主要区别
从无序 —> 有序
从K-Means —> KNN
- KNN:监督学习,类别是已知的,对已知分类的数据进行训练和学习,找到不同类的特征,再对未分类的数据进行分类。
- K-Means:无监督学习,事先不知道数据有几类,通过聚类分析将数据聚合成几个群体。聚类不需要对数据进行训练和学习。
KNN
原理
将预测点与所有点的距离进行计算,然后保存并排序,选出前面K个值看看哪些类别比较多,则预测的点就属于哪一类。
KNN也可以用于回归预测
算法步骤
对未知类别属性的数据集中每个点依次执行以下操作:
- 计算已知类别数据集中的点与当前点之间的距离;
通常使用的是欧氏距离 - 按照距离递增次序排序;
- 选取与当前点距离最小的k个点;
如何确定k?
通过交叉验证,从选取一个较小的k值开始,不断增加k的值,然后计算验证集合的方差,最终找到一个比较合适的k值。 - 确定前k个点所在类别的出现频率;
- 返回前k个点出现频率最高的类别作为当前点的预测分类。
K-Means
原理
随机选取质心——计算各样本点和质心的距离后分类——再次选择新的质心
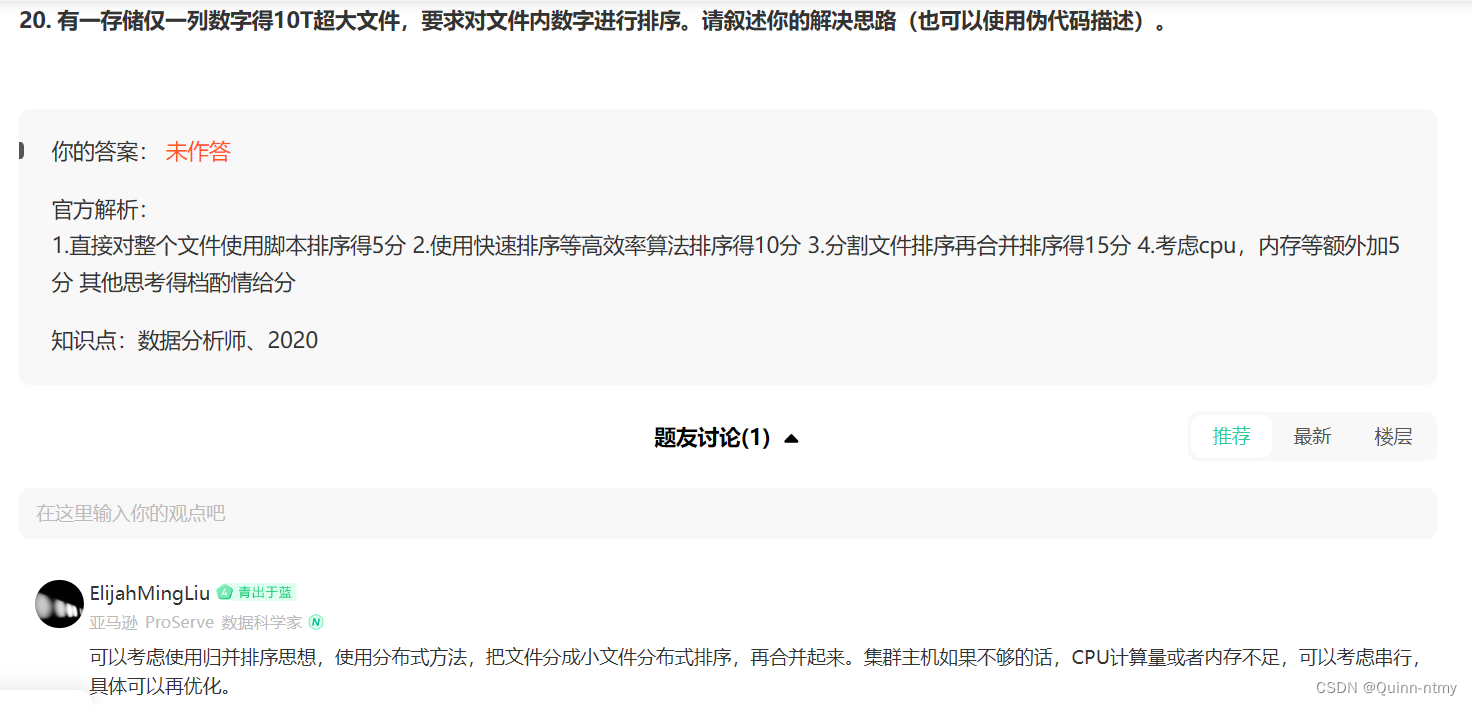
【扩展】
邻近度函数(即距离计算):
(1)曼哈顿距离:质心——中位数,目标函数——最小化对象到簇质心的距离和;
(2)平方欧几里得距离:质心——均值,目标函数——最小化对象到簇质心的距离的平方和;
(3)余弦距离:质心——均值,目标函数——最大化对象与其质心的余弦相似度和;
(4)Bregman散度:质心——均值,目标函数——最小化对象到簇质心的Bregman散度和。
算法步骤
- 随机选取k个质心(k值取决于想聚成几类);
- 计算样本到质心的距离,距离质心近的归为一类,分为k类;
- 求出分类后的每类的新质心;
- 再次计算样本到新质心的距离,距离质心距离近的归为一类;
- 判断新旧聚类是否相同,如果相同就代表已经聚类成功,如果没有则循环2-4。

(一)相机内参标定)









)

![NSS [SWPUCTF 2021 新生赛]sql](http://pic.xiahunao.cn/NSS [SWPUCTF 2021 新生赛]sql)


)



