下面的内容需要了解系统调用,可看下面的链接:
系统调用来龙去脉-CSDN博客
1.底层文件IO和标准IO
这里指的是操作系统提供的IO服务,不同于ANSI建立的标准IO。
底层IO和标准IO各自所使用的函数:
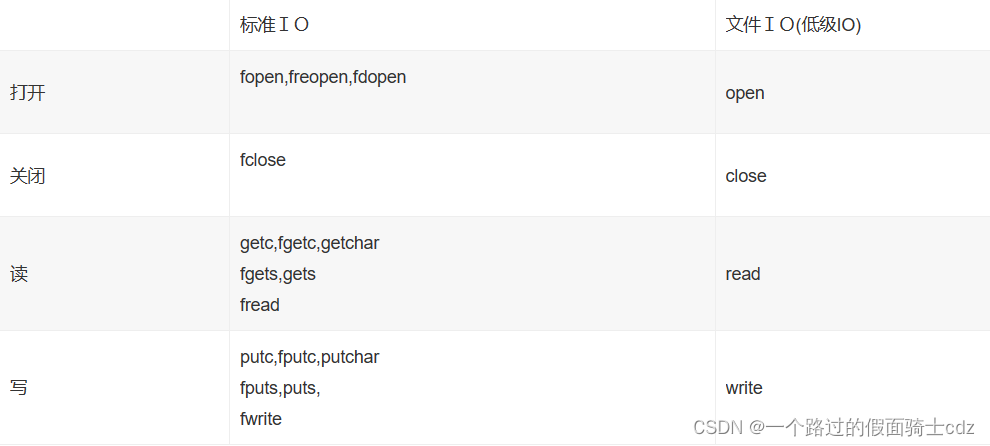
区别:
1.底层文件IO不带用户级缓存,称为unbuffered I/O,每次操作都会执行相关系统调用,这一过程系统消耗资源大,而且时间也比较长。
而标准IO则带有三种缓冲机制,可以对缓冲区进行访问,必要时再访问实际文件,也就是说这时才会执行系统调用,减少了开销。
(1)全缓存
当填满I/O缓存后才进行实际I/O操作
(2)行缓存
当在输入和输出中遇到新行符(‘\n’)时,进行I/O操作。
当流遇到一个终端时,典型的行缓存。
(3)不带缓存
标准I/O库不对字符进行缓冲,例如stderr。
2.底层I/O特定于操作系统,只能在某些操作系统才能使用,而标准IO具有一定的移植性,只要有标准IO库就能使用。
但也不是说标准I/O一定比底层I/O好,因为缓冲的机制,我们必须时刻注意内容是否已经被冲刷过去,也就是说内容可能还在缓冲里存着,必须掌握这一缓冲机制,程序才能向我们想象的目标去完成。
2.文件描述符的介绍
Linux系统一切皆文件,Linux操作系统不区分套接字和文件。
Linux操作系统给文件或套接字分配整数,用来标识文件或者套接字,称为文件描述符(File descriptor)。因此,程序中套接字可以像文件一样来进行输入输出。
实际上,标准输入输出及标准错误在Linux中也配分配文件描述符。
文件和套接字一般经过创建过程才会被分配文件描述符。而标准输入输出及标准错误即使未经过特殊的创建过程,程序开始运行后也会被自动分配文件描述符。如下:

3.底层文件I/O函数
为了方便我们查看下面的函数调用具体发生那些错误,可看下面的链接:
errno变量和显示错误信息-CSDN博客
(1)打开文件
int open(const char *pathname,int flags);
int open(const char *pathname,int flags,mode_t mode);
//path 文件名的字符串地址,保存的是目标文件及路径信息
//flags 文件打开模式信息
//mode 文件的权限
//成功返回文件描述符,失败时返回-1,同时errno变量被设置。flags 有以下的几个值:
| O_RDONLY | 只读打开 |
| O_WRONLY | 只写打开 |
| O_RDWR | 读写打开 |
| O_CREAT | 必要时创建文件 |
| O_TRUNC | 删除文件全部现有内容,从头开始写入 |
| O_APPEND | 维持文件现有内容,在内容末尾追加 |
| O_EXCL | 如果文件存在则出错,和O_CREAT搭配使用 |
| O_NONBLOCK | 设置为非阻塞模式 |
打开模式参数可以通过位或运算符 ” | " 组合传递。
另外创建文件时,可能需要指定文件权限。
mode为四位八进制的数,例如mode=0644,第一个0表示八进制,文件权限根据后三位为你想要设置该文件的权限,它会与umask取反后的数相与,得到的最终结果为文件的权限。
文件权限=mode&~umask
umask通过命令umask可以查看:

(2)关闭文件
int close(int fd);
//fd 需要关闭的文件描述符,
//fd含义即上面说的file descriptor文件描述符
//成功时返回0,失败时返回-1,同时errno变量被设置。(3)传输数据
ssize_t write(int fd,const void *buf,size_t count);
//fd 要写入对象的文件描述符
//buf 要写入数据的缓存地址值
//count 要写的字节数
//成功时返回写入的字节数,失败返回-1,同时errno变量被设置。
//通过此函数向fd指定的文件或者套接字写入buf里nbytes个字节的数据后缀_t意味着type/typedef(类型),是一种命名规范。
size_t是通过typedef声明的unsigned int类型,表示字节数不能为负,
size中文意思尺寸大小,不能为负
ssize_t在size_t的前面加了s,表示ssize_t是通过typedef声明的signed int类型
(4)读取数据(read函数)
ssize_t read(int fd,void *buf,size_t nbytes);
//fd 需要读取数据对象的文件描述符
//buf 接收数据的缓冲地址值
//nbytes 要接受数据的最大字节数
//实际读取的字节数可能小于nbytes要求的字节数
//成功时返回接收的字节数,失败时返回-1,同时errno变量被设置。
//通过此函数将fd指定的文件或套接字读取nbytes个字节到buf里面(5)移动读写指针
off_t lseek(int fd, off_t offset, int whence);
//fd 文件描述符
//offset 距离whence的偏移量//whence 有三个参数选择:
//SEEK_SET:文件的头部
//SEEK_CUR:当前文件流指针的位置
//SEEK_END:文件的尾部//通过此函数将读写指针移动到相应的位置,注意上面的write和read函数都是从指针处开始执行的
//例如下面的代码如果将lseek函数注释掉,则buf2里面没有读取到fd里面的数据。
//因为我们写完指针在fd文件里面的末尾,而末尾后面根本没有字节可以读取//当lseek执行成功时,它会返回最终以文件起始位置为起点的偏移位置。如果出错,则返回-1,同时errno被
//设置为对应的错误值。简单的示例代码:
//low_io.c
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<fcntl.h>void error_handling(const char *message)
{fputs(message,stderr);fputc('\n',stderr);exit(1);
}int main(int argc,char *argv[])
{char buf1[]="hello,world";char buf2[20];int fd=open("data666.txt",O_RDWR|O_TRUNC);if(fd==-1)error_handling("open error!\n");printf("file descriptor is %d\n",fd);int len1=0;int len2=0;if((len1=write(fd,buf1,sizeof(buf1)))==-1)error_handling("write error!");printf("write len is %d\n",len1);lseek(fd,0,SEEK_SET);if((len2=read(fd,buf2,sizeof(buf2)))==-1)error_handling("read error!");printf("read len is %d\n",len2);fputs(buf2,stdout);fputc('\n',stdout);close(fd);return 0;
}结果:

4.验证深入文件I/O和标准I/O
先分别用标准I/O和文件I/O分别写一个程序,该程序复制一个文件。
标准I/O:
//stdcopy.c
#include<error.h>
#include<stdlib.h>
#include<stdio.h>int main(int argc,char *argv[])
{if(argc!=3){ printf("<file1 file2>\n");exit(1);} FILE* fp1=fopen(argv[1],"r");if(!fp1){ perror("cp1.txt open failed");exit(1);} FILE* fp2=fopen(argv[2],"w");if(!fp2){ perror("cp2.txt open failed");exit(1);}while(1){int ch=fgetc(fp1);if(ch==-1){printf("end of file\n");break;}fputc(ch,fp2);}return 0;
}文件I/O:
//filecopy.c
#include<stdio.h>
#include<stdlib.h>
#include<fcntl.h>#define N 1char buf[N];int main(int argc,char *argv[])
{if(argc!=3){printf("<file1 file2>\n");exit(1);}int fd1=open(argv[1],O_RDONLY);if(fd1==-1){perror("fd1 open failed");exit(1);} int fd2=open(argv[2],O_WRONLY|O_CREAT|O_TRUNC);if(fd1==-1){perror("fd2 open failed");exit(1);}int readLen=0;while(readLen=(read(fd1,buf,N))){if(readLen==-1){perror("read error");exit(1);}write(fd2,buf,N);}return 0;
}
使用这两个文件拷贝一个超大的文件,可以发现文件I/O将会比标准I/O慢。
下面深入理解这俩的差别。
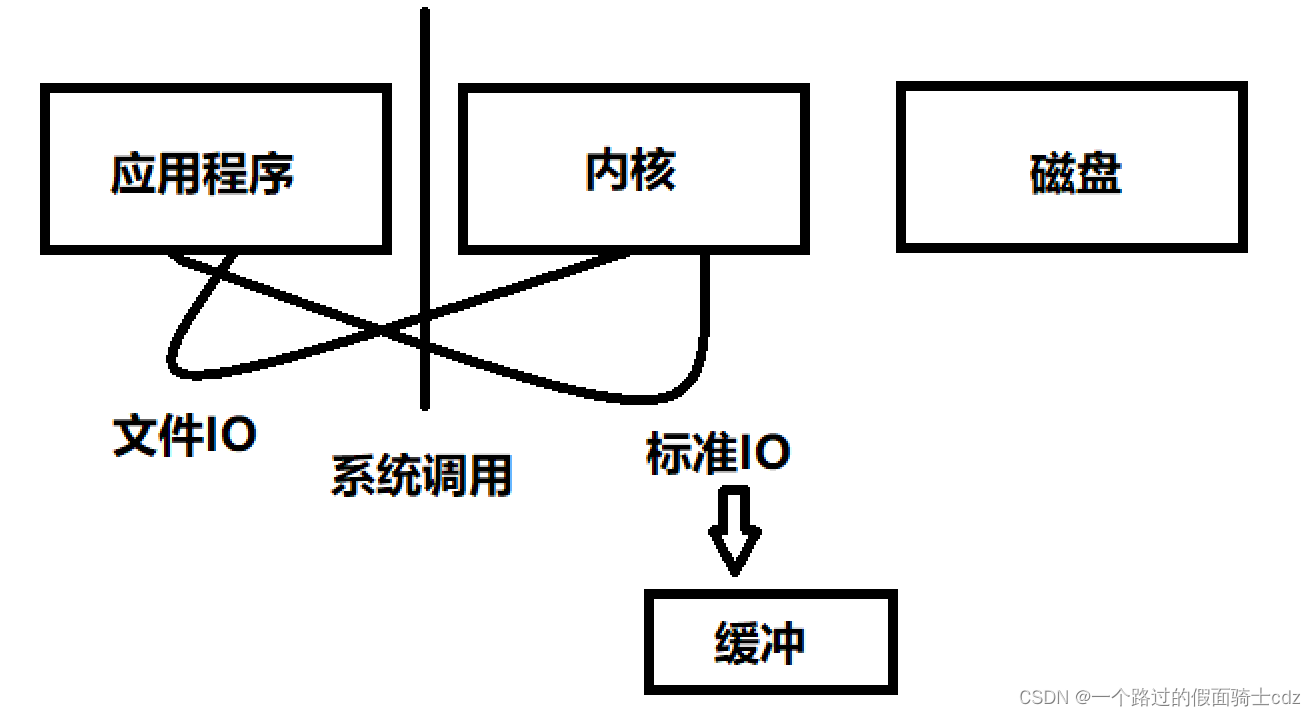
内核到磁盘的相互读写有内核自己的一个算法,我们只要把文件内容写到内容或者从内核读取内容,就相当于和磁盘做了数据交换。
而应用程序到内核,需要系统调用。系统调用,用户态到核心态,核心态到用户态这个过程消耗资源会非常大,时间消耗也会非常长。
文件I/O每一次操作都需要这样的一个过程,我们输入命令:
sudo yum -y install strace然后输入命令,运行filecopy.c文件编译完成的可执行程序filecopy:
strace ./filecopy 文件1 文件2发现:

而标准I/O它自带一个缓冲,它先把要写的内容先写到自己的内存,直到写满了它才使用系统调用把内容写到内核中去。
输入命令,运行stdcopy.c编译完成的可执行程序stdcopy:

结果是发现它只执行了一次系统调用。



















