在课程的transformer视频中,李老师详细介绍了部分self-attention内容,但是self-attention其实还有各种各样的变化形式:

一、Self-attention运算存在的问题
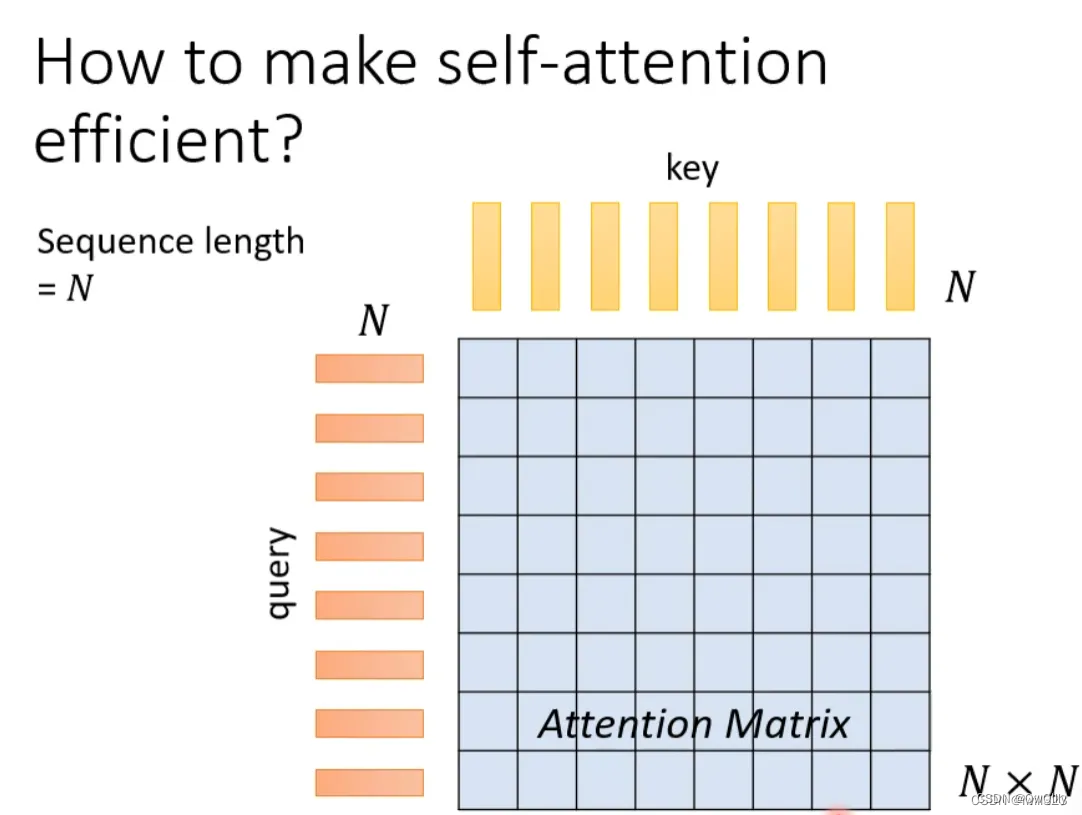
在self-attention中,假设输入序列(query)长度是N,为了捕捉每个value或者token之间的关系,需要产生N个key与之对应,并将query与key之间做dot-product,就可以产生一个Attention Matrix(注意力矩阵),维度N*N。
这种方式最大的问题:当序列长度太长的时候,对应的Attention Matrix维度太大,计算量太大。
对于transformer来说,self-attention只是大的网络架构中的一个module。由上述分析我们知道,对于self-attention的运算量是跟N的平方成正比的。当N很小的时候,单纯增加self-attention的运算效率可能并不会对整个网络的计算效率有太大的影响。因此,提高self-attention的计算效率从而大幅度提高整个网络的效率的前提是N特别大的时候,比如做图像识别(影像辨识、image processing)。
比如图片像素是256*256,每个像素当成一个单位,输入长度是256*256,self-attention的运算量正比于256*256的平方。

二、各种变形:加快self-attention的求解速度
根据上述分析可以知道,影响self-attention效率最大的一个问题就是Attention Matrix的计算。如果根据一些的知识或经验,选择性的计算Attention Matrix中的某些数值或者某些数值不需要计算就可以知道数值,理论上可以减小计算量,提高计算效率。
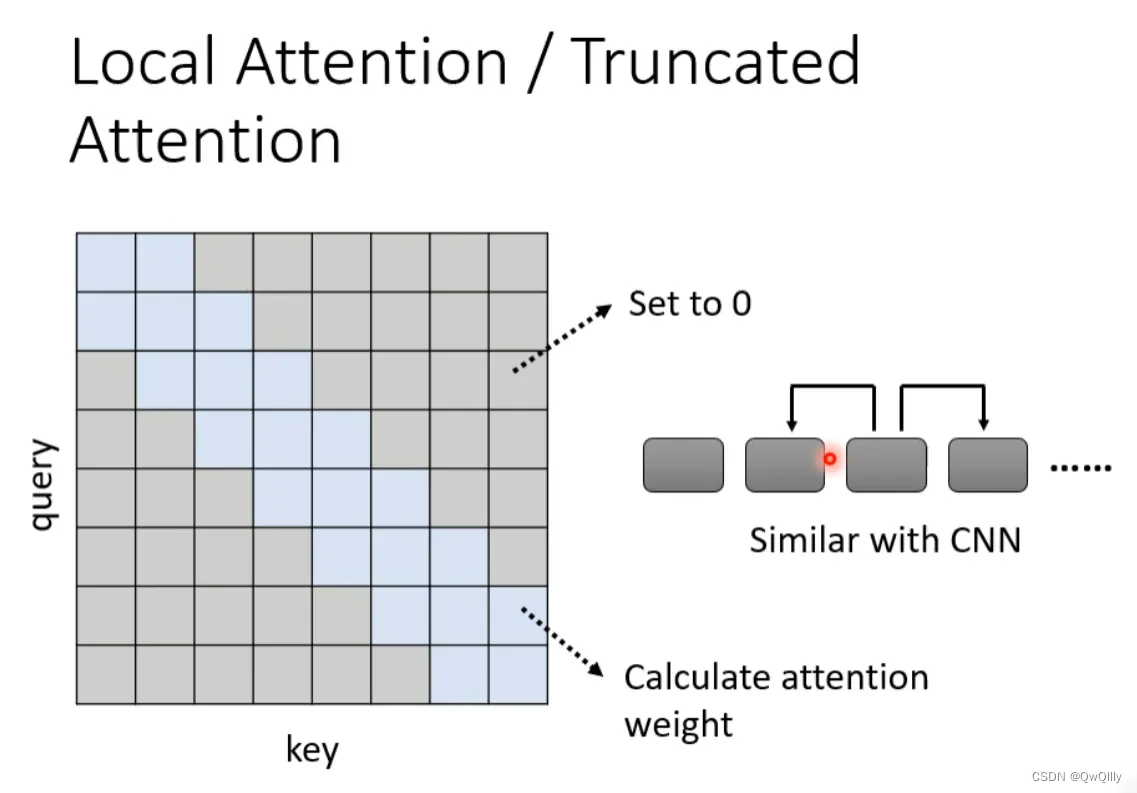
local attention
举个例子,比如在做文本翻译的时候,有时候在翻译当前的token时不需要给出整个sequence,其实只需要知道这个token左右的邻居,把较远处attention的数值设为0,就可以翻译的很准,也就是做局部的attention(local attention)。
优点:大大提升运算效率。
缺点:只关注周围局部的值,这样做法其实跟CNN没有太大区别,结果不一定非常好。
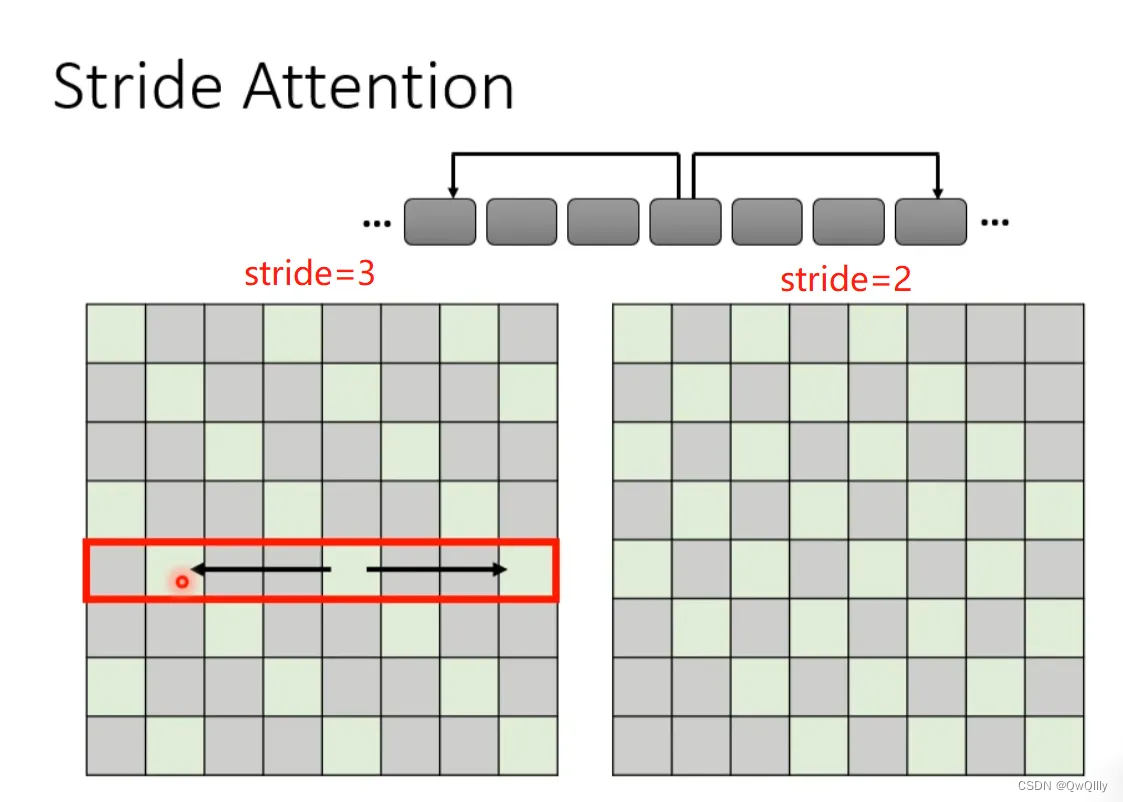
Stride Attention
如果觉得上述local attention不好,也可以换一种思路:在翻译当前token的时候,让他空一定间隔(stride)的左右邻居的信息,从而捕获当前与过去和未来的关系。stride的数值可以自己确定。
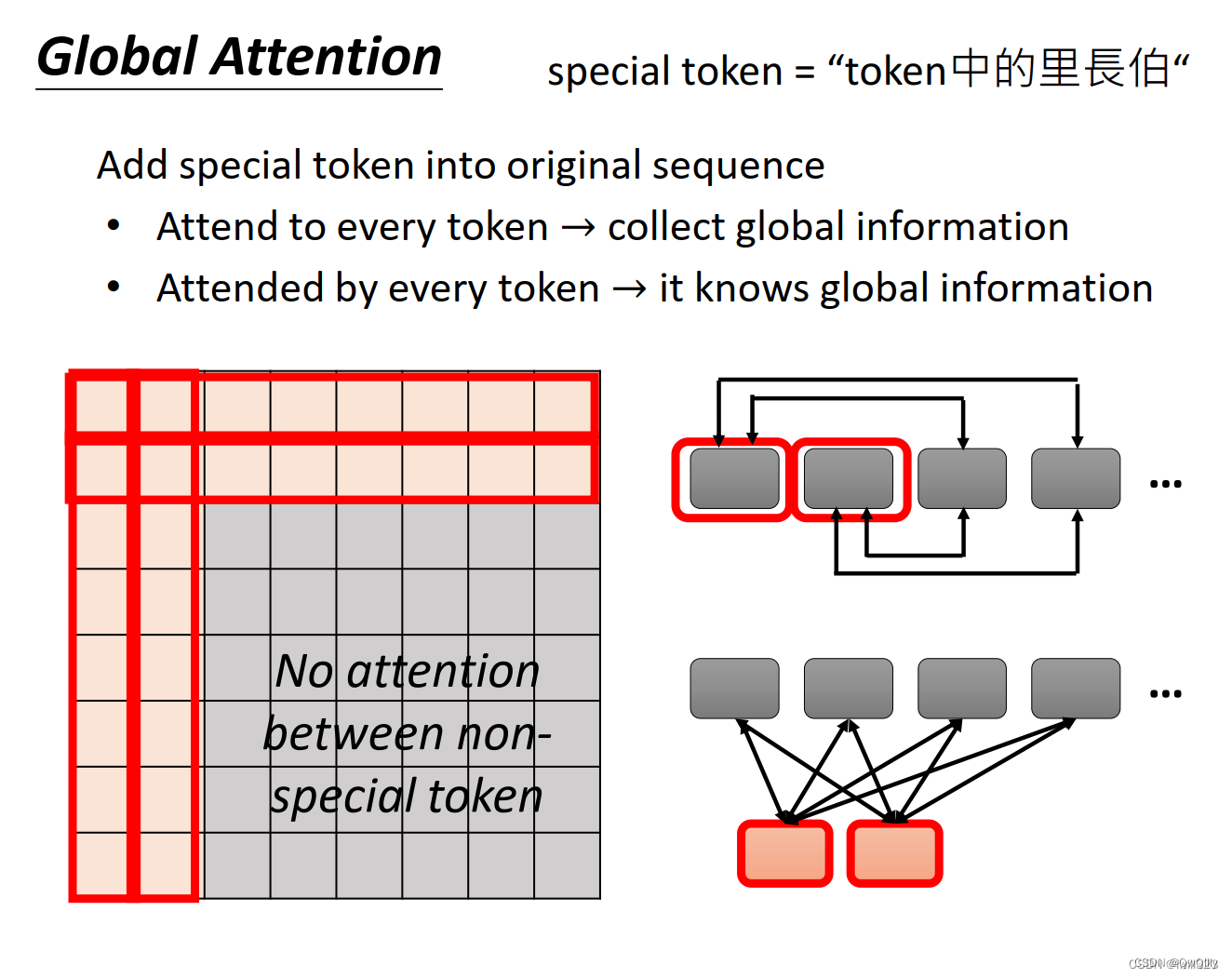
global attention
选择sequence中的某些token作为special token(比如开头的token,标点符号),或者在原始的sequence中增加special token。让special token与sequence里每一个token产生关系(Attend to every token和Attended by every token),但其他不是special token的token之间没有attention。
以在原始sequence头两个位置增加两个special token为例,只有前两行和前两列做attend计算。
Big Bird:综合运用
对于一个网络,有的head可以做local attention,有的head可以做stride attention,有的head可以做global attention。看下面几个例子:
Longformer就是组合了上面的三种attention
Big Bird就是在Longformer基础上随机选择attention赋值,进一步提高计算效率

Reformer:Clustering
上面几种方法都是人为设定的哪些地方需要算attention,哪些地方不需要算attention,但是这样算是最好的方法吗?并不一定。
对于Attention Matrix来说,如果某些位置值非常小,可以直接把这些位置置0,这样对实际预测的结果也不会有太大的影响。也就是说我们只需要找出Attention Matrix中attention的值相对较大的值。但是如何找出哪些位置的值非常小/非常大呢?
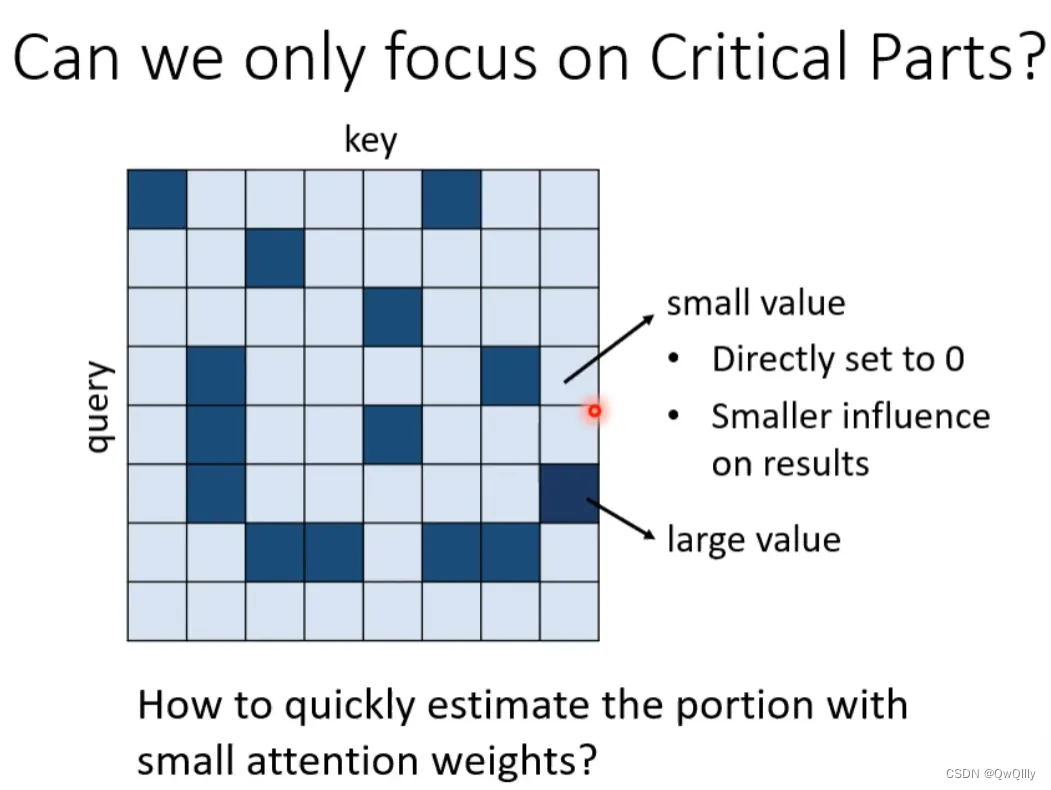
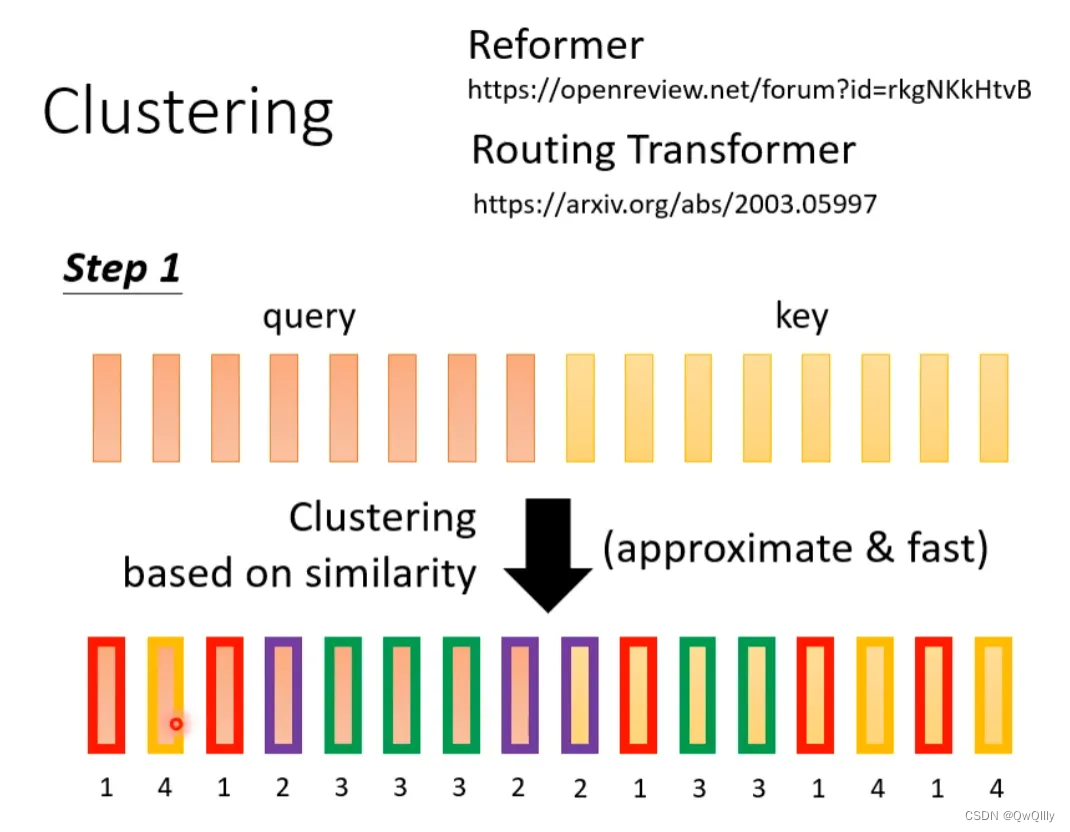
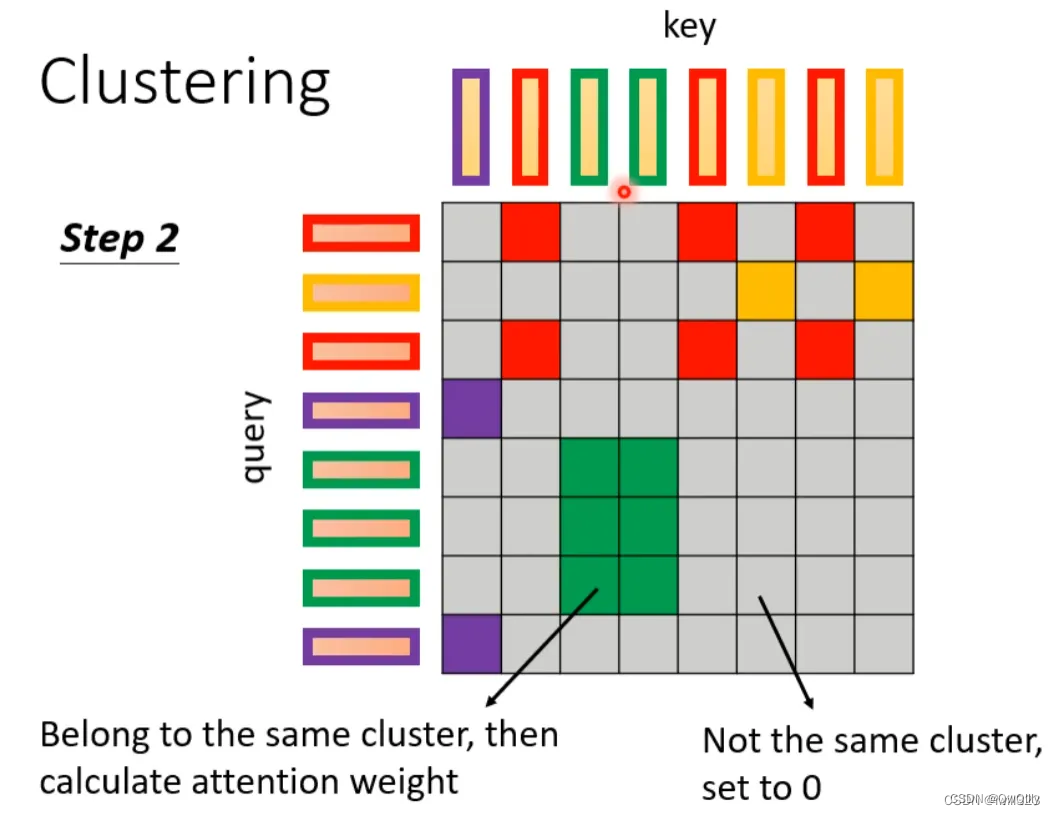
下面这两个文献中给出一种Clustering(聚类)的方案,即对query和key进行聚类,属于同一类的query和key来计算attention,不属于同一类的就不参与计算,这样就可以加快Attention Matrix的计算。比如下面这个例子中,分为4类:1(红框)、2(紫框)、3(绿框)、4(黄框)。在下面两个文献中介绍了可以快速粗略聚类的方法。
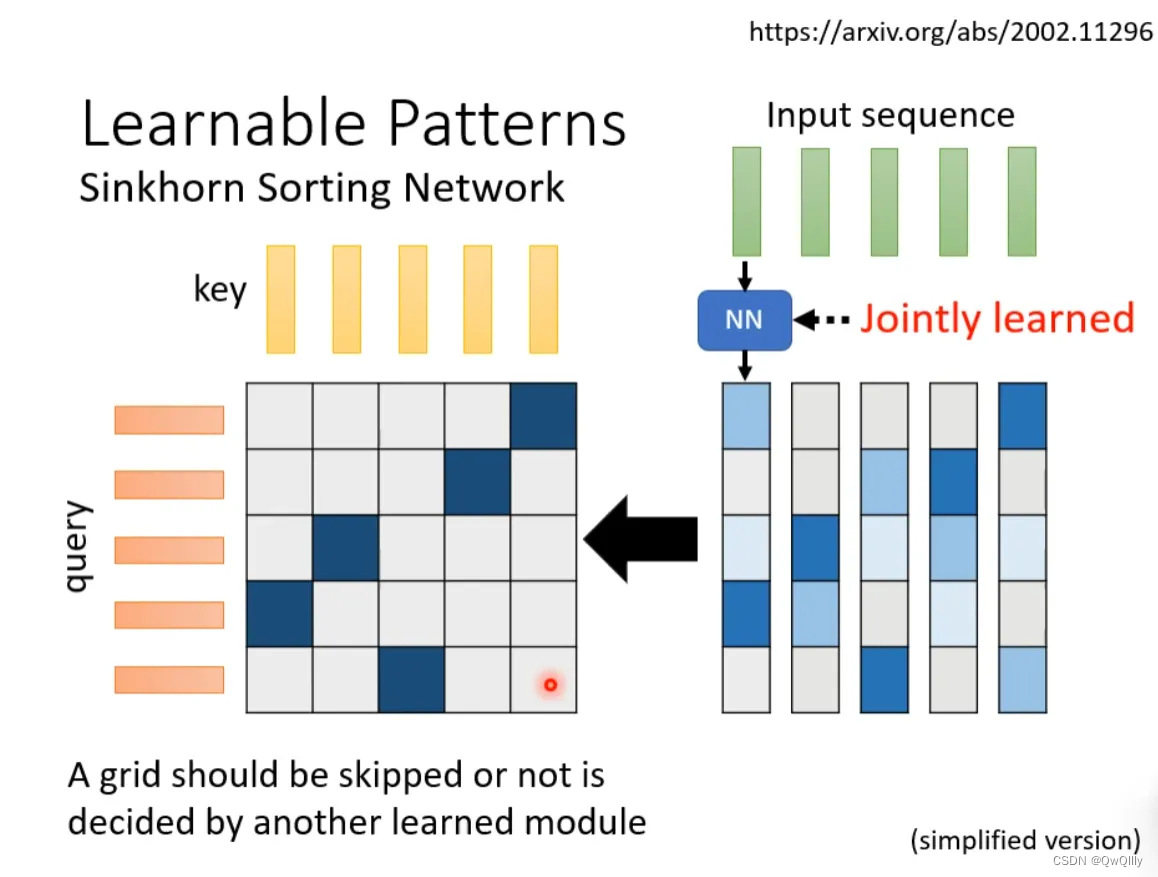
sinkhorn:Learnable Patterns
有没有一种将要不要算attention的事情用learn的方式学习出来呢?有可能的。可以再训练一个网络,输入是input sequence,输出是相同长度的weight sequence(N*N),将所有weight sequence拼接起来,再经过转换,就可以得到一个矩阵,值只有1和0,指明哪些地方需要算attention,哪些地方不需要算attention。该网络和其他网络一起被学出来。
有一个细节是:某些不同的sequence可能经过NN输出后共用同一个weight sequence,这样可以大大减小计算量。
Linformer:减少key数目
上述我们所讲的都是N*N的Matrix,但是实际来说,这样的Matrix通常来说并不是满秩的,一些列是其他列的线性组合,也就是说我们可以对原始N*N的矩阵降维,将重复的column去掉,得到一个比较小的Matrix。

具体来说,从N个key中选出K个具有代表的key,跟query做点乘,得到Attention Matrix。从N个value vector中选出K个具有代表的value,Attention Matrix的每一行对这K个value做weighted sum,得到self-attention模型的输出。
为什么选有代表性的key不选有代表性的query呢?因为query跟output是对应的,这样output就会缩短从而损失信息。

怎么选出有代表性的key呢?这里介绍两种方法,一种是直接对key做卷积(conv),一种是对key跟一个矩阵做矩阵乘法,就是将key矩阵的列做不同的线性组合。

Linear Transformer和Performer:另一种方式计算
回顾一下注意力机制的计算过程,其中I为输入矩阵,O为输出矩阵。
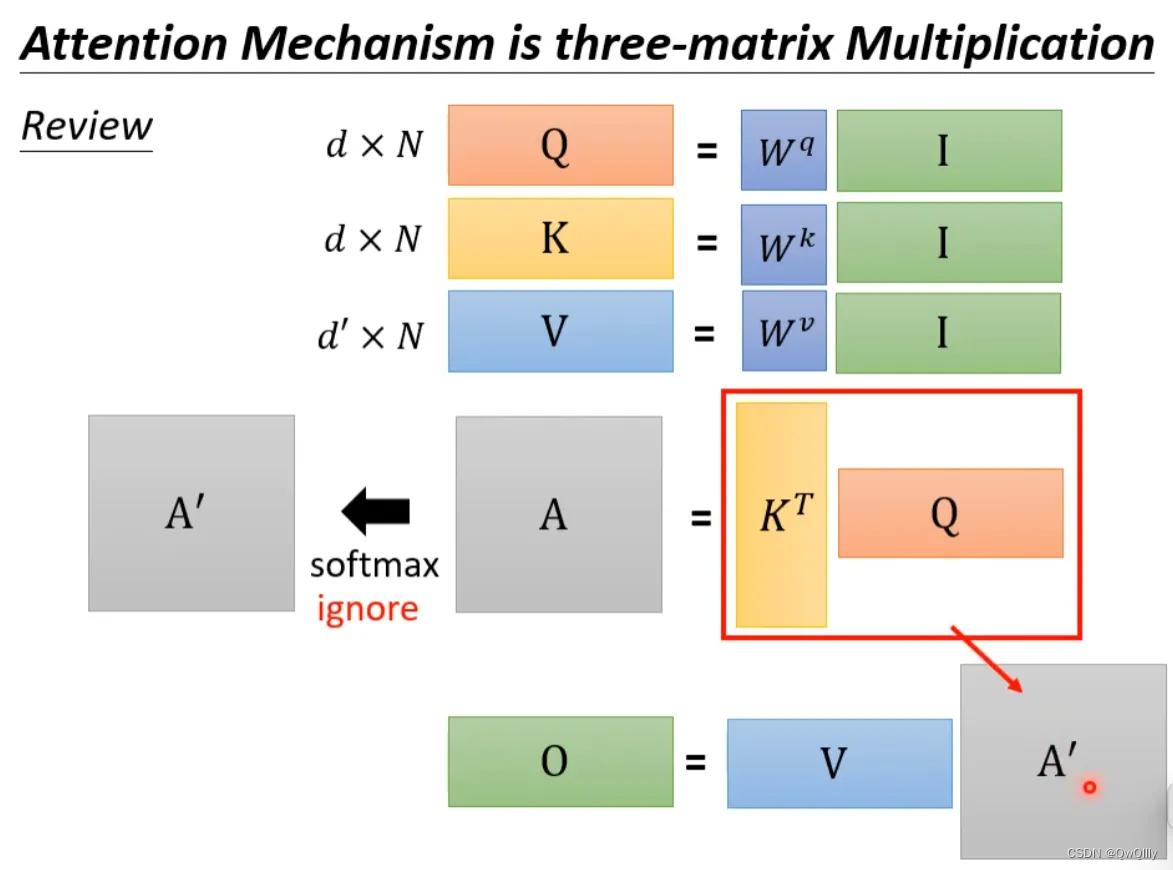
先忽略softmax,那么可以化成如下表示形式:

上述过程是可以加速的。如果先V*K^T,再乘Q的话,相比于K^T*Q,再乘V结果是相同的,但是计算量会大幅度减少。
附:线性代数关于这部分的说明

还是对上面的例子进行说明。K^T*Q会执行N*d*N次乘法,V*A会再执行d'*N*N次乘法,那么一共需要执行的计算量是(d+d')N^2。

V*K^T会执行d'*N*d次乘法,再乘以Q会执行d'*d*N次乘法,所以总共需要执行的计算量是2*d'*d*N。
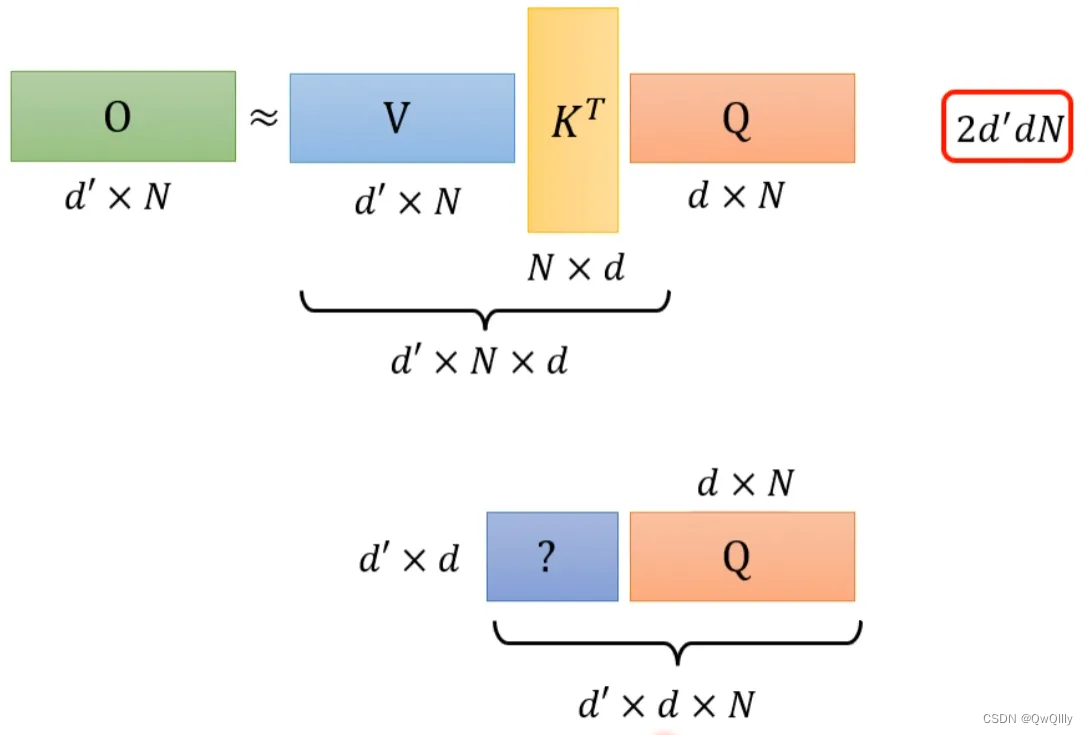
而(d+d')N^2>>2*d'*d*N,所以通过改变运算顺序就可以大幅度提升运算效率。
现在我们把softmax拿回来。原来的self-attention是这个样子,以计算b1为例:
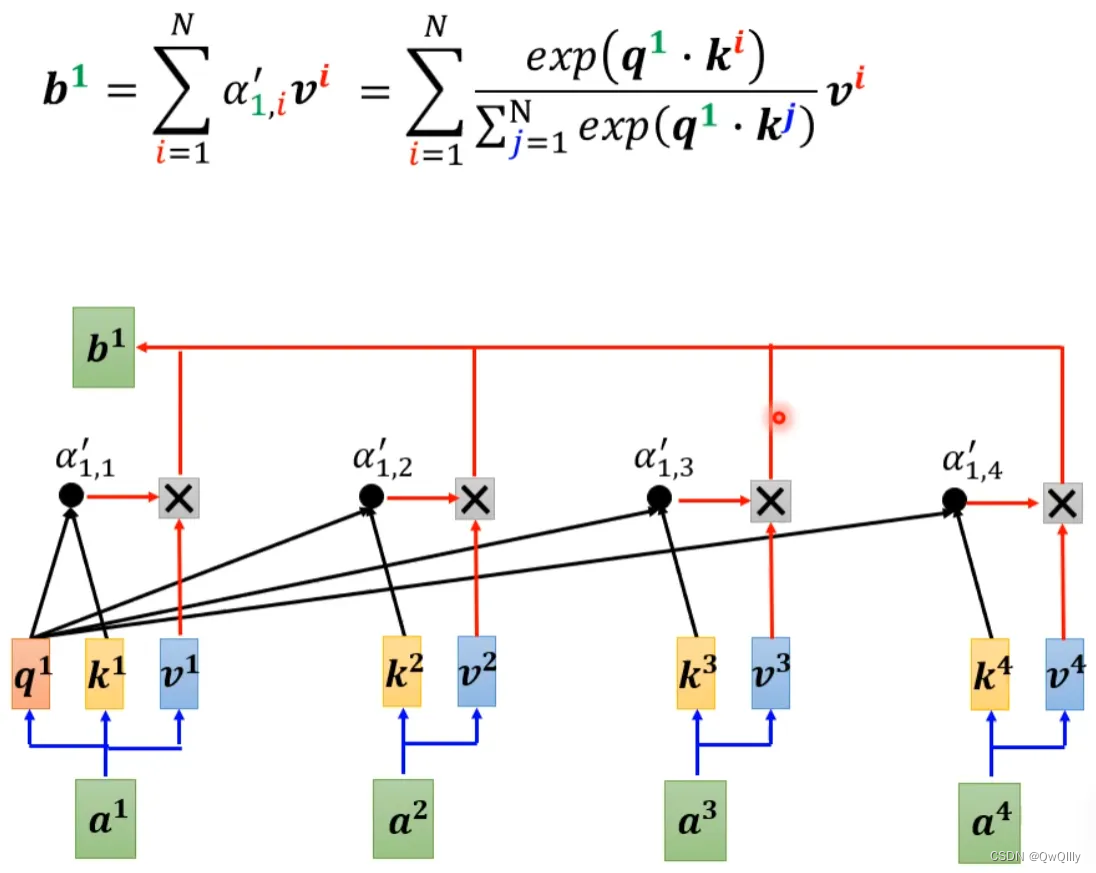
可以将exp(q*k)转换成两个映射相乘的形式,对上式进行进一步简化:
分母化简
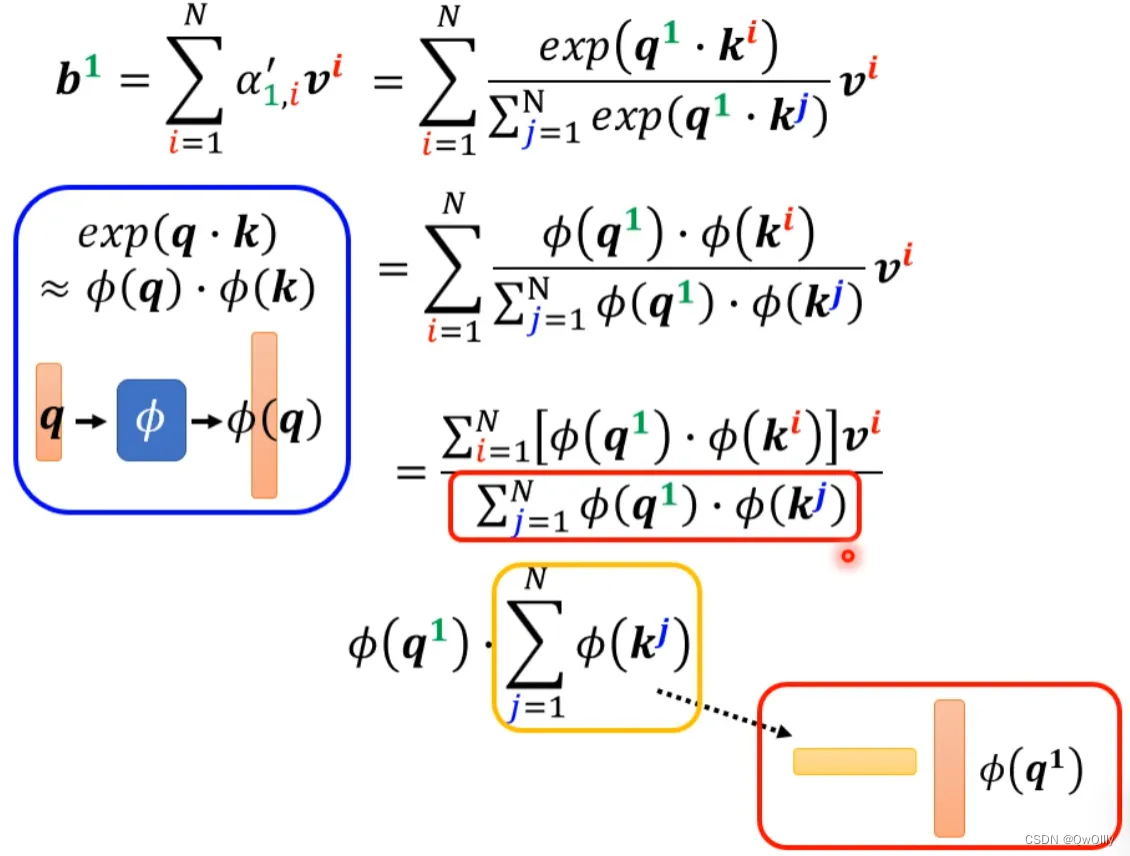
分子化简

将括号里面的东西当做一个向量,M个向量组成M维的矩阵,在乘以φ(q1),得到分子。

用图形化表示如下:
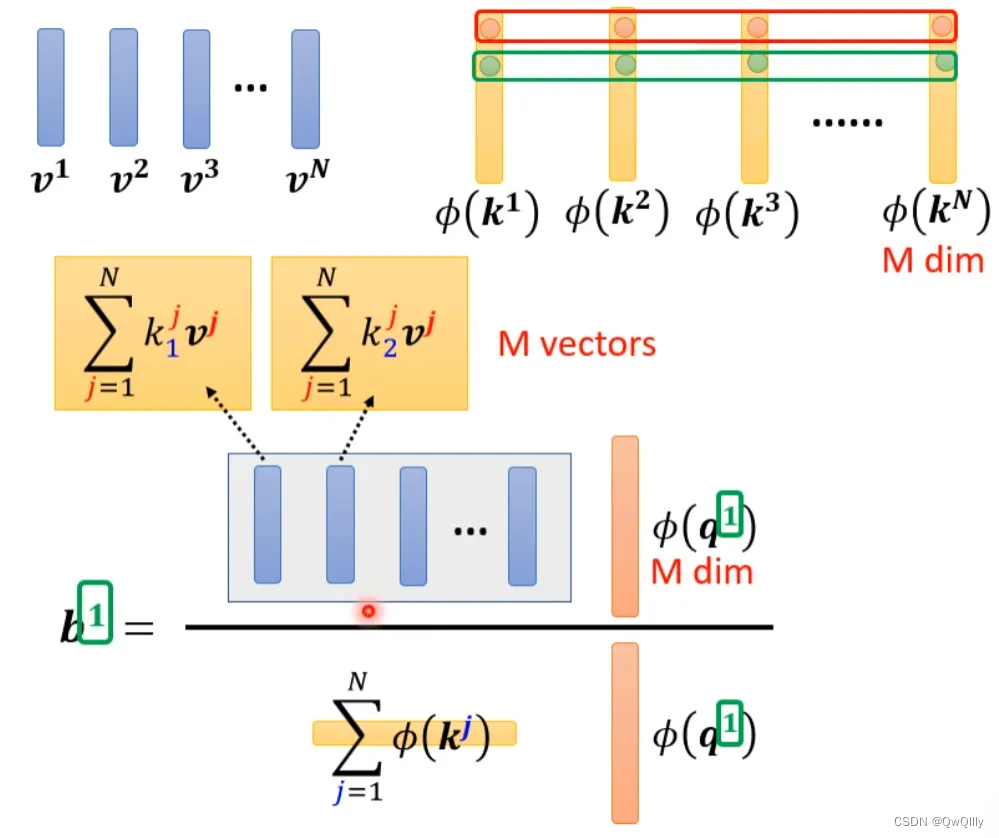
由上面可以看出蓝色的vector和黄色的vector其实跟b1中的1是没有关系的。也就是说,当我们算b2、b3...时,蓝色的vector和黄色的vector不需要再重复计算。

self-attention还可以用另一种方法来看待。这个计算的方法跟原来的self-attention计算出的结果几乎一样,但是运算量会大幅度减少。简单来说,先找到一个转换的方式φ(),对k进行转换得到M维向量φ(k),然后φ(k)跟v做weighted sum点乘得到M vectors。再对q做转换,φ(q)每个元素跟M vectors做weighted sum点乘,得到一个向量,即是b的分子。
其中M维的vector只需要计算一次。
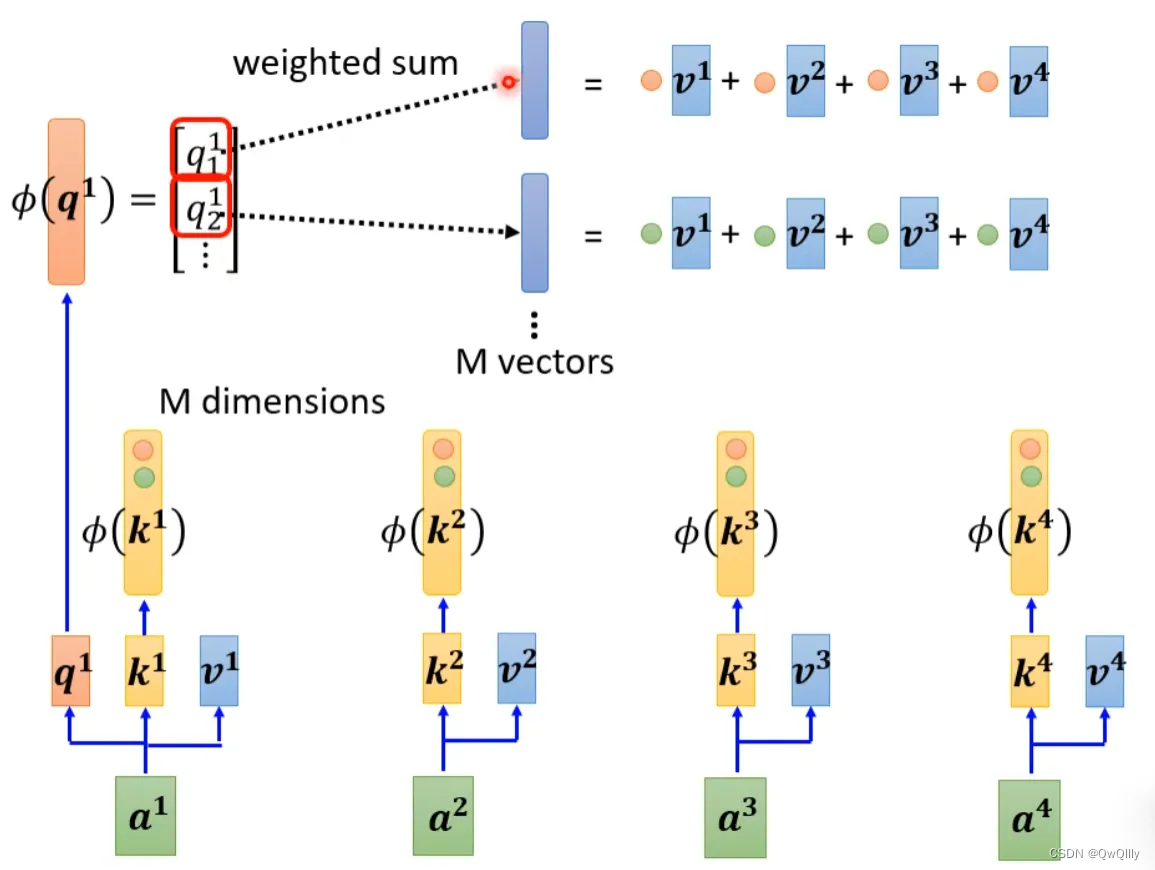
b1计算如下:

对于不同b,M vectors只需要计算一次。这种方式运算量会大幅度减少,计算结果一样的计算方法。
b2计算如下:

可以这样去理解,sequence每一个位置都产生v,对这些v做线性组合得到M个template(模板),然后通过φ(q)去寻找哪个template是最重要的(模板的线性组合),并进行矩阵的运算,得到输出b。
那么φ到底如何选择呢?不同的文献有不同的做法:

Synthesizer:attention matrix通过学习得到
在计算self-attention的时候一定需要q和k吗?不一定。
在Synthesizer文献里面,对于attention matrix不是通过q和k计算得到的,而是作为网络参数学习得到。虽然不同的input sequence对应的attention weight是一样的,但是performance不会变差太多。其实这也引发一个思考,attention的价值到底是什么?

使用其他网络:不用attention
处理sequence一定要用attention吗?可不可以尝试把attention丢掉?有没有attention-free的方法?下面有几个用mlp的方法用于代替attention来处理sequence。
用mlp的方法用于代替attention来处理sequence。
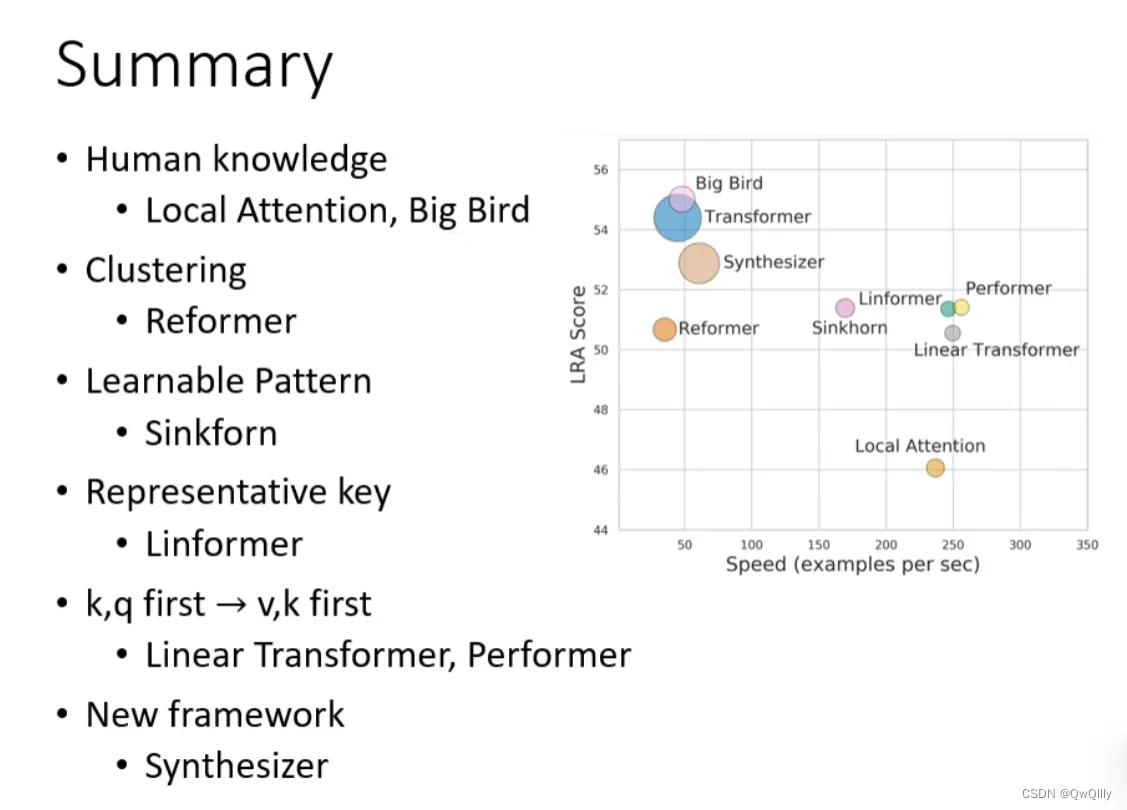
三、总结
最后这页图为今天所有讲述的方法的总结。下图中,纵轴的LRA score数值越大,网络表现越好;横轴表示每秒可以处理多少sequence,越往右速度越快;圈圈越大,代表用到的memory越多(计算量越大)。









:实现顶部导航栏功能:导航栏静态搭建,菜单折叠功能实现,面包屑动态展示路径,刷新页面功能,全屏功能)
(哈希函数、哈希算法)(将任意长度的消息变成固定长度的短消息))




|LeetCode93. 复原 IP 地址、LeetCode78. 子集、LeetCode90. 子集 II)



