audioset_tagging
github上开源的音频识别模型,可以识别音频文件的类型并打分给出标签占比,如图
@echo off
set CHECKPOINT_PATH="module/Cnn14_mAP=0.431.pth"
set MODEL_TYPE="Cnn14"
set CUDA_VISIBLE_DEVICES=0
python pytorch\inference.py audio_tagging --model_type=%MODEL_TYPE% --checkpoint_path=%CHECKPOINT_PATH% --audio_path="resources/hansheng.mp3" --cuda
pause
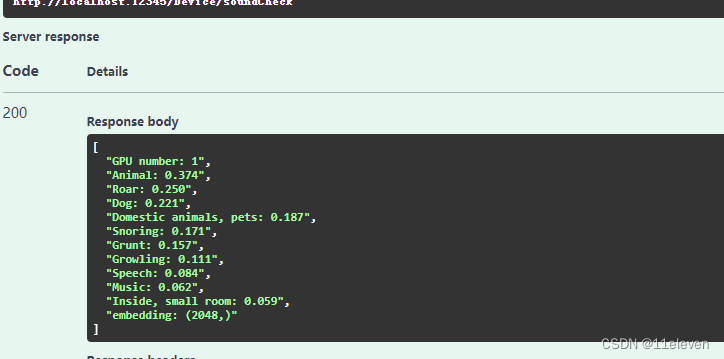
["GPU number: 1","Animal: 0.374","Roar: 0.250","Dog: 0.221","Domestic animals, pets: 0.187","Snoring: 0.171","Grunt: 0.157","Growling: 0.111","Speech: 0.084","Music: 0.062","Inside, small room: 0.059","embedding: (2048,)"
]这里我封装成API了,指定文件路径进行识别,会调用GPU或者CPU进行运算,得出结果,
例如动物得分0.3等等,有兴趣的可以去GITHUB上去获取试试。
public static List<string> Do(AudioCheckCondition condition) {
List<string> res = new List<string>();
// 创建一个进程启动信息
ProcessStartInfo start = new ProcessStartInfo();
start.FileName = AppsettingsConfig.PythonSet.ExePath; // Python可执行文件的路径
start.Arguments = AppsettingsConfig.PythonSet.ScriptContent.Replace("[[audio]]", condition.FilePath); // 你的Python脚本文件路径
start.UseShellExecute = false;
start.RedirectStandardOutput = true;
start.RedirectStandardError = true;
start.CreateNoWindow = true;
// 设置工作目录
start.WorkingDirectory = AppsettingsConfig.PythonSet.WorkingDirectory;
// 启动Python进程
using (Process process = new Process())
{
process.StartInfo = start;
process.OutputDataReceived += (sender, e) => {
if (!string.IsNullOrEmpty(e.Data))
{
res.Add(e.Data);
Console.WriteLine("Output: " + e.Data);
}
};
process.ErrorDataReceived += (sender, e) => {
if (!string.IsNullOrEmpty(e.Data))
{
Console.WriteLine("Python Error: " + e.Data);
}
};
process.Start();
process.BeginOutputReadLine();
process.BeginErrorReadLine();
process.WaitForExit();
// 获取Python程序的返回代码
int exitCode = process.ExitCode;
Console.WriteLine("Python Process Exit Code: " + exitCode);
}
return res;
}

)

















