最近我在 International Journal of Digital Earth (《国际数字地球学报》)发表了一篇森林生物量模型构建的文章:Evaluation of machine learning methods and multi-source remote sensing data combinations to construct forest above-ground biomass models,主要是利用多源遥感变量开展样地生物量反演具体请前往原文:https://www.tandfonline.com/doi/full/10.1080/17538947.2023.2270459
文章出发点
虽然已有一些研究探索了利用多源遥感变量估算森林 AGB 的方法(Sinha 等引文 2016;Su 等引文 2016;Sun 等引文 2011;Zhang 等引文 2020),但目前还没有具体的构建过程来选择 ML 方法和不同的遥感变量组合(Lu 引文 2006)。在此,我们采用最优 ML 方法,使用单一输入数据类型构建不同的森林 AGB 模型,并构建多源遥感变量与最优单一变量进行比较。然后根据多源遥感变量的重要性和多源遥感变量阵列之间的相关性构建多源遥感变量组合,以检验最佳森林 AGB 模型。然而,为了准确测定混交林的生物量,有必要考虑遥感数据中树种的具体差异。本文的目的是:(i) 改进不同森林类型(即阔叶林、针叶林和混交林)的 AGB 估算;(ii) 确定遥感数据的最佳组合,以提高使用 ML 方法估算森林 AGB 的准确性;(iii) 对太岳山下霍东煤矿区域内的森林进行勘探,以验证所选方法。
题目
Evaluation of machine learning methods and multi-source remote sensing data combinations to construct forest above-ground biomass models
ABSTRACT
Rapid and accurate estimation of forest biomass are essential to drive sustainable management of forests. Field-based measurements of forest above-ground biomas (AGB) can be costly and difficult to conduct. Multi-source remote sensing data offers the potential to improve the accuracy of modelled AGB predictions. Here, four machine learning methods: Random Forest (RF), Gradient Boosting Decision Tree (GBDT), Classification and Regression Trees (CART), and Minimum Distance (MD) were used to construct forest AGB models of Taiyue Mountain forest, Shanxi Province, China using single and multi-sourced remote sensing data and the Google Earth Engine platform. Results showed that the machine learning method that most accurately predicted AGB were GBDT and spectral index for coniferous (R2 = 0.99; RMSE = 65.52 Mg/ha), broadleaved (R2 = 0.97; RMSE = 29.14 Mg/ha), and mixed-species (R2 = 0.97; RMSE = 81.12 Mg/ha) forest types. Models constructed using bivariate variable combinations that included the spectral index improved the AGB estimation accuracy of mixed-species (R2 = 0.99; RMSE = 59.52 Mg/ha) forest types and reduced slightly the accuracy of coniferous (R2 = 0.99; RMSE = 101.46 Mg/ha) and broadleaved (R2 = 0.97; RMSE = 37.59 Mg/ha) forest AGB estimation. Overall, parameterizing machine learning algorithms with multi-source remote sensing variables can improve the prediction accuracy of mixed-species forests.
摘要
快速和准确地评估森林生物量对于推动森林的可持续管理至关重要。通过野外调查来评估的森林地上生物量(AGB)不仅需要耗费巨大的人力物力,且观测面积有限,随着遥感影像技术的发展,利用多源遥感数据为大面积的AGB估算提供了可能。本文利用随机森林(Random Forest,RF)、梯度提升决策树(Gradient Boosting Decision Tree,GBDT)、分类回归树(Classification and Regression Trees,CART)和最短距离法(Minimum Distance,MD)四种方法构建山西省矿林复合区(太岳山和霍东矿区)AGB模型。结果表明,四种机器学习方法中GBRT方法所构建的AGB模型精度最高,在单一变量的AGB模型中,以光谱指数构建的的AGB模型精度最高,针叶树(R2=0.99;RMSE=65.52 Mg/ha)、阔叶林(R2=0.97; RMSE=29.14 Mg/ha)和混交林(R2=0.97; RMSE=81.12 Mg/ha) 。采用光谱波段和指数的双变量组合构建的AGB模型可有效提高混交林的预测精度(R2=0.99;RMSE=59.52 Mg/ha),而针叶树(R2=0.99;RMSE=101.46 Mg/ha)和阔叶林(R2=0.97; RMSE=37.59 Mg/ha) 的模型误差略有增加。总体而言,基于多源遥感变量的机器学习算法所构建的AGB模型可以提高混交林的模型精度,而单一树种的RMSE误差会增大。
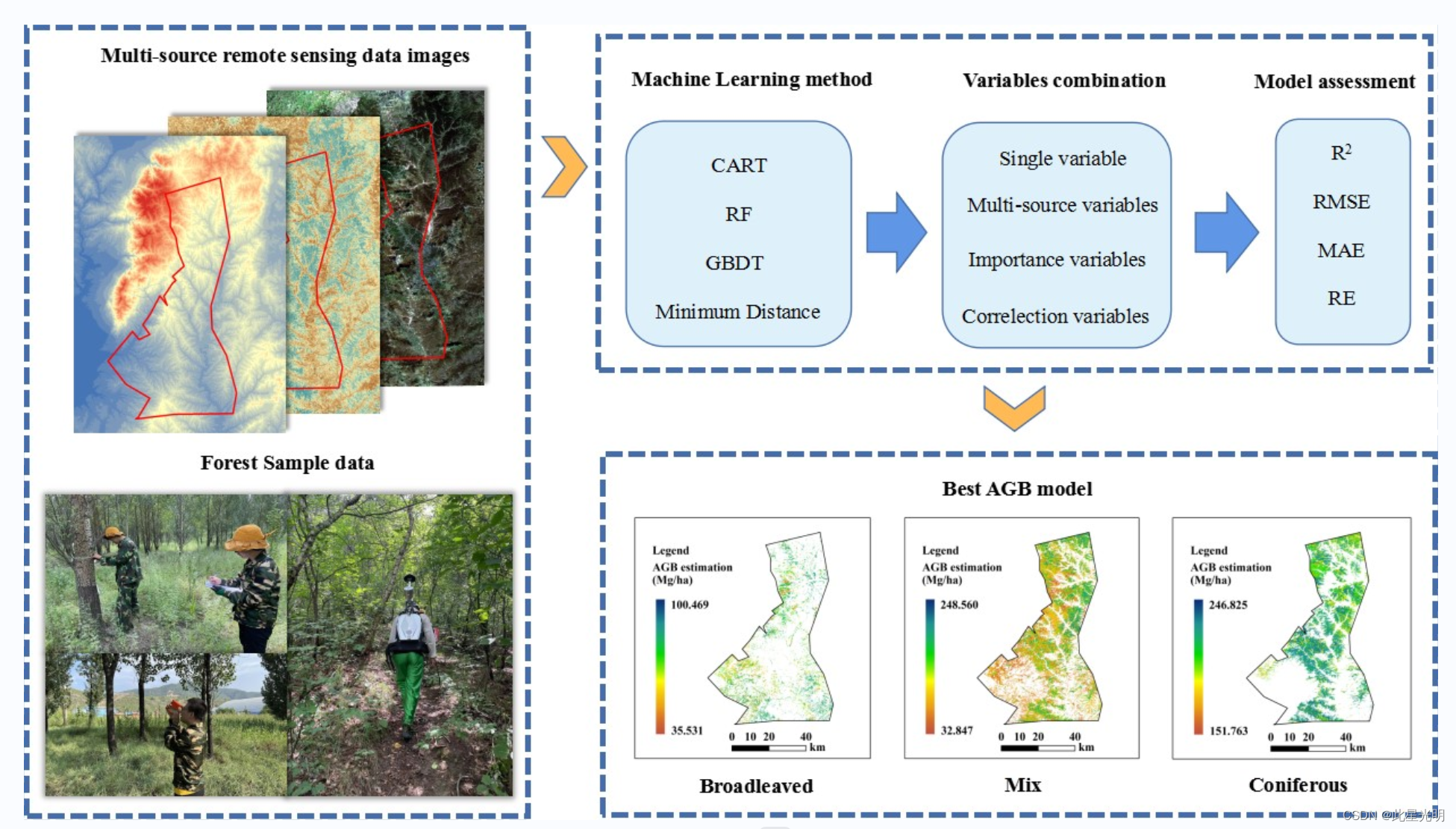
流程图
大多数科学文献并未解释如何选择合适的变量来开发和评估森林 AGB 模型。基于这一认识,我们设计了本实验,利用多源遥感变量组合构建森林 AGB 模型,然后比较不同变量组合对森林 AGB 模型的准确性,以更科学地遵循单一变量的最优组合,并揭示哪种变量组合的拟合效果最好。
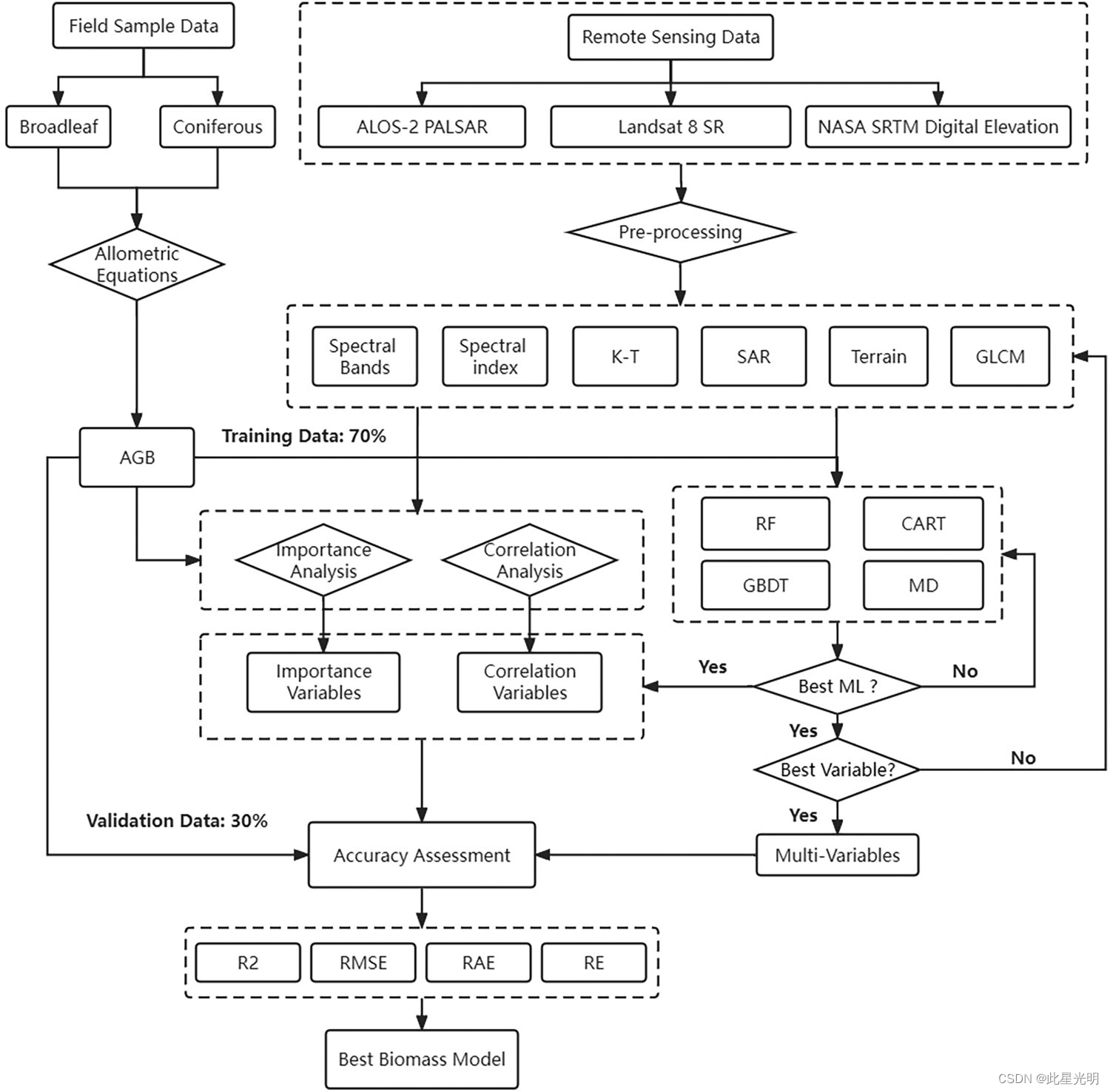
为了评估不同变量组合的效用及其在估算森林 AGB 方面的准确性,我们进行了四项实验:(i) 单一变量;(ii) 多源变量组合;(iii) 变量重要性;(iv) 皮尔逊相关系数。本研究中使用的四种 ML 方法(RF、CART、GBDT 和 MD)以 n = 500 个决策树参数进行了评估。通过评估以下四个指标对每个模型进行了分析:R2、RMSE、MAE 和 RE。卫星图像处理和使用 ML 生成森林 AGB 模型的详细流程图如图所示。
卫星图像处理和基于机器学习(ML)方法生成森林地上生物量(AGB)模型的流程图。在数据处理过程中获得的六种变量类型中,特征变量合成孔径雷达(SAR)来自 ALOS-2 PALSAR 数据。光谱波段、光谱指数、Kauth-Thomas(K-T)和灰度共现矩阵(GLCM)均来自 Landsat 8 SR 图像。地形变量来自美国国家航空航天局的航天飞机雷达地形图任务(SRTM)。
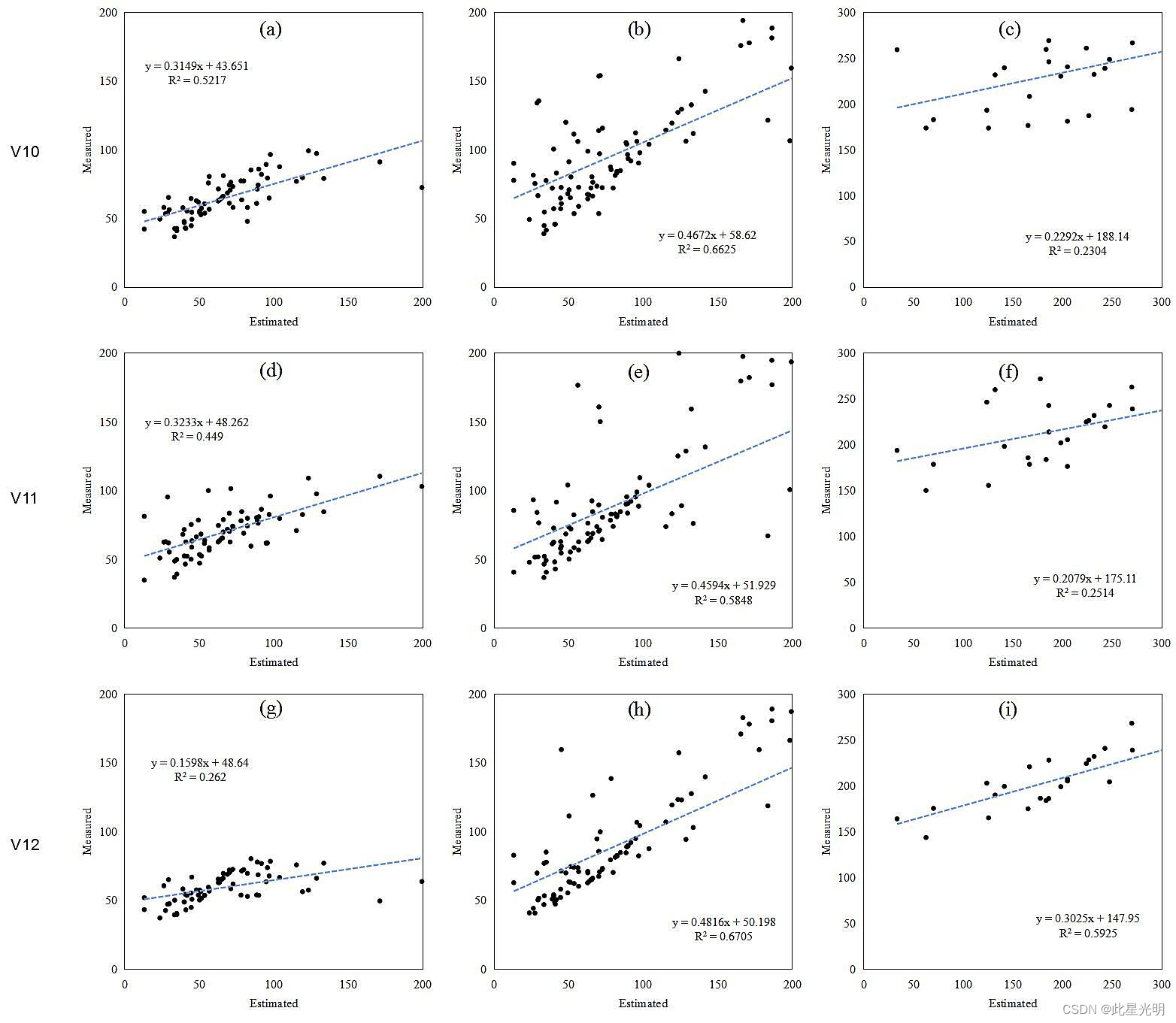
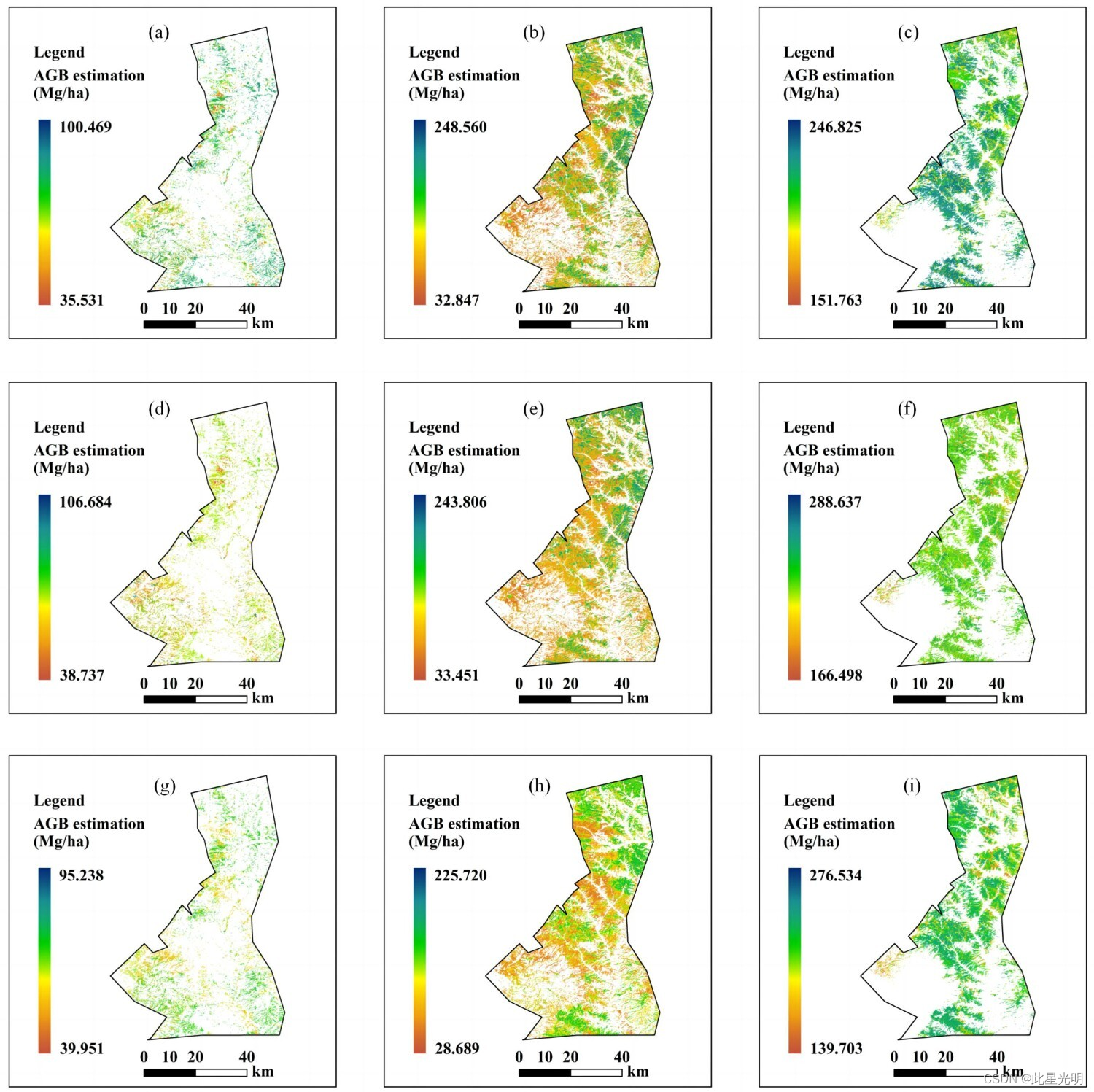
模型预测结果
讨论
本研究的目的是建立一个框架,用于选择 ML 方法和变量组合,以构建一个能准确预测不同森林类型中森林 AGB 的森林 AGB 模型。许多研究报道了 RF 方法在利用遥感数据预测森林 AGB 方面的卓越性能(Chen 等引文 2018;Zhang 等引文 2023b)。本文发现,GBDT 方法具有更高的森林 AGB 预测精度,尤其是当训练数据中的样本点数量较多时。然而,RF 和 GBDT 方法之间的差异并不明显,这与之前的研究结果一致(Tamiminia 等人,引用 2022)。本研究中使用的选择最佳森林 AGB 模型的方法和过程适用于所有森林 AGB 建模。尽管研究区域是位于复杂地形的混交林,但仍有可能对森林 AGB 进行准确预测。通过比较不同变量组合建立的生物量模型,结果表明变量数量与模型精度并无直接关系,两个变量组合的模型精度优于三个或更多变量组合的模型。经过重要性和相关性筛选后的变量建立的森林 AGB 模型的精度低于最佳单一变量组合。
不区分树种的森林 AGB 模型降低了森林 AGB 估计的准确性。区分不同树种以构建树种特异性森林 AGB 模型可能会使利用遥感技术对大面积森林 AGB 的评估更加准确。然而,构建树种特异性森林 AGB 模型需要投入大量精力和资源,以获得用于训练和验证的森林样地。在太岳山森林下的霍东煤矿地区,阔叶树大多分布在海拔较低的地方,导致采样点位于居民区附近,森林样地分布零散,这可能导致除光谱指数外,其他单一变量的总体拟合度较低(Zhang 等,引用 2023a)。相比之下,针叶林大多分布在人烟稀少的高海拔地区,这增加了森林资源清查数据收集的难度,也是本研究用于训练和验证的样本量有限的原因。尽管样本量有限,但由于针叶林的斑块往往位于不常受干扰的独特斑块中,因此仍能以合理的精度估算针叶林的 AGB。不过,由于针叶树种的样本量较小,在构建变量重要性和相关变量时,可能会因样本点不足而导致模型拟合精度不稳定。因此,如果随后使用 ML 方法构建生物量模型,建议收集足够的样本点,以便进行训练和验证活动(Yang 等,引用 2023)。根据本文的实验结果,单一树种生物量模型至少需要 100 个样本点。
在单变量和多源变量生物量预测模型中,样本数量决定了模型的准确性,如图 A 和 B(补充)所示。即使不区分树种,混交林 AGB 模型的预测结果也比单独预测阔叶林和针叶林的结果要好。在不同的变量组合中,用光谱指数和 K-T 构建的最佳模型对阔叶林的 AGB 预测最好,而对针叶林和混交林的最佳变量组合是光谱指数、纹理特征、光谱指数和波段。特别是针叶林的 AGB 模型参数化了纹理特征和光谱指数,似乎弥补了由于训练和验证样本量较小而导致的预测准确率较低的问题。
结论
本研究在 GEE 云平台中使用了四种 ML 方法,利用单源和多源变量组合构建了森林 AGB 模型,并利用变量重要性值和预测 AGB 值与测量 AGB 值之间的皮尔逊相关系数对其性能进行了评估。使用包括 R2、RMSE、MAE 和 RE 的完整模型评价系统来确定预测森林 AGB 的最佳模型。结果表明,使用 GBDT ML 方法获得了最佳模型结果。混交林的生物量估算最为准确。多源遥感数据和 ML 方法能够准确估算森林 AGB 生物量,从而快速估算复杂地形景观中的森林生产力、常量生物量和碳储量。
生物量预测模型应用APP
为了帮助可视化和解释,开发了三个基于 GEE 的应用程序,即
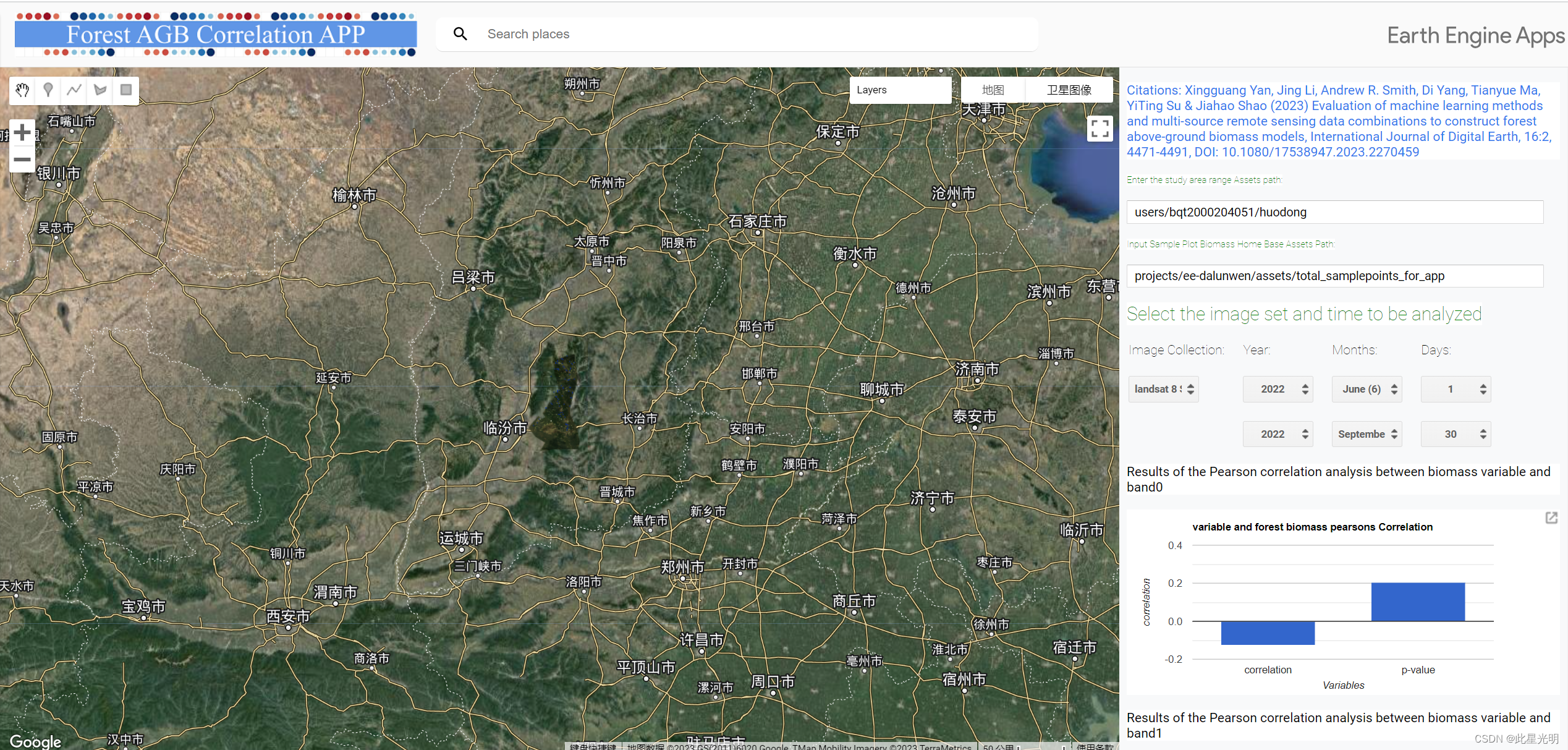
森林生物量与变量相关性分析应用程序
(https://bqt2000204051.users.earthengine.app/view/forest-agb-variables-correlation-analysis)
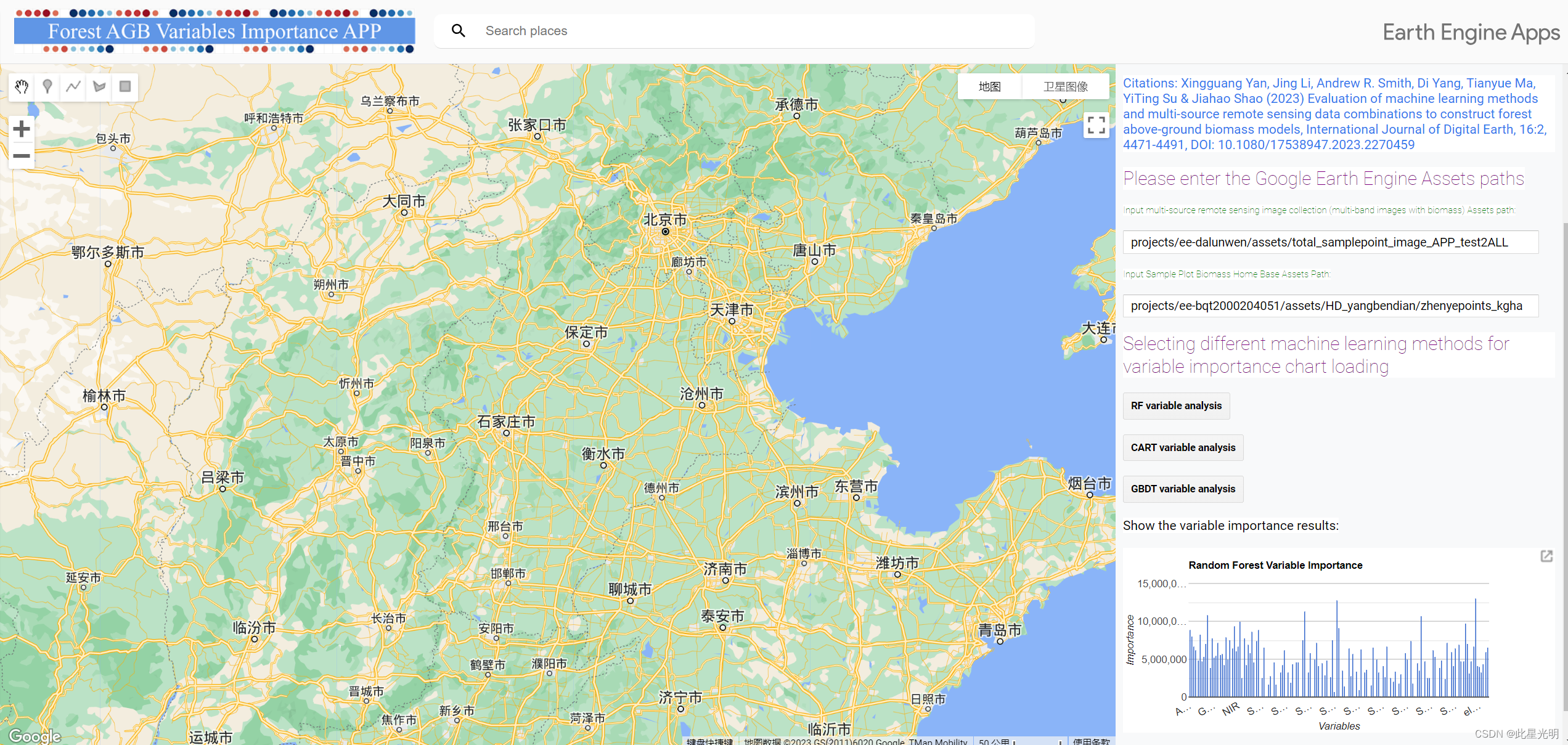
森林生物量与变量重要性分析应用程序
(https://bqt2000204051.users.earthengine.app/view/forest-agb-variable-importance-analysis)
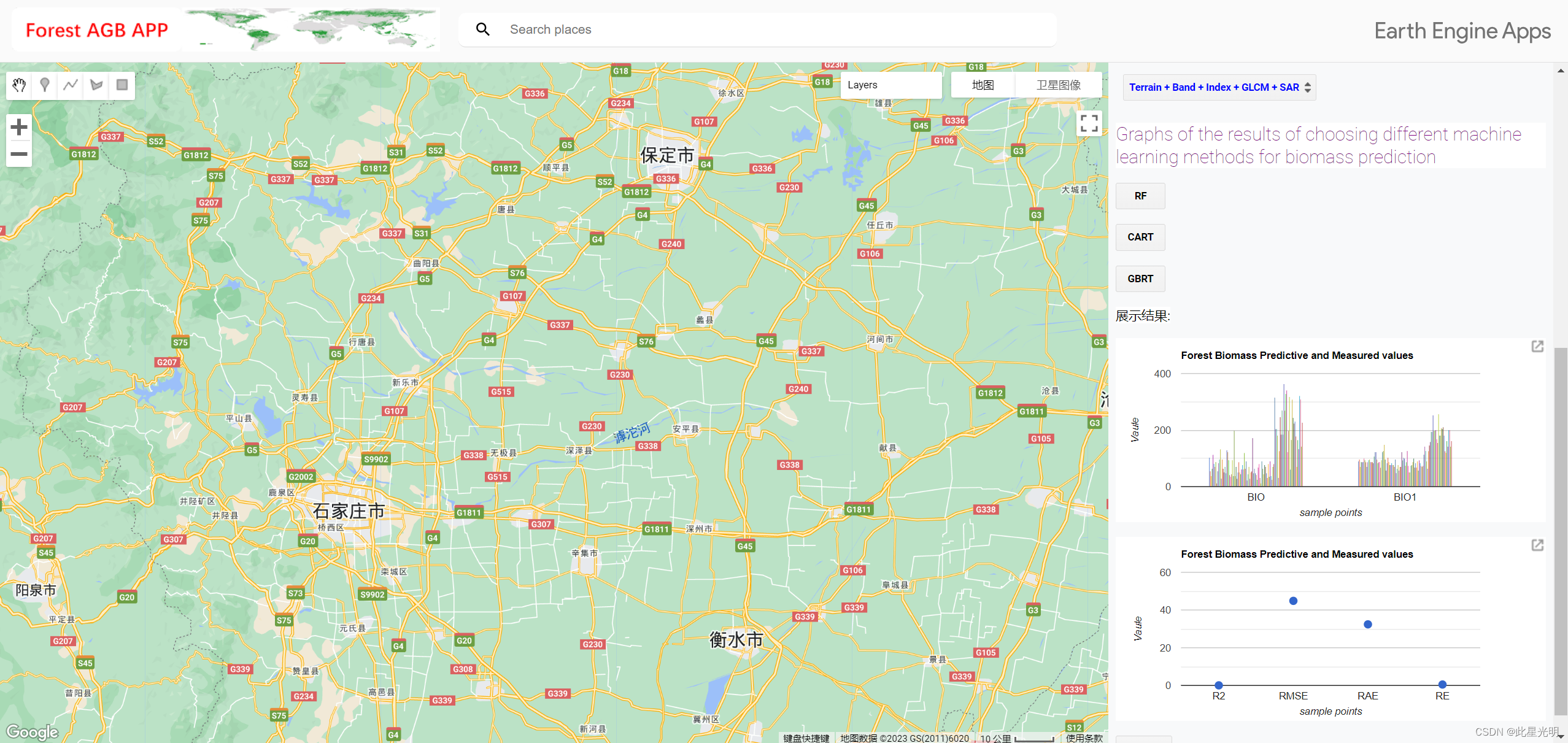
森林生物量预测应用程序
(https://bqt2000204051.users.earthengine.app/view/forest-aboveground-biomass-prediction)
将选定的多源遥感变量与采集的森林生物量相关联,并根据相关系数筛选出相关性高的遥感变量,用于生物量建模。
数百个变量的相关性分析结果包括相关系数和 p 值。森林生物量和变量重要性分析应用程序根据多源遥感变量和森林生物量进行变量重要性分析,并根据变量重要性结果选择多源遥感变量建立模型,变量重要性分析中提供了 RF、CART 和 GBDT ML 方法。森林生物量预测应用程序以上述应用程序为基础,但对其进行了扩展,允许用户使用本分析中使用的 30 种多源变量组合选择不同的 ML 方法进行生物量模型预测,并可在线比较森林 AGB 估计值和准确性(即 R2、RMSE、MAE 和 RE)的评估结果。
文章引用:
Xingguang Yan, Jing Li, Andrew R. Smith, Di Yang, Tianyue Ma, YiTing Su & Jiahao Shao (2023) Evaluation of machine learning methods and multi-source remote sensing data combinations to construct forest above-ground biomass models, International Journal of Digital Earth, 16:2, 4471-4491, DOI: 10.1080/17538947.2023.2270459

(Standard Template Library)【学习笔记(七)】)



:训练一个Glue的RTMPose模型)




图像分割)
)







+权衡 (Trade-off)”是什么?)