JavaEE平台技术——预备知识(Maven、Docker)
- 1. Maven
- 2. Docker


在观看这个之前,大家请查阅前序内容。
😀JavaEE的渊源
😀😀JavaEE平台技术——预备知识(Web、Sevlet、Tomcat)
1. Maven
💻Maven和Docker在我们的课程设计中以及我们的JavaEE应用程序中,扮演着非常重要的角色。Maven是一个纯Java的开源项目,其主要功能类似于集成开发环境(IDE),除了代码编写外,IDE还负责编译、执行和测试代码,以及生成各种文档。尽管IDE可以完成这些任务,但由于不同的IDE之间存在巨大差异,比如有人使用IntelliJ IDEA,而另一些人喜欢使用Eclipse,甚至有人使用微软的VS Code,这使得不同IDE生成的工程文件无法互通。为了解决这个问题,我们需要选择一个与IDE无关的项目管理工具,这就是Maven。
💻Maven不仅仅用于工程管理,它还能够有效地管理Java Archive (Jar)包。传统上,在IDE中,我们需要手动引入不同的Jar包,而且这些Jar包的版本可能存在差异,导致冲突。然而,Maven提供了一个中央仓库,可以在代码编写过程中自动下载所需的Jar包,因此开发者无需关心Jar包的具体位置和版本,从而简化了开发流程。
💻在Maven中,所有项目的结构和文件命名都遵循一套标准的规范,这可以避免因项目结构不一致而导致的混乱。
Maven通过一个名为POM(Project Object Model)的XML文件来管理项目。POM文件描述了项目的所有信息和依赖关系,其中一个重要特性是可以在POM文件中声明项目所依赖的第三方库,Maven会从中央仓库自动下载这些依赖。

💻Maven的Jar包仓库位于用户目录下的隐藏目录.m2中,通过将Jar包从中央仓库下载到本地仓库,再从本地仓库复制到工程目录下,实现了对Jar包的管理和依赖解析。作为初学者,可能会遇到一些关于Jar包的问题,如果出现问题,可以尝试删除.m2目录并重新构建,不过这样做可能会导致编译过程变慢,因为Maven需要重新下载所有的依赖。

Maven通过三个概念(生命周期、阶段和插件及其目标)来管理构建、打包和编译的过程。
💻生命周期包括clean、default和site。
- clean用于清理工程文件(比如编译出的class文件 打包的jar包)
- default用于编译、测试和打包。
- site用于生成项目报告和发布测试报告。(少用)
在项目开发过程中,我们通常会用到这些生命周期来管理项目的构建和测试过程,确保项目的可靠性和稳定性。
Clean💻
首先,我们谈到"clean"(清理)。对于每个生命周期中的中间阶段,它可以被进一步划分为若干个phase(阶段)。生命周期是独立的,彼此之间没有先后关系,它们各自是相互独立的。但是phase是有先后关系的。以最简单的"clean"为例,它包括三个phase:pre-clean(清理前),clean(清理),post-clean(清理后)。

根据名称,我们可以了解它们各自的功能:在进行清理前会做一些事情,在进行清理后又会做一些事情。默认情况下,既不做清理前的操作,也不做清理后的操作。清理操作指的是将所有内容清空。默认情况下有许多的phase。
Default💻

实际上,Default(默认)包含了许多的phase,这些phase可以在构建、编译和打包测试等过程中执行各种任务。每个phase都可以根据需求进行自定义,当然它们也有默认的定义。在这里我们不打算逐个phase地讲解它们的内容,而是重点介绍我们最常用的几个phase。这些phase的顺序是固定的。我们刚才说了,phase是有顺序的,即在进行任何一个阶段时,该阶段之前的所有阶段都会被执行。
比如说我们最常见的是在package这个阶段,我们可以看到几个橙色的阶段,其中包括prepare-package(准备打包)、test(测试)、compile(编译)和validate(验证)。
这些是我们常用的几个阶段。这意味着当我们要执行package阶段时,之前的阶段也会被执行。它首先会验证您的代码是否合法,然后对代码进行编译生成所需的 .class 文件,接着会对编译出的代码进行测试,一旦测试通过,就会对代码进行打包。如果任何一个phase失败,后续阶段就不会继续执行。例如,如果在编译过程中出现错误,测试阶段和打包阶段都不会执行。
这样的定义使用生命周期来定义我们的三个主要任务:
清理、构建和将构建结果发布到特定服务器上。在每个大任务中,通过定义一系列带有先后关系的phase,可以定义在这个任务中要执行哪些操作,以及这些操作的执行顺序。这些是默认的phase。
Site💻

site(网站)是用来发布(部署)的,因此可以看到在site阶段中,实际生成的是中间的site,并且还有pre-site和post-site,最终将生成的文档发布到特定的服务器上。在我们课程设计的代码中,实际上也使用了site和site-deploy phase。它用来生成我们的测试报告,并将测试报告发布到特定的服务器上,这样每个人都可以查看测试报告。这是site生命周期的应用。
第三个要介绍的是插件。我们已经定义了生命周期并定义了每个phase要执行的任务,这些任务都是由插件完成的。插件是在Maven中实际工作的组件。它们包括Maven自身提供的插件以及许多第三方插件。
因此,Maven能做什么其实说不好,关键在于Maven拥有哪些插件。只要Maven拥有某个插件,它就能执行该插件的任务。
💻许多第三方公司都为Maven开发了各种各样的插件,因此Maven可以执行各种各样的任务。当Maven执行任务时,它将这些插件绑定到相应的phase上。如前所述,phase是有顺序的,因此可以根据需要将插件绑定到特定的阶段。对于每个插件来说,它实际上可以执行多个任务。
💻例如,就我们之前的例子而言,我们的默认编译插件实际上可以执行两个任务:一是编译项目代码,二是编译测试代码。

💻由于工程代码和测试代码位于两个目录下,因此如果需要编译工程代码,它只会编译工程代码;如果需要编译测试代码,它只会编译测试代码。对于每个插件,它所执行的每个任务都称为"plugin goal"(插件目标)。您需要完整地标识要完成的任务,并告诉它您要使用哪个插件以及您要让该插件完成什么任务。
💻如上所述,compile-plugin用于compile的目标,它只会编译工程代码。
如果让它编译测试代码,那么就是testCompile。
插件与phase相关联,默认情况下它们是关联的,当然您可以修改这一关联。
正如我们之前提到的,在clean生命周期中的clean phase之前,有pre-clean phase和post-clean phase,这两者都是空的。clean phase执行的操作是maven-clean-plugin:clean的目标,它的功能是将上次构建的所有文件全部清除,将其清空并将目录删除。如果您希望执行其他操作,可以更改这个目标所绑定的插件。这是默认设置中我们常用的几个phase的示例。

例如,compile使用compile-plugin:compile的目标,我们可以看到编译了工程代码。 test-compile phase位于test之前,它使用的是maven-compile-plugin:testCompile来编译测试代码。
类似的例子不再一一讨论。因此,每个phase默认情况下都已绑定了plugin goal。这是site阶段所绑定的默认goal,我们不再一一讨论。
最后,我们将介绍一个特殊关系,称为父子关系,它是pom文件中的一个特殊关系。
💻严格来说,一个pom描述了一个工程所需的所有依赖以及构建和打包的方式,但是我们的课程设计是分为多个模块的,每个模块的要求是不同的,因为每个模块执行的内容不同,所以它们的依赖关系也不同,它们的构建打包方式也不同。
pom实际上支持继承关系。所谓继承就是将一些通用的内容定义在父pom中,将一些特定的内容定义在子pom中。如此格式,即在父pom中定义了许多子pom的共性内容,同时也可以管理所有子pom的版本号等内容。

💻有了Maven之后,整个过程变得相对简单。——我们有一个视频向大家展示在没有Maven的情况下,我们如何在IDE中运行之前提到的Servlet。有了Maven之后,我们可以使用Maven来运行它,我们使用两个示例来比较使用Idea和Maven来管理项目的差异。
💻这两个示例都是基于我们之前提到的Servlet示例,但我们创建了两个项目,一个是Idea项目,一个是Maven项目。
在GitHub上获取了这个项目之后,我们首先展示了如何在Idea中运行Servlet示例。

Idea是一个集成开发环境,因此在使用Idea管理项目时,我们需要配置许多相关信息。
💻💻首先在第二章的预备知识目录中,有两个项目,一个是Servlet_Idea,一个是Servlet_Maven,它们分别是使用Idea和Maven管理的项目。然后我们打开Idea项目,我们会发现在它的根目录下有一个Servlet_Idea.iml文件,这个文件是Idea项目管理文件。

💻我们右键选择这个文件,导入这个module,之后我们会发现所有的文件和目录都会有颜色,这表明Idea已经识别了这些不同类型的文件。然后我们打开一个Java文件,我们会发现Java文件中有许多红色部分。

红色部分表示Idea不认识这些关键字。导致这种情况的原因可能是:
- 一方面,项目原有的jdk可能与当前安装的Idea的jdk不一样;
- 另一方面,JavaEE的Servlet相关库尚未导入。
为了使项目能够运行起来,我们需要在Idea中设置SDK和Servlet库。我们可以在File->Project Structure中找到SDK并设置为项目所需的SDK。

然后我们找到Tomcat的库,发现目前尚未设置,因此我们需要在Run->Edit Configuration中设置Tomcat的环境,包括指定Tomcat的安装目录等信息。

设置好Tomcat环境后,我们可以返回Project Structure,会发现在dependencies中的library中已经有了我们刚才设置的Tomcat 10.0.23。

接下来我们可以看到在Run->Edit Configuration中的Tomcat配置中,我们将刚才设置的artifacts部署到Tomcat服务器上,然后点击确定。
这样Idea的环境就配置好了。

太繁琐了!!!!!
接下来我们看一下在Maven中是如何做的。
我们的另一个目录中有Maven项目,在Maven项目中找到pom文件,您可能在课程中已经讲过pom文件包含了一个Maven项目所需的所有信息。因此,我们只需要右键单击pom文件,然后选择Add as Maven Project,然后您会发现所有的问题都解决了,代码中也不会有任何红色的部分,这表明Idea已经识别了所有的库。

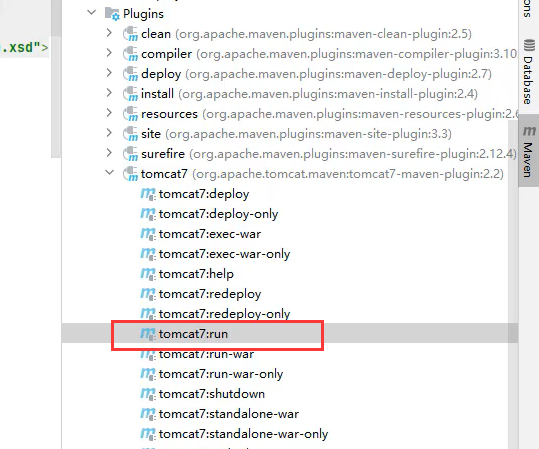
此时右侧会出现一个Maven的小tab,我们打开Maven的tab会看到Maven的生命周期和phase。

然后我们选择package phase,让它执行打包操作。
完成打包后,我们在下面的plugins中使用Tomcat 7的plugin将其运行起来。这两步操作之后,我们的Servlet就可以正常运行了。
为什么Maven可以如此简单地完成配置?
💻因为它将所有的信息都写在了pom文件中,所有的库都会从Maven的中央仓库下载并安装到相应的位置。因此,相对于Idea来说,将一个Maven项目引入到任何一个IDE中都是非常方便的。
通过上述过程我们可以看到,Maven的配置过程要简单得多。最后我们来看一下在Maven的pom文件中放了什么样的内容。
<?xml version="1.0" encoding="UTF-8"?>
<!-- 工程的根标签-->
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><!-- 模型版本需要设置为 4.0。--><modelVersion>4.0.0</modelVersion><!-- 工程组的标识。它在一个组织或者项目中通常是唯一的--><groupId>cn.edu.xmu.javaee</groupId><!-- 工程的标识。它通常是工程的名称。--><artifactId>Servlet_Maven</artifactId><!-- 工程的版本号。在 artifact 的仓库中,它用来区分不同的版本。--><version>1.0-SNAPSHOT</version><!-- 打包的格式--><packaging>war</packaging><!-- 定义属性,用在后面的定义中--><properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding></properties><!-- 定义依赖关系--><dependencies><dependency><groupId>javax.servlet</groupId><artifactId>javax.servlet-api</artifactId><version>4.0.1</version><scope>provided</scope></dependency></dependencies><!-- 定义构建的方法--><build><sourceDirectory>src/main/java</sourceDirectory><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.10.1</version><configuration><source>11</source><target>11</target></configuration></plugin><plugin><groupId>org.apache.tomcat.maven</groupId><artifactId>tomcat7-maven-plugin</artifactId><version>2.2</version><configuration><port>8080</port><path>/</path><server>tomcat7</server></configuration></plugin></plugins></build>
</project>
首先是一个dependency,依赖是Servlet的API,但我们将其类型标记为provided。"provided"表示在打包时它实际上不会将这个库打包到我们最终的项目中,因为我们的项目依赖于Tomcat,而Tomcat本身就包含了这个库。但是在编译时,它会使用Maven中央仓库中的库来检查编译是否正常。但在运行时,实际上并不会包含Servlet库,而是使用了Tomcat库。这是一个dependency的示例。接下来我们可以看到我们使用了两个plugin。
💻一个plugin是Maven的plugin,用来做编译的,而另外一个plugin,则是运行我们的工程的,Tomcat的plugin,靠这两个plugin,我们就能够把整个项目把它编译好,然后把它运行起来,这就是一个Maven的例子。
💻没有Maven的时候我们大家在做十几步,才能在IDE里把它配出来跑,因为IDE需要知道所有的外部环境,有Maven以后所有的环境都描述在pom文件中间,你只要把import进去就可以跑,所以只有两步这个差异是非常明显的,所以今天在做所有的项目的时候,基本上就是用的Maven,或者另外一个等价的东西叫做graddle,但是我们课程都是用的Maven,Maven graddle其实是一样的,我们很多的东西都可以看到它既有,Maven的版本也有graddle版本。
2. Docker
导读:让我们花一些时间来探讨Docker。Docker也是我们在这里使用的一个至关重要的技术。我们在第一堂课中提到,我们的目标是建立一个具有弹性和可扩展性的架构。我们希望我们编写的程序能够灵活部署。如果负载增加,它可以增加部署数量;如果负载减少,它也可以减少部署数量。然而,实现这种任意部署实际上需要一定的前提条件。我们知道每个应用程序都对其部署环境有一定的要求。例如,我们编写的程序可能依赖于特定版本的Java虚拟机(JVM),有些应用程序可能依赖于JRE11,有些可能依赖于JRE8。此外,某些程序可能还依赖于像之前提到的Apache Portable Runtime (APR) 等软件。因此,每个应用程序都有其独特的要求。问题是,我们如何将应用程序与其依赖的环境整合成一个整体,并将其部署在整个服务器上。
我们的Docker来了!!!!
这就是Docker的核心思想。Docker是一项虚拟化技术。在Docker出现之前,我们已经有了虚拟化技术。我们目前使用的服务器实际上都是虚拟机。那为什么还需要Docker呢?
实际上,虚拟机和Docker是不同的。虚拟机虚拟的是什么呢?它虚拟的是物理资源。可能在物理上只有一台机器,但是通过虚拟机技术,可以虚拟出许多台虚拟的机器。每台虚拟机都可以安装操作系统和其他软件。
而Docker虚拟的是什么呢?Docker虚拟的是操作系统。

就像这张图所示,目前的情况是,在下方有一台虚拟机,其上安装了操作系统,并在操作系统上安装了Docker引擎。通过这个引擎,您可以虚拟出不同的环境。每个环境看起来就像是一台独立的机器,但实际上它只是在操作系统上虚拟出来的环境。虚拟化环境的好处在于,每个应用程序都可以拥有自己独特的环境。由于每个应用程序的环境可能不同,它可以将应用程序和其环境作为一个整体部署在任意服务器上。它带着环境运行,而不受服务器环境的影响。
这种方法的基本思想是,所有应用程序实际上都基于相同的操作系统。它并不需要不同的操作系统。我们都是在Ubuntu 18.04的操作系统上运行我们的应用程序。应用程序之间的区别仅仅是它们的环境不同。因此,Docker将这些环境容器化,虚拟化出来,并使每个应用程序及其环境成为一个虚拟的独立单位,不会相互干扰。这就是Docker的作用。
现在Docker已经非常成熟了。这是因为目前大家普遍认为,虚拟化操作系统是有意义的,但对于我们的应用程序来说,虚拟化环境更加有用。因为应用程序可能始终使用Ubuntu操作系统,而不是一会儿想用Windows,一会儿想用Ubuntu。但每个应用程序对环境的要求可能不同。因此,Docker才会有其用武之地。
我们讲下一些Docker的基本概念,包括里头有两个基本概念,一个是镜像一个是容器。
- Docker镜像:应用环境的只读模板
- Docker容器:运行和隔离应用的沙箱
镜像和容器是用来描述应用程序所依赖的环境的。镜像是只读的,而容器是可以修改的。如何理解这一点呢?
通常情况下,在安装一个应用程序时,大家会有这样的体验:安装一个应用程序后,您需要安装许多环境才能使该应用程序正常运行。例如,您安装了操作系统,但是Java程序无法运行,需要先安装虚拟机。一旦安装好虚拟机,Java程序才能在虚拟机上运行。虚拟机就是您需要在操作系统上安装的环境。我们可以将镜像视为一个只读的环境。举个例子,除了安装虚拟机之外,您可能还需要更改一些配置参数,如系统参数等。安装好虚拟机后,我们可以将其视为一个镜像。
实比如际上,镜像是分层的。在Docker中,镜像是分层的。每次安装一个组件,它就形成一层。您安装了Java虚拟机后,再安装其他组件,它们就会形成若干层叠在一起,最终构成您所使用的环境。一般来说,镜像中不会包含完整的Ubuntu操作系统,因为在镜像中包含完整的Ubuntu并没有意义。通常情况下,镜像中包含的是在Ubuntu操作系统上安装的其他组件。这些组件形成一个镜像,比如最常见的是在镜像上安装JVM,然后安装Tomcat。由于Tomcat是基于JVM的,所以安装JVM是一个镜像层,Tomcat是在JVM上另一个镜像层,最后您使用的就是这两个镜像层组成的环境。
安装完环境后,我们可能需要更改其配置。例如,在Tomcat中可能需要更改一些值。我们可以将需要更改的配置保存在容器中,而不是将其保存为只读的。因为不同的Tomcat可能具有不同的配置,但是JVM和Tomcat可能会被重复使用。因此,我们可以将配置更改保存在容器中。因此,容器和镜像共同构成我们最终的环境。但是容器和镜像的区别在于,容器是由镜像生成的。您可以在容器中随意更改或安装任何东西,但是这些更改不会被保存。如果删除了容器,更改也会被删除。而镜像是会被保存下来的,它会一直存在。
实际上,在最终使用时,我们使用的是容器。容器是由镜像生成的,您可以对容器进行进一步的更改,但是容器不会保存这些更改。容器与容器之间是隔离的。我们可以将容器看作是一台独立的虚拟机。它具有独立的IP地址,就像一台独立的机器一样使用。但实际上它是在操作系统中虚拟出来的。这就是Docker的一些应用。

镜像和容器就是类和实例的关系
-
我们从后面的开始讲,我们最开始是首先要有镜像,所以我们用这个命令能够看到,本地的所有的镜像。
docker images:列出本地镜像 -
然后由镜像生容器,去从一个镜像里头,产出一个容器,容器出来以后你在容器,里头就可以任意去改配置,然后形成你最终要用的东西。
docker run:由镜像创建容器并运行一个命令 -
你可以启动停止和重启一个容器,这都不会去让这个容器死亡掉。
docker startlstop/restart:启动/停止重启容器 -
但是这条命令会让容器死亡掉,会删掉一个容器,你在容器里头改的那些内容就没了,这个容器就没有了。
docker rm :删除一个或多个容器 -
ps可以列出当前的所有的容器,一个镜像可以出多个容器,因为每个容器可以任意去改配置,ps可以看到,所有的容器以及容器和镜像的关系。
docker ps:列出服务器上的容器 -
ps都可以看镜像能不能删,镜像也可以删,用rmi可以把镜像删掉
docker rmi :删除个或多个镜像
产生镜像的方式有很多种,其中最常用且推荐的方式是使用一个描述文件来生成镜像。这个描述文件被称为Dockerfile。Dockerfile实际上包含了一系列指令,指令并不多,稍加介绍后大家就能了解,主要有以下几条指令:
-
FROM:指定基础镜像。可以基于另一个镜像构建新的镜像。由于镜像是分层的,您可以在现有镜像的基础上安装新的组件,从而形成一个新的镜像。
-
MAINTAINER:描述镜像是由谁创建的。
-
RUN:在镜像中执行命令。通常用于安装软件。例如,您可以基于一个基础镜像,然后使用RUN命令安装Tomcat。
-
EXPOSE:将容器的端口暴露出来。我们稍后会讨论为什么要这样做。
-
ADD:将文件复制到镜像中。
-
ARGS:为镜像指定参数。
此外还有两个指令,即ENTRYPOINT和CMD,它们在容器启动时继续执行命令。这两个指令只能使用其中之一,如果同时写了两个,那么只有后面那条指令会起作用。这两条指令的区别在于,ENTRYPOINT是不可覆盖的,如果要覆盖,则需要添加参数,而CMD是可以覆盖的。因此,通常会综合使用ENTRYPOINT和CMD来达到我们的目的。

让我们看一个例子,这个例子是我们以后会频繁使用的Dockerfile。这个Dockerfile的基础镜像是jdk11,这个基础镜像已经在Docker的库中存在,因此我们不需要再安装JDK11或进行其他RUN操作。所以我们使用了基础镜像JDK11,它提供了一个带有JDK11的虚拟机。操作系统的第一层是一个虚拟机。在这个基础镜像上,第一条指令只是提示了一下是谁创建的这个镜像。然后我们指定了当前工作目录是/app。因此,在镜像中会有一个当前的工作目录/app。
这个例子中有一个传参。我们之后会使用这个参数来传递文件名,因为我们现在并不知道文件名,所以我们需要在镜像中拷贝一个文件。ADD命令就是用来拷贝文件的。我们将传入的文件拷贝到镜像的/app目录下,并将其命名为app.jar。
接下来,我们要将容器的8080端口暴露出来。这是因为8080端口实际上是Tomcat的默认端口。我们计划让外部可以访问,所以我们将其暴露出来。然后在最后写了一个ENTRYPOINT和CMD。ENTRYPOINT是用来执行一个java -jar这样的命令。我们现在写了两条命令,实际上是java -jar,后面跟着app.jar。这些命令的目的是将拷贝进来的Jar文件运行起来。
这就是我们以后会经常使用的一个Dockerfile示例。使用这个Dockerfile,它可以生成一个镜像。当我们完成了工程,将代码变成Jar包并将Jar包拷贝到其中后,这个Dockerfile就可以生成一个镜像。然后我们可以将这个镜像拷贝到任何一台服务器上并运行它。当您启动这个容器时,它会自动执行后面的命令,并将应用在jdk11的服务器上运行起来。
AAAAAAA
为什么要分成两句话来写呢?实际上这样做并没有多大意义,只是为了展示一下可以这么做。因为这个可以在运行时被覆盖,java -jar到底运行哪个Jar包其实是可以覆盖的,但对此没有意义。镜像中间实际上只有一个Jar包,在本地/app目录下找到第二个Jar包是没有意义的。不过这样做的一个作用是代表ENTRYPOINT和CMD是可以分开写的,而且CMD可以在启动时指定要启动的Jar包,可以从外部传参而不会有问题。
最后,我们要谈论一个问题。在一台虚拟机上可以运行多个容器,容器和容器之间的程序该如何通讯呢?因为所有的容器之间是被相互隔离的,它们是不能相互访问的。为了解决这个问题,Docker在服务器平台上提供了一个集群,叫做Swarm集群。
Swarm集群的作用是将我们在若干台服务器上运行的容器作为一个集群来管理,统一控制这些容器之间应该运行什么样的服务。通过将主服务和从服务全部加入集群,它可以将整个集群作为一个整体来提供服务。只需要启动主服务,然后将剩余的服务加入,剩下的事情就会搞定。因此,从操作的角度来说,我们需要补充一些关于Docker集群的概念。
它的结构是这样的,所有的服务器被分为两类,一类是manager,另一类是worker。Manager在整个集群中负责管理和协调所有的服务。我们所有的操作也都在Manager上进行。Worker基本上不动,只要装好它能够运行的Docker的image。

我们在Docker中有两个概念,一个是只读的Image,另一个是能够运行的容器,即container。在worker上只要装好它能够运行的image,在manager上也可以装image,其实manager也是一个worker,它是平等的。
这是总的结构,由manager和worker组成。它的特点是去中心化,也就是所有的manager和worker实际上都可以运行我们的Docker。至于它运行哪个Docker,是由它自己去调度的。我们只需要告诉它你要运行3份还是运行4份,它自己去调度说它运行什么。所有的服务器构成了一个服务器的主机网络。它在内部采用了Overlay网络。
Overlay网络是一个虚拟网络。
- 利用它本身提供的Overlay网络,就能够实现所有的容器互通。关键是,它给我们带来了最大的好处,就是因为每一个节点的IP是会发生改变的,所以它也提供了一些有限的服务发现机制。
- 另外,它还具有负载平衡的功能。如果你访问其中的任何一台服务器,它都会将其转发给集群中真正负责这项任务的那台服务器。至于它会转发给谁,它会根据动态负载平衡来决定。
总的特点主要有三个方面。首先,需要选择一台机器作为Manager,并在该Manager上初始化Swarm,创建一个Swarm集群。通过一条命令创建完成后,系统会返回一个命令,用于让其他Worker加入集群,其中包含一个Token,会在屏幕上显示出来。您可以复制此命令,并在要加入集群的其他服务器上执行。这样,Swarm就会很简单地建立起来了。在Manager启动后,它还会返回一条命令,让您在其他服务器上运行。您只需将此命令复制并在所有服务器上执行一次,就可以建立一个Swarm集群。初始时,一个是Manager,其余都是Worker。由于只有一个Manager,其他操作相对简单。如果有多个Manager,操作会相对复杂。在初始实验中,只需建立一个Manager和一组Worker就足够了。
建立好Swarm后,我们如何运行Docker呢?只需要两步。首先,确保您的Docker可以运行。在每个Worker上都必须有Docker的镜像。如果Worker上没有相应的镜像,即使您让其运行Docker,它也无法运行。因为镜像是只读的,保存在文件中。那么如何建立Docker的镜像呢?在我们所有的代码中,今年的所有代码中我都加了Dockerfile。在原有的代码基础上,加上了Dockerfile,而原本的代码中仅限于使用Maven。最终只需执行package命令即可打出一个Jar包,整个过程就结束了。
今年的代码中间,我正在逐步地为我们今天将要讲述的所有代码中间逐步添加一些更新。实际上,我已经在每个代码中添加了一个Dockerfile。此外,我们还添加了一个插件,将其绑定到了
package后面的一个阶段上。我们还记得我们之前讨论过的内容,在默认生命周期中,它包含了若干个阶段,所有的阶段按顺序执行。一般我们会使用package,因为package意味着代码已经编译、测试通过并打包完成,生成了一个JAR包。而install和deploy会将其安装到Maven仓库并部署到远端的Maven仓库,我们通常不会使用。现在我在代码中加入了一个插件,将其绑定到了package后面的阶段。我查看了一下package后面的阶段,发现只剩下integration-test,我们打算之后还会用到它,所以不能绑定到该阶段上。我将其绑定到了pre-integration-test阶段,这意味着在集成测试之前执行。pre-integration-test阶段在package阶段之后,因此,当您在自己的笔记本电脑或台式机上运行代码时,您不需要打包成Docker镜像,因为您可能没有安装Docker环境。您只需运行到package阶段即可,运行到package阶段就意味着已经打出了JAR包。然后,如果您使用Spring Boot的插件运行,只需运行它即可。但是,如果您要在我们的服务器上运行,则需要运行到pre-integration-test阶段。因为pre-integration-test阶段之前是package阶段,实际上在完成前面的工作(编译完成后),它会将其编译为Docker的镜像文件,并安装到服务器上。每个您需要运行的内容都需要在服务器上安装对应的镜像。安装完成后,它就可以在服务器上运行了。如果没有安装,它也不会出错,只是在那台机器上不会运行这个任务。换句话说,如果您在集群中要运行某个Docker,而某台worker没有安装对应的镜像,它肯定是不会运行的,只有安装了镜像的才会运行。因此,这是我们需要事先说明的一个问题。整个运行过程实际上是很简单的。如果这些worker和Manager上都已经安装了镜像,那么您只需要在Manager上创建一个服务即可,创建服务的命令就是Docker run命令。这将使得Docker容器作为一个服务在集群中运行。然后您告诉它您是要运行一份还是两份,如果您告诉它运行一份,它会在所有的机器中挑选一台有镜像的机器来运行。如果您告诉它运行两份,它将在有镜像的两台机器上运行。这就是引入Swarm后的一种工作方式。引入Swarm后,我们将会发现实验变得相对简单,我们的环境配置也会相对简单。