于 LLM 的交互式智能体的规划能力;与 MemGPT 类似,LLM 在执行函数时也能 “plan out loud”(示例见图 5 和图 8)。
- Liu 等人(2023b)推出了一套 LLM 即智能体基准(LLM-as-an-agent benchmarks),用于评估互动环境中的 LLM,包括视频游戏、思考谜题和网络购物。相比之下,我们的工作侧重于解决为智能体配备用户输入长期记忆的问题。
5 Concluding Remarks and Future Directions
在本文中,我们介绍了受操作系统启发而开发的新型 LLM 系统 MemGPT,它可以管理大型语言模型的有限上下文窗口。通过设计与传统操作系统类似的内存层次结构和控制流,MemGPT 为 LLM 提供了更大上下文资源的假象。在现有 LLM 性能受限于有限上下文长度的两个领域:文档分析和对话智能体中,对这种受操作系统启发的方法进行了评估。在文档分析方面,MemGPT 通过有效地将相关上下文分页进出内存,可以处理远远超出当前 LLM 上下文限制的冗长文本。在对话智能体方面,MemGPT 可以在长时间对话中保持长期记忆、一致性和可发展性。总之**,MemGPT 演示了分层内存管理和中断等操作系统技术,即使受到固定上下文长度的限制,也能释放 LLM 的潜力**。这项工作为未来的探索开辟了许多途径,包括将 MemGPT 应用于具有大规模或无限制上下文的其他领域,集成数据库或缓存等不同内存层技术,以及进一步改进控制流和内存管理策略。通过将操作系统架构的概念与人工智能系统相融合,MemGPT 代表了在基本限制范围内最大化 LLM 能力的一个很有前途的新方向。
5.1 Limitations
我们的参考实施利用了专门针对函数调用进行微调的 OpenAI GPT-4 模型。虽然 OpenAI 模型的内部工作原理是专有的,并未公开披露,但 OpenAI 的 API 文档指出,在使用函数微调模型时,所提供的函数模式会转换为系统消息,通过微调过程对模型进行解释训练。虽然针对函数调用进行了微调的 GPT 模型仍然需要解析器来验证输出是否为有效的函数语法,但我们观察到,GPT-4 函数微调模型很少在 MemGPT 函数集上出现语法或语义错误,而 GPT-3.5 微调模型则总是生成不正确的函数调用,或试图使用不正确的函数。同样,我们还发现,最流行的 Llama 2 70B 模型变体(即使是那些针对函数调用进行了微调的变体)也会持续生成错误的函数调用,甚至在所提供的模式之外产生幻觉。目前,只有使用专门的 GPT-4 模型才能实现合理的性能,不过,我们预计未来的开源模型最终会通过微调改进(例如,在更大的函数调用数据集或更专门的函数调用数据集上微调),提示工程或基础模型质量的提高,达到支持 MemGPT 运行的程度。尽管如此,就目前而言,依赖专有封闭源模型的性能仍然是这项工作的一大局限。






)
)




)


)



——select)