前言
NOTE:本文中所指 “线程” 均为可执行调度单元 Kernel Thread。
NUMA 体系结构
NUMA(Non-Uniform Memory Access,非一致性存储器访问)的设计理念是将 CPU 和 Main Memory 进行分区自治(Local NUMA node),又可以跨区合作(Remote NUMA node),以这样的方式来缓解单一内存总线存在的瓶颈。

这里写图片描述
不同的 NUMA node 都拥有几乎相等的资源,在 Local NUMA node 内部会通过自己的存储总线访问 Local Memory,而 Remote NUMA node 则可以通过主板上的共享总线来访问其他 Node 上的 Remote Memory。
显然的,CPU 访问 Local Memory 和 Remote Memory 所需要的耗时是不一样的,所以 NUMA 才得名为 “非一致性存储器访问"。同时,因为 NUMA 并非真正意义上的存储隔离,所以 NUMA 同样只会保存一份操作系统和数据库系统的副本。也就是说,默认情况下,耗时的远程访问是很可能存在的。
这种做法使得 NUMA 具有一定的伸缩性,更加适合应用在服务器端。但也由于 NUMA 没有实现彻底的主存隔离,所以 NUMA 的扩展性也是有限的,最多可支持几百个 CPU/Core。这是为了追求更高的并发性能所作出的妥协。

这里写图片描述
基本对象概念
- Node(节点):一个 Node 可以包含若干个 Socket,通常是一个。
- Socket(插槽):一颗物理处理器 SoC 的封装。
- Core(核心):一个 Socket 封装的若干个物理处理器核心(Physical processor)。
- Hyper-Thread(超线程):每个 Core 可以被虚拟为若干个(通常为 2 个)逻辑处理器(Virtual processors)。逻辑处理器会共享大多数物理处理器资源(e.g. 内存缓存、功能单元)。
- Processor(逻辑处理器):操作系统层面的 CPU 逻辑处理器对象。
- Siblings:操作系统层面的 Physical processor 和下属 Virtual processors 之间的从属关系。
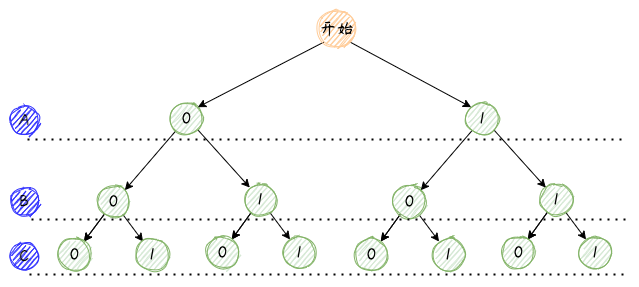
下图所示为一个 NUMA Topology,表示该服务器具有 2 个 Node,每个 Node 含有一个 Socket,每个 Socket 含有 6 个 Core,每个 Core 又被超线程为 2 个 Thread,所以服务器总共的 Processor = 2 x 1 x 6 x 2 = 24 颗,其中 Siblings[0] = [cpu0, cpu1]。

这里写图片描述
查看 Host 的 NUMA Topology
#!/usr/bin/env python
# SPDX-License-Identifier: BSD-3-Clause
# Copyright(c) 2010-2014 Intel Corporation
# Copyright(c) 2017 Cavium, Inc. All rights reserved.from __future__ import print_function
import sys
try:xrange # Python 2
except NameError:xrange = range # Python 3sockets = []
cores = []
core_map = {}
base_path = "/sys/devices/system/cpu"
fd = open("{}/kernel_max".format(base_path))
max_cpus = int(fd.read())
fd.close()
for cpu in xrange(max_cpus + 1):try:fd = open("{}/cpu{}/topology/core_id".format(base_path, cpu))except IOError:continueexcept:breakcore = int(fd.read())fd.close()fd = open("{}/cpu{}/topology/physical_package_id".format(base_path, cpu))socket = int(fd.read())fd.close()if core not in cores:cores.append(core)if socket not in sockets:sockets.append(socket)key = (socket, core)if key not in core_map:core_map[key] = []core_map[key].append(cpu)print(format("=" * (47 + len(base_path))))
print("Core and Socket Information (as reported by '{}')".format(base_path))
print("{}\n".format("=" * (47 + len(base_path))))
print("cores = ", cores)
print("sockets = ", sockets)
print("")max_processor_len = len(str(len(cores) * len(sockets) * 2 - 1))
max_thread_count = len(list(core_map.values())[0])
max_core_map_len = (max_processor_len * max_thread_count) \+ len(", ") * (max_thread_count - 1) \+ len('[]') + len('Socket ')
max_core_id_len = len(str(max(cores)))output = " ".ljust(max_core_id_len + len('Core '))
for s in sockets:output += " Socket %s" % str(s).ljust(max_core_map_len - len('Socket '))
print(output)output = " ".ljust(max_core_id_len + len('Core '))
for s in sockets:output += " --------".ljust(max_core_map_len)output += " "
print(output)for c in cores:output = "Core %s" % str(c).ljust(max_core_id_len)for s in sockets:if (s,c) in core_map:output += " " + str(core_map[(s, c)]).ljust(max_core_map_len)else:output += " " * (max_core_map_len + 1)print(output)
OUTPUT:
$ python cpu_topo.py
======================================================================
Core and Socket Information (as reported by '/sys/devices/system/cpu')
======================================================================cores = [0, 1, 2, 3, 4, 5]
sockets = [0, 1]Socket 0 Socket 1-------- --------
Core 0 [0] [6]
Core 1 [1] [7]
Core 2 [2] [8]
Core 3 [3] [9]
Core 4 [4] [10]
Core 5 [5] [11]
上述输出的意义:
- 有两个 Socket(物理 CPU)
- 每个 Socket 有 6 个 Core(物理核),总计 12 个
Output:
$ python cpu_topo.py
======================================================================
Core and Socket Information (as reported by '/sys/devices/system/cpu')
======================================================================cores = [0, 1, 2, 3, 4, 5]
sockets = [0, 1]Socket 0 Socket 1-------- --------
Core 0 [0, 12] [6, 18]
Core 1 [1, 13] [7, 19]
Core 2 [2, 14] [8, 20]
Core 3 [3, 15] [9, 21]
Core 4 [4, 16] [10, 22]
Core 5 [5, 17] [11, 23]
- 有两个 Socket(物理 CPU)。
- 每个 Socket 有 6 个 Core(物理核),总计 12 个。
- 每个 Core 有两个 Virtual Processor,总计 24 个。
NUMA 架构中的多线程性能开销
1、跨 Node 的 Memory 访问开销
NUMA(非一致性存储器访问)的意思是 Kernel Thread 访问 Local Memory 和 Remote Memory 所需要的耗时是不一样的。
NUMA 的 CPU 分配策略有下 2 种:
- cpu-node-bind:约束 Kernel Thread 运行在指定的若干个 NUMA Node 上。
- phys-cpu-bind:约束 Kernel Thread 运行在指定的若干个 CPU Core 上。
NUMA 的 Memory 分配策略有下列 4 种:
- local-alloc:约束 Kernel Thread 只能访问 Local Node Memory。
- preferred:宽松地为 Kernel Thread 指定一个优先 Node,如果优先 Node 上没有足够的 Memory 资源,则允许运行在访问 Remote Node Memory。
- mem-bind:规定 Kernel Thread 只能请求指定的若干个 Node 上的 Memory,但并不严格规定只能访问 Local NUMA Memory。
- inter-leave:规定 Kernel Thread 可以使用 RR 算法轮转地从指定的若干个 Node 上请求访问 Memory。
2、跨 Core 的多线程 Cache 同步开销
NUMA Domain Scheduler 是 Kernel 针对 NUMA 体系架构实现的 Kernel Thread 调度器,目的是为了让 NUMA 中的每个 Core 都尽量均衡的忙碌。
根据 NUMA Topology 的特性呈一颗树状结构。NUMA Domain Scheduling,从叶节点向上根节点遍历,直到所有的 NUMA Domain 中的负载都是均衡的。当然,用户可以对不同的 Domain 设置相应的调度策略。

这里写图片描述
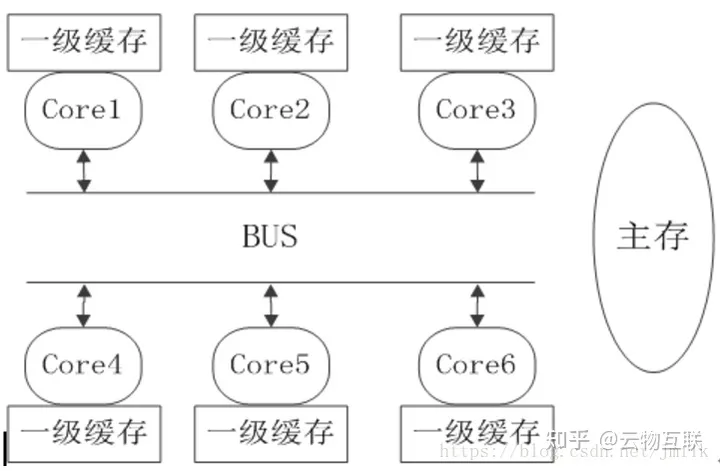
但这种针对所有 Cores 的均衡优化是有代价的,比如:将同一个 User Process 对应若干个 Kernel Thread 均衡到不同的 Cores 上执行,会使得 Core Cache 失效,造成性能下降。
- Cache 可见性(并发安全)问题:分别在 Core1 和 Core2 上运行的 Kernel Thread 都会在各自的 L1/L2 Cache 中缓存数据,但这些数据对彼此是不可见的,即:如果在 Core1 不将 Cache 中的数据写回到 Main Memory 的前提下,Core2 永远看不见 Core1 对某个变量数值的修改。继而会导致多线程共享数据不一致的情况。
- Cache 一致性(并发性能)问题:如果多个 Kernel Thread 运行在多个 Cores 上,同时这些 Threads 之间存在共享数据,而这些数据有存储在 Cache 中,那么就存在 Cache 一致性数据同步的必要。例如:分别在 Core1 和 Core2 上运行的 Kernel Thread 希望保证共享数据是一致的,那么就需要强制性的将 Core1 Cache 中对变量数值的修改写回到 Main Memory,然后 Core1 通知 Core2 数值更新了,再让 Core2 从 Main Memory 获取到最新的数值,并加载到 Core2 Cache 中。为了维护 Cache 数据的一致性所产生的流量会为主存数据总线带来压力,继而影响到 CPU 的性能。
- Cache 失效性(并发性能)问题:如果出于均衡的考虑,调度器会主动出发线程切换,例如:将在 Core1 上运行的 Kernel Thread 动态的调度到另一个空闲的 Core2 上运行,那么在 Core1 Cache 上的数据就需要先写回到 Memory,然后再进行调度。如果此时 Core1 和 Core2 分属于不同的 NUMA Node,那么就会出现更加耗时的 Remote Memory 访问。
在这里插入图片描述
如下图所示,在不同的 Domain 中存在着不同的 Cache 成本。虽然 NUMA Domain Scheduling 自身也具有软亲和特性,但其到底是侧重于 NUMA Cores 的均衡调度,而不是保证应用程序的执行性能。
可见,NUMA Domain Scheduler 的均衡调度机制和高并发性能是相悖的。

这里写图片描述
3、多线程上下文切换开销
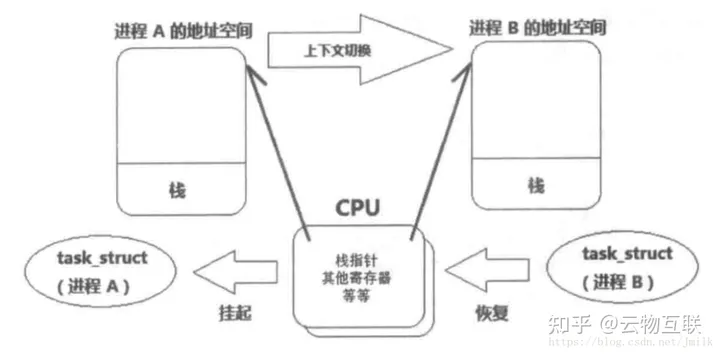
在 Core 执行任务期间,需要将线程的执行现场信息存储在 Core 的 Register 和 Cache 中,这些数据集称为 Context(上下文),有下列 3 种类型:
- User Level Context:PC 程序计数器、寄存器、线程栈等。
- Register Context:通用寄存器、PC 程序寄存器、处理器状态寄存器、栈指针等。
- Kernel Level Context:进程描述符(task_struct)、PC 程序计数器、寄存器、虚拟地址空间等。
多线程的 Context Switch(上下文切换)也可以分为 2 个层面:
- User Level Thread 层面:由高级编程语言线程库实现的 Multiple User Threads,在单一个 Core 上进行时间分片轮训被动切换,或协作式自动切换。由于 User Thread 的 User Level Context 非常轻量,且共享同一个 User Process 的虚拟地址空间,所以 User Level 层面的 Context Switch 开销小,速度快。
- Kernel Level Thread 层面:Multiple Kernel Threads 由 Kernel 中的 NUMA Domain Scheduler 在多个 Cores 上进行调度和切换。由于 Kernel Thread 的 Context 更大(Kernel Thread 执行现场,包括:task_struct 结构体、寄存器、程序计数器、线程栈等),且涉及跨 Cores 之间的数据同步和主存访问,所以 Kernel Level 层面的 Context Switch 开销大,速度慢。
进行线程切换的过程中,首先会将一个线程的 Context 存储在相应的用户或内核堆栈中,然后把下一个要运行的线程的 Context 加载到 Core 的 Register 和 Cache 中。
这里写图片描述
可见,多线程的 Context Switch 势必会导致处理器性能的下降。并且 User Level 和 Kernel Level 切换很可能是同时出现的,这些都是应用多线程模式所需要付出的代价。
使用 vmstat 指令查看当前系统的上下文切换情况:
$ vmstat
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----r b swpd free buff cache si so bi bo in cs us sy id wa st4 1 0 4505784 313592 7224876 0 0 0 23 1 2 2 1 94 3 0
- r:CPU 运行队列的长度和正在运行的线程数。
- b:正在阻塞的进程数。
- swpd:虚拟内存已使用的大小,如果大于 0,表示机器的物理内存不足了。如果不是程序内存泄露的原因,那么就应该升级内存或者把耗内存的任务迁移到其他机器上了。
- si:每秒从磁盘读入虚拟内存的大小,如果大于 0,表示物理内存不足或存在内存泄露,应该杀掉或迁移耗内存大的进程。
- so:每秒虚拟内存写入磁盘的大小,如果大于 0,同上。
- bi:块设备每秒接收的块数量,这里的块设备是指系统上所有的磁盘和其他块设备,默认块大小是 1024Byte。
- bo:块设备每秒发送的块数量,例如读取文件时,bo 就会大于 0。bi 和 bo 一般都要接近 0,不然就是 I/O 过于频繁,需要调整。
- in:每秒 CPU 中断的次数,包括时间中断。
- cs:每秒上下文切换的次数,这个值要越小越好,太大了,要考虑减少线程或者进程的数目。上下文切换次数过多表示 CPU 的大部分时间都浪费在上下文切换了而不是在执行任务。
- st:CPU 在虚拟化环境上在其他租户上的开销。
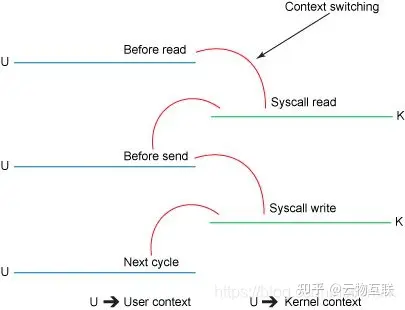
4、CPU 运行模式切换开销
CPU 运行模式切换同样会对执行性能造成影响,不过相对于上下文切换会更低一些,因为模式切换最主要的任务只是切换线程寄存器的上下文。
Linux 系统中的以下操作会触发 CPU 运行模式切换:
- 系统调用 / 软中断:当应用程序需要访问 Kernel 资源时,需要通过 SCI 进入内核模式执行相应的内核代码,完成所需操作后再返回到用户模式。
- 中断处理:当外设发生中断事件时,会向 CPU 发出中断信号,此时 Kernel 需要立即响应中断,进入内核模式执行相应的中断处理程序,处理完后再返回用户模式。
- 异常处理:当 Kernel 出现运行时错误或其他异常情况,如:页错误、除零错误、非法操作等,操作系统需要进入内核模式执行相应的异常处理程序,进行错误恢复或提示,然后再返回用户模式。
- Kernel Thread 切换:当 User Process 下属的 Kernel Thread 进行切换时,首先需要切换相应的 Kernel Level Context 并执行,最后再返回用户模式下执行 User Process 的代码。
在这里插入图片描述
5、中断处理的开销
硬件中断(HW Interrupt)是一种外设(e.g. 网卡、磁盘控制器、鼠键、串行适配卡等)和 CPU 交互通信的机制,让 CPU 能够及时掌握外设发生的事件,并视乎于中断的类型来决定是否放下当前任务,尽快处理紧急的外设事件(e.g. 以太网数据帧到达,键盘输入)。
硬件中断的本质是一个 IRQ(中断请求信号)电信号。Kernel 为每个外设分配了一个 IRQ Number,以此来区分发出中断的设备类型。IRQ Number 又会映射到 Kernel ISR(中断服务路由列表)中的一个中断处理程序(通常又外设驱动提供)。
硬件中断是 Kernel 调度优先级最高的任务类型之一,进行抢占式调度,所以硬件中断通常都伴随着任务切换,将当前任务切换到中断处理程序的上下文。
一次中断处理,首先需要将 CPU 的状态寄存器数据保存到虚拟内存空间中的堆栈,然后运行中断服务程序,最后再将状态寄存器数据从堆栈中夹在到 CPU。整个过程需要至少 300 个 CPU 时钟周期。并且在多核处理器计算平台中,每个 Core 都有可能执行硬件中断处理程序,所以还存在着跨 Core 处理要面对的 Cache 一致性流量的问题。
可见,大量的中断处理,尤其是硬件中断处理会非常消耗 CPU 资源。
6、TLB 缓存失效的开销
因为 TLB(地址映射表高速缓存)的空间非常有限,在使用 4K 小页的操作系统中,出现 Kernel Thread 频繁切换时,会导致 TLB 缓存的虚拟地址空间映射条目频繁变更,产生大量的缓存缺失。
7、内存拷贝的开销
在网络报文处理场景中,NIC Driver 运行在内核态,当 Driver 收到的报文后,首先会拷贝到 TCP/IP Stack 处理,然后再拷贝到用户空间的应用程序缓冲区。这些拷贝处理的时间会占报文处理总时长的 57.1%。
NUMA 架构中的性能优化:使用多核编程代替多线程
为了解决上述问题,在 NUMA 架构中进一步提升多核处理器平台的性能,应该广泛采用 “多核编程代替多线程编程” 的思想,通过将 Kernel Threrad 与 NUMA Node 或 Core 建立亲和性,以此来避免多线程调度带来的开销。
NUMA 亲和性:避免 CPU 跨 NUMA 访问内存
在 Linux Shell 上,可以使用 numastat 指令来查看 NUMA Node 的内存分配统计数据;可以使用 numactl 指令可以将 User Process 绑定到指定的 NUMA Node,还可以绑定到指定的 NUMA Core 上。
CPU 亲和性:避免跨 CPU Cores 的 Kernel Thread 切换
CPU 亲和性(CPU Affinity)是 Kernel 的一种 Kernel Thread 调度属性(Scheduling Property),指定 Kernel Thread 要在特定的 CPU 上尽量长时间地运行而不被调度到其他的 CPU 上。在 NUMA 架构中,设置 Kernel Thread 的 CPU 亲和性,能够有效提高 Thread 的 CPU Cache 命中率,减少 Remote NUMA Memory 访问的损耗,以获得更高的性能。
- 软 CPU 亲和性:是 Linux Scheduler 的默认调度策略,调度器会积极的让 Kernel Thread 在同一个 CPU 上运行。
- 硬 CPU 亲和性:是 Linux Kernel 提供的可编程 CPU 亲和性,用户程序可以显式地指定 User Process 对应的 Kernel Thread 在哪个或哪些 CPU 上运行。
硬 CPU 亲和性通过扩展 task_struct(进程描述符)结构体来实现,引入 cpus_allowed 字段来表示 CPU 亲和位掩码(BitMask)。cpus_allowed 由 n 位组成,对应系统中的 n 个 Processor。最低位表示第一个 Processor,最高位表示最后一个 Processor,通过对掩码位置 1 来指定 Processors 亲和,当有多个掩码位被置 1 时表示运行进程在多个 Processor 间迁移,缺省为全部位置 1。进程的 CPU 亲和特性会传递给子线程。
在 Linux Shell 上,可以使用 taskset 指令来设定 User Process 的 CPU 亲和性,但不能保证 NUMA 亲和性的内存分配。
IRQ(中断请求)亲和性
Linux Kernel 提供了 irqbalance 程序来进行中断负载优化,在大部分场景中,irqbalance 提供的中断分配优化都是可以起到积极作用的,irqbalance 会自动收集系统数据来分析出使用模式,并依据系统负载状况将工作状态调整为以下 2 种模式:
- Performance mode:irqbalance 会将中断尽可能均匀地分发给各个 CPU 的 Core,以充分提升性能。
- Power-save mode:irqbalance 会将中断处理集中到第一个 CPU,保证其它空闲 CPU 的睡眠时间,降低能耗。
当然,硬件中断处理也具有亲和性属性,用于指定运行 IRP 对应的 ISR 的 CPU。在 Linux Shell 上,可以修改指定 IRQ Number 的 smp_affinity。注意,手动指定 IRQ 亲和性首先需要关闭 irqbalance 守护进程。
使用大页内存
- 《Linux 实现原理 — 大页内存》
- END -






![[JavaWeb]——JWT令牌技术,如何从获取JWT令牌](https://img-blog.csdnimg.cn/4e4640fb09c447c0a6beeec279e08990.png)