前沿重器
栏目主要给大家分享各种大厂、顶会的论文和分享,从中抽取关键精华的部分和大家分享,和大家一起把握前沿技术。具体介绍:仓颉专项:飞机大炮我都会,利器心法我还有。(算起来,专项启动已经是20年的事了!)
2022年的文章合集,累积起来有60w字,在这:CS的陋室60w字原创算法经验分享-2022版。
往期回顾
前沿重器[31] | 理性聊聊ChatGPT
前沿重器[32] | 域外意图检测——解决“没见过”的问题
前沿重器[33] | 试了试简单的prompt
前沿重器[34] | Prompt设计——LLMs落地的版本答案
前沿重器[35] | 提示工程和提示构造技巧
在顶会ACL2023上,陈丹琦老师团队带来了一份长达近4小时的tutorial:Retrieval-based Language Models and Applications,内容非常丰富而且具有很强的使用价值,本文主要总结一下这篇文章的内容,并附带一些自己的理解和思考。
开始之前,先把关键的参考资料给出:
官方材料:https://acl2023-retrieval-lm.github.io/,PPT和阅读材料都给到。
还不错的解读文章:https://blog.csdn.net/qq_27590277/article/details/132399887
简介
简介章节讲的是比较基础的,主要介绍了本次要介绍的概念,即检索(Retrieval)和大语言模型(LLM):
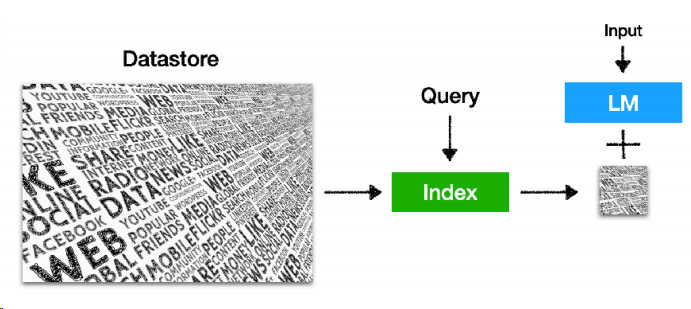
简单的说,其实就是通过检索的模式,为大语言模型的生成提供帮助,从而使之生成更符合要求的结果,听起来,其实就和最近比较火的另一个概念——检索增强生成(RAG,retrieval augment generation),在我的理解下,就是一件事。
众所周知,LLM其实已经在很多领域和问题下都取得了很好的效果,那为何还需要依赖检索做进一步优化,在本文看来,主要有5个原因:
LLM无法记住所有知识,尤其是长尾的。受限于训练数据、现有的学习方式,对长尾知识的接受能力并不是很高。
LLM的知识容易过时,而且不好更新。只是通过微调,模型的接受能力其实并不高而且很慢,甚至有丢失原有知识的风险。
LLM的输出难以解释和验证。一方面最终的输出的内容黑盒且不可控,另一方面最终的结果输出可能会受到幻觉之类的问题的干扰。
LLM容易泄露隐私训练数据。用用户个人信息训练模型,会让模型可以通过诱导泄露用户的隐私。
LLM的规模大,训练和运行的成本都很大。
而上面的问题,都可以通过数据库检索快速解决:
数据库对数据的存储和更新是稳定的,不像模型会存在学不会的风险。
数据库的数据更新可以做得很敏捷,增删改查可解释,而且对原有的知识不会有影响。
数据库的内容是明确、结构化的,加上模型本身的理解能力,一般而言数据库中的内容以及检索算法不出错,大模型的输出出错的可能就大大降低。
知识库中存储用户数据,为用户隐私数据的管控带来很大的便利,而且可控、稳定、准确。
数据库维护起来,可以降低大模型的训练成本,毕竟新知识存储在数据库即可,不用频繁更新模型,尤其是不用因为知识的更新而训练模型。
问题定义
首先,按照文章的定义:
A language model (LM) that uses an external datastore at test time。
关键词两个:语言模型和数据库。
语言模型这块,我们其实都熟悉了,早些年以bert代表的模型,到现在被大量采用的大模型,其实结构都具有很大的相似性,而且已经相对成熟,模型结构这事就不赘述了。更为重要的是,prompt受到关注的这件事,在现在的视角看来是非常关键的发现,prompt能让大模型能完成更多任务,通过引导能让模型解决不同的问题,同时,效果还是不错,在现在的应用下,prompt精调已经成为了经济高效的调优手段了。

至于数据库,配合大模型,构造成如下的推理结构:
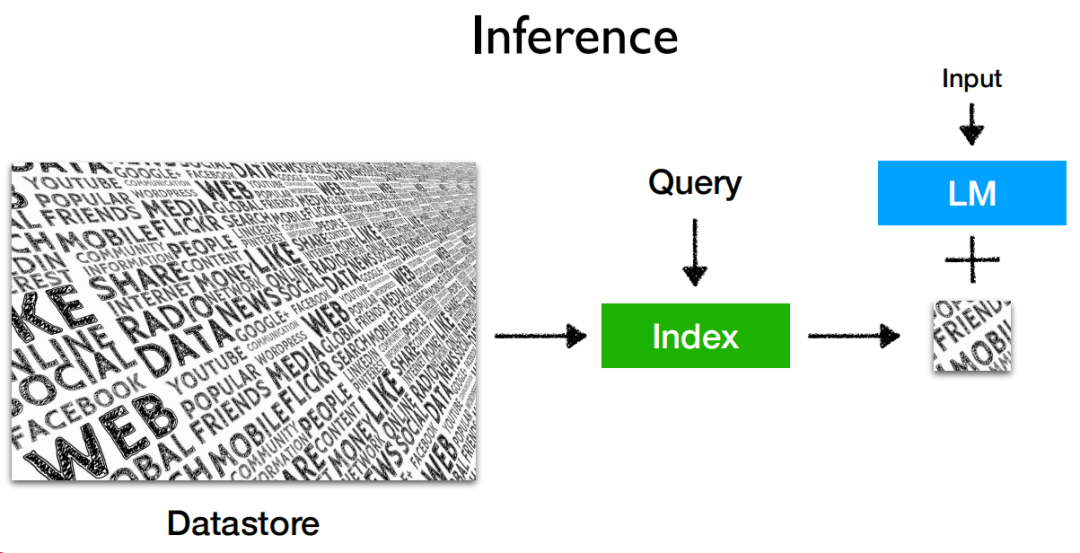
datastore是数据源,构造成索引后,可以接受query进行检索,检索结果和大模型配合,就能输出结果。
架构
此时,就出现一个问题,大模型和检索查询之间的关系是什么,拆解下来,就是这几个问题:
查什么:query如何构造以及检索的。
如何使用查询:查询结果出来后如何跟大模型协同。
何时查:什么时候触发查询,或者换个说法,如何构造查询query。
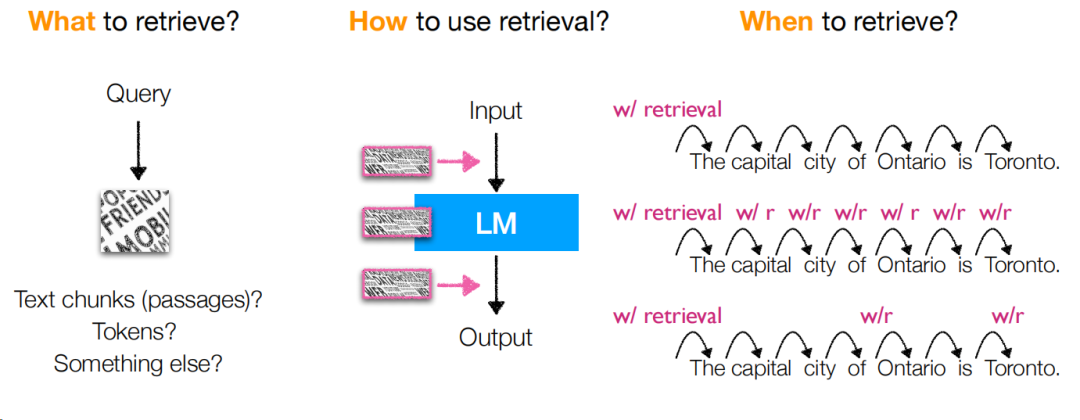
section3中,通过论文讲解的方式,讨论了多篇论文在解决上述3个问题下的解决方案,并且讨论了他们的优缺点。
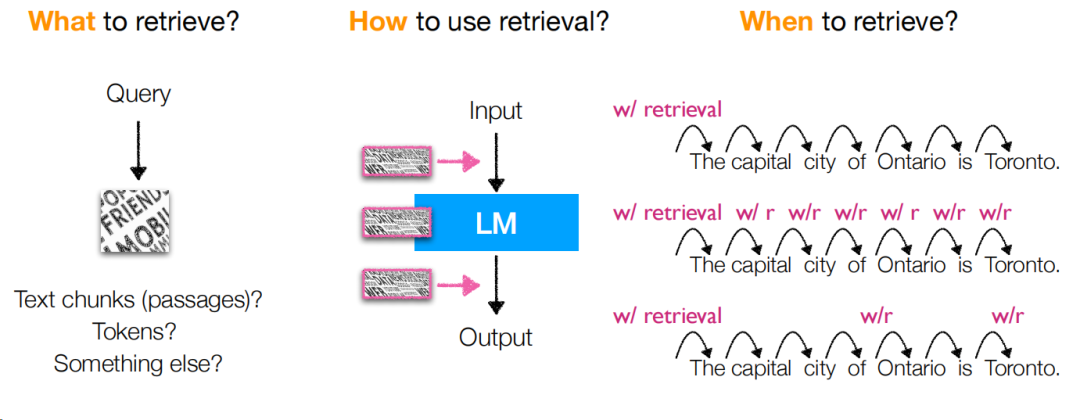
这里总结一些关键要点给大家,让大家理解这些检索策略的不一样会有什么优缺点:
检索不一定检索一次,可以切句,例如机械地n个token地切后查询,会比只查一次要强一些。
RETRO中构造了临时层对检索结果进行解析,提升检索结果的理解和使用能力,但这也意味着这些层需要进行训练后才可使用,训练成本是增加的。
KNN-LM在检索上,从词降级为token,能对低频或域外(out of domain)数据有很好的支持,但存储空间会变大很多,同时该方法缺少输入和检索结果的交互信息。
后续的FLARE和Adaptive-LM采用了自适应检索的方式,能提升检索的效率,但当然与之对应的检索策略并不一定是最优的(误差叠加)。
Entities as Experts直接检索实体,能提升效率,但这个位置是需要额外的实体识别的。
训练
在LLM-Retrieval的框架下,训练除了为了更好地让LLM做好推理预测,还需要尽可能让LLM和检索模块协同,而显然,同时训练LLM和检索模块的模型,无疑是成本巨大的,就这个背景,文章总结了4种LLM和检索模块的更新策略。(注意,此处我把training翻译为更新)
首先是独立更新(Independent training),即两者各自更新,互不影响。这个应该是目前我看到最常见的一种方式了。
优点:对频繁更新的索引,大模型不需要频繁更新,甚至不需要更新;每个模块可以独立优化。
缺点:大模型和检索模型两者之间并无协同。
然后是依次训练(Sequential training),即训练其中一个的时候,另一个固定,等此模块训练完训练完以后再训另一个。
优点:和独立更新有相似点,大模型不需要频繁更新,甚至不需要更新;不同的是,大模型可以进行适配检索模块的训练,反之亦然。
缺点:因为是依次训练,所以在训练其中一个时,另一个是固定的,不能做到比较彻底的协同,而且大模型更新的频率不见得跟得上索引库的更新,如果紧跟,成本会变高。
第三种是异步索引更新下的联合训练,即允许索引过时,定期更新即可。这种方式的难点是需要权衡,索引更新的频率是多少,太多了则训练成本昂贵,太少了则索引过时,导致有些问题会出错。
第四种也是联合训练,但考虑到更新索引的频次问题,所以索引通过批次的方式来更新,当然了,这种方式的同样会带来成本的问题,无论是训练阶段,还是索引更新阶段。
总结一下,有关训练阶段,两者协同,有如下优缺点。

应用
应用这块,通过这几个月我们的深入使用,大模型给了我们很多的使用空间,到了LLM+检索的场景,我们需要知道的是有哪些优势场景,在本文中,作者总结了如下使用场景:
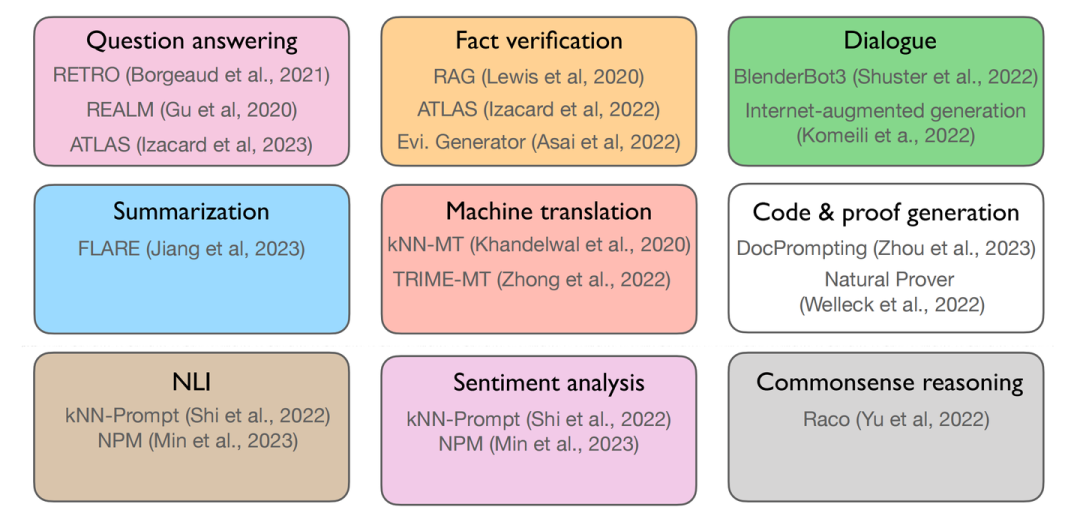
第一行3个任务主要优势表现在知识密集型的任务中,中间和下面的6个则是比较经典的NLP任务了,中间3个偏向生成,后面3个倾向于分类,此时,我们需要回答两个问题:
如何把LLM+检索这个模式应用在这些任务中?
使用LLM+检索这个模式的时机是什么?
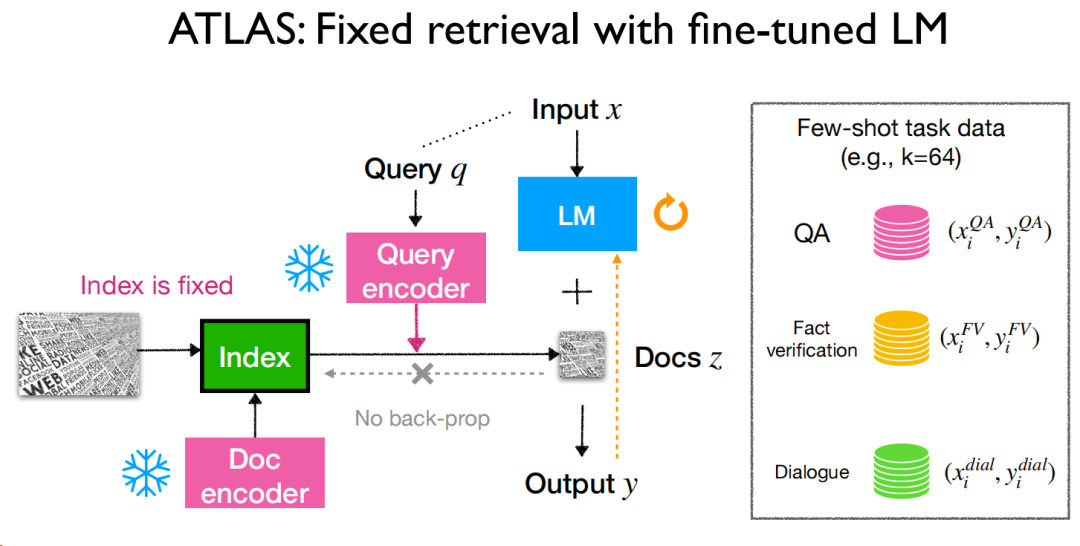
首先是第一个问题,如何应用,这里给出了3种使用方法,分别是微调、强化学习和prompt。我们日常使用的更多的可能是prompt,但是从一些实战经验上,可能还有别的模式可能能让模型更好地利用。
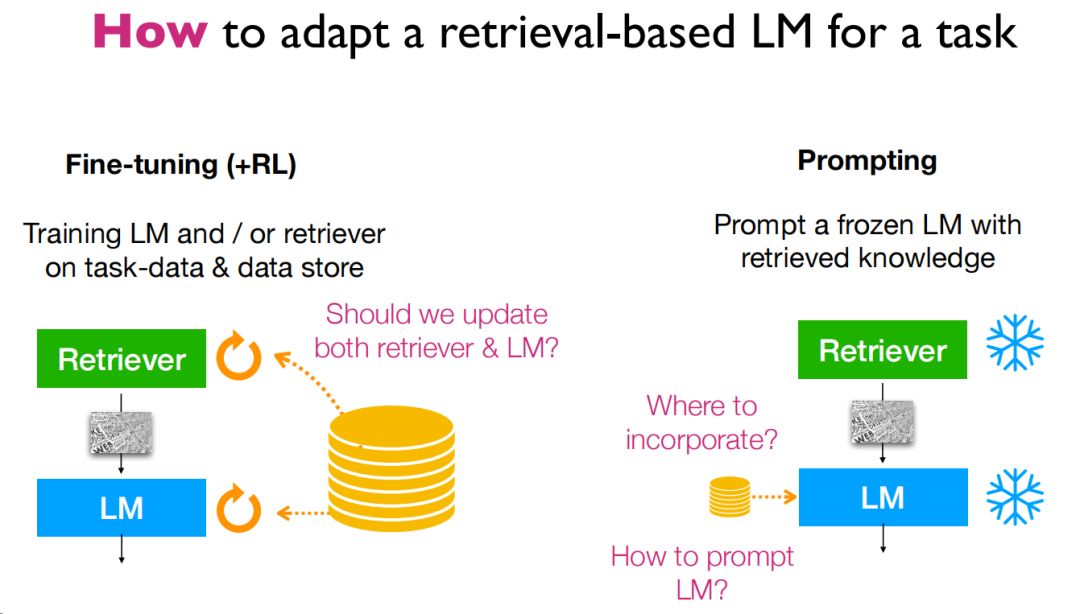
微调方面,只要把整个流程串起来其实就能发现,是完全可行的,ATLAS这篇论文比较典型,再处理知识库的更新上选择了相对独立的策略,从实验来看,效果还是不错的,作者的评价是这样的:
微调能为知识密集型任务提供很大的提升。
对检索库本身的微调也十分重要。
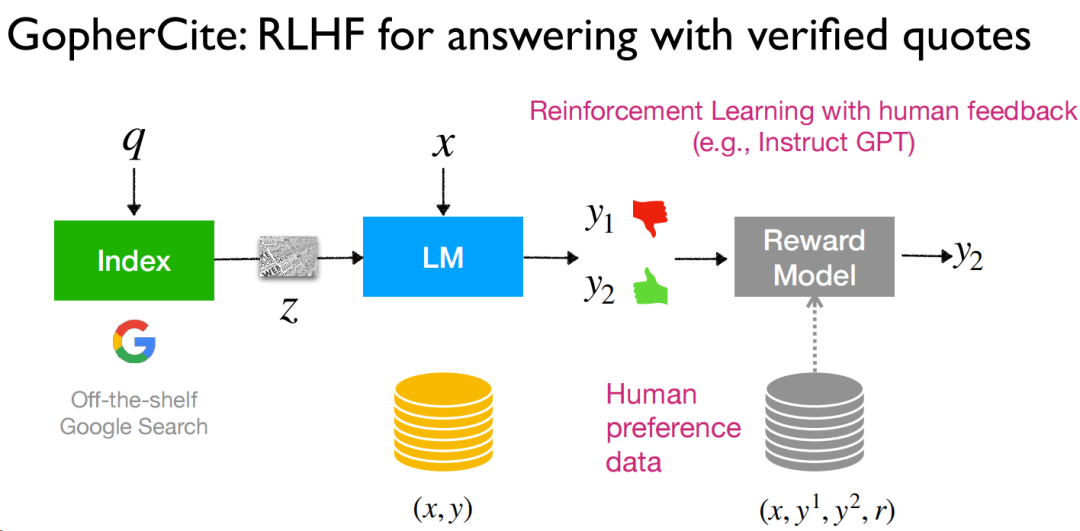
而强化学习,也算是最近比较热门的研究方向了,RLHF能把全流程串起来,有人工的评价能为结果带来更多的提升,作者用的是“alignment”,是对齐用户的偏好,然而实际上,这种人工的数据其实还是比较难获得并使用的。
在prompt这块,作者首先提出一个问题:“What if we cannot train LMs for downstream tasks?”,这个问题很现实,因为很多原因,我们可能没法训练模型,只能用开源的或者是固定通用的模型(心法利器[102] | 大模型落地应用架构的一种模式),此时,prompt就是一个非常好用的方案了。从结果层面显示,这种方案可以说是非常“effective”,同时作者还提及不用训练和并不差的效果(用的strong),但缺点也比较明显,可控性还是不够,相比微调的效果还是要差点。
然后,下一个问题,就是使用检索这个模式的时机了。说到时机,其实回归到前面所提到的原因就知道了,即长尾知识、知识过时、内容难验证、隐私问题和训练成本问题,经过作者的整理,从使用检索的原因,转为提及检索这个模式的优势,则是6点:长尾知识、知识更新能力、内容可验证性、参数效率、隐私以及域外知识的适配性(可迁移性)。
多模态
多模态是让自然语言处理超越文字本身的窗口了,知识的形式是丰富多样的,可以是文章、图谱、图片、视频、音频等,如果能把多种信息进行解析,那对知识的支撑能力无疑是新的提升(毕竟不是所有信息都通过文字传播),在这章,更多是给了很多知识应用的思路,论文还不少,此处不赘述,大家可以去PPT里面钱问题记得网站上面找参考文献。
挑战和展望
总算到了挑战和展望,本章在总结前文的基础上,提出了很多新的问题,研究者们可以参考作为新的研究方向。
首先是基于检索的LLM的规模,第一个问题是小模型+大数据库,是否能约等于一个大模型,
小模型+大数据库,是否能约等于一个大模型?两者在规模上的关系是什么样的。
两者的缩放规则是什么样的,当知识库能支撑知识层面的需求后,语言模型的参数量、token量对结果有什么影响。
检索效率问题,一个是速度,另一个是空间。
第二个问题是,需要探索其应用。
开放式文本生成下,基于检索的大模型在蕴含和推理能力上还有局限性,毕竟光靠相似度的检索不太够,同时知识库大了以后,面对相似但是困难的知识点也会对推理造成干扰。
对于复杂的推理任务,有没有更好的潜在方案可探索,例如多次检索、query改写等策略。
再然后,是一些开放的问题:
基于检索的LLMs下最优的结构和训练策略是什么样的。
对模型的规模,我们无法比较好地去拓展和提升,尤其在具有检索能力支持的情况下。
下游任务上,需要更多更好的解码、推理等方案,甚至是自适应的。
小结
这篇文章写了挺久的,可以说是大开眼界吧,里面的论文看了不少,收获还是挺大的,让我知道有关检索-LLM这个模式下有那么多前人尝试过的玩法,后面有些我应该也会去尝试,看看提升如何。
补充一下,有关RAG和这个Retrieval-based LLM,我自己感觉其实是一回事,很难感受出区别,如果有大佬了解的,欢迎在评论区指点下,感谢感谢。

 D. Maximum AND)



——综合的基础知识)



【java】A卷+B卷)


)

)





