文章目录
- (148)NN多目录配置
- (149)DataNode多目录配置及磁盘间数据平衡
- 磁盘间数据均衡
- 参考文献
(148)NN多目录配置
NN多目录的意思是,本地目录可以配置成多个,且每个目录存放内容相同,这样的目的是增加可靠性。比如说下图这样:

但其实生产中不常用哈,生产中要增加NN的可靠性的话,一般会开启NN的高可用,即在不同节点上开启多个NN,靠zookeeper来协调。
所以本节就了解一下即可。
配置的话,首先在hdfs-site.xml文件中添加如下内容:
<property><name>dfs.namenode.name.dir</name><value>file://${hadoop.tmp.dir}/dfs/name1,file://${hadoop.tmp.dir}/dfs/name2</value>
</property>
这个配置也可以不分发,每个节点单独调整,因为怕每个节点目录结构不一样,如果一样的话那就无所谓了。
停止集群myhadoop.sh stop,删除三台节点的data和logs中所有数据。
[atguigu@hadoop102 hadoop-3.1.3]$ rm -rf data/ logs/[atguigu@hadoop103 hadoop-3.1.3]$ rm -rf data/ logs/[atguigu@hadoop104 hadoop-3.1.3]$ rm -rf data/ logs/
(3)格式化集群并启动。
[atguigu@hadoop102 hadoop-3.1.3]$ bin/hdfs namenode -format[atguigu@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh
必须停止集群并重新格式化NameNode,所以如果是在生产环境下,集群一旦启动,那就不要再修改NameNode了。
最后,进入hadoop的data/dfs/目录下,查看文件结构,会发现,现在多了一个文件夹:
[atguigu@hadoop102 dfs]$ ll
总用量 12
drwx------. 3 atguigu atguigu 4096 12月 11 08:03 data
drwxrwxr-x. 3 atguigu atguigu 4096 12月 11 08:03 name1
drwxrwxr-x. 3 atguigu atguigu 4096 12月 11 08:03 name2
即name1和name2,且两个文件夹里的内容一模一样。
(149)DataNode多目录配置及磁盘间数据平衡
不同于NN多目录,在生产环境下,DN的多目录配置就非常重要了。
DN可以配置多个目录,且每个目录内存储的数据不一样。注意,不是一个副本一个目录,而是一个副本的数据可以分开存放在多个目录。
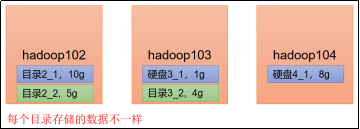
这个的好处其实很明显。
假设一个DataNode,我最早只挂了一块10G的磁盘,后来业务做大做强了,数据膨胀到10G以上了,这时候该怎么办?
这时候就可以给这个DN多挂载一块磁盘,然后通过DN的多目录,把新磁盘设定称为DN的第二个目录,新来的数据就可以继续往新磁盘放了。
老的数据不用大规模的动,新的数据还有地方放,这个的意义是很重要的。
具体配置,首先在hdfs-site.xml文件中添加:
<property><name>dfs.datanode.data.dir</name><value>file://${hadoop.tmp.dir}/dfs/data1,file://${hadoop.tmp.dir}/dfs/data2</value>
</property>
可以视情况分发配置。然后重启集群以识别修改。
进到hadoop安装目录的data/dfs/目录下,查看:
[atguigu@hadoop102 dfs]$ ll
总用量 12
drwx------. 3 atguigu atguigu 4096 4月 4 14:22 data1
drwx------. 3 atguigu atguigu 4096 4月 4 14:22 data2
drwxrwxr-x. 3 atguigu atguigu 4096 12月 11 08:03 name1
drwxrwxr-x. 3 atguigu atguigu 4096 12月 11 08:03 name2
可以看到,现在有两个data相关的文件夹了。
然后可以测试一下,在102上向集群上传一个文件,会发现上面两个文件夹里内容是不一样的,其中一个有数,另一个没有:
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -put wcinput/word.txt /
就不赘述了。
磁盘间数据均衡
但是给DN配置了多目录之后,又会引入一个新的问题,就是新的目录,它是空的,那我如果想把老目录里的部分数据转移到新的目录,让两个目录都不是那么空,也都不是那么满,那该怎么做呢?
可以执行磁盘数据均衡命令,对单节点内部的DN目录(位于不同磁盘)开始均衡。(这是Hadoop3.x的新特性)

(1) 首先生成均衡计划(单磁盘的话,不会生成计划):
hdfs diskbalancer -plan hadoop103
(2)执行均衡计划
hdfs diskbalancer -execute hadoop103.plan.json
(3)查看当前均衡任务的执行情况
hdfs diskbalancer -query hadoop103
(4)取消均衡任务
hdfs diskbalancer -cancel hadoop103.plan.json
有兴趣可以拿虚拟机增加磁盘来试一下。
参考文献
- 【尚硅谷大数据Hadoop教程,hadoop3.x搭建到集群调优,百万播放】



)






)



![利用TreeMap来解决P3029 [USACO11NOV] Cow Lineup S](http://pic.xiahunao.cn/利用TreeMap来解决P3029 [USACO11NOV] Cow Lineup S)


- 类型支持 (运行时类型识别,type_info ))

