了解索引扫描吗?
答:
MySQL有两种方法生成有序结果:
- 通过排序操作
- 按照索引顺序扫描
如果 explain 出来的 type 列值为 “index” 的话,说明是按照索引扫描了。
索引扫描本身的速度是很快的。但是如果索引不能覆盖查询所需的全部列的话,那在每次查询索引时都需要回表再查询其他字段,这样的话,按索引顺序读取的速度通常比顺序地全表扫描要慢。如下图,select *时没有使用索引,select age时使用了索引。
explain select age from user order by age; # 结果1
explain select * from user order by age; # 结果2

设计:设计的时候,尽可能让同一个索引既满足排序,又用于查找行,这样是最好的。
只有当索引的列顺序和order by子句的顺序完全一致时,MySQL才能使用索引来对结果进行排序,如果查询需要关联多张表时,只有order by子句引用的字段全部为第一个表时,才能使用索引做排序。
order by查询时,需要满足索引的最左前缀要求,否则MySQL需要执行排序操作,无法利用索引进行排序。
order by有一种情况可以不满足索引的最左前缀的要求:前导列为常量。(即如果age,name为索引列,那么select * from user where age = 30 order by name,使用where将age指定为常量,这时也是可以使用索引排序的)
索引这么多优点,为什么不对表中的每一个列创建一个索引呢?使用索引一定提高查询性能吗?
答:
如果出现过多的重复索引和未使用索引,会影响插入、删除、更新的性能。
例如,如果创建了一个主键id,再去向id上添加索引,那么就添加了重复的索引,因为MySQL的主键限制也是通过索引实现的。
冗余索引是:如果创建了索引(A, B),再创建索引(A)就是冗余索引,因为(A)是(A, B)的前缀索引。
还有一种情况是,(A, ID)其中ID是主键,也是冗余索引,因为在 InnoDB 中,二级索引的叶子节点中已经包含主键值了。
使用索引一定提高查询性能吗?
不一定
- 在数据量比较小的表中,使用全表扫描比使用索引扫描速度更快,并且可以直接获取到全量数据
- 索引虽然提高了查询性能,但是在插入、删除、更新的过程中也是需要进行维护的
最左前缀匹配原则?
答:
最左前缀原则:规定了联合索引在何种查询中才能生效。
规则如下:
- 如果想使用联合索引,联合索引的最左边的列必须作为过滤条件,否则联合索引不生效
如下图:
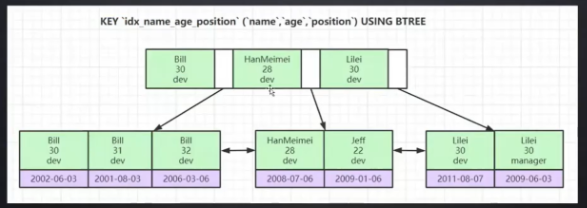
假如索引为:(name, age, position)
select * from employee where name = 'Bill' and age = 31;
select * from employee where age = 30 and position = 'dev';
select * from employee where position = 'manager';
对于上边三条 sql 语句,只有第一条 sql 语句走了联合索引。
为什么联合索引需要遵循最左前缀原则呢?
因为索引的排序是根据第一个索引、第二个索引依次排序的,假如我们单独使用第二个索引 age 而不使用第一个索引 name 的话,我们去查询age为30的数据,会发现age为30的数据散落在链表中,并不是有序的,所以使用联合索引需要遵循最左前缀原则。
索引下推?
答:
在索引遍历过程中,对索引中包含的所有字段先做判断,过滤掉不符合条件的记录之后再回表,可以有效减少回表次数
比如:
索引:(name, age, positioni)
SELECT * FROM employees WHERE name like 'LiLei%' AND age = 22 AND position ='manager';
对上面这条 sql 语句就是用了索引下推,经过索引下推优化后,在联合索引(name,age,position)中,匹配到名字是 LiLei 开头的索引之后,同时还会在索引中过滤 age、position 两个字段的值是否符合,最后会拿着过滤完剩下的索引对应的主键进行回表,查询完整数据
(MySQL5.6 之前没有索引下推,因此匹配到 name 为 LiLei 开头的索引之后,会直接拿到主键,进行回表查询)
优点:
- 索引下推可以有效减少回表次数
- 对于 InnoDB 引擎的表,索引下推只能用于二级索引,因为 InnoDB 的主键索引的叶子节点存储的是全行数据,如果在主键索引上使用索引下推并不会减少回表次数
MySQL 的锁
答:
MySQL 的锁
从数据操作的粒度分的话,分为表锁和行锁
从数据操作的类型分的话,分为读锁和写锁
表锁
每次操作锁住整张表,锁粒度大,性能低
- 手动增加表锁(可以给表加读锁或写锁,如果加读锁,其他会话可以读,但是无法写;如果加写锁。其他会话的读写都会被阻塞)
lock table 表名 read(write)
- 查看表上加过的锁
show open tables;
- 删除表锁
unlock tables;
行锁
每次操作锁住一行数据,锁力度小,性能高
InnoDB与MYISAM的最大不同有两点:
- InnoDB支持事务
- InnoDB支持行级锁
总结
-
MyISAM 在执行查询语句 select 前,会自动给涉及的所有表加读锁,在执行 update、insert、delete 操作会自动给涉及的表加写锁。
-
InnoDB 在执行查询语句 select 时(非串行隔离级别),不会加锁。但是 update、insert、delete 操作会加行锁。
-
简而言之,就是读锁会阻塞写,但是不会阻塞读。而写锁则会把读和写都阻塞。
-
锁主要是加在索引上,如果对非索引字段更新,行锁可能会变表锁:
假如 account 表有 3 个字段(id, name, balance),我们在 name、balance 字段上并没有设置索引
session1 执行:mysql> begin;Query OK, 0 rows affected (0.00 sec)mysql> select * from account;+----+------+---------+| id | name | balance |+----+------+---------+| 1 | zs | 777 || 2 | ls | 800 || 3 | ww | 777 || 4 | abc | 999 || 10 | zzz | 2000 || 20 | mc | 1500 |+----+------+---------+6 rows in set (0.01 sec)mysql> update account set balance = 666 where name='zs';Query OK, 1 row affected (0.00 sec)Rows matched: 1 Changed: 1 Warnings: 0此时 session2 执行(发现执行阻塞,经过一段时间后,返回结果锁等待超时,证明 session1 在没有索引的字段上加锁,导致行锁升级为表锁,因此 session2 无法对表中其他数据做修改):
mysql> begin;Query OK, 0 rows affected (0.00 sec)mysql> update account set balance = 111 where name='abc';RROR 1205 (HY000): Lock wait timeout exceeded; try restarting transactionInnoDB 的行锁是针对索引加的锁,不是针对记录加的锁。并且该索引不能失效,否则会从行锁升级为表锁
select for update 了解吗?
答:
select for update 即排他锁,根据 where 条件的不同,对数据加的锁又分为行锁和表锁:
- 如果 where 字段使用到了索引,则会添加行锁
- 如果 where 字段没有使用索引,则会添加表锁
并发事务带来的问题
答:
- 脏写:多个事务更新同一行,每个事务不知道其他事务的存在,最后的更新覆盖了其他事务所做的更新
- 脏读:事务 A 读取到了事务 B 已经修改但是没有提交的数据,此时如果事务 B 回滚,事务 A 读取的则为脏数据
- 不可重复读:事务 A 内部相同的查询语句在不同时刻读出的结果不一致,在事务 A 的两次相同的查询期间,有其他事务修改了数据并且提交了
- 幻读:当事务 A 读取到了事务 B 提交的新增数据
不可重复读和幻读很类似,都是事务 A 读取到了事务 B 新提交的数据,区别为:
- 不可重复读是读取了其他事务更改的数据,针对 update 操作
- 幻读是读取了其他事务新增的数据,针对 insert 和 delete 操作
MySQL 的事务隔离级别了解吗?
答:
MySQL 的事务隔离级别分为:
- 读未提交:事务 A 会读取到事务 B 更新但没有提交的数据。如果事务 B 回滚,事务 A 产生了脏读
- 读已提交:事务 A 会读取到事务 B 更新且提交的数据。事务 A 在事务 B 提交前后两次查询结果不同,产生不可重复读
- 可重复读:保证事务 A 中多次查询数据一致。可重复读是 MySQL 的默认事务隔离级别。可重复读可能会造成幻读 ,事务A进行了多次查询,但是事务B在事务A查询过程中新增了数据,事务A虽然查询不到事务B中的数据,但是可以对事务B中的数据进行更新
演示可重复读:-
先创建一个事务 A,查询表
mysql> start transaction;Query OK, 0 rows affected (0.00 sec)mysql> select * from account;+----+------+---------+| id | name | balance |+----+------+---------+| 1 | zs | 150 || 2 | ls | 200 |+----+------+---------+2 rows in set (0.00 sec) -
此时再去创建事务 B,修改数据让第一条数据的 balance 减去 50,并且提交事务
mysql> start transaction;Query OK, 0 rows affected (0.00 sec)mysql> update account set balance = balance - 50 where id = 1;Query OK, 1 row affected (0.00 sec)Rows matched: 1 Changed: 1 Warnings: 0mysql> select * from account;+----+------+---------+| id | name | balance |+----+------+---------+| 1 | zs | 100 || 2 | ls | 200 |+----+------+---------+2 rows in set (0.00 sec)mysql> commit;Query OK, 0 rows affected (0.00 sec) -
在事务 B 提交之后,在事务 A 中查询数据,发现与上次查询数据一致(可重复读)
mysql> select * from account;+----+------+---------+| id | name | balance |+----+------+---------+| 1 | zs | 150 || 2 | ls | 200 |+----+------+---------+2 rows in set (0.00 sec)``` -
在事务 A 中让第一条数据的 balance 减去 50,由于在事务 B 中已经减去 1 次 50 了,所以在事务 A 中的 update account set balance = balance - 50 where id = 1 语句中的 balance 值使用的是上边步骤 2 中的 100,所以事务 A 中更新之后的 balance 值为 50。可重复读的隔离级别下使用了 MVCC 机制,select 操作不会更新版本号,是快照读(历史版本);insert、update 和 delete 会更新版本号,是当前读(当前版本)
mysql> select * from account;+----+------+---------+| id | name | balance |+----+------+---------+| 1 | zs | 150 || 2 | ls | 200 |+----+------+---------+2 rows in set (0.01 sec)mysql> update account set balance = balance - 50 where id = 1;Query OK, 1 row affected (0.00 sec)Rows matched: 1 Changed: 1 Warnings: 0mysql> select * from account;+----+------+---------+| id | name | balance |+----+------+---------+| 1 | zs | 50 || 2 | ls | 200 |+----+------+---------+2 rows in set (0.00 sec) -
验证出现幻读,重新打开事务 B,插入一条数据
mysql> start transaction;Query OK, 0 rows affected (0.00 sec)mysql> select * from account;+----+------+---------+| id | name | balance |+----+------+---------+| 1 | zs | 50 || 2 | ls | 200 |+----+------+---------+2 rows in set (0.00 sec)mysql> insert into account values(4, 'abc', 300);Query OK, 1 row affected (0.00 sec)mysql> select * from account;+----+------+---------+| id | name | balance |+----+------+---------+| 1 | zs | 50 || 2 | ls | 200 || 4 | abc | 300 |+----+------+---------+3 rows in set (0.00 sec)mysql> commit;Query OK, 0 rows affected (0.01 sec) -
在事务 A 中查询,发现没有看到事务 B 新插入的数据,但是事务 A 可以直接更新事务 B 中插入的数据(说明事务 A 是可以感知到事务 B 插入的数据,因此发生了幻读),更新之后,事务 A 再次查询就查询到了事务 B 的数据。
mysql> select * from account;+----+------+---------+| id | name | balance |+----+------+---------+| 1 | zs | 50 || 2 | ls | 200 |+----+------+---------+2 rows in set (0.00 sec)mysql> update account set balance = 888 where id = 4;Query OK, 1 row affected (0.00 sec)Rows matched: 1 Changed: 1 Warnings: 0mysql> select * from account;+----+------+---------+| id | name | balance |+----+------+---------+| 1 | zs | 50 || 2 | ls | 200 || 4 | abc | 888 |+----+------+---------+3 rows in set (0.00 sec)
-
- 可串行化:并发性能低,不常使用

 -- 实体类的配置注解(@ApiModel与@ApiModelProperty 的 认识与使用))








)
)







