- 题目:HBM Connect: High-Performance HLS Interconnect for FPGA HBM
- 时间:2021
- 会议:FPGA
- 研究机构:UCLA Jason Cong
- 题目:Demystifying the Memory System of Modern Datacenter FPGAs for Software Programmers through Microbenchmarking
- 时间:2021
- 会议:FPGA
- 研究机构:加拿大西蒙菲莎大学
FPGA中的HBM主要是为了解决带宽受限的问题,这里的两篇论文都是针对存储和互连的优化,希望能最大化HBM的带宽。需要解决两个事情:
- memory port的数量、位宽、burst_len等一些列参数的确定,避免小马拉大车
- 如何充分的利用多个独立的HBM通道,需要互连的优化
所以第一篇论文的主要贡献点在于:
- 通过设计的switching和crossbar结构提高throughput
- A BRAM-efficient HLS buffering scheme that increases the AXI burst length and the effective bandwidth when PEs access several HBM pseudo channel
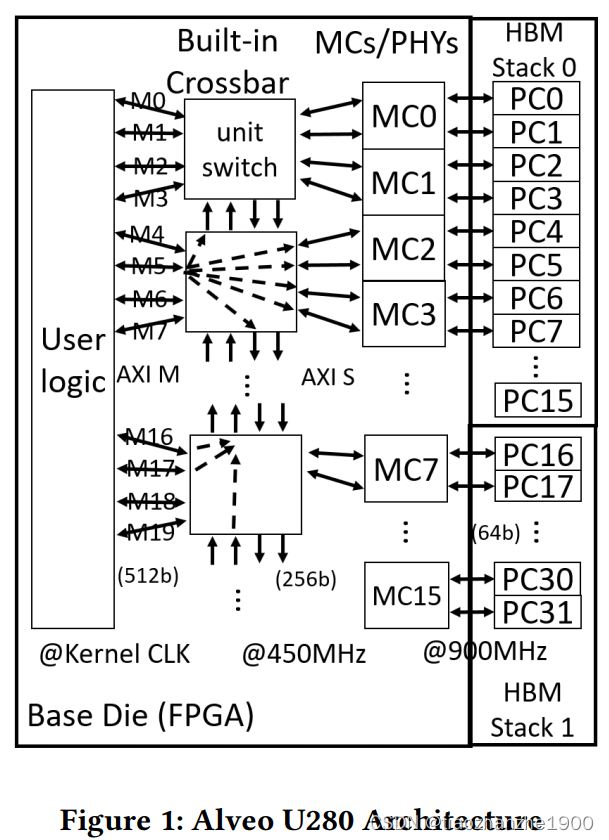
相比于第一篇论文,第二篇论文更简单些,主要是针对不同参数进行一系列对比实验,一些有意义的结论包括:
- 总有效片外存储器带宽几乎与所有并发存储器访问端口的合计端口宽度成线性比例关系。对于理论峰值带宽为19.2GB/s的单个DDR4存储体,其在512位变得平坦:有效峰值读写带宽约为18.01GB/s和16.56GB/s。对于理论峰值带宽为14.4GB/s的单个HBM2存储体,其在512位也变得平坦:多个存储器端口访问单个DRAM存储体的有效峰值读写带宽约为13.18GB/s和13.17 GB/s。
- 每个端口的最大突发访问大小(即每个端口的数据宽度和最大突发访问长度的乘积)应设置为16Kb(即2KB)。 然而,单端口接入没有这个要求。对于HBM,通常每个存储器访问端口连接到一个单独的HBM bank
- 有效片外存储器带宽随着连续数据访问大小的增加而增加,当该大小在128KB左右时变得平坦。
- 对于加速器到加速器的流端口,总(片内)通信带宽与每个端口的数据宽度(每个端口最高1024位)和端口数量(16个端口时持平)成线性比例关系。
- 在设计中,应通过联合考虑计算-内存平衡和资源利用来选择最佳配置,而不是综合选择峰值带宽配置。



(一)相机内参标定)









)

![NSS [SWPUCTF 2021 新生赛]sql](http://pic.xiahunao.cn/NSS [SWPUCTF 2021 新生赛]sql)


)

