目录
前言
1、自动录制脚本
1.1、原理
1.2、JMeter脚本录制
2、JMeter直连数据库
2.1、直连数据库的作用
2.2、JMeter直连数据库的步骤
案例:
3、JMeter的逻辑控制器
3.1、if控制器
案例:
3.2、循环控制器
案例:
3.3、ForEach控制器
案例:使用用户自定变量~
4、JMeter的定时器
4.1、同步定时器
案例:
4.2、常数吞吐量定时器
案例:
4.3、固定定时器
案例:
前言
JMeter学习上:http://t.csdnimg.cn/DOWpY
JMeter学习中:http://t.csdnimg.cn/sLJ99
1、自动录制脚本
1.1、原理
JMeter录制脚本,在没有接口文档的旧项目中,快速录制web页面产生的http接口请求,帮助编写接口测试脚本。
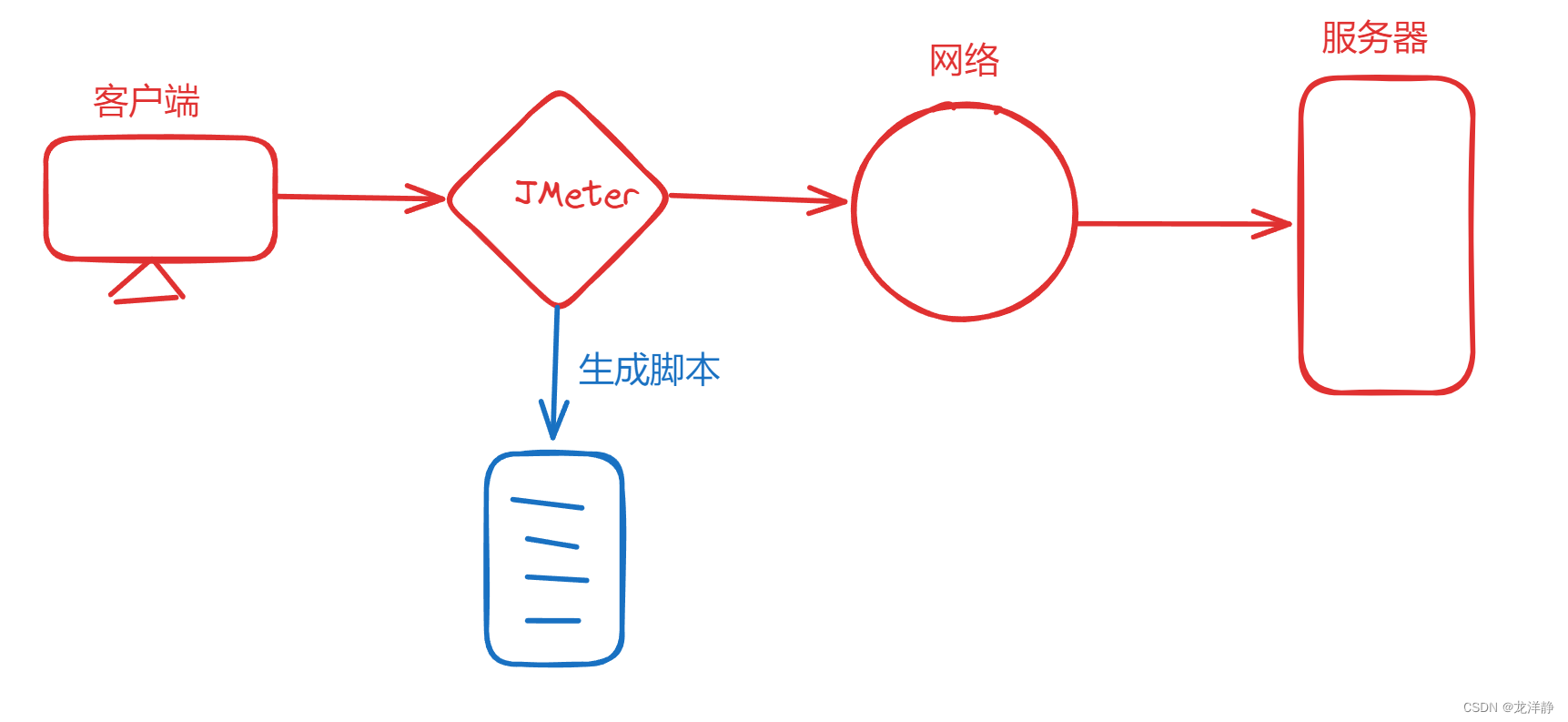
JMeter录制脚本原理:
正常请求过程:

JMeter录制过程:
1.2、JMeter脚本录制
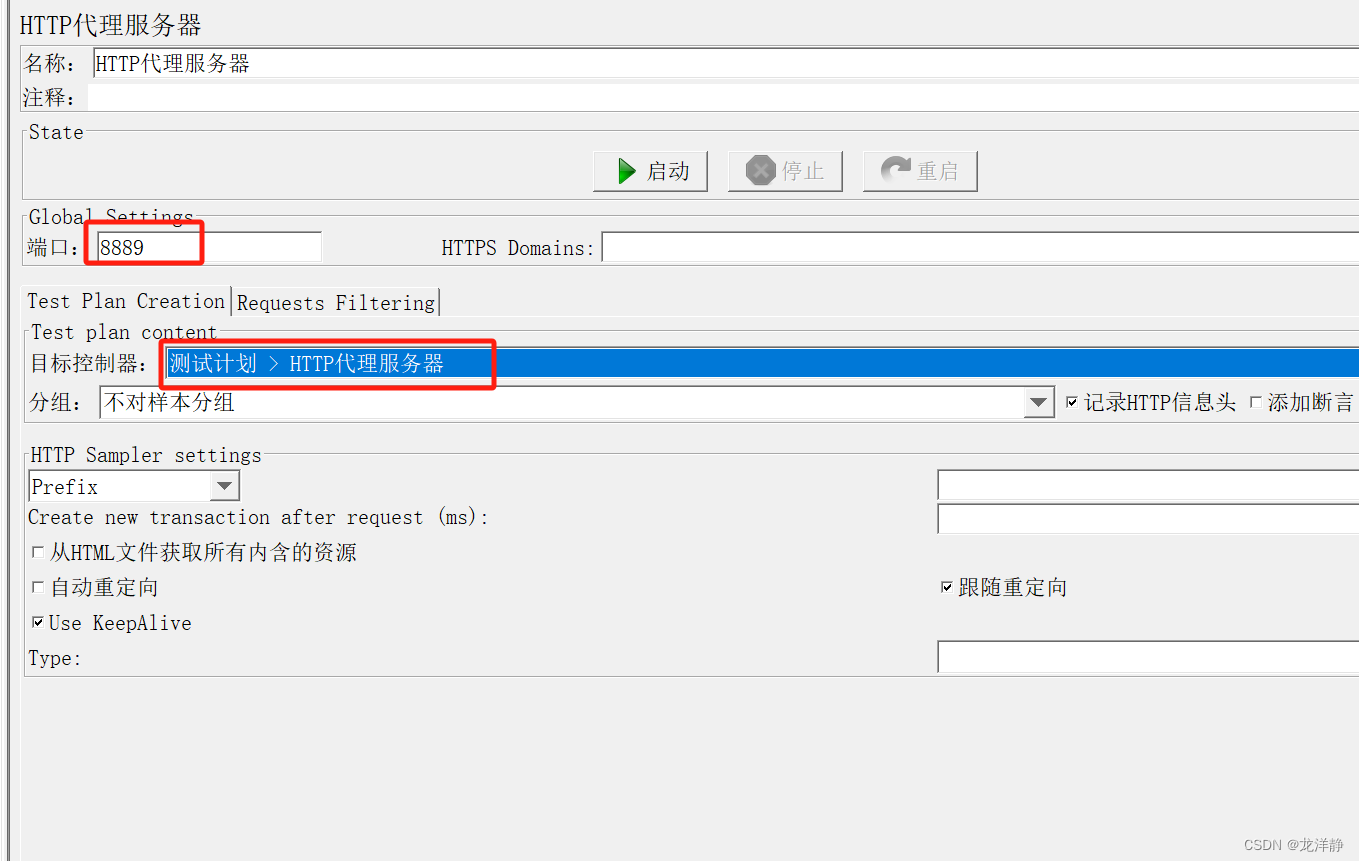
步骤一:添加http代理服务器,并进行配置
加http代理服务器:

配置代理服务器的参数:
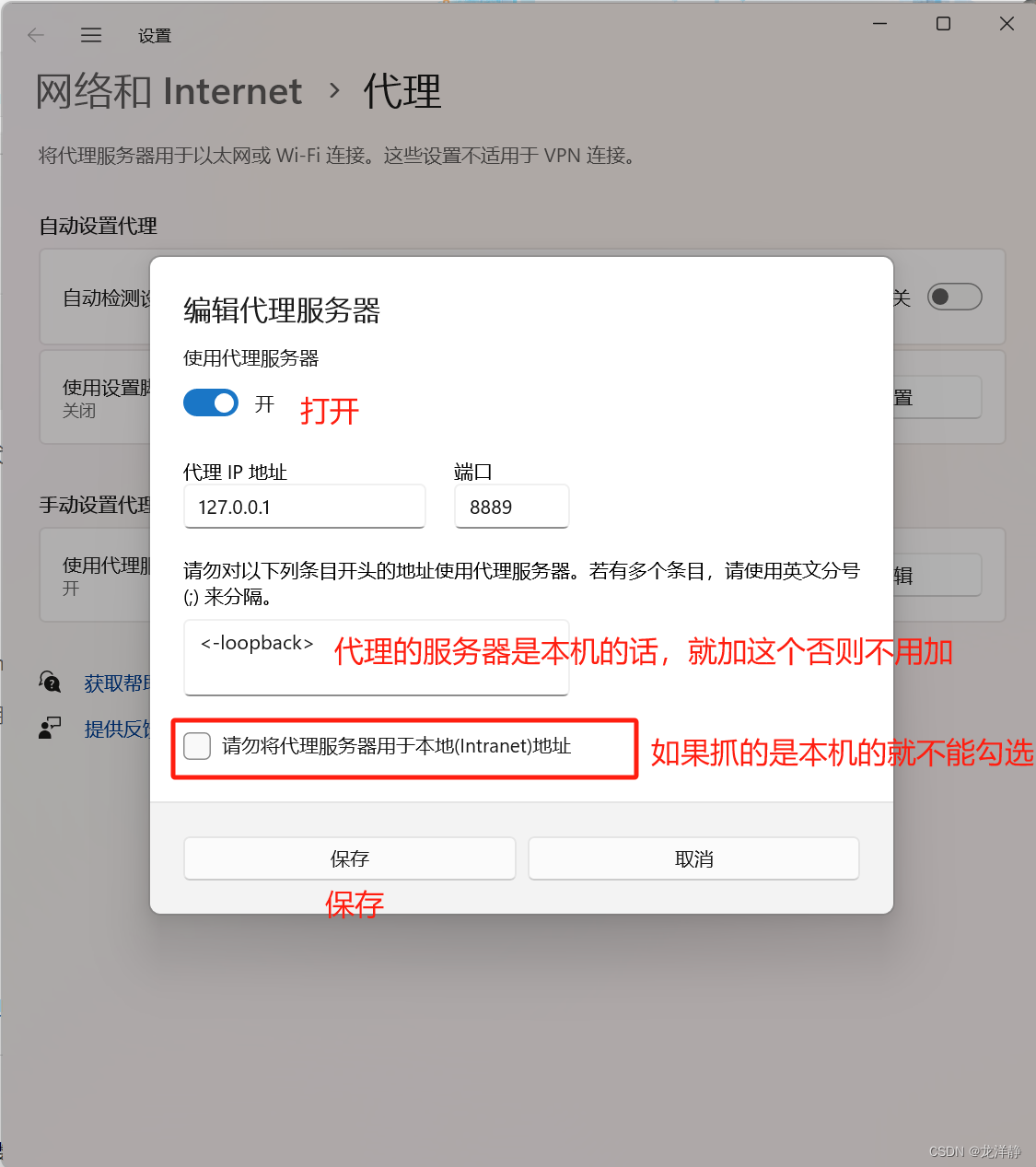
步骤二:开启Windows操作系统的浏览器代理
步骤三:启动代理服务器:

然后去,浏览器操作,有的可能要在Chrome浏览器,有的是IE,你都试试,看哪个能抓到:
我这边是Chrome浏览器,我浏览了我本机服务器下的一个博客系统的网页,如下:
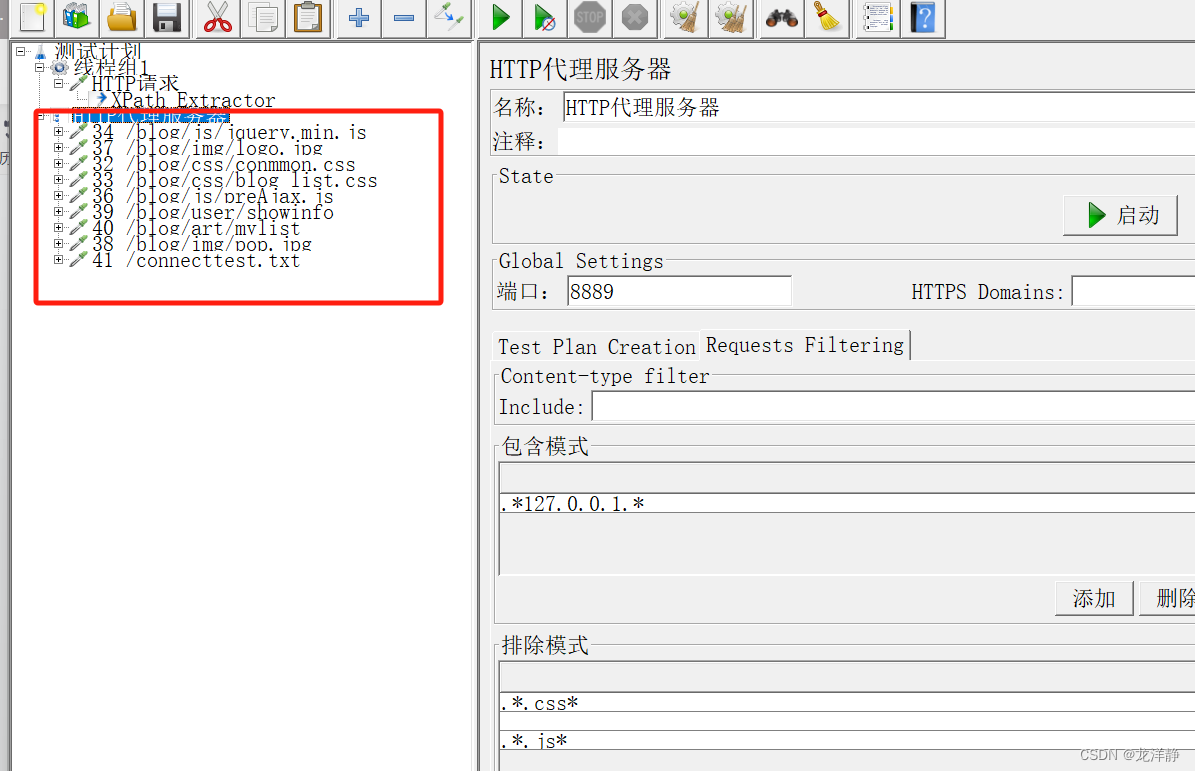
我们这就是成功了~
我们可以看到上面有很多是css文件js文件,我们不想获取这类的文件,可以在http代理服务器的配置中做如下修改:

包含就是:匹配则抓取;排除模式:匹配则丢弃【不抓取】~
2、JMeter直连数据库
2.1、直连数据库的作用
- 用作请求的参数化。例如:登录时需要的用户名,可以从数据库中查询获取
- 用作结果断言。例如:添加购物车下订单,检查接口返回的订单号,是否与数据库中生成的订单号一致
- 清理垃圾数据。例如:添加商品时(添加商品编号不能重复),重复时执行该脚本不能成功,需要在下次执行前删除该商品数据(取消添加)
- 准备测试数据。例如:通过数据库来准备大量的(几十万条)的性能测试数据
2.2、JMeter直连数据库的步骤
我们先要准备一个MySQL驱动包,我们在MySQL官网中下载即可,下载jar的版本最好和你使用的MySQL的版本一致~下载后,是得到一个压缩包,你解压缩后里面就有一个jar包了~
步骤一:添加MySQL驱动jar包
方式一:在测试计划面板点击:浏览..按钮,将你的JDBC驱动添加进来

方式二:将MySQL驱动jar包放入到lib/ext目录下,重启JMeter

步骤二:配置数据库连接信息
位置:
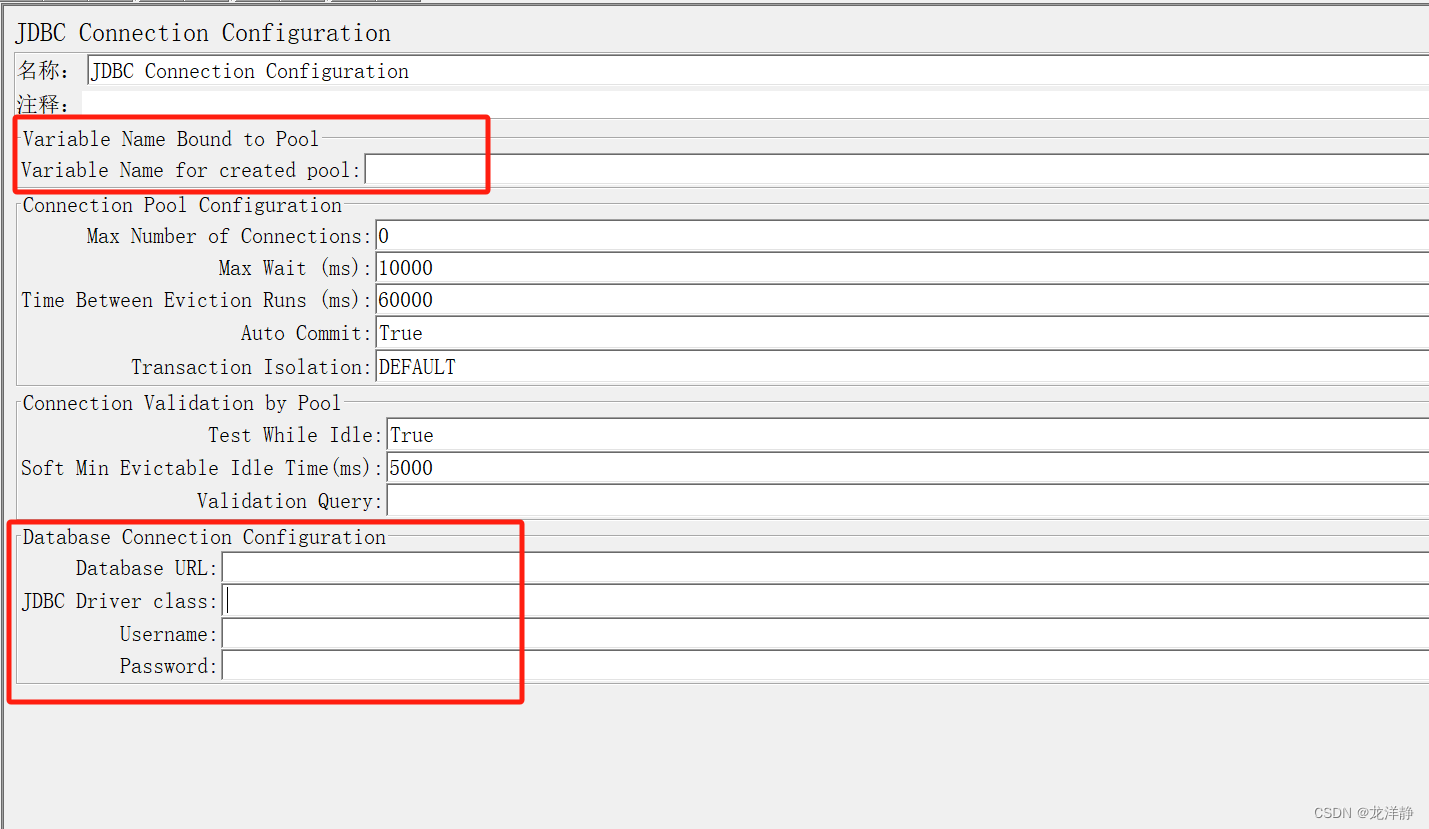
参数介绍:
- Variable Name for created pool:MySQL数据库连接池名称(JDBC请求时要引用,自己命名)
- Database URL:jdbc:mysql://localhost:3306/cnblog【协议 + 数据库IP + 数据库端口 +连接的数据库名,例我这里,协议是jdbc:mysql,数据库IP是本机,端口3306,数据库名是cnblog】
- JDBC Driver class:com.mysql.jdbc.Driver【下拉框】
- Username:root【连接的数据库用户名,如实填写】
- Password:****【连接的数据库密码,如实填写,密码为空就不写】
如下:

步骤三:添加JDBC请求
位置:
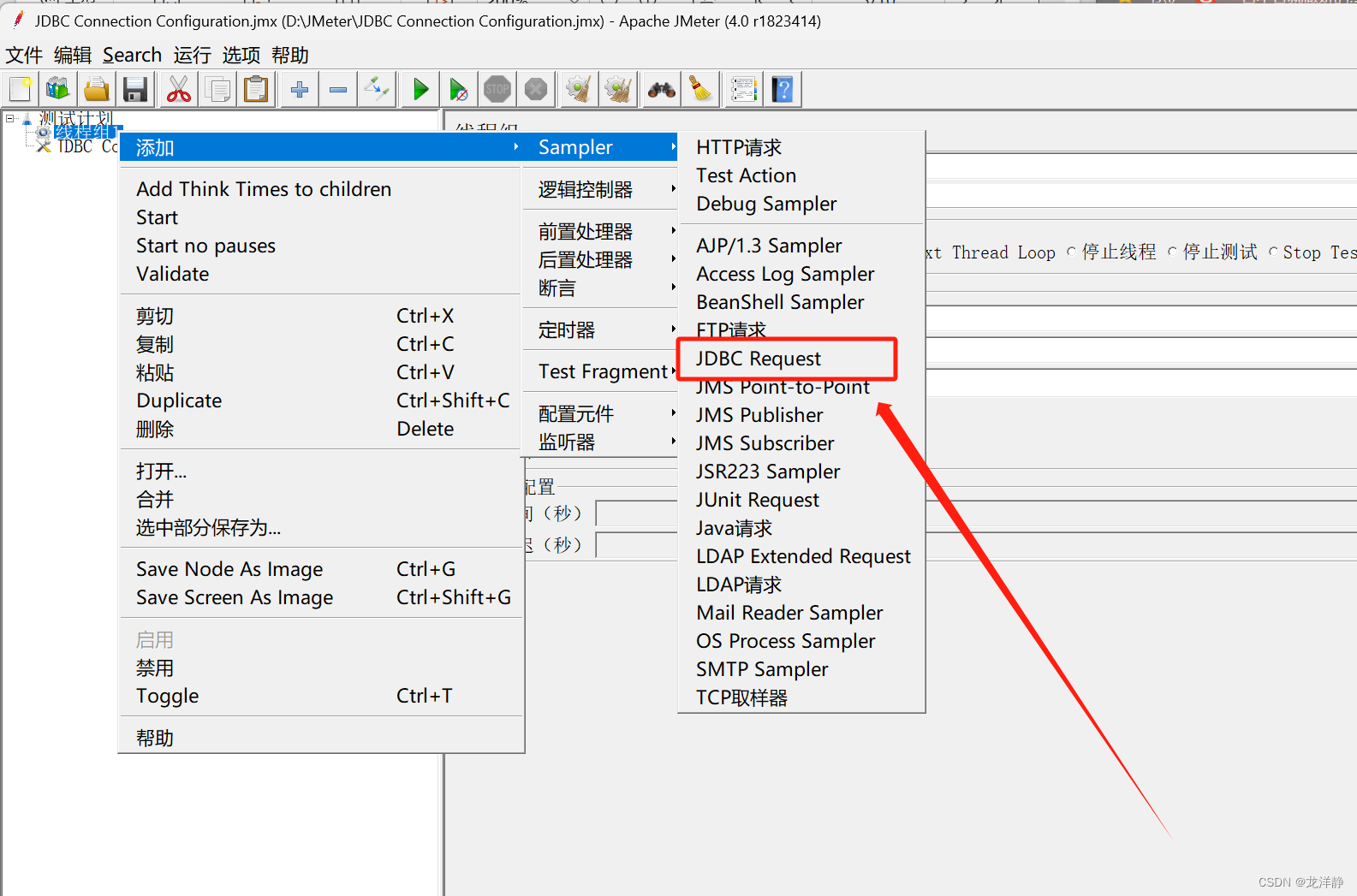
添加:

参数介绍:
- Variable Name:数据库连接池的名字,就是上面你自己命名的那个名字
- Query Type:自己选择是什么操作,有:增删改查~
- Query:填写SQL语句,末尾不要";"
- Variable names:保存sql语句返回结果的变量名
案例:
我刚才的JDBC连接配置的就是我本机数据库中的cnblog库,所以我们就使用这个库,这个库中有一张用户表,我们现在来查查这张表有多少个用户吧~
步骤:
- 添加一个线程组
- 添加JDBC Connection Configuration

- 添加JDBC request

- 添加一个正则表达式,取结果

- 添加http请求
- 添加查看结果树
- 运行看结果

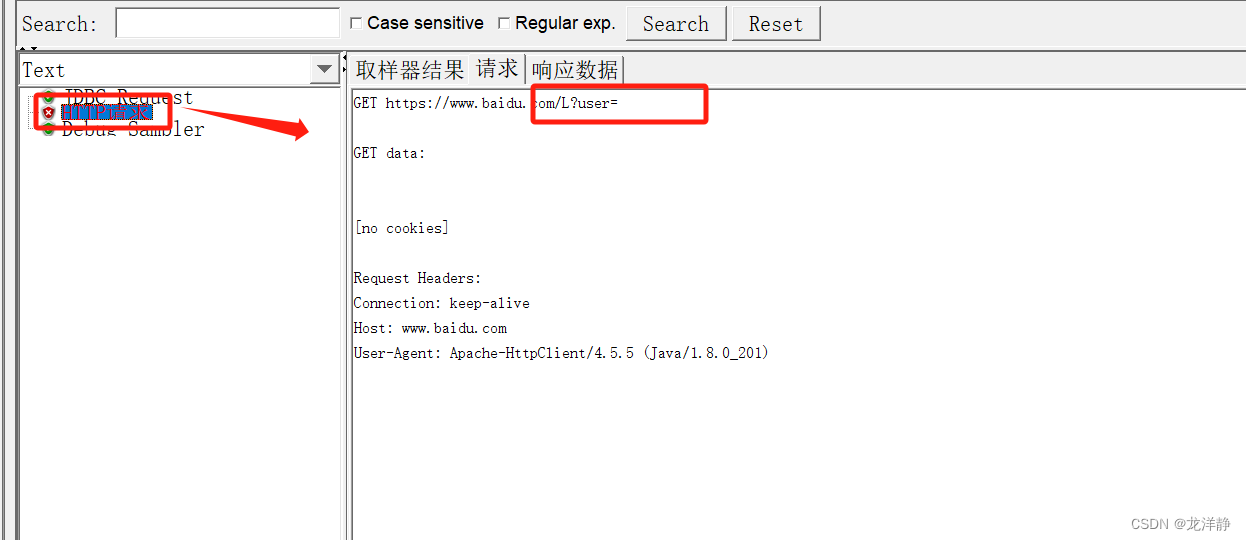
这个请求数据不对,我们添加一个调试取样器,来看看,到底有没有值:
重新运行看看:

所以我们来修改一下请求中的变量:
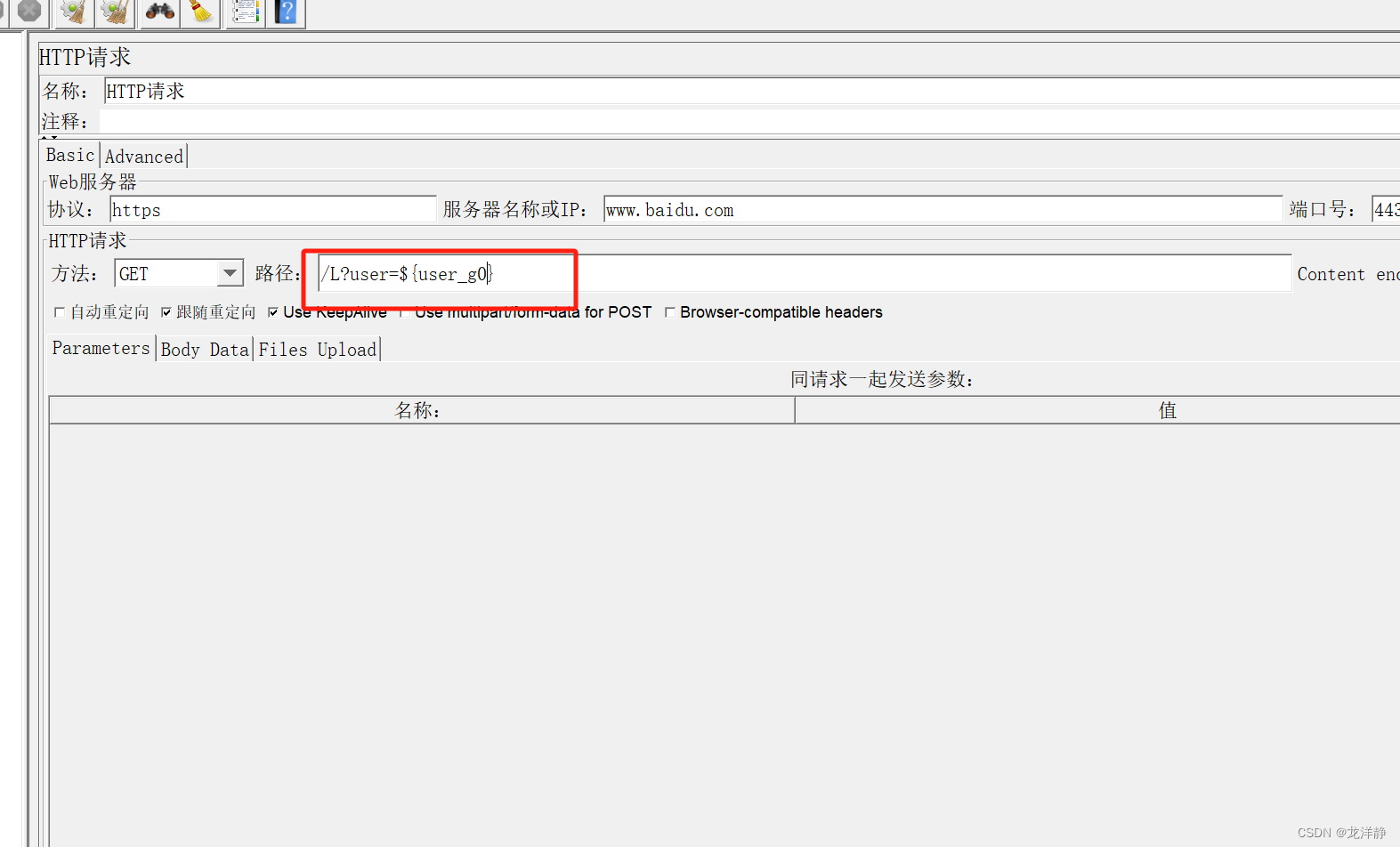
运行看结果:

成功~
3、JMeter的逻辑控制器
3.1、if控制器
作用:if控制器用来控制指定的测试元素是否运行
位置: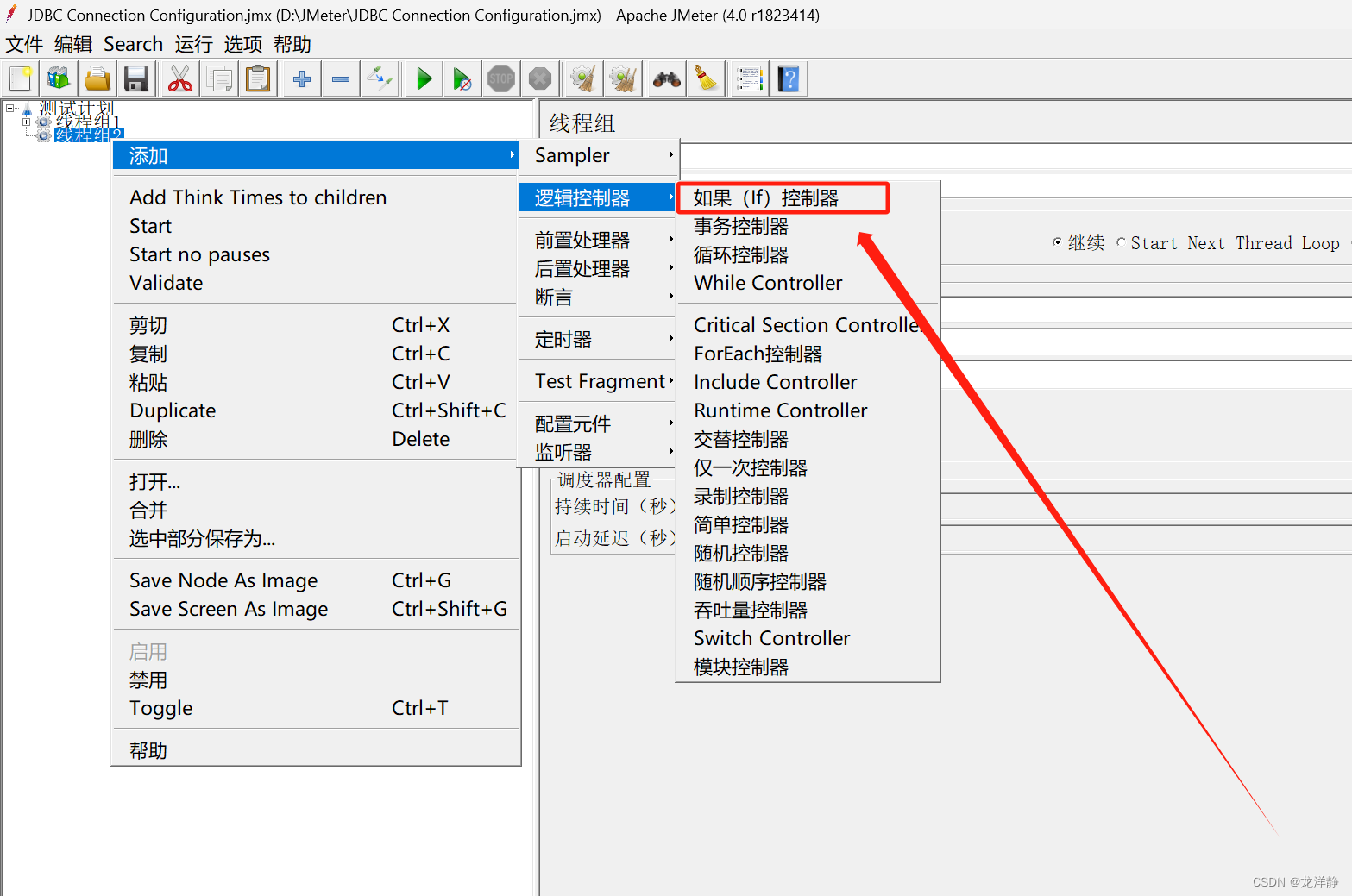

参数说明:
- Expression (must evaluate to true or false) :表达式(值必须是true或false),也就是说,在右边文本框中输入的条件值必须是true 或 false,(默认情况下)
- Interpret Condition as Variable Expression?:默认勾选项,将条件解释为变量表达式(expression中不能直接填写条件表达式,需要借助函数将条件表达式计算为true/false,可以借助的函数有_jexl3和_groovy)【选中这一项时表示:判断变量值是否等于字符串true(不区分大小写)】【不选中:直接输入我们需要判断的表达式即可,判断表达式为真时,执行if控制器下的请求,例如“1!=2”,则一定会执行下面的http请求】
- Evaluate for all children?:条件作用于每个子项,执行每个子项,都会判断一次条件。一般不勾选,条件一般只判断一次即可
解释:
- 上面有一个黄色感叹号,就是提示你使用__jexl3 or __groovy 表达式,以提高性能,也就是默认的方式
-
jexl全称:Jakarta Commons Jexl,是一种表达式语言(Java Expression Language)解释器
举例1,直接输入我们需要判断的表达式:
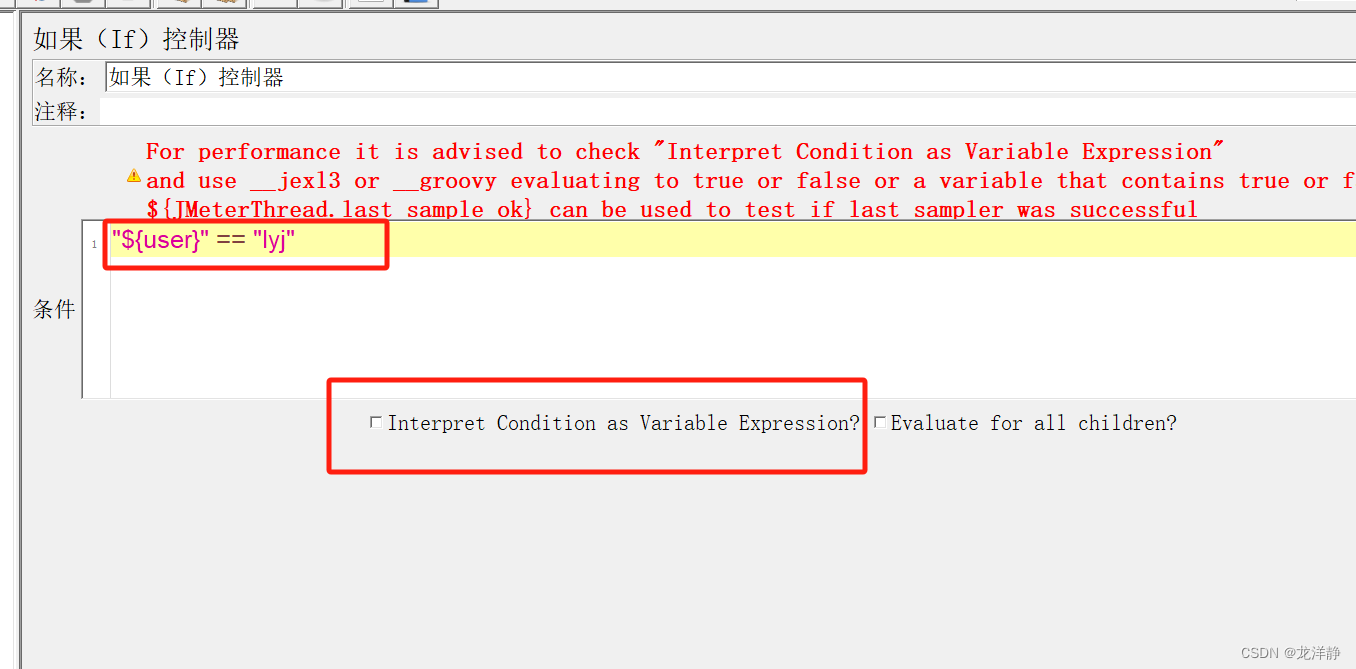
举例2,使用函数:


案例:
步骤:
- 创建一个线程组
- 创建一个用户定义的变量,在这里添加一个变量,名为title,值为百度
- 创建一个if控制器,和上面的步骤一样,在函数中生成,复制过来,比较title值等不等于百度
- 在if控制器下创建一个http请求【if为真请求可发送,为假,请求不发送】
- 创建一个查看那结果树
目录结构:

运行看结果:
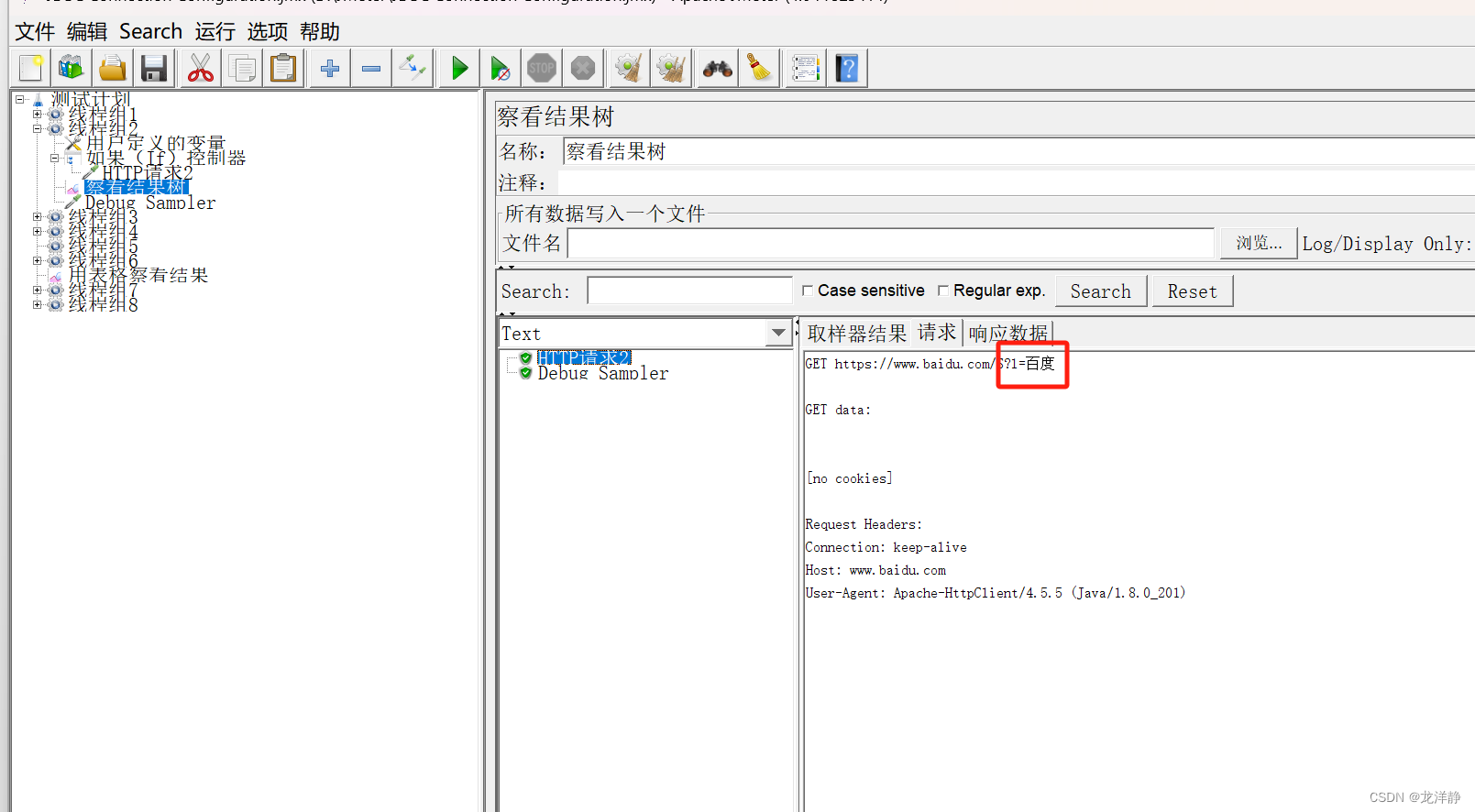
你可以尝试修改值,不相等时,请求就不会发送了~
3.2、循环控制器
位置:
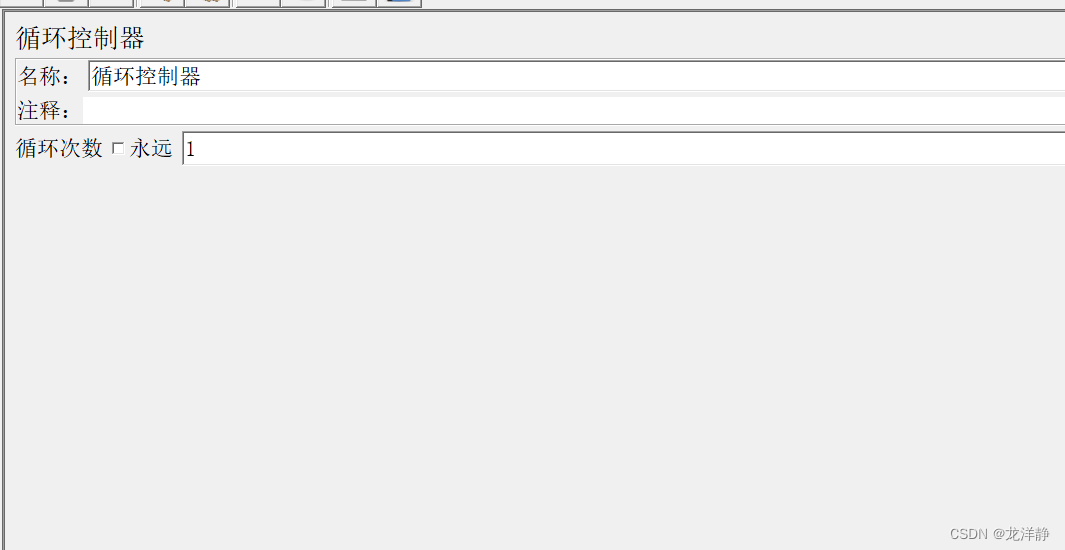
参数都是中文就不介绍了~
案例:
- 添加一个线程组
- 添加一个循环控制器,循环次数设置为3
- 在上面这个循环控制器下面添加一个http请求
- 添加一个表格查看结果树
目录结构:
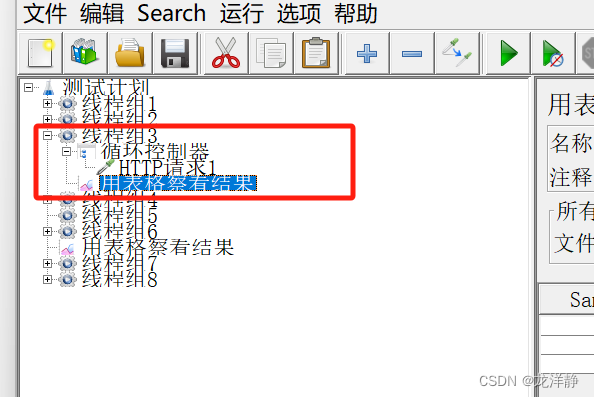
运行结果:

3.3、ForEach控制器
作用:一般和用户自定义变量或者正则表达式提取器一起使用,读取返回结果中一系列相关的变量值。该控制器下的取样器都会被执行一次或多次,每次读取不同的变量值。
位置:
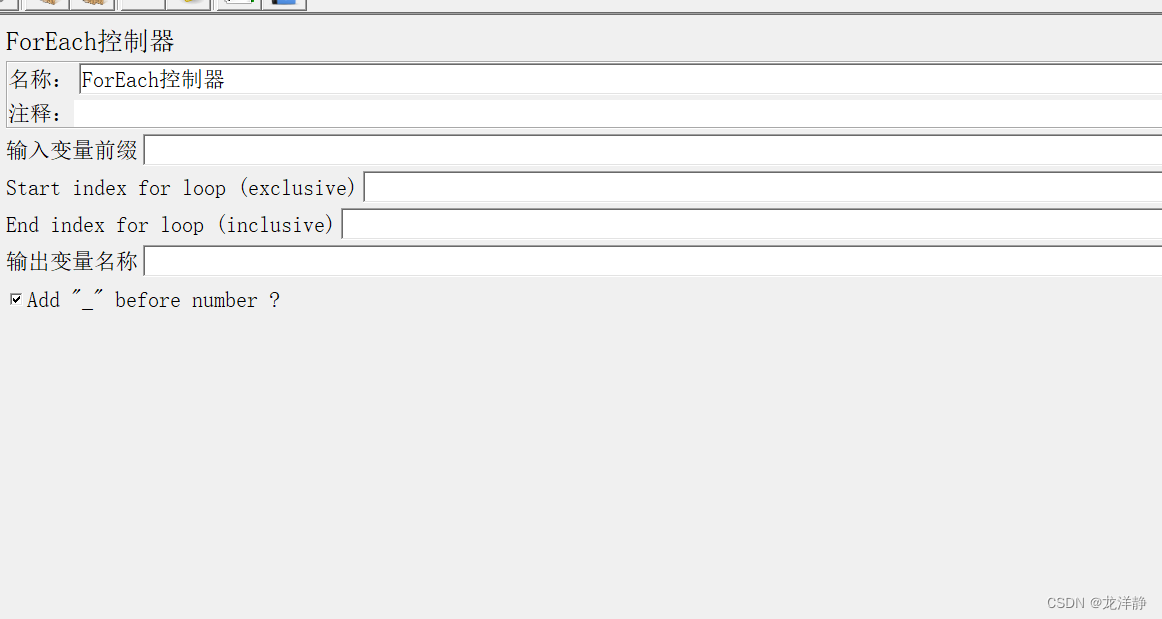
参数介绍:
- 输入变量前缀:要读取的输入变量的固定前缀
- Start index for loop(exclusive):开始循环字段(不包含)。要读取的输入变量后缀数字的最小值-1
- End index for loop(inclusive):结束循环字段(包含)。要读取的输入变量后缀数字的最大值
- 输出变量名称:读取输入变量的值后保存的新变量名,用于后续http请求来引用~
案例:使用用户自定变量~
步骤:
- 添加一个线程组
- 添加一个用户定义的变量:

- 添加foreach循环器:

- 在控制器下面添加一个http请求:

- 添加生成结果树
目录结构:
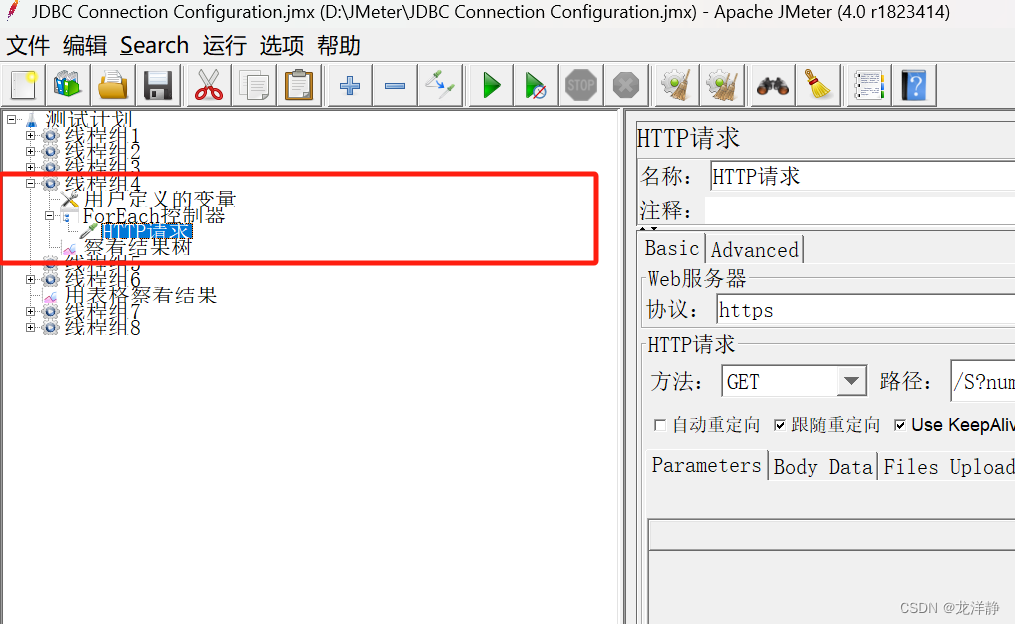
运行结果:
例如查看第5个请求:
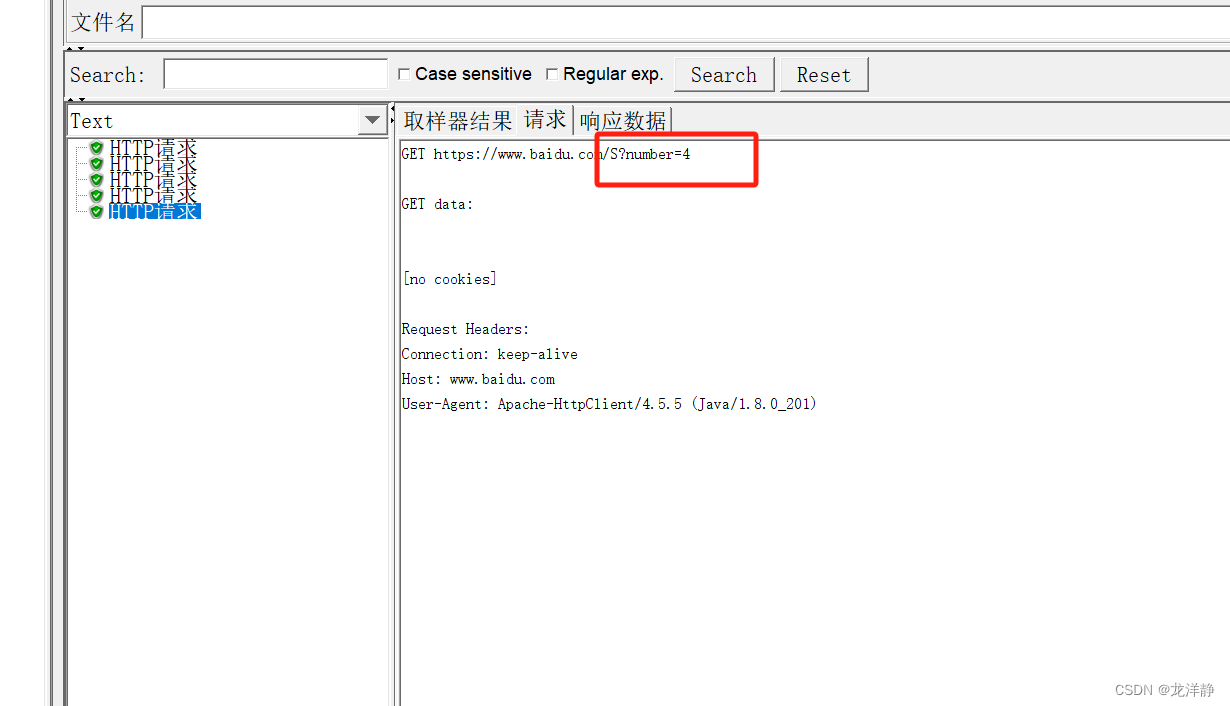
4、JMeter的定时器
4.1、同步定时器
同步定时器:阻塞线程(累计一定的请求),当在规定时间内达到一定的线程数量,这些线程会在同一个时间点一起释放,瞬间产生很大的压力。
位置:

参数介绍:
- Number of Simulated Users to Group by:模拟用户的数量,即指定同时释放的线程数数量。如果设置为0,表示设置为线程组中的线程数量
- Timeout in milliseconds:超时时间,即超时多少毫秒后同时释放指定的线程数。如果设置为0,表示该定时器将会等待线程数达到了设置的线程数才释放,若没有达到设置的线程数会一直死等;如果设置的值大于0,那么如果超过设置的最大等待时间还没有达到设置的线程数,Timer将不再等待,释放已到达的线程。默认为0.
案例:
步骤:
- 添加一个线程组,线程数设置为20
- 添加一个http请求
- 添加同步定时器,模拟用户数量设置为5,超时为100
- 添加一个表格查看结果树
目录:

运行结果:

前五个为一组,几乎是同一时间发送的请求~
4.2、常数吞吐量定时器
作用:可以让线程以一个目标吞吐量去运行
位置: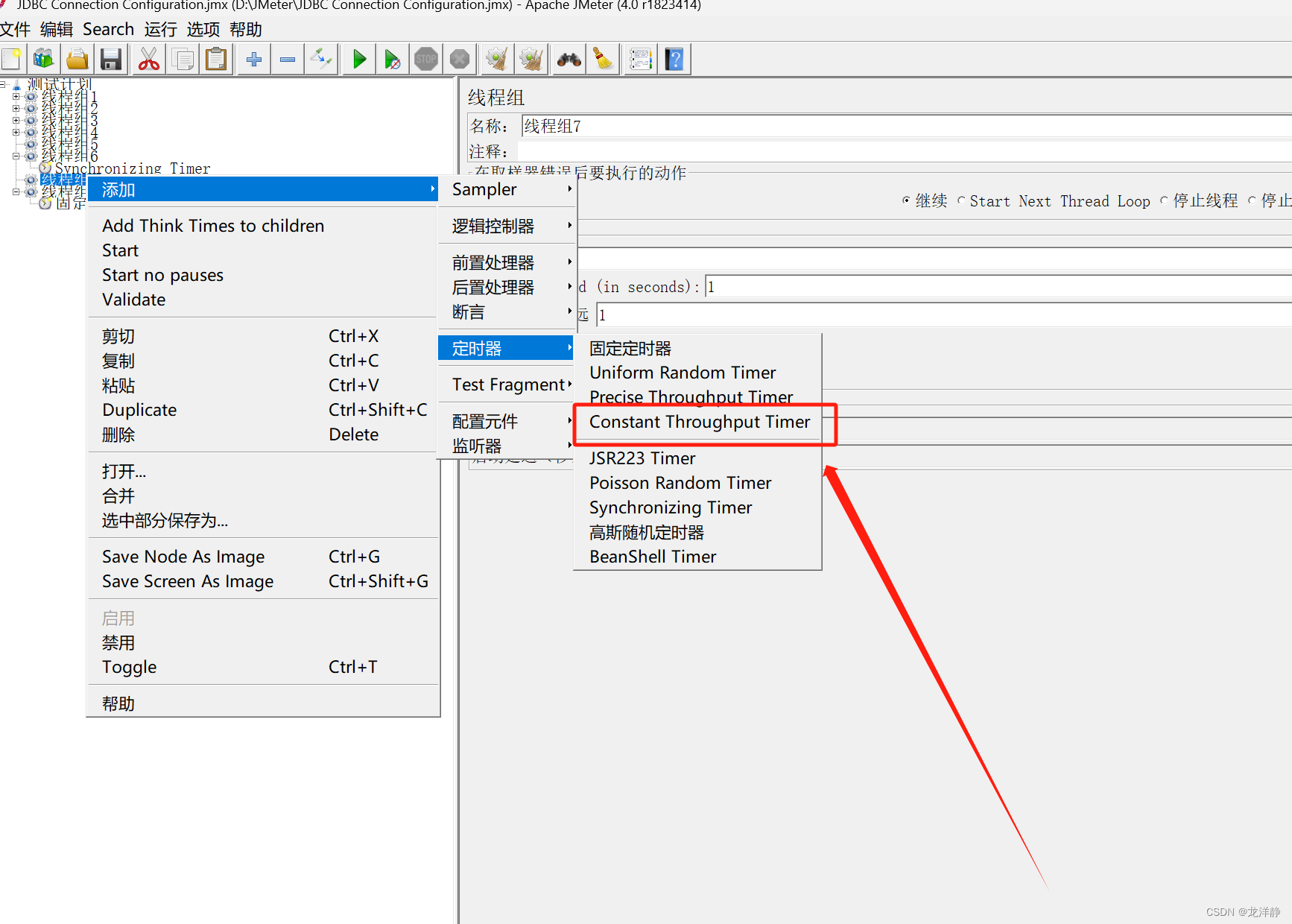

参数说明:
- Target throughput (in samples per minute):目标吞吐量(每分钟的样本量)。每分钟的吞吐量
- Calculate Throughput based on:基于什么计算吞吐量
- this thread only:只有此线程。控制每个线程的吞吐量,选择这种模式时,总的吞吐量为设置的target Throughput(上面设置的每分钟的吞吐量) 乘以该线程的数量
- all active threads:所有活动线程。设置的target Throughput 将分配在每个活跃线程上,每个活跃线程在上一次运行结束后等待合理的时间后再次运行。活跃线程指同一时刻同时运行的线程
- all active threads in current thread group:当前线程组中的所有活动线程。设置的target Throughput 将分配在当前线程组的每一个活跃线程上,当测试计划中只有一个线程组时,该选项和all active threads 选项的效果完全相同
- all active threads (shared):所有活动线程(共享)。与all active threads的选项基本相同。唯一区别是,每个活跃线程都会在所有活跃线程上一次运行结束后等待合理的时间后再次运行
- all active threads in current thread group (shared):当前线程组中的所有活动线程(共享)。与all active threads in current thread group 基本相同,唯一的区别是,每个活跃线程都会在所有活跃线程的上一次运行结束后等待合理的时间后再次运行
案例:
步骤:
- 添加一个线程组

- 添加一个常数吞吐量定时器

- 添加一个调试取样器
- 添加一个聚合报告
目录结构:

运行结果:

3秒发送了33个请求~
4.3、固定定时器
作用:在两个请求之间,第一个请求发送之后等待一段时间再发送第二个请求。
位置:

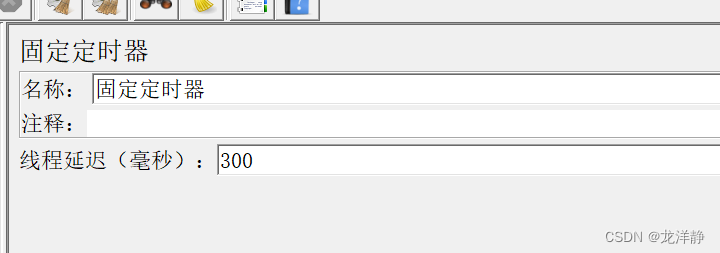
上面这里设置的延迟时间就是请求1发送后等300毫秒再发后面的请求~
案例:
步骤:
- 添加一个线程组
- 添加一个http请求1
- 添加一个固定定时器,时间设置为3000毫秒,也就是3s
- 添加http请求2
- 添加一个表格查看结果树
目录结构:

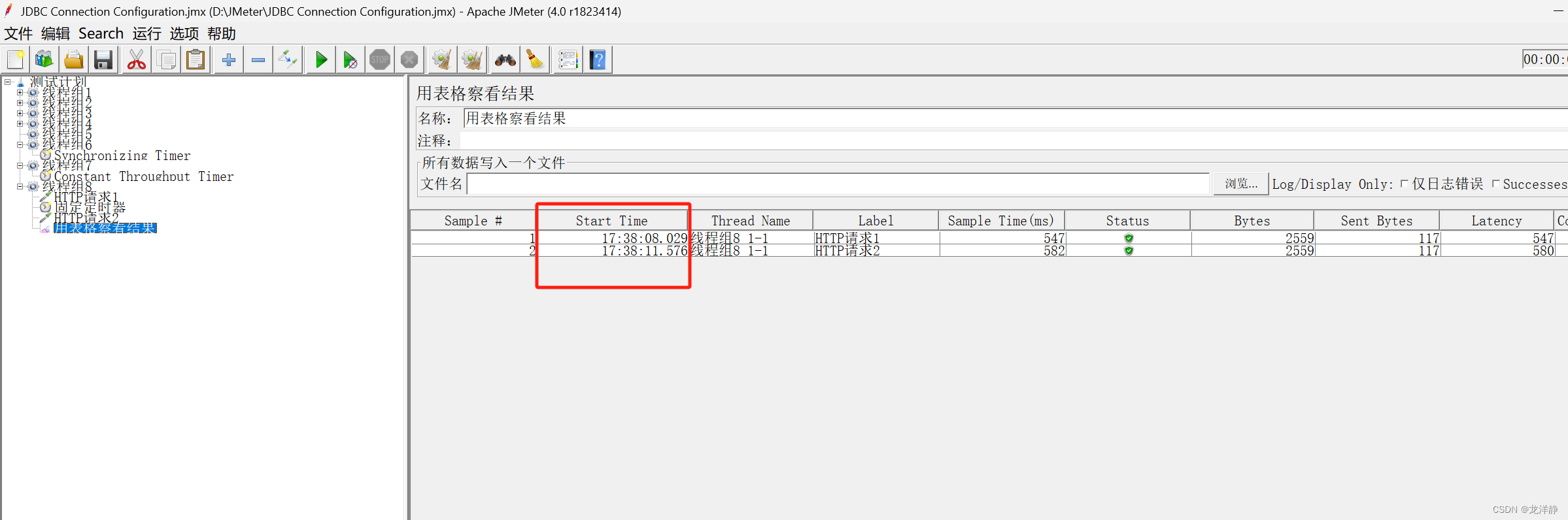
运行观察结果:
相差3秒:
好啦,我们先这里咯,下期见~
)



)


---超详细)











![[已解决]该主机与 Cloudera Manager Server 失去联系的时间过长。 该主机未与 Host Monitor 建立联系。](http://pic.xiahunao.cn/[已解决]该主机与 Cloudera Manager Server 失去联系的时间过长。 该主机未与 Host Monitor 建立联系。)