这篇文章是ES7.11版本的文章,主要学习的是思路,记录在这里留作以后参考用。
原文地址:https://www.elastic.co/cn/blog/how-we-made-date-histogram-aggregations-faster-than-ever-in-elasticsearch-7-11
正文开始:
Elasticsearch 的 date_histogram 聚合是 Kibana 的 Discover 和 Logs Monitoring UI 的基石。我经常使用它来调查构建失败的趋势,但当它运行缓慢时,我会感到不高兴。用了整整四秒钟才绘制出过去六个月某个测试的所有失败情况!我可没有那么多时间!谁能把我的四秒钟还给我?所以在过去的六个月里,我一直在努力提升它的性能。断断续续地。
手动进行舍入
在很久之前(2018年),有一个 bug,名为“time_zone 选项会使 date_histogram 聚合变得慢”。那些涉及夏令时转换的时区会慢四倍。@jpountz 通过在不包含夏令时转换的分片上解释时间并忽略夏令时来修复了它。这很好,因为没有夏令时转换的时区很容易处理!你只需从 UTC 减去它们的偏移量,四舍五入,再加上偏移量,然后进行聚合。嗯,你不亲自操作,是 CPU 来执行的,但问题或情况仍会存在,你能理解吧。
所以 date_histogram 聚合速度很快。但每隔六个月它就会变慢!通常在索引中有大约一天的数据是相当常见的。如果你必须在带有夏令时转换的索引之一上运行 date_histogram,速度会很慢。在我知道这个问题之时,日期舍入本身比具有夏令时转换的分片要慢大约1400%。
原来,我们使用的是 java.util.time APIs,它们非常可爱、精确,并涵盖了所有内容,但它们会分配对象。而你确实希望避免为聚合中的每个数值创建新对象。所以我们摘下了手套,为自己实现了一套特定于日期舍入方式的夏令时转换代码。现在,我们不再分配对象,而是可以构建一个包含分片可见的所有夏令时转换的数组,然后进行二进制搜索。这很快!即使分片有成千上万个转换。对数时间真是一件美妙的事情。
停止舍入
但是,如果你要在分片上预先计算所有数据的夏令时转换,为什么不预先计算所有的“舍入点”呢?也就是 date_histogram 可能生成的每个存储桶的所有键。在我们实现“去除限制”的舍入 API 时,我们进行了所有工作,将索引中的最小日期和最大日期流式传输到所有正确的位置,因此你可以从最小日期开始,然后获取下一个舍入值,直到超出最大日期,将其添加到一个数组中并进行二进制搜索。然后你根本不需要再调用日期舍入代码。这种方法总是更快的。嗯,几乎总是。只有当你有很长时间范围内的一小组文档时,才不适用。但即使在这种情况下,它也很快。再次强调,对数时间是一种奇妙的东西。
开始过滤
稍微偏题一下:@polyfractal 提出了一个想法,通过查看搜索索引而不是文档值,可以加速范围聚合。这显示出了相当引人注目的速度提升,但我们不想合并这个原型,因为维护成本较高,而且人们并不经常使用范围聚合。
但我们意识到,如果你已经预先计算了 date_histogram 的所有“舍入点”,你可以将其转换为范围聚合。如果你像 @polyfractal 的原型一样,为该范围聚合使用搜索索引,你将获得8倍的速度提升。现在,正在维护范围聚合的优化,因为它正在为日期直方图聚合提供优化支持。
这是我们第一次将一个聚合转换为另一个聚合,以更高效地执行它。实际上,我们执行了两次。我们将 date_histogram 转换为范围聚合,然后将范围聚合转换为过滤聚合。过滤聚合从来没有非常快。因此,我们为其编写了“按过滤器过滤”的执行模式,以在某些情况下生成正确的结果,并在其他情况下不使用它。因此,事件的顺序如下:
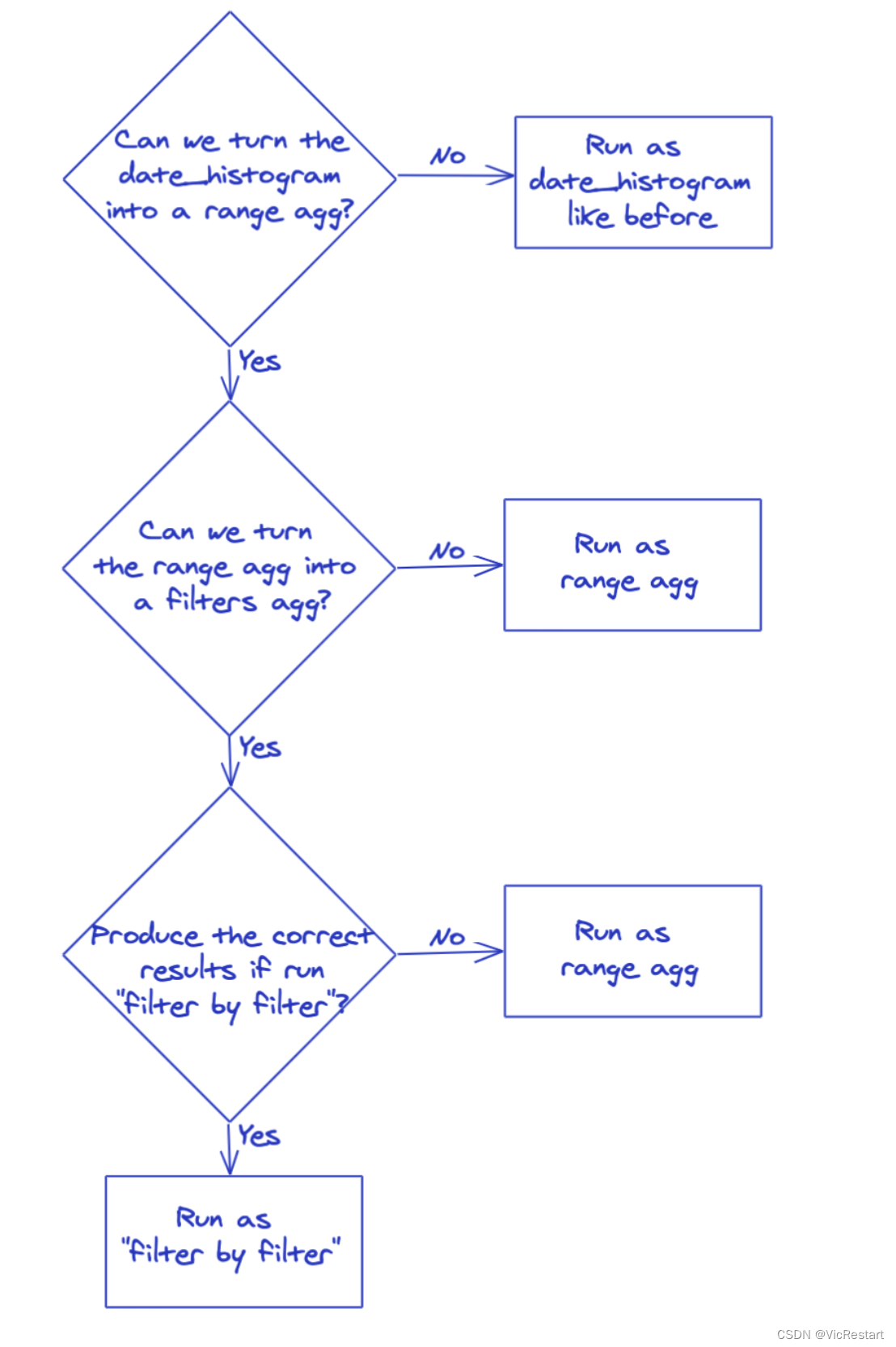
这个方法的巧妙之处在于你可以在沿途的任何站点上加入“optimization train - 优化列车”。范围聚合将检查它们是否可以运行“filter by filter - 按过滤器过滤”。过滤聚合也会这样检查。
它没有范围特定优化所带来的维护负担,因为我们只需要维护新的“filter by filter - 按过滤器过滤”执行机制和聚合重写。而且我们可能可以通过其他重写来加速更多的聚合。我们能否将terms聚合重写为filters聚合并获得相同的优化效果?很可能!我们是否可以通过将 date_histogram 聚合中的terms聚合视为filters聚合而不是另一个filters聚合来优化它?也许。我们是否可以将geo-distance聚合重写为环形过滤器?很可能,但实际上可能不会更快。即使它不会在本质上更快,是否值得这样做,以减少工作集?找出答案将是一件有趣的事情。
于是,这个全新的世界 需要 崭新的 基准测试。我们依靠JMH进行微基准测试,而依靠Rally进行宏观基准测试。我们每晚运行Rally并发布结果。但这是另一篇博客文章的故事了。
无论如何,看到自己的工作让图表变得更好是一件有趣的事情。总的来说,这是一次有趣的旅程。在过去的一年里,我阅读的汇编语言比过去15年加起还要多。(后面的都是宣传广告了,就不贴了)
结束
感谢您的阅读,别忘了点赞、收藏哟~ Thanks♪(・ω・)ノ

(Cookie 和 Session、理解会话机制 (Session)、实现用户登录网页、上传文件网页、常用的代码片段))


--jupyter官方文档(oneAPI_Intro)学习笔记)

)
和JWT 详解)
)










