有用的话谢谢点赞~
安装Python3.11
cd /root
wget https://www.python.org/ftp/python/3.11.0/Python-3.11.0.tgz
tar -xzf Python-3.11.0.tgz
yum -y install gcc zlib zlib-devel libffi libffi-devel
yum install readline-devel
yum install openssl-devel openssl11 openssl11-devel
export CFLAGS=$(pkg-config --cflags openssl11)
export LDFLAGS=$(pkg-config --libs openssl11)
cd /root/Python-3.11.0
./configure --prefix=/usr/python --with-ssl
make
make install
ln -s /usr/python/bin/python3 /usr/bin/python3
ln -s /usr/python/bin/pip3 /usr/bin/pip3
克隆网页
安装httrack
优点:方便
缺点,很慢克隆一个网页需要3分钟左右,而且他会把html放在没有规则很深的目录下。
sudo yum install epel-release
sudo yum install httrack
import subprocess
import os
import datetimedef clone_website(url):# 获取当前时间戳的后五位timestamp_suffix = str(int(datetime.datetime.now().timestamp()))[-5:]# 在当前脚本的目录中创建一个新的目录(如果它不存在)current_dir = os.path.dirname(os.path.realpath(__file__))output_dir = os.path.join(current_dir, timestamp_suffix)os.makedirs(output_dir, exist_ok=True)# 构建 HTTrack 命令,使用10个并发连接command = ['httrack',url,'-O', output_dir,'+*.css', '+*.js', '+*.png', '+*.jpg', '+*.jpeg', '+*.gif', '+*.bmp', '+*.tif', '+*.ico', '+*.svg', '+*.woff', '+*.woff2', '+*.ttf', '+*.eot','+*.doc', '+*.docx', '+*.xls', '+*.xlsx', '+*.ppt', '+*.pptx', '+*.pdf','-v', # 显示详细的输出'-c20' # 设置并发连接数为10]# 调用 HTTrackresult = subprocess.run(command, stdout=subprocess.PIPE, stderr=subprocess.PIPE, text=True)# 检查结果if result.returncode == 0:print(f'Website cloned successfully to {output_dir}.')else:print(f'Error: {result.stderr}')# 使用函数,替换下面的URL为你要克隆的网站的URL
clone_website('https://jw.cq.gov.cn/zwxx_209/gggs/202304/t20230407_11857087.html')
克隆的效果,复制到windows后查看:
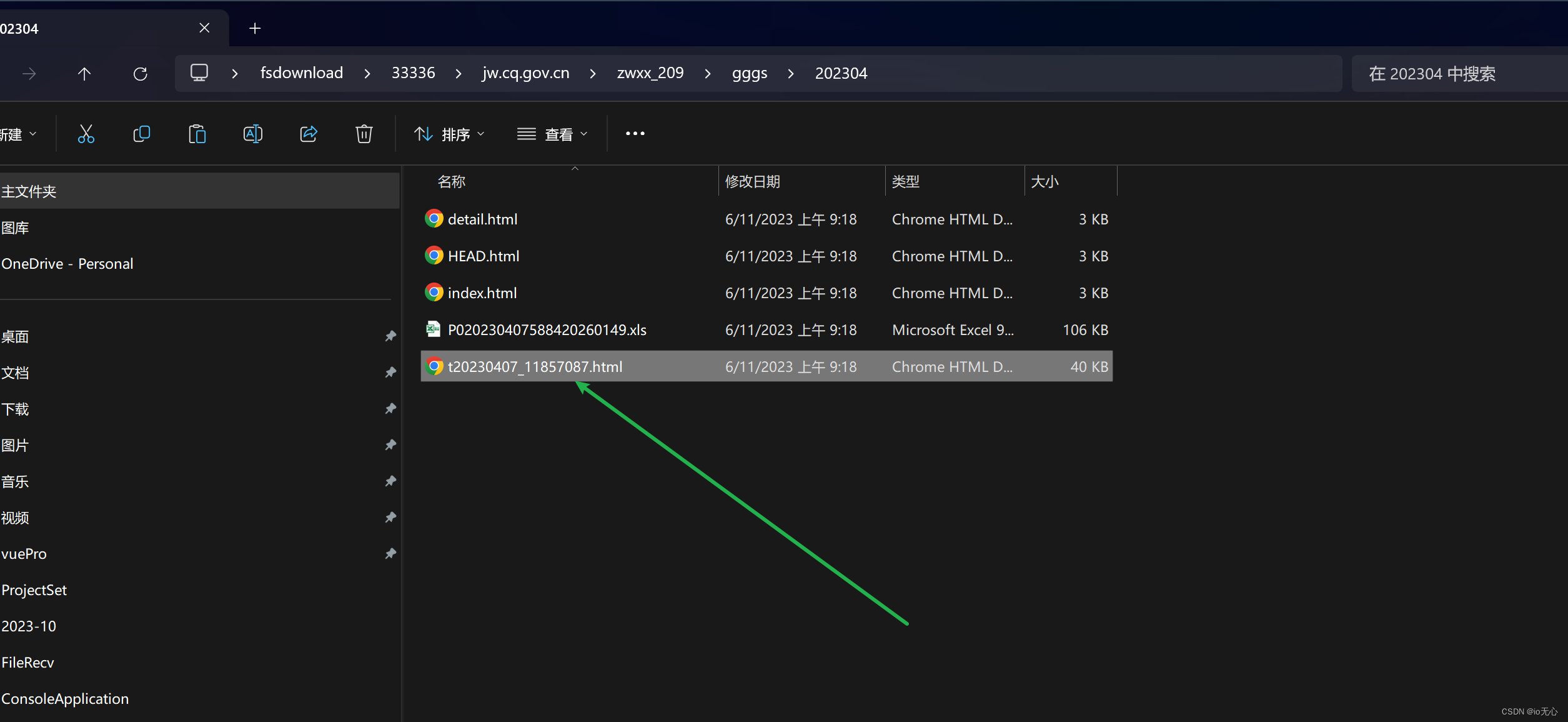
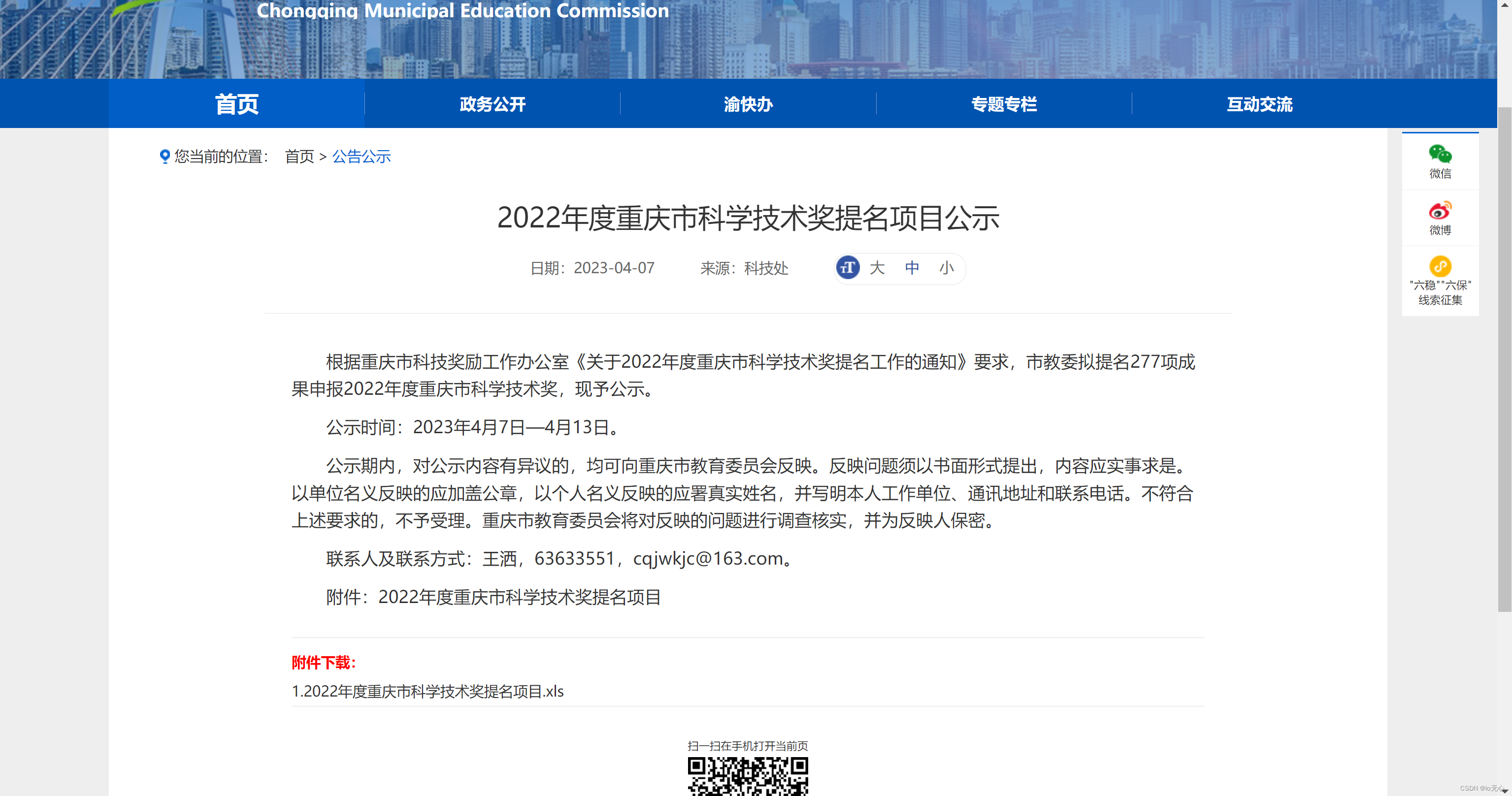
对网页长截图
Centos7自带了火狐浏览器,先给卸载,然后安装新的:
sudo yum install firefox然后去:火狐浏览器下载链接,选择geckodriver-v0.33.0-linux64.tar.gz的
tar -zxvf geckodriver-v0.23.0-linux64.tar.gz
mv geckodriver /usr/bin
pip3 install selenium
pip3 install pillowfrom selenium import webdriver
from PIL import Image
import io
import time# 初始化浏览器选项
options = webdriver.FirefoxOptions()
options.add_argument('--headless')# 启动Firefox浏览器
driver = webdriver.Firefox(options=options)# 设置浏览器窗口大小
driver.set_window_size(1920, 1080) # 设置足够宽的窗口以避免水平滚动条# 访问网页
driver.get('https://mp.weixin.qq.com/s?__biz=MzA4NzA4OTcxOA==&mid=2652043883&idx=1&sn=b92866b4ca48eb9347c86975ef0d7d63&chksm=8bd8ed32bcaf6424cd29c8f570e4017a891845d4eaa0f84200a296c2559fce58f7812444616d&mpshare=1&scene=23&srcid=0317rO8OszUoDa3ONY9rPLV2&sharer_sharetime=1679227735767&sharer_shareid=81423ad49b97041adbcf45fdceef7dc6#rd')
time.sleep(5) # 给页面时间加载内容# 获取页面总高度
total_height = driver.execute_script("return document.body.parentNode.scrollHeight")# 开始截图
slices = []
offset = 0
while offset < total_height:# 滚动到新的截图位置driver.execute_script(f"window.scrollTo(0, {offset});")time.sleep(2) # 等待滚动动画完成和内容加载img = Image.open(io.BytesIO(driver.get_screenshot_as_png()))slices.append(img)offset += img.size[1]# 将截图拼接为一张完整的图片
screenshot = Image.new('RGB', (slices[0].size[0], total_height))
offset = 0
for img in slices:screenshot.paste(img, (0, offset))offset += img.size[1]# 保存截图
screenshot.save('entire_page_screenshot.png')# 关闭浏览器
driver.quit()
效果如图:


)




)


)

》重磅发布)







