六 继承与面向对象设计
红色字 \color{FF0000}{红色字} 红色字
32 确定你的public继承塑模出 is-a关系
如果你令class D (“Derived”)以public形式继承class B (“Base”),你便是告诉C++编译器(以及你的代码读者)说,每一个类型为D的对象同时也是一个类型为B的对象,反之不成立。你的意思是B比D表现出更一般化的概念,而D比B表现出更特殊化的概念。
你主张“B对象可派上用场的任何地方,D对象一样可以派上用场”,因为每一个D对象都是一种(是一个)B对象。反之如果你需要一个D对象,B对象无法效劳,因为虽然每个D对象都是-个B对象,反之并不成立。
is-a 理解为,继承中,派生类是一个基类(反之不成立)
总结
- “public继承”意味is-a。适用于base classes身上的每一件事情一定也适用于derived classes身上,因为每一个derived class对象也都是一个base class对象。
33 避免遮掩继承而来的名称
局部作用域变量遮掩外层作用域变量名称
int x;
void someFunc()
{double x;std::cin >> x;
}
如我们熟知的 局部变量double x;会接收输入的内容,寻找变量时会优先在当前作用域寻找。
继承中的遮掩
class Base{
private:int x;
public:virtual void mf1() = 0;virtual void mf2();void mf3();
};class Derived:public Base{
public:virtual void mf1();void mf4();
};void Derived::mf4()
{mf2();
}
当调用Derived::mf4()时,首先查找当前函数内的作用域是否有mf2的声明;然后去查找外围作用域,也就是class Derived覆盖的作用域;最后去基类中寻找,找到后停止查找。如果基类内没有mf2 ,将继续去基类所在的命名空间的作用域查找(如果有)。
继续看以下例子
class Base{
private:int x;
public:virtual void mf1() = 0;virtual void mf1(int);virtual void mf2();void mf3();void mf3(double);
};class Derived:public Base{
public:virtual void mf1();void mf3();void mf4();
};
Derived d;
int x;
d.mf1(); //没问题,调用Derived::mf1
d.mf1(x); //错误,因为Derived::mf1遮掩了Base::::mf1
d.mf2(); //没问题,调用Base::mf2
d.mf3(); //没问题,调用Derived::mf3
d.mf3(x); //没错误,调因为Derived::mf3遮掩了Base::::mf3
基类的mf1和mf3函数被派生类的mf1和mf3函数遮掩掉了,从名称查找观点来看,基类的mf1和mf3函数不再被继承。
继承的成员函数遮盖基类重载的函数.
如果解决以上问题呢,可尝试如下做法:
class Base{
private:int x;
public:virtual void mf1() = 0;virtual void mf1(int);virtual void mf2();void mf3();void mf3(double);
};class Derived:public Base{
public:using Base::mf1; //让Base class 内名为mf1和mf3的所有东西在Derived作用域内都可见using Base::mf3;virtual void mf1();void mf3();void mf4();
};
Derived d;
int x;
d.mf1(); //没问题,调用Derived::mf1
d.mf1(x); //没问题,调用Base::::mf1
d.mf2(); //没问题,调用Base::mf2
d.mf3(); //没问题,调用Derived::mf3
d.mf3(x); //没问题,调用Base::::mf3
这意味如果你继承base class并加上重载函数,而你又希望重新定义或覆写(推翻)其中一部分,那么你必须为那些原本会被遮掩的每个名称引入一个using声明式,否则某些你希望继承的名称会被遮掩。
using 声明会令继承而来的给定名称 的 所有同名函数 在derived class中都可见。
如果某些重载的函数不想继承,指向继承其中某一些函数呢,可以使用如下的转交函数
class Base{
public:virtual void mf1() = 0;virtual void mf1(int);
};class Derived:public Base{
public:virtual void mf1(){ //转交函数,暗自成为inlineBase::mf1(); }
};
Derived d;
int x;
d.mf1(); //没问题,调用Derived::mf1
d.mf1(x); //错误,Base::::mf1被遮掩了
总结
- derived classes 内的名称会遮掩 base classes 内的名称。在public继承下从来没有人希望如此。
- 为了让被遮掩的名称再见天日,可使用
using声明式或 转交函数( forwardingfunctions)。
34 区分接口继承与实现继承
class Shape{
public:virtual void draw() const = 0;virtual void error(const std::string& msg);int objectID() const;
};
class Rectangle:public Shape{};
class Ellipse:public Shape{};
成员函数的接口总是会被继承
基类可以调用的函数,也一定可以在派生类上调用。
声明纯虚函数的目的是为了让派生类只继承接口
通常是各个派生类都需要有,而且各不相同的方法。
虽然纯虚函数通常可以不进行定义实现,但是纯虚函数的实现其实是可以通过编译的,但访问时只能通过指定类名的方式。
void Shape::draw(){...};Shape* ps = new Shape; //错误 Shape是抽象的
Shape* ps1 = new Rectangle; //没问题
ps1->draw(); //调用 Rectangle::draw
Shape* ps2 = new Ellipse; //没问题
ps2->draw(); //调用 Ellipse::draw
ps1->Shape::draw(); //调用 Shape::draw
ps2->Shape::draw(); //调用 Shape::draw
声明非纯虚的虚函数的目的,是为了让派生类继承函数的的接口和缺省实现
如上例中的 Shape::error 。派生类即可重写,也可以不重写,调用这个缺省版本。
可能发生 派生类有业务需要重写此接口,但是忘记了重写 的情形,如何避免呢
将此接口声明为纯虚函数,并增加一个缺省实现的方法:
class Shape{
public:virtual void error(const std::string& msg)= 0;
protected:void defaultErr(const std::string& msg);//默认行为不允许修改,所以定义为protected
};
void Shape::defaultErr(const std::string& msg)
{//缺省行为
}//子类
class Rectangle:public Shape{
public:virtual void error(const std::string& msg){defaultErr(msg);}
};class Ellipse:public Shape{
public:virtual void error(const std::string& msg){defaultErr(msg);}
};
这时如果子类忘记实现error,则会导致错误,无法实例化。(error提供了接口继承,defaultErr提供了缺省实现继承)
还有一种方法,就是为纯虚函数实现:
class Shape{
public:virtual void error(const std::string& msg)= 0;
};
void Shape::error(const std::string& msg)
{//缺省行为
}//子类
class Rectangle:public Shape{
public:virtual void error(const std::string& msg){Shape::error(msg);}
};class Ellipse:public Shape{
public:virtual void error(const std::string& msg){Shape::error(msg);}
};
子类需要明确调用父类的纯虚函数。
声明非虚函数的目的是为了令派生类继承函数的接口及一份强制性实现。
它并不打算在派生类中有不同的行为。实际上一个非虚成员函数所表现的不变性( invariant〉凌驾其特异性(specialization),因为它表示不论派生类变得多么特异化,它的行为都不可以改变。
80-20法则:软件整体的性能取决于代码组成中的一小部分,所以不必每部分都很上心,找到程序中关键的那部分进行思考、优化。
总结
- 接口继承和实现继承不同。在public继承之下,派生类总是继承街垒的接口
- 纯虚函数只具体指定接口继承。
- 简朴的普通虚 函数具体指定接口继承及缺省实现继承。非虚函数具体指定接口继承以及强制性实现继承。
35 考虑virtual 函数以外的其他选择
考虑以下场景的替换virtual的实现方式
class GameCharacter {
public:virtual int healthValue() const; //返回角色人物的健康指数
};
使用非虚接口实现模板方法模式(Template Method)
特点是:接口函数是public 非虚的,此接口函数中调用private虚函数。
class GameCharacter {
public:int healthValue() const{//处理一些工作int retVal = doHealthValue();//处理另外一些工作return retVal;}
private:virtual int doHealthValue() const //派生类可重新定义{std::cout << "base do\n";return 0;}
};class EvilBadGuy :public GameCharacter {
private:virtual int doHealthValue() const{std::cout << "derive do\n";return 0;}
};EvilBadGuy gay;
gay.healthValue();//derive do
这种通过非虚函数接口(NVI non-virtual interface)的方法就是模板方法(Template Method)设计模式。
大致就是基类定义了何时调用,子类实现具体调用时作何操作。
用函数指针实现策略模式
class GameCharacter;
int defaultHealthCalc(const GameCharacter& gc);//计算健康指数的缺省算法
class GameCharacter {
public:typedef int(*HealthCalcFunc)(const GameCharacter&);explicit GameCharacter(HealthCalcFunc hcf = defaultHealthCalc):healthFunc(hcf){}int healthValue() const{return healthFunc(*this);}
private:HealthCalcFunc healthFunc;
};
不同的对象可以定制不同的计算规则,通过传入的函数指针参数
class GameCharacter;
int defaultHealthCalc(const GameCharacter& gc)//计算健康指数的缺省算法
{std::cout << "defaultHealthCalc\n";return 0;
}
class GameCharacter {
public:typedef int(*HealthCalcFunc)(const GameCharacter&);explicit GameCharacter(HealthCalcFunc hcf = defaultHealthCalc):healthFunc(hcf){}int healthValue() const{return healthFunc(*this);}
private:HealthCalcFunc healthFunc;
};int loseHealthQuickly(const GameCharacter&) {std::cout << "loseHealthQuickly\n";return 0;
}int loseHealthSlowly(const GameCharacter&) {std::cout << "loseHealthSlowly\n";return 0;
}class EvilBadGuy :public GameCharacter
{
public:explicit EvilBadGuy(HealthCalcFunc hcf = defaultHealthCalc):GameCharacter(hcf){};
};EvilBadGuy ebg1(loseHealthQuickly);EvilBadGuy ebg2(loseHealthSlowly);ebg1.healthValue();//loseHealthQuicklyebg2.healthValue();//loseHealthSlowly
需要注意的是,计算函数中不可访问类的私有成员,所以采用此种方式,应该保证计算方式可以通过类的公有成员方法实现。
tr1::function
参考:https://blog.csdn.net/B10090411/article/details/53171669
//t.cpp
#include "stdafx.h"
#include<iostream>
#include<functional>
using namespace std;
void foo(int i){cout<<"aaa"<<endl;}
void (*p)(int)=foo;
int _tmain(int argc, _TCHAR* argv[])
{function<void (int)> fm;fm=foo;(*p)(2);fm(2);return 0;
}
它和函数指针很像
1.定义一个function对象。
由于function是一个类模板,所以使用起来,首先定义一个类的对象。
Function <void (int)> fm;-----<>中第一个参数是要绑定函数的返回类型,第二个参数是要绑定的函数的参数列表。注意使用小括号括起来。
2.像函数指针一样,这个指针需要指向某个函数。
fm=function<void (int)>(foo);
优点:
函数指针只能绑定普通的外部函数。而tr1::function可以绑定各种函数类型
- 外部普通函数和类的static函数
//t.cpp
#include "stdafx.h"
#include<iostream>
#include<functional>
using namespace std;
class A{
public:
static void foo(inti){cout<<"aaa"<<endl;}
};
int _tmain(int argc, _TCHAR* argv[])
{function<void (int)>fm(A::foo);//function<void (int)> fm;fm=function<void(int)>(A::foo); also OKvoid (*p)(inti)=A::foo();//errorfm(2);return 0;
}
- 类的非static成员函数
//t.cpp
#include "stdafx.h"
#include<iostream>
#include<functional>
using namespace std;
class A{
public:
void foo(int i){cout<<"aaa"<<endl;}
};
int _tmain(int argc, _TCHAR* argv[])
{A b;function<void (int)>fm=bind(&A::foo,b,tr1::placeholders::_1);//OK//function<void (int)> fm=b.foo();//errorfm(2);return 0;
}
通过tr1::function 完成策略模式
class GameCharacter;
int defaultHealthCalc(const GameCharacter& gc)//计算健康指数的缺省算法{std::cout << "defaultHealthCalc\n";return 0;
}
class GameCharacter {
public:typedef std::tr1::function<int (const GameCharacter&)> HealthCalcFunc;explicit GameCharacter(HealthCalcFunc hcf = defaultHealthCalc):healthFunc(hcf){}int healthValue() const{return healthFunc(*this);}
private:HealthCalcFunc healthFunc;
};
貌似还有风险

和上面相比,唯一的不同就是由GameCharacter持有函数指针变成了GameCharacter持有一个 tr1::function对象,但是使用场景更多样了:
short calcHealth(const GameCharacter&); //健康计算函数;返回类型为short
struct HealCalculator{ //计算健康的函数对象int operator()(const GameCharacter&) const{...}
};
class GameLevel{
public:float health(const GameCharacter&) const; //成员函数
};
class EvilBadGuy:public GameCharacter{}; //同上
class EyeCandyCharacter:public GameCharacter{...}; //新的人物类型,假设构造函数与EvilBadGuy相同EvilBadGuy ebg1(calcHealth); //人物1,使用函数
EyeCandyCharacter eccl(HealCalculator()); //人物2,使用函数对象
GameLevel currentLevel;
EvilBadGuy ebg2(std::st1::bind(&GameLevel::health,currentLevel,_1)); //人物2,使用成员函数,health的this指针隐藏参数使用的是对象currentLevel
古典策略模式
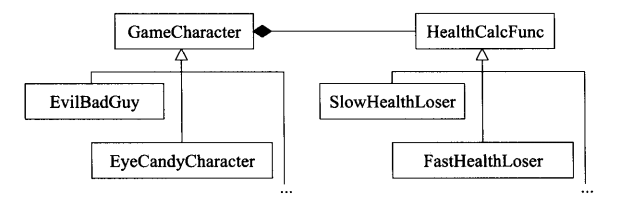
实现如下:
class GameCharacter;
class HealthCalcFunc {
public:virtual int calc(const GameCharacter& gc)const{std::cout << "HealthCalcFunc:calc\n";return 0;}
};
HealthCalcFunc defaultHealthCalc;
class GameCharacter {
public:explicit GameCharacter(HealthCalcFunc *phcf = &defaultHealthCalc):phealthFunc(phcf){}int healthValue() const{return phealthFunc->calc(*this);}
private:HealthCalcFunc* phealthFunc;
};
使用non-virtual interface (NVI)手法,那是Template Method设计模式的一种特殊形式。它以 public non-virtual成员函数包裹较低访问性( private或protected)的 virtual函数。
将virtual 函数替换为“函数指针成员变量”,这是Strategy设计模式的一种分解表现形式。
以tr1: :function成员变量替换virtual函数,因而允许使用任何可调用物( callable entity)搭配一个兼容于需求的签名式(也就是满足tr1: :function定义的类型)。这也是Strategy设计模式的某种形式。
将继承体系内的 virtual函数替换为另一个继承体系内的 virtual函数。这是strategy设计模式的传统实现手法。
总结
- virtual函数的替代方案包括NVI手法及Strategy设计模式的多种形式。NVI手法自身是一个特殊形式的Template Method设计模式。
- 将机能从成员函数移到class外部函数,带来的一个缺点是,非成员函数无法访问class 的 non-public成员。
- tr1 : : function对象的行为就像一般函数指针。这样的对象可接纳“与给定的目标签名式( target signature)兼容”的所有可调用物((callable entities)。
36 绝不重新定义继承而来的 non-virtual 函数
class B{
public:void mf();
};class D:public classB{
};D x;
B* pB = &x;
pB->mf(); //调用B::mfD* pD = &x;
pD->mf(); //调用B::mf
如果D定义自己的mf
class D:public classB{
public:void mf();
};
pB->mf(); //调用B::mf
pD->mf(); //调用D::mf
非虚函数静态绑定,定义的指针类型是什么就调用对应的类型的函数。
对于继承,有两个观点:
- 适用于基类的函数(特性),也适用于派生类(is-a的关系)
- 派生类会继承基类的接口与实现,因为mf是非虚函数
如果D重新定义了mf,就与设计初衷相反,非虚函数应表现为不变性,虚函数才表现为特异性凌驾于不变性。如果不是每个D都是一个B,那么就不应该public继承。
总结
- 绝对不要重新定义继承而来的非虚函数。
37 绝不重新定义继承而来的缺省参数值
原因就在于:虚函数是动态绑定的,缺省参数却是静态绑定的
#include <iostream>enum ShapeColor { Red, Green, Blue };
class Shape {
public:virtual void draw(ShapeColor color = Red) const = 0;
};
class Rectangle :public Shape {
public:virtual void draw(ShapeColor color = Green) const{std::cout << "Rectangle default Green! color="<<color<<std::endl;}
};
class Circle :public Shape {
public:virtual void draw(ShapeColor color ) const{std::cout << "Circle default no! color=" << color << std::endl;}
};
int main()
{Shape* ps; //静态类型为Shape*Shape* pc = new Circle; //静态类型为Shape*Shape* pr = new Rectangle; //静态类型为Shape*pc->draw(ShapeColor::Blue); //调用 Circle::draw Circle default no! color=2pr->draw(ShapeColor::Blue); //调用 Rectangle::draw Rectangle default Green! color=2pr->draw(); //调用 Rectangle::draw(ShapeColor::Red) Rectangle default Green! color=0pc->draw(); //调用 Circle::draw(ShapeColor::Red) Circle default no! color=0delete pc;delete pr;return 0;
}
虽然 pr 的 draw 动态绑定到了指向的 new Rectangle,但是draw 的缺省参数却仍然使用 声明时的Shape* pr,也就是Shape::draw(ShapeColor color = Red)。意思是你可能会在“调用一个定义于派生类内的virtual函数”的同时,却使用base class为它所指定的缺省参数值。
避免起来可以使用条款36中的做法:
enum ShapeColor { Red, Green, Blue };
class Shape {
public:void draw(ShapeColor color = Red) const{doDraw(color);}
private:virtual void doDraw(ShapeColor color) const = 0;//真正执行的地方
};
class Rectangle :public Shape {
private:virtual void doDraw(ShapeColor color) const; //不再指定缺省参数
};
如此,缺省值总是Red
总结
- 绝对不要重新定义一个继承而来的缺省参数值,因为缺省参数值都是静态绑定,而virtual函数中 你唯一应该覆写的东西却是动态绑定。
38 通过复合塑模出 has-a 或“根据某物实现出”
查看以下场景
class Address {};
class PhoneNumber{};class Person
{
public:Person();~ Person();private:std::string name;Address address;PhoneNumber voiceNumber;PhoneNumber faxNumber;
};Person:: Person()
{
}Person::~ Person()
{
}
类 Person 中包含成员的类型包括 Address 、PhoneNumber。当某种类型的对象内包含其他类型的对象时,就是复合关系;复合关系可以是has-a(有一个),也可能是is-implemented-in-terms-of(根据某物实现出)。以上这种就可以看作为has-a的关系。
查看以下例子:
template<class T>class Set {public:bool memeber(const T& item) const;void insert(const T& item);void remove(const T& item);std::size_t size() const;private:std::list<T> rep; //用来表述set的数据};template<typename T>bool Set<T>::memeber(const T& item) const{return std::find(rep.begin(), rep.end(), item) != rep.end();}template<typename T>void Set<T>::insert(const T& item){if (!member(item)) rep.push_back(item);}template<typename T>void Set<T>::remove(const T& item){typename std::list<T>::iterator it = std::find(rep.begin(), rep.end(), item);if (it != rep.end()) rep.erase(it);}template<typename T>std::size_t Set<T>::size() const{return rep.size();}
自己实现不重复队列类Set(之所以没有选择继承,是因为 set明显不是一个list,list的元素可以重复);通过成员rep 实现队列功能,可以看做是 is-implemented-in-terms-of。
总结
- 复合(composition)的意义和public 继承完全不同。
- 在应用域,复合意味has-a(有一个)。在实现域( implementation domain),复合意味is-implemented-in-terms-of(根据某物实现出)
39 明智而审慎的使用private继承
class Person{};
class Student:public Person{};
void eat(const Person& p);
void study(const Student& s);Person p;
Student s;eat(p); //没问题
eat(s); //报错,s无法转为Person
Private继承意味 implemented-in-terms-of (根据某物实现出)。如果你让 class D 以 private 形式继承 class B,你的用意是为了采用 class B 内已经备妥的某些特性,不是因为B对象和p对象存在有任何观念上的关系。
private 继承纯粹只是一种实现技术(这就是为什么继承自一个 private baseclass 的每样东西在你的 class 内都是 private:因为它们都只是实现枝节而己)。
private 继承意味只有实现部分被继承,接口部分应略去。如果D以 private 形式继承B,意思是D对象根据B对象实现而得,再没有其他意涵了。Private 继承在软件“设计”层面上没有意义,其意义只及于软件实现层面。
上一条款有说到,复合的意义就是 implemented-in-terms-of (根据某物实现出),而 private 的意义也是如此,那么该如何取舍呢,以下为例:
class Timer {public:explicit Timer(int tickFrequency) :m_nTicks(tickFrequency){ };virtual void onTick() const;};class Widget :private Timer {private:virtual void onTick() const ;};
我们决定修改widget class,让它记录每个成员函数的被调用次数。运行期间我们将周期性地审查那份信息,也许再加上每个 widget 的值,以及我们需要评估的任何其他数据。为完成这项工作,我们需要设定某种定时器,使我们知道收集统计数据的时候是否到了。这就是我们找到的东西。一个Timer对象,可调整为以我们需要的任何频率滴答前进,每次滴答就调用某个virtual函数。我们可以重新定义那个virtual函数,让后者取出widget的当时状态。完美!
作者提及的思路没太明白,如何实现的滴答,但是结论部分可以参考。
1.widget不是timer,所以如此继承不是很合适
2.在widget中需要重新定义onTick,这不是一个对外合理的接口,为了避免错误调用,如此设计不是很合理
3.编译依存性问题,增加了新的类,可能也会导致新的头文件的引入。
所以可以尝试以下方式:
class Widget {private:class WidgetTimer {public:virtual void onTick() const;};WidgetTimer timer;};
有一种激进的保证内存的 使用私有继承而不是复合的情况。
c++ 规定 凡是独立(非附属)对象都必须是非零大小
class Empty{}; //没有数据,所以应该不使用任何内存class HoldsAnInt{ //应该只需要一个int控件
private:int x;Empty e; //应该不需要任何内存
};
当时最后会发现 sizeof(HoldsAnInt) > sizeof(int);
在大多数编译器中 sizeof(Empty)的大小为1,面对 大小为0的独立(非附属)对象,通常C+官方勒令默默安插-一个char到空对象内。然而齐位需求(alignment,见条款50)可能造成编译器为类似HoldsAnInt 这样的class加上一些衬垫( padding),所以有可能HoldsAnInt对象不只获得–个char大小,也许实际上被放大到足够又存放一个int。在我试过的所有编译器中,的确有这种情况发生。
但是如下情况
class HoldsAnInt:private Empty{ //只需要一个int空间
private:int x;
};
这就是EBO(empty base optimization 空白基类最优化)
复合和 private 继承都意味着 is-implemented-in-terms-of,但是复合比较容易理解,所以无论什么时候,只要可以,还是应该选择复合。“明智而审慎的使用 private 继承”意味,在考虑其他方案之后,如果仍然认为 private 继承 是“表现程序内两个classes之间的关系”的最佳办法,这才用它。
总结
- Private继承意味is-implemented-in-terms of(根据某物实现出)。它通常比复合(composition)的级别低。但是当derived class需要访问protected base class 的成员,或需要重新定义继承而来的 virtual函数时,这么设计是合理的。
- 和复合(composition)不同,private继承可以造成empty base最优化。这对致力于“对象尺寸最小化”的程序库开发者而言,可能很重要。
40 明智而审慎的使用多重继承
当多重继承时,可能会发生重名的现象:
#include <iostream>
class BorrowableItem {
public:void checkOut() {std::cout << "BorrowableItem checkOut!\n";}
};class ElectronicGadget {
private:bool checkOut() const {std::cout << "ElectronicGadget checkOut!\n";}
};class MP3Player : public BorrowableItem, public ElectronicGadget {};int main()
{MP3Player mp;mp.checkOut();//编译报错,对checkOut的访问不明确std::cout << "Hello World!\n";
}
这里由于两个基类都有 checkOut 成员函数,所有有歧义(虽然 ElectronicGadget 类中为私有成员),导致不错,可以如下修改:
mp.BorrowableItem::checkOut();
如果调用mp.ElectronicGadget ::checkOut();则会报错调用private成员函数。
钻石型多重继承
class File{};
class InputFile:public File{};
class OutputFile:public File{};
class IOFile:public InputFile,public OutputFile{};
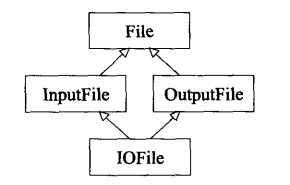
这种情况中,IOFile内就会有两份File中的成员,分别从InputFile和OutputFile中继承。
为解决这种情况,就可以考虑使用虚继承
参考:https://blog.csdn.net/weixin_61857742/article/details/127344922
使用virtual继承的那些classes所产生的对象往往比使用non-virtual继承的兄弟们体积大,访问virtual base classes 的成员变量时,也比访问 non-virtual base classes 的成员变量速度慢。种种细节因编译器不同而异,但基本重点很清楚:你得为 virtual继承付出代价。
但是有的场景使用多重继承更加合理方便,有时候不得不重写基类的方法,或者继承接口类时。
class IPerson{
public:virtual ~IPerson();virtual std::string name() const = 0;virtual std::string birthDate() const = 0;
};
class DatabaseID{};
class PersonInfo{ //用来实现IPerson接口
public:explicit PersonInfo(DatabaseID pid);virtual ~PersonInfo();virtual const char* theName() const;virtual const char* theBirthDate() const;virtual const char* valueDelimOpen() const;virtual const char* valueDelimClose() const;
};class CPerson:public IPerson,private PersonInfo{
public:explicit CPerson(DatabaseID pid):PersonInfo(pid){}virtual std::string name() const{return PersonInfo::theName();}virtual std::string birthDate() const{return PersonInfo::theBirthDate();}
private:const char* valueDelimOpen() const {return "";}const char* valueDelimClose() const {return "";}//重新定义继承来的 virtual 界限函数
};

总结
- 多重继承比单一继承复杂。它可能导致新的歧义性,以及对 virtual 继承的需要。virtual 继承会增加大小、速度、初始化(及赋值)复杂度等等成本。如果 virtual base classes 不带任何数据,将是最具实用价值的情况。
- 多重继承的确有正当用途。其中一个情节涉及“public继承某个Interface class”和“private继承某个协助实现的class”的两相组合。
七 模板与泛型编程
41 了解隐式接口和编译期多态
Templates及泛型编程的世界,与面向对象有根本上的不同。在此世界中显式接口和运行期多态仍然存在,但重要性降低。反倒是隐式接口(implicit interfaces)和编译期多态(compile-time polymorphism〉移到前头。
参考阅读:https://blog.csdn.net/shayne000/article/details/88591210
查看例子
class Widget{
public:Widget();virtual ~Widget();virtual std::size_t size() const;virtual void normalize();void swap(Widget& other);
};void doProcessing(Widget& w) //不考虑实际使用意义
{if(w.size()> 10 && w != someNastyWidget){Widget temp(w);temp.normalize();temp.swap(w);}
}
在模板和泛型编程中可能会写成
template<typename T>
void doProcessing(T& w) //不考虑实际使用意义
{if(w.size()> 10 && w != someNastyWidget){T temp(w);temp.normalize();temp.swap(w);}
}
对模板参数而言,多态是通过模板具现化和函数重载解析实现的。以不同的模板参数具现化导致调用不同的函数,这就是所谓的编译期多态。
相比较于运行期多态,实现编译期多态的类之间并不需要成为一个继承体系,它们之间可以没有什么关系,但约束是它们都有相同的隐式接口。
个人理解就是,传入的类型不同(typename ),造成调用不同类型的对应接口,也就是对于w,可以是 Widget 类型也可以是 Widget2 类型,这取决于调用 doProcessing 时,实参类型,这就是编译器多态。
而隐式接口就是指,在函数 doProcessing 中,对类型T做出的要求、约束,要求T类型需要
它必须提供一个名为size的成员函数,该函数返回一个整数值。
它必须支持一个operator!=函数,用来比较两个T对象。这里我们假设someNastywidget的类型为T。
当然,如果再考虑上操作符重载,这两个约束都不需要满足。T必须支持size成员函数,然而这个函数也可能从base class 继承而得。这个成员函数不需返回一个整数值,甚至不需返回一个数值类型。就此而言,它甚至不需要返回一个定义有operator>的类型!它唯一需要做的是返回一个类型为x的对象,而x对象加上一个int(10的类型)必须能够调用一个operator>。这个operator>不需要非得取得一个类型为x的参数不可,因为它也可以取得类型Y的参数,只要存在一个隐式转换能够将类型x的对象转换为类型r的对象!
同样道理,T并不需要支持operator!=,因为以下这样也是可以的: operator!=接受一个类型为 x的对象和一个类型为Y的对象,T可被转换为x而someNastywidget的类型可被转换为r,这样就可以有效调用operator!=。
通常显式接口由函数的签名式(也就是函数名称、参数类型、返回类型)构成。
class Widget{
public:Widget();virtual ~Widget();virtual std::size_t size() const;virtual void normalize();void swap(Widget& other);
};
//Widget 的显示接口
隐式接口就完全不同了。它并不基于函数签名式,而是由有效表达式(valid expressions) 组成。
template<typename T>
void doProcessing(T& w) //不考虑实际使用意义
{if(w.size()> 10 && w != someNastyWidget){T temp(w);temp.normalize();temp.swap(w);}
}
//形参w(T类型)的隐式接口
总结
- classes 和 templates 都支持接口( interfaces)和多态(polymorphism) 。
- 对 classes 而言接口是显式的( explicit),以函数签名为中心。多态则是通过virtual函数发生于运行期。
- 对 template 参数而言,接口是隐式的(implicit),奠基于有效表达式。多态(编译器多态)则是通过 template 具现化和函数重载解析(function overloading resolution)发生于编译期。
42 了解 typename 的双重意义
试看以下区别
template<class T> class Widget;
template<typename T> class Widget;
答案:没有不同。当我们声明template类型参数,class 和 typename 的意义完全相同。某些程序员始终比较喜欢class,因为可以少打几个字。其他人(包括我〉比较喜欢 typename,因为它暗示参数并非一定得是个 class 类型。少数开发人员在接受任何类型时使用 typename,而在只接受用户自定义类型时保留旧式的 class。然而从C++的角度来看,声明 template 参数时,不论使用关键字 class 或typename,意义完全相同。
从属名称
template<typename C>
void print2nd(const C& container)
{if(container.size()>=2){C::const_iterator iter(container.begin());++iter;int value = *iter;std::cout << value;}
}
两个局部变量 iter 和 value。 iter 的类型是C: : const_iterator,实际是什么必须取决于 template 参数c。template 内出现的名称如果相依于某个 template 参数,称之为从属名称(dependent names)。如果从属名称在 class 内呈嵌套状,我们称它为嵌套从属名称( nested dependent name)。c: :const_iterator就是这样一个名称。实际上它还是个嵌套从属类型名称(nesteddependent type name),也就是个嵌套从属名称并且表示某类型。
print2nd 内的另一个 local 变量value,其类型是 int。int 是一个并不倚赖任何 template 参数的名称。这样的名称是谓非从属名称(non-dependent names)。
嵌套从属名称可能导致解析混乱:
template<typename C>
void print2nd(const C& container)
{C::const_iterator* x;
}
看起来好像我们声明x为一个local变量,它是个指针,指向一个c: :const_iterator。
如果c有个static成员变量而碰巧被命名为const_iterator,或如果x碰巧是个global变量,那么就这个语句就是将两个变量相乘。
C++有个规则可以解析(resolve)此一歧义状态:如果解析器在template中遭遇一个嵌套从属名称,它便假设这名称不是个类型,除非你告诉它是。所以缺省情况下嵌套从属名称不是类型。
一般性规则很简单:任何时候当你想要在template中指涉一个嵌套从属类型名称,就必须在紧临它的前一个位置放上关键字typename。
template<typename C>
void print2nd(const C& container)
{typename C::const_iterator* x;
}
typename 只被用来验明嵌套从属类型名称;其他名称不该有它存在。
template<typename C> //允许使用 typename
void f(const C& container, //不允许使用 typenametypename C::iterator iter); //一定使用 typename
上述的c并不是嵌套从属类型名称(它并非嵌套于任何“取决于template参数”的东西内),所以声明container 时并不需要以 typename 为前导,但 c: :iterator 是个嵌套从属类型名称,所以必须以typename 为前导。
“typename 必须作为嵌套从属类型名称的前缀词”这一规则的例外是,typename不可以出现在 base classes list 内的嵌套从属类型名称之前,也不可在member initialization list(成员初值列)中作为base class修饰符。例如:
template<typename T>
class Derived:public Base<T>::Nested{ //base class list中不允许typename
public:explicit Derived(int x):Base<T>::Nested(x) //member initial list 中不允许typename{typename Base<T>::Nested Temp; //嵌套从属类型名称,既不在base class list中也不在 mem init list中,需要加上typename}
};
查看某个特殊例子
template<typename IterT>
void workWithIterator(IterT iter)
{typedef typename std::iterator_traits<IterT>::value_type value_type;value_type temp(*iter);
}
别让 std: :iterator_traits<IterT> : :value_type 惊吓了你,那只不过是标准traits class(见条款47)的一种运用,相当于说“类型为IterT的对象所指的目标的类型”。这个语句声明一个local变量(temp),类型就是 IterT 对象所指的目标的类型,并将 temp 初始化为iter所指物。
如果IterT是vector: :iterator,temp的类型就是int。
如果IterT是 list : :iterator,temp的类型就是string。
总结
- 声明 template 参数时,前缀关键字 class 和 typename 可互换。
- 请使用关键字 typename 标识嵌套从属类型名称;但不得在base class lists(基类列表)或member initialization list(成员初值列表)内把它作为base class修饰符。
43 学习处理模板化基类内的名称
class CompanyA {
public:void sendCleartext(const std::string& msg);void sendEncrypted(const std::string& msg);
};class CompanyB {
public:void sendCleartext(const std::string& msg);void sendEncrypted(const std::string& msg);
};class CompanyZ {
public:void sendEncrypted(const std::string& msg);
};class MsgInfo{};template<typename Company>
class MsgSender {
public:void sendClear(const MsgInfo& info){std::string msg;Company c;c.sendCleartext(msg);}void sendSecret(const MsgInfo& info){std::string msg;Company c;c.sendEncrypted(msg);}
};template<>
class MsgSender<CompanyZ> { //全特化版本
public:void sendSecret(const MsgInfo& info){std::string msg;CompanyZ c;c.sendEncrypted(msg);}
};template<typename Company>
class LoggingMsgSender :public MsgSender<Company> {
public:void sendClearMsg(const MsgInfo& info){sendClear(info); //编译报错 找不到标识符 sendClear}
};
LoggingMsgSender 继承的是MsgSender,但其中的 company 是个 template 参数,不到后来(当LoggingMsgSender被具现化)无法确切知道它是什么。而如果不知道 Company 是什么,就无法知道class Msgsender看起来像什么,更明确地说是没办法知道它是否有个 sendClear 函数。上面例子中的全特化 template<> class MsgSender 就没有 sendClear 函数。
注意 class 定义式最前头的“template<>”语法象征这既不是 template 也不是标准 class,而是个特化版的 MsgSender template,在 template 实参是 Companyz 时被使用。这是所谓的模板全特化( total template specialization) : template MsgSender针对类型Companyz 特化了,而且其特化是全面性的,也就是说一旦类型参数被定义为 Companyz,再没有其他 template 参数可供变化。
c++ 往往拒绝在 templatized base classes(模板化基类,本例的 MsgSender)内寻找继承而来的名称(本例的 SendClear)。
为了可以通过编译,可以采用以下几种方式:
this->
template<typename Company>
class LoggingMsgSender :public MsgSender<Company> {
public:void sendClearMsg(const MsgInfo& info){this->sendClear(info); //通过编译,假设 sendClear 将被继承}
};
using
template<typename Company>
class LoggingMsgSender :public MsgSender<Company> {
public:using MsgSender<Company>::sendClear; //告诉编译器,假设 sendClear 在base class中void sendClearMsg(const MsgInfo& info){sendClear(info); //通过编译,假设 sendClear 将被继承}
};
(虽然using声明式在这里或在条款33都可有效运作,但两处解决的问题其实不相同。这里的情况并不是base class名称被derived class名称遮掩,而是编译器不进入 base class作用域内查找,于是我们通过using告诉它,请它那么做。)
MsgSender<Company>::
template<typename Company>
class LoggingMsgSender :public MsgSender<Company> {
public:void sendClearMsg(const MsgInfo& info){MsgSender<Company>::sendClear(info); //通过编译,假设 sendClear 将被继承}
};
但是这种方法在sendClear是虚函数时 将会导致多态调用碰到错误,只会调用基类的sendClear。
以上方式虽然能通过编译,但是只是承诺给编译器 继承了 sendClear ,如果实际没有,也还是报错
LoggingMsgSender<CompanyZ> zMsgSender;MsgInfo msgData;zMsgSender.sendClearMsg(msgData);
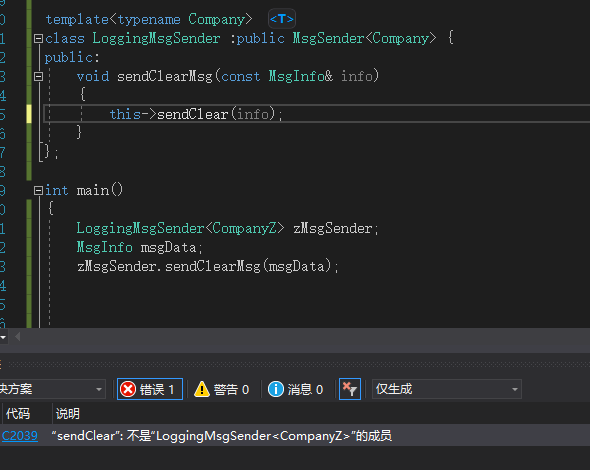
根本而言,本条款探讨的是,面对“指涉base class members”之无效references,编译器的诊断时间可能发生在早期(当解析derived class template的定义式时),也可能发生在晚期(当那些templates被特定之template实参具现化时)。C++的政策是宁愿较早诊断,这就是为什么“当base classes 从templates中被具现化时”它假设它对那些base classes 的内容不去查找的缘故。
总结
- 可在 derived class templates 内通过"this->”指向 base class templates 内的成员名称,或藉由一个明白写出的“base class资格修饰符”(作用域说明)完成。
44 将与参数无关的代码抽离 templates
读第一遍,完全不知道在说什么的条款。
基本思路就是像函数一样,将具有相同功能的代码部分抽离到另外一个函数中。
模板函数、模板类会根据不同的类型参数生成不同的函数、类,其中的代码,也会被生成多份,特性不高的代码将会造成不必要的冗余。
如下导致代码膨胀的例子
template<typename T,std::size_t n> //支持n x n矩阵,元素为T类型
class SquareMatrix{
public:void invert(); //求逆矩阵
};SquareMatrix<double,5> sm1;
sm1.invert();SquareMatrix<double,10> sm2;
sm2.invert();
原文:这会具现化两份invert。这些函数并非完完全全相同,因为其中一个操作的是55矩阵而另一个操作的是1010矩阵,但除了常量5和10,两个函数的其他部分完全相同。这是template引出代码膨胀的一个典型例子。
如下进行修改:
template<typename T>
class SquareMatrixBase{
protected:void invert(std::size_t matrixSize); //以给定尺寸 求逆矩阵
};template<typename T,std::size_t n>
class SquareMatrix: private SquareMatrixBase<T>{
private:using SquareMatrixBase<T>::invert;
public:void invert(){this->invert(n);}; //调用基类 invert 求逆矩阵
};
SquareMatrixBase 只对元素对象的类型 参数化,不对矩阵尺寸参数化,因此对于某给定的元素对象类型,所有矩阵共享同一个(也是唯一一个) SquareMatrixBase class。它们也将因此共享这唯一一个 class 内的 invert。
接下来考虑更为复杂的场景,加入矩阵的数据。
template<typename T>
class SquareMatrixBase{
protected:SquareMatrixBase(std::size_t n, T* pMem):size(n),pData(pMem){}void setDataPtr(T* ptr){pData = ptr;} //重新复制矩阵内容
private:std::size_t size; //矩阵大小T* pData; //指针,指向矩阵内容
};template<typename T,std::size_t n>
class SquareMatrix: private SquareMatrixBase<T>{
private:T data[n*n];
public:SquareMatrix():SquareMatrixBase<T>(n,data){}
};
这种类型的对象不需要动态分配内存,但对象自身可能非常大。另一种做法是把每一个矩阵的数据放进heap(也就是通过new来分配内存):
template<typename T,std::size_t n>
class SquareMatrix: private SquareMatrixBase<T>{
private:boost::scoped_array<T> pData;
public:SquareMatrix():SquareMatrixBase<T>(n,data),pData(new T[n*n]){this->setDataPtr(pData.get());}
};
原文:不论数据存储于何处,从膨胀的角度检讨之,关键是现在许多----说不定是所有—–SquareMatrix成员函数可以单纯地以inline方式调用base class版本,后者由“持有同型元素”(不论矩阵大小)之所有矩阵共享。在此同时,不同大小的squareMatrix对象有着不同的类型,所以即使(例如 squareMatrix<double,5>和squareMatrix<double,10>)对象使用相同的squareMatrixBase成员函数,我们也没机会传递一个SquareMatrix<double,5>对象到一个期望获得SquareMatrix<double,10>的函数去。很棒,对吗?
读了几遍后的理解,前面的一句比较好理解,基类模板参数只和矩阵类型 参数有关,但参数相同时,使用的基类是一个类。
同样的,派生类的模板参数为矩阵类型和矩阵大小,不同的矩阵大小、类型不是同一个类的对象,所以调用函数、传递的参数也不一样。
原文:硬是绑着矩阵尺寸的那个invert版本,有可能生成比共享版本(其中尺寸乃以函数参数传递或存储在对象内)更佳的代码。例如在尺寸专属版中,尺寸是个编译期常量,因此可以藉由常量的广传达到最优化,包括把它们折进被生成指令中成为直接操作数。这在“与尺寸无关”的版本中是无法办到的。
读了几遍没读懂,什么是“藉由常量的广传达到最优化”和“折进被生成指令中成为直接操作数”?是指在编译器优化代码的意思吗,就像内联函数会被自动又换?
接下来说的比较好理解,模板生成的冗余函数减少后,代码页占用的内存减少,寻址会更加快和高效。
原文:这个条款只讨论由non-type template parameters(非类型模板参数>带来的膨胀,其实type parameters(类型参数)也会导致膨胀。例如在许多平台上. int和long有相同的二进制表述,所以像vector和vector的成员函数有可能完全相同一-这正是膨胀的最佳定义。某些连接器(linkers)会合并完全相同的函数实现码,但有些不会,后者意味某些templates被具现化为int和 long两个版本,并因此造成代码膨胀(在某些环境下)。类似情况,在大多数平台上,所有指针类型都有相同的二进制表述,因此凡 templates持有指针者(例如list<int*>,list<const int*>, list<SquareMatrix<long,3>>等等)往往应该对每一个成员函数使用唯一一份底层实现。这很具代表性地意味,如果你实现某些成员函数而它们操作强型指针(strongly typed pointers,即T),你应该令它们调用另个操作无类型指针(untyped pointers,即void*)的函数,由后者完成实际工作。某些C++标准程序库实现版本的确为vector,deque和 list 等templates做了这件事。如果你关心你的templates可能出现代码膨胀,也许你会想让你的templates 也做相同的事情。
这里如果举个例子会更好理解,我的理解是,针对指针的操作时,不必再针对指针指向的类型区分对待,全部作为void指针进行操作存储,将这部分操作统一到一处、一个函数中执行。
总结
- Templates 生成多个classes和多个函数,所以任何templatc代码都不该与某个造成膨胀的 template参数产生相依关系。
- 因非类型模板参数(non-type template parameters)而造成的代码膨胀,往往可消除,做法是以函数参数或class成员变量替换template参数。
- 因类型参数(type parameters)而造成的代码膨胀,往往可降低,做法是让带有完全相同二进制表述(binary representations)的具现类型( instantiation types)共享实现码。
45 运用成员函数模板接受所有兼容类型
class Top{};
class Middle:public Top{};
class Bottom:public Middle{};
Top* pt1 = new Middle;
Top* pt2 = new Bottom; //将Bottom*转换为Top*
const Top* pct2 = pt1; //将Top*转换为const Top*就像派生类指针可以隐式转换为基类指针一样,
我们期望智能指针也能如此,如下的场景:
template<typename T>
class SmartPtr {
public:explicit SmartPtr(T* realPtr); //智能指针通常以内置(原始)指针完成初始化
};SmartPtr<Top> pt1 = SmartPtr<Middle>(new Middle); //希望将SmartPtr<Middle> 转换为SmartPtr<Top>
SmartPtr<Top> pt1 = SmartPtr<Bottom>(new Bottom); //希望将SmartPtr<Bottom> 转换为SmartPtr<Top>
SmartPtr<const Top> pct1 = pt1; //希望将SmartPtr<Top> 转换为SmartPtr<const Top>
但是,同一个 template 的不同具现体( instantiations)之间并不存在什么与生俱来的固有关系(译注:这里意指如果以带有base-derived关系的B D两类型分别具现化某个template,产生出来的两个具现体并不带有base-derived关系),所以编译器视smartPtr 和 SmartPtr 为完全不同的 类型,它们之间的关系并不比 vector 和 widget更密切。为了获得我们希望获得的 SmartPtr classes 之间的转换能力,我们必须将它们明确地编写出来。
可尝试模板构造函数
template<typename T>
class SmartPtr {
public:template<typename U>SmartPtr(const SmartPtr<U>& other); //模板成员函数,为了生成拷贝构造函数
};
之所以没有加 explicit 声明,是为了能像派生类转换为基类指针那样隐式转换。
以上代码的意思是,对任何类型T和任何类型U,这里可以根据 smartPtr 生成一个 SmartPtr ——因为 SmartPtr 有个构造函数接受一个 SmartPtr 参数。这一类构造函数根据对象U创建对象T(例如根据 SmartPtr创建一个SmartPtr),而U和T的类型是同一个 template 的不同具现体,有时我们称之为泛化(generalized) copy构造函数。
如果 SmartPtr 提供一个get成员函数,返回智能指针对象所持有的原始指针的副本,那么:
template<typename T>
class SmartPtr {
public:template<typename U>SmartPtr(const SmartPtr<U>& other):heldPtr(other.get()) {}; //初始化 heldPtrT* get() const { return heldPtr; }
private:T* heldPtr; //持有的内置指针
};
我使用成员初值列(member initialization list)来初始化 smartPtr之内类型为T的成员变量,并以类型为U的指针(由SmartPtr持有)作为初值。这个行为只有当“存在某个隐式转换可将一个U指针转为一个指针”时才能通过编译。最终效益是SmartPtr现在有了一个泛化 copy构造函数,这个构造函数只在其所获得的实参隶属适当(兼容)类型时才通过编译。
member function templates(成员函数模板)的效用不限于构造函数,它们常扮演的另一个角色是支持赋值操作。
template<class T>
class shared_ptr {
public:shared_ptr(shared_ptr const& p); //拷贝构造函数template<class Y>explicit shared_ptr(Y* p); //构造函数兼容内置指针template<class Y>shared_ptr(shared_ptr<Y> const& r); //兼容share_ptr; 泛化拷贝构造函数template<class Y>explicit shared_ptr(weak_ptr<Y> const& r); //兼容weak_ptr;template<class Y>shared_ptr(auto_ptr<Y> const& r); //兼容auto_ptr;shared_ptr& operator=(shared_ptr const& r); //拷贝赋值template<class Y>shared_ptr& operator=(shared_ptr<Y> const& r); //泛化拷贝赋值template<class Y>shared_ptr& operator=(auto_ptr<Y> & r);//赋值auto_ptr时,他已经改变了,所以不必加const
};
上述所有构造函数都是explicit,惟有“泛化 copy构造函数”除外。那意味从某个shared _ptr类型隐式转换至另-一个shared ptr类型是被允许的,但从某个内置指针或从其他智能指针类型进行隐式转换则不被认可(如果是显式转换如cast强制转型动作倒是可以)。
member templates并不改变语言规则,而语言规则说,如果程序需要一个copy构造函数,你却没有声明它,编译器会为你暗自生成一个。在class内声明泛化 copy构造函数(是个member template)并不会阻止编译器生成它们自己的 copy构造函数(一个non-template)(尽管当U和T类型相同时,泛化拷贝构造函数会具现化为一个正常的拷贝构造函数),所以如果你想要控制copy构造的方方面面,你必须同时声明泛化 copy构造函数和“正常的”copy构造函数。相同规则也适用于赋值(assignment)操作。如上例,同时有拷贝构造函数和泛化拷贝构造函数。
总结
- 请使用 member function templates(成员函数模板)生成“可接受所有兼容类型”的函数。
- 如果你声明 member templates 用于“泛化 copy构造”或“泛化 assignment操作”,你还是需要声明正常的copy构造函数和 copy assignment操作符。
46 需要类型转换时请为模板定义非成员函数
将条款24讨论的 Rational 进行模板化
template<typename T>
class Rational {
public:Rational(const T& numerator = 0, const T& denominator = 1) {m_numerator = numerator;m_denominator = denominator;}const T numerator() const {return this->m_numerator;}const T denominator() const {return this->m_denominator;}
private:T m_numerator;T m_denominator;
};template<typename T>
const Rational<T> operator*(const Rational<T>& lhs, const Rational<T>& rhs)
{std::cout << "global!\n";return Rational<T>(lhs.numerator() * rhs.numerator(), lhs.denominator() * rhs.denominator());
}Rational<int> oneHalf(1, 2);
Rational<int> result2 = oneHalf * 2; //编译报错 错误 C2676 二进制“*”:“Rational<int>”不定义该运算符或到预定义运算符可接收的类型的转换
在 template实参推导过程中从不将隐式类型转换函数纳入考虑。这样的转换在函数调用过程中的确被使用,但在能够调用一个函数之前,首先必须知道那个函数存在。而为了知道它,必须先为相关的 function template 推导出参数类型(然后才可将适当的函数具现化出来)。然而template实参推导过程中并不考虑采纳“通过构造函数而发生的”隐式类型转换。
我们可以缓和编译器在template实参推导方面受到的挑战: template class 内的 friend 声明式可以指涉某个特定函数。那意味classRational 可以声明 operator* 是它的一个 friend 函数。Class templates 并不倚赖 template 实参推导(后者只施行于function templates身上),所以编译器总是能够在class Rational具现化时得知 T。因此,令 Rational class 声明适当的operator* 为其 friend 函数,可简化整个问题:
template<typename T>
class Rational {
public:friend const Rational operator*(const Rational& lhs, const Rational& rhs) {std::cout << "friend!\n";return Rational(lhs.numerator() * rhs.numerator(), lhs.denominator() * rhs.denominator());}
};
现在对 operator* 的混合式调用可以通过编译了,因为当对象 oneHalf 被声明为一个 Rational,class Rational 于是被具现化出来,而作为过程的一部分,friend 函数 operator*(接受Rational参数)也就被自动声明出来。后者身为一个函数而非函数模板( function template),因此编译器可在调用它时使用隐式转换函数(例如Rational的 non-explicit构造函数),而这便是混合式调用之所以成功的原因。
在一个class template内,template名称可被用来作为“template和其参数”的简略表达方式,所以在 Rational内我们可以只写 Rational而不必写Rational。如下写法也正确
friend const Rational<T> operator*(const Rational<T>& lhs, const Rational<T>& rhs) {std::cout << "friend!\n";return Rational<T>(lhs.numerator() * rhs.numerator(), lhs.denominator() * rhs.denominator());
}
如果嫌弃友元函数写成了内敛方式,可以在友元内调用全局函数
测试
最初看这段的时候没看懂,是因为没有具现化 int 类型的模板函数的原因吗,于是注释掉友元函数,加入全局特化函数
template<typename T>
const Rational<T> operator*(const Rational<T>& lhs, const Rational<T>& rhs)
{std::cout << "global!\n";return Rational<T>(lhs.numerator() * rhs.numerator(), lhs.denominator() * rhs.denominator());
}template<>
const Rational<int> operator*(const Rational<int>& lhs, const Rational<int>& rhs)
{std::cout << "global special!\n";return Rational<int>(lhs.numerator() * rhs.numerator(), lhs.denominator() * rhs.denominator());
}
Rational<int> result2 = oneHalf * 2; 编译依旧报错,
当然Rational<int> result1 = oneHalf * oneHalf;就正常执行特化版本的全局函数。
如果定义另外一个普通的全局函数就可以编译通过了
const Rational<int> operator*(const Rational<int>& lhs, const Rational<int>& rhs)
{std::cout << "global no template!\n";return Rational<int>(lhs.numerator() * rhs.numerator(), lhs.denominator() * rhs.denominator());
}
这时Rational<int> result2 = oneHalf * 2; 和Rational<int> result1 = oneHalf * oneHalf;都调用的这个普通函数。
如果此时取消注释友元函数则会报错:错误 C2084 函数“const Rational<int> Rational<int>::operator *(const Rational<int> &,const Rational<int> &)”已有主体
那么就是说,前面的友元函数就相当于这个全局函数,是普通函数而不是模板函数,所以查找规则中,会将参数进行隐式转换。
但是显然,友元函数的写法支持多种类型,更像是模板函数,支持以下应用,而全局普通函数想要做到这点,还得重新定义一个函数。
Rational<float> oneHalff(1.1, 2.1);
Rational<float> resultf = oneHalff * 2.1;
完整的测试如下:
#include <iostream>
template<typename T>
class Rational {
public:Rational(const T& numerator = 0, const T& denominator = 1) {m_numerator = numerator;m_denominator = denominator;}const T numerator() const {return this->m_numerator;}const T denominator() const {return this->m_denominator;}//friend const Rational<T> operator*(const Rational<T>& lhs, const Rational<T>& rhs) {// std::cout << "friend!\n";// return Rational<T>(lhs.numerator() * rhs.numerator(), lhs.denominator() * rhs.denominator());//}friend const Rational operator*(const Rational& lhs, const Rational& rhs) {std::cout << "friend!\n";return Rational(lhs.numerator() * rhs.numerator(), lhs.denominator() * rhs.denominator());}
private:T m_numerator;T m_denominator;
};template<typename T>
const Rational<T> operator*(const Rational<T>& lhs, const Rational<T>& rhs)
{std::cout << "global!\n";return Rational<T>(lhs.numerator() * rhs.numerator(), lhs.denominator() * rhs.denominator());
}template<>
const Rational<int> operator*(const Rational<int>& lhs, const Rational<int>& rhs)
{std::cout << "global special!\n";return Rational<int>(lhs.numerator() * rhs.numerator(), lhs.denominator() * rhs.denominator());
}//const Rational<int> operator*(const Rational<int>& lhs, const Rational<int>& rhs)
//{
// std::cout << "global no template!\n";
// return Rational<int>(lhs.numerator() * rhs.numerator(), lhs.denominator() * rhs.denominator());
//}int main()
{Rational<int> oneHalf(1, 2);Rational<int> oneone(2);Rational<int> result1 = oneHalf * oneHalf;Rational<int> result2 = oneHalf * 2;Rational<float> oneHalff(1.1, 2.1);Rational<float> resultf = oneHalff * 2.1;std::cout << "---------------\n";
}
总结
- 当我们编写一个 class template,而它所提供的与此 template相关的函数支持所有参数的隐式类型转换时,请将那些函数定义为class template内部的friend函数。
47 请使用 traits classes 表现类型信息
初读感觉这一节主要学个思想。
目标实现 将某个迭代器移动给定距离的函数,大致如下:
template<typename IterT,typename DistT>
void advance(IterT& iter, DistT d); //如果d < 0 则向后移动
迭代器分类
Input迭代器:只能向前移动,一次一步,客户只可读取(不能涂写)它们所指的东西,而且只能读取一次。它们模仿指向输入文件的阅读指针(read pointer) ;C++程序库中的istream_iterators是这一分类的代表。
Output迭代器:它们只向前移动,一次一步,客户只可涂写它们所指的东西,而且只能涂写一次。它们模仿指向输出文件的涂写指针(write pointer) ; ostream_iterators是这一分类的代表。
由于这两类都只能向前移动,而且只能读或写其所指物最多一次,所以它们只适合“一次性操作算法”( one-passalgorithms)。
forward迭代器:这种迭代器可以做前述两种分类所能做的每一件事,而且可以读或写其所指物一次以上。这使得它们可施行于多次性操作算法(multi-pass algorithms)。STL并未提供单向linked list,但某些程序库有(通常名为slist),而指入这种容器的迭代器就是属于forward迭代器。
Bidirectional迭代器:它除了可以向前移动,还可以向后移动。STL的list迭代器就属于这一分类,set,multiset,map和multimap 的迭代器也都是这一分类。
random access迭代器:它可以执行“迭代器算术”,也就是它可以在常量时间内向前或向后跳跃任意距离。这样的算术很类似指针算术,那并不令人惊讶,因为random access迭代器正是以内置(原始)指针为榜样,而内置指针也可被当做random access迭代器使用。vector, deque和 string提供的迭代器都是这一分类。
c++标准库对于这五个分类提供了专属的卷标(tag struct)加以确认
struct input_iterator_tag{};
struct output_iterator_tag{};
struct forward_iterator_tag:public input_iterator_tag{};
struct bidirectional_iterator_tag:public forward_iterator_tag{};
struct random_access_iterator_tag:public bidirectional_iterator_tag{};
这些 structs 之间的继承关系是有效的 is-a 关系(见条款32):是的,所有 forward 迭代器都是 input 迭代器,依此类推。很快我们会看到这个继承关系的效力。
traits
Traits并不是C+关键字或一个预先定义好的构件;它们是一种技术,也是一个C++程序员共同遵守的协议。这个技术的要求之一是,它对内置(built-in)类型和用户自定义(user-defined)类型的表现必须一样好。举个例子,如果上述 advance 收到的实参是一个指针(例如const char*)和一个int,上述advance仍然必须有效运作,那意味traits技术必须也能够施行于内置类型如指针身上。
“traits必须能够施行于内置类型”意味“类型内的嵌套信息( nestinginformation)”这种东西出局了,因为我们无法将信息嵌套于原始指针内。因此类型的 traits信息必须位于类型自身之外。标准技术是把它放进一个template 及其一或多个特化版本中。
iterator_traits 的运作方式是,针对每一个类型 IterT,在 struct iterator_traits 内一定声明某个 typedef 名为 iterator_category。这个 typedef 用来确认 IterT 的迭代器分类。
首先它要求每一个“用户自定义的迭代器类型”必须嵌套一个 typedef,名为 iterator_category,用来确认适当的卷标结构(tag struct)。例如deque的迭代器可随机访问,所以一个针对deque迭代器而设计的class看起来会是这样子:
template<...>
class deque{
public:class iterator{public:typedef random_access_iterator_tag iterator_category;};
};template<...>
class list{
public:class iterator{public:typedef bidirectional_iterator_tag iterator_category;};
};
advance实现
运行时
我们期望实现的方式:
template<typename IterT,typename DistT>
void advance(IterT& iter, DistT d)
{if(iter is a random access iterator) //针对random access 迭代器使用迭代器算术运算{iter +=d; }else //针对其他迭代器分类,反复调用 ++ 或者 --{if(d>=0){while(d--)++iter;}else{while(d++)--iter;}}
}
这种实现方式,需要确定迭代器类型。
根据迭代器中存储的类型,可以编译器确定迭代器类型,同时考虑兼容一般指针,iterator_traits 的实现如下:
template<typename IterT>
struct iterator_traints{typedef typename IterT::iterator_category iterator_category;
};template<typename IterT>
struct iterator_traints<IterT*>{ //template 偏特化 针对内置指针typedef random_access_iterator_category iterator_category; //指针的行为与random access 迭代器类似
};
一个traits 类的实现步骤:
- 确认若干你希望将来可取得的类型相关信息。例如对迭代器而言,我们希望将来可取得其分类( category) 。
- 为该信息选择一个名称(例如 iterator_category) 。
- 提供一个template和一组特化版本(例如 iterator_traits),内含你希望支持的类型相关信息。
现在有了 iterator_traits(实际上是 std: :iterator_traits,因为它是C++标准程序库的一部分),我们可以对advance实践先前的伪码(pseudocode):
template<typename IterT,typename DistT>
void advance(IterT& iter, DistT d)
{if(typeid(typename std::iterator_traits<IterT>::iterator_category)==typeid(std::random_access_iterator_tag))...
}
这里,只有在运行到 if 语句时才会进行检测,可能会浪费时间。
编译时
实现编译器确定类型,可以通过重载函数确认。
当你重载某个函数f,你必须详细叙述各个重载件的参数类型。当你调用f,编译器便根据传来的实参选择最适当的重载件。编译器的态度是“如果这个重载件最匹配传递过来的实参,就调用这个f;如果那个重载件最匹配,就调用那个f;如果第三个f最匹配,就调用第三个f!”依此类推。看到了吗,这正是一个针对类型而发生的“编译期条件句”。
//用于实现 random access迭代器
template<typename IterT,typename DistT>
void doadvance(IterT& iter, DistT d,std::random_access_iterator_tag)
{iter+=d;
}
//用于实现 bidirectional 迭代器
template<typename IterT,typename DistT>
void doadvance(IterT& iter, DistT d,std::bidirectional_iterator_tag)
{if(d>=0){while(d--)++iter;}else{while(d++)--iter;}
}
//用于实现 input 迭代器;由于forward是input的子类,所以也可以处理forward迭代器
template<typename IterT,typename DistT>
void doadvance(IterT& iter, DistT d,std::input_iterator_tag)
{if(d<0){throw std::out_of_range("negative distance");}while(d++)--iter;
}template<typename IterT,typename DistT>
void doadvance(IterT& iter, DistT d)
{doadvance(iter,d,typename std::iterator_traits<IterT>::iterator_category());//调用 doadvance 的重载版本 对iter的迭代器分类而言 一定是适当的
}
总结过程:
- 建立一组重载函数(身份像劳工)或函数模板(例如 doAdvance),彼此间的差异只在于各自的 traits 参数。令每个函数实现与其接受的 traits 信息相匹配。
- 建立一个控制函数(身份像工头)或函数模板(例如advance),它调用上述那些“劳工函数”并传递 traits class 所提供的信息。
总结
- Traits classes 使得“类型相关信息”在编译期可用。它们以 templates 和" templates特化”完成实现。
- 整合重载技术( overloading)后,traits classes有可能在编译期对类型执行if…else测试。
48 认识template元编程
Template metaprogramming (TMP,模板元编程)是编写template-based C++程序并执行于编译期的过程。花一分钟想想这个:所谓template metaprogram(模板元程序)是以C++写成、执行于C++编译器内的程序。一旦TMP程序结束执行,其输出,也就是从templates具现出来的若干C++源码,便会一如往常地被编译。
由于template metaprograms 执行于C++编译期,因此可将工作从运行期转移到编译期。这导致的一个结果是,某些错误原本通常在运行期才能侦测到,现在可在编译期找出来。另一个结果是,使用TMP的C++程序可能在每一方面都更高效:较小的可执行文件、较短的运行期、较少的内存需求(这不会生成更多的代码占用更多代码页吗?)。然而将工作从运行期移转至编译期的另一个结果是,编译时间变长了。是的,程序如果使用TMP,其编译时间可能远长于不使用TMP的对应版本。
template<typename IterT,typename DistT>
void advance(IterT& iter, DistT d)
{if(typeid(typename std::iterator_traits<IterT>::iterator_category)==typeid(std::random_access_iterator_tag)){iter+=d; }else {if(d>=0){while(d--)++iter;}else{while(d++)--iter;}}
}
没懂呢,原文说iter+=d;这里会报错,当第一个实参(形参IterT)是std::list<int>::iterator iter类型,但是list的iterator_category类型是bidirectional_iterator_tag ,不应该判断为true呢。
循环
TMP并没有真正的循环构件,所以循环效果系藉由递归(recursion)完成。TMP主要是个“函数式语言”(functional language),TMP的递归甚至不是正常种类,因为TMP循环并不涉及递归函数调用,而是涉及“递归模板具现化”(recursive template instantiation)。
查看如下阶乘的实现代码:
template<unsigned n>
struct Factorial{enum{value = n* Factorial<n-1>::value};
};template<>
struct Factorial<0>{enum{value = 1};
};int main()
{std::cout << Factorial<5>::value << std::endl; //120std::cout << Factorial<10>::value << std::endl;//3628800
}
循环发生在 template 具现体 Factorial 内部指涉另一个 template 具现体 Factorial 之时。和所有良好递归一样,我们需要一个特殊情况造成递归结束。这里的特殊情况是 template 特化体 Factorial<0>。
每个 Factorial template 具现体都是一个struct,每个 struct 都使用 enum hack(见条款2)声明一个名为 value 的 TMP 变量,value用来保存当前计算所得的阶乘值。如果 TMP 拥有真正的循环构件,value 应该在每次循环内获得更新。但由于TMP系以“递归模板具现化”(recursive template instantiation)取代循环,每个具现体有自己的一份value,而每个value有其循环内的适当值。
所以会不会生成了n个类型呢?
模板元编程的应用场景
- 确保量度单位正确
- 优化矩阵计算,可以避免计算时生成的中间临时变量,减少内存消耗,提升运算速度
- 可以生成客户定制的设计模式( custom design pattern)实现品。设计模式如Strategy(见条款35),observor,Visitor等等都可以多种方式实现出来。运用所谓policy-based design 的 TMP-based 技术,有可能产生一些 templates 用来表述独立的设计选项(所谓"policies"),然后可以任意结合它们,导致模式实现品带着客户定制的行为。这项技术已被用来让若干templates实现出智能指针的行为政策(behavioral policies),用以在编译期间生成数以百计不同的智能指针类型。这项技术已经超越编程工艺领域如设计模式和智能指针,更广义地成为generative programming(殖生式编程)的一个基础。(没理解什么意思,直接贴这了)
好像没有调试TMP的工具目前。
总结
- Template metaprogramming ( TMP,模板元编程)可将工作由 运行期 移往 编译期,因而得以实现早期错误侦测和更高的执行效率。
- TMP可被用来生成“基于政策选择组合”( based on combinations of policychoices)的客户定制代码,也可用来避免生成对某些特殊类型并不适合的代码。
八 定制 new 和 delete
49 了解 new-handler 的行为
当 new 操作无法满足某一内存分配需求时,它会抛出异常。以前它会返回一个null 指针,某些旧式编译器目前也还那么做。
当 new 操作抛出异常以反映一个未获满足的内存需求之前,它会先调一个客户指定的错误处理函数,一个所谓的 new-handler。为了指定这个“用以处理内存不足”的函数,客户必须调用set_new_handler,那是声明于的一个个标准程序库函数:
namespace std{typedef void(*new_handler)();new_handler set_new_handler(new_handler p) throw();
}
new_handler 是个 typedef,定义出一个指针指向函数,该函数没有参数也不返回任何东西。set_new_handler则是“获得一个new_handler 并返回一个 new_handler ”的函数。set_new_handler声明式尾端的“throw()"是一份异常明细,表示该函数不抛出任何异常。
set_new_handler的参数是个指针,指向 new 操作无法分配足够内存时该被调用的函数。其返回值也是个指针,指向set_new_handler被调用前正在执行(但马上就要被替换)的那个 new-handler 函数(也就是返回旧的异常处理函数) 。
void outOfMem()
{std::cerr << "unable to satisfy request for memory" << std::endl;std::abort();
}
int main()
{std::set_new_handler(outOfMem);int* pBigDataArray = new int[10000000L];
}
如果operator new无法为100,000,000个整数分配足够空间,outofMem会被调用,于是程序在发出一个信息之后夭折( abort).
设计良好的 new_handler
- 让更多内存可被使用。这便造成 new 操作内的下一次内存分配动作可能成功。实现此策略的一个做法是,程序一开始执行就分配一大块内存,而后当 new-handler 第一次被调用,将它们释还给程序使用。
- 安装另一个new-handler。如果目前这个 new-handler 无法取得更多可用内存,或许它知道另外哪个 new-handler 有此能力。果真如此,目前这个 new-handler 就可以安装另外那个 new-handler 以替换自己(只要调用set_new_handler)。下次当operator new 调用 new-handler ,调用的将是最新安装的那个。(这个旋律的变奏之一是让new-handler修改自己的行为,于是当它下次被调用,就会做某些不同的事。为达此目的,做法之一是令 new-handler 修改“会影响 new-handler 行为”的static数据、namespace 数据或 global 数据。)
- 卸除 new-handler,也就是将 null 指针传给 set_new_handler。一旦没有安装任何 new-handler,operator new会在内存分配不成功时抛出异常。
- 抛出 bad_alloc(或派生自bad_alloc)的异常。这样的异常不会被 operator new 捕捉,因此会被传播到内存索求处。
- 不返回,通常调田abort战exit。
每个类自己单独的 new_handler
void outOfMem()
{std::cerr << "unable to satisfy request for memory" << std::endl;std::abort();
}class NewHandlerHolder {
public:explicit NewHandlerHolder(std::new_handler nh):handler(nh){} //取得目前的new_handler,释放它~NewHandlerHolder(){std::set_new_handler(handler);}
private:std::new_handler handler; //记录NewHandlerHolder(const NewHandlerHolder&); //阻止拷贝构造NewHandlerHolder& operator=(const NewHandlerHolder&);
};class Widget {
public:static std::new_handler set_new_handler(std::new_handler p) throw();//自定义类成员函数set_new_handlerstatic void* operator new(std::size_t size) throw(std::bad_alloc);//自定义类成员操作符函数 new
private:static std::new_handler currentHandler;
};std::new_handler Widget::currentHandler=0;//初始化std::new_handler Widget::set_new_handler(std::new_handler p) throw()
{std::new_handler oldHandler = currentHandler;currentHandler = p;return oldHandler;
}void* Widget::operator new(std::size_t size) throw(std::bad_alloc)
{NewHandlerHolder h(std::set_new_handler(currentHandler));//设置使用Widget的new_handler,同时将之前的new_handler存储到NewHandlerHolderreturn ::operator new(size);//分配内存;同时恢复设置NewHandlerHolder中存储的之前的new_handler
}
//调用标准set_new_handler,告知 widget的错误处理函数。这会将widget的new-handler安装为global new-handler。
//调用global operator new,进行内存分配。
//如果分配失败,global operator new 会调用 widge 的 new-handler,因为那个函数才刚被安装为global new-handler。
//如果global operator new 最终无法分配足够内存,会抛出一个bad_alloc异常。
//在此情况下 widget 的operator new 必须恢复原本的 globalnew-handler,然后再传播该异常。
//为确保原本的 new-handler 总是能够被重新安装回去,widget将global new-handler 视为资源并遵守条款13的忠告,运用资源管理对象(resource-managing objects)(NewHandlerHolder )防止资源泄漏。//如果 global operator new 能够分配足够一个 widget 对象所用的内存,widget的operator new会返回一个指针,指向分配所得。
//NewHandlerHolder 析构函数会管理global new-handler,它会自动将 widget's operator new 被调用前的那个globalnew-handler恢复回来。int main()
{Widget::set_new_handler(outOfMem); //设定outOfMem为Widget的new_handler,异常处理函数Widget* pw1 = new Widget; //此时如果 new 失败,则会调用 outOfMemstd::string* ps = new std::string; //如果 new 失败,调用全局的 new_handlerWidget::set_new_handler(0); //设定Widget的new_handler为nullWidget* pw2 = new Widget; //如果内存分配失败,直接抛出异常(因为没有异常处理函数)return 0;
}
模板化单独的 new_handler
template<typename T>
class NewHandlerSupport {
public:static std::new_handler set_new_handler(std::new_handler p) throw();static void* operator new(std::size_t size) throw(std::bad_alloc);
private:static std::new_handler currentHandler;
};template<typename T>
std::new_handler NewHandlerSupport<T>::set_new_handler(std::new_handler p) throw()
{std::new_handler oldHandler = currentHandler;currentHandler = p;return oldHandler;
}template<typename T>
void* NewHandlerSupport<T>::operator new(std::size_t size) throw(std::bad_alloc)
{NewHandlerHolder h(std::set_new_handler(currentHandler));return ::operator new(size);
}template<typename T>
std::new_handler NewHandlerSupport<T>::currentHandler = 0;//初始化
使用以上模板类作为基类
class Widget2 :public NewHandlerSupport<Widget2>
{...
};
NewHandlerSupport template从未使用其类型参数T。实际上T的确不需被使用。我们只是希望,继承自 NewHandlerSupport 的每一个类,拥有实体互异的 NewHandlersupport 复件(更明确地说是其 static 成员变量 currentHandler )。类型参数T只是用来区分不同的派生类。Template 机制会自动为每一个T ( NewHandlerSupport 赖以具现化的根据)生成一份 currentHandler。
widget 继承自一个模板化的( templatized) base class,而后者又以 Widget 作为类型参数,它被证明是一个有用的技术,因此甚至拥有自己的名称:“怪异的循环模板模式”(curiously recurring template pattern; CRTP)。
nothrow new
直至1993年,C++都还要求 operator new 必须在无法分配足够内存时返回 null。新一代的 operator new 则应该抛出 bad_alloc 异常,但很多C++程序是在编译器开始支持新修规范前写出来的。C++标准委员会不想抛弃那些“侦测null”的族群,于是提供另一形式的 operator new,负责供应传统的“分配失败便返回null”行为。这个形式被称为"nothrow"形式——某种程度上是因为他们在 new的使用场合用了nothrow对象(定义于头文件) :
class Widget{};
Widget* pw1 = new Widget; //如果分配失败,抛出 bad_alloc
if(pw1==0)... //判断将不会按照写程序时的想法进行,测试失败
Widget* pw2 = new (std::nothorw) Widget; //如果分配失败,返回0
if(pw1==0)... //测试可能成功
Nothrow new 对异常的强制保证性并不高。nothrow 版的 operator new 被调用,用以分配足够内存给 widget 对象。如果分配失败便返回 null 指针。如果分配成功,接下来 widget 构造函数会被调用, widget 构造函数可以做它想做的任何事。它有可能又 new 一些内存,而没人可以强迫它再次使用nothrow new。因此虽然"new (std: ;nothrow) widget”调用的 operator new 并不抛掷异常,但 widget构造函数却可能会。如果它真那么做,该异常会一如往常地传播。结论就是:使用 nothrow new 只能保证 operator new 不抛掷异常,不保证像“new (std: :nothrow) widget"这样的表达式绝不导致异常。因此你其实没有运用 nothrow new 的需要。
总结
- set_new_handler 允许客户指定一个函数,在内存分配无法获得满足时被调用。
- Nothrow new 是一个颇为局限的工具,因为它只适用于内存分配;后继的构造函数调用还是可能抛出异常。
50 了解 new 和 delete 的合理替换时机
也就是考虑替换(封装一层) operator new 和 operator delete 的时刻(好处)
用来检测运行上的错误
错误情况:
- 如果将“new所得内存”delete 掉却不幸失败,会导致内存泄漏(memory leaks)
- 如果在“new所得内存”身上多次delete则会导致不确定行为。
- 如果operator new持有一串动态分配所得地址,而 operator delete 将地址从中移走,倒是很容易检测出上述错误用法。(new []分配内存,但是delete其中的某一部分的意思吗?)
各式各样的编程错误可能导致数据“overruns"(写入点在分配区块尾端之后)或“underruns"(写入点在分配区块起点之前)。
(内存指针指向了错误的地方,没有在分配的内存内写入数据?)
如果我们自行定义一个operator news,便可超额分配内存,以额外空间(位于客户所得区块之前或后)放置特定的 byte patterns(即签名,signatures)。
operator deletes便得以检查上述签名是否原封不动,若否就表示在分配区的某个生命时间点发生了overrun或underrun,这时候operator delete可以志记 (log)那个事实以及那个惹是生非的指针。
(就是我们自己重写new 和 delete 就可以控制创建的内存,在地址的前后做上特殊的标记(写入特殊字符),那写入时怎么判断呢?)
强化效能
编译器所带的 operator new 和 operator delete 主要用于一般目的,它们必须考虑破碎问题(fragmentation),这最终会导致程序无法满足大区块内存要求,即使彼时有总量足够但分散为许多小区块的自由内存。
如果你对你的程序的动态内存运用型态有深刻的了解,通常可以发现,定制版的operator new和 operatordelete性能胜过缺省版本。说到胜过,我的意思是它们比较快,有时甚至快很多,而且它们需要的内存比较少,最高可省50%。对某些(虽然不是所有〉应用程序而言,将旧有的(编译器自带的)new和 delete替换为定制版本,是获得重大效能提升的办法之一。
收集与统计
分配区块的大小分布如何?
寿命分布如何?
它们倾向于以FIFO(先进先出)次序或LIFO(后进先出)次序或随机次序来分配和归还?
它们的运用型态是否随时间改变,也就是说你的软件在不同的执行阶段有不同的分配/归还形态吗?
任何时刻所使用的最大动态分配量(高水位)是多少?
自行定义 operator new 和 operator delete 使我们得以轻松收集到这些信息。
定制版 new delete
static const int signature = 0xDEADBEEF;
typedef unsigned char Byte;void* operator new(std::size_t size) throw(std::bad_alloc)
{using namespace std;size_t realSize = size + 2 * sizeof(int);void* pMem = malloc(realSize);if (!pMem){throw bad_alloc();}//将 signature 写入内存的最前段落和最后段落*(static_cast<int*>(pMem)) = signature;*(reinterpret_cast<int*>(static_cast<Byte*>(pMem)+realSize-sizeof(int))) = signature;//返回指针,指向恰位于第一个signature之后的内存位置return static_cast<Byte*>(pMem) + sizeof(int);
}
*(reinterpret_cast<int*>(static_cast<Byte*>(pMem)+realSize-sizeof(int))) = signature;由于创建内存大小时一般是指创建的字节数,也就是 size 参数的含义,所以先转换为指向 byte 的指针,将指针移动到指向末尾 将要填入 signature的位置,然后转换指针为 int*,再写入signature。
上述实现中有很多细节没有考虑:
- 没有反复调用 new-handling 函数,就是前面条款讨论过的函数
- 没有考虑齐位问题
许多计算机体系结构(computer architectures)要求特定的类型必须放在特定的内存地址上。例如它可能会要求指针的地址必须是4倍数〈four-byte aligned)或doubles 的地址必须是8倍数(eight-byte aligned)。如果没有奉行这个约束条件,可能导致运行期硬件异常。有些体系宣称如果齐位条件获得满足,便提供较佳效率。例如Intel x86体系结构上的 doubles可被对齐于任何 byte边界,但如果它是8-byte齐位,其访问速度会快许多。
在我们目前这个主题中,齐位( alignment)意义重大,因为C++要求所有 operator news 返回的指针都有适当的对齐(取决于数据类型)。malloc 就是在这样的要求下工作,所以令 operator new 返回一个得自 malloc 的指针是安全的。然而上述 operator new 中我并未返回一个得自 malloc 的指针,而是返回一个得自 malloc 且偏移一个 int 大小的指针。没人能够保证它的安全! 如果客户端调用operator new 企图获取足够给一个 double 所用的内存(或如果我们写个operator new[],元素类型是 doubles ),而我们在一部“ints为 4 bytes且 doubles 必须 8-byte 齐位”的机器上跑,我们可能会获得一个未有适当齐位的指针。那可能会造成程序崩溃或执行速度变慢。
也有很多商业的编译器实现了可调试、增加了日志的new 及 delete,但是可能需要收费;而一些开源的库,如 boost 也有实现,但可能或多或少存在一起未考虑的问题,如齐位、线程安全等,但是tr1就有对齐位的考虑。
增加分配和归还的速度
泛用型分配器往往(虽然并不总是)比定制型分配器慢,特别是当定制型分配器专门针对某特定类型对象而设计时。Class专属分配器是“区块尺寸固定”的分配器实例,例如 Boost 提供的 Pool 程序库便是。如果你的程序是个单线程程序,但你的编译器所带的内存管理器具备线程安全,你或许可以写个不具线程安全的分配器而大幅改善速度。当然,在获得“operator new 和 operator delete 有加快程序速度的价值”这个结论之前,首先请分析你的程序,确认程序瓶颈的确发生在那些内存函数身上。
降低缺省内存管理器带来的空间额外开销
泛用型内存管理器往往(虽然并非总是)不只比定制型慢,它们往往还使用更多内存,那是因为它们常常在每一个分配区块身上招引某些额外开销。针对小型对象而开发的分配器(例如Boost 的 Pool程序库)本质上消除了这样的额外开销。
弥补缺省分配器中的非最佳齐位(suboptimal alignment)
如先前所说,在x86体系结构上 doubles 的访问最是快速——如果它们都是8-byte齐位。但是编译器自带的 operator news 并不保证对动态分配而得的 doubles 采取 8-byte 齐位。这种情况下,将缺省的operator new 替换为一个8-byte 齐位保证版,可导致程序效率大幅提升。
将相关对象成簇集中
如果你知道特定某个数据结构往往被一起使用,而你又希望在处理这些数据时将“内存页错误”(page faults)的频率降至最低,那么为此数据结构创建另一个heap就有意义,这么一来它们就可以被成簇集中在尽可能少的内存页( pages) 上。new 和 delete 的“placement版本”(见条款52)有可能完成这样的集簇行为。
获得非传统的行为
有时候你会希望 operators new 和 delete 做编译器附带版没做的某些事情。例如你可能会希望分配和归还共享内存( shared memory)内的区块,但唯一能够管理该内存的只有CAPI 函数,那么写下一个定制版 new 和 delete(很可能是placement版本,见条款52),你便得以为CAPI 穿上一件C++外套。你也可以写一个自定的 operator delete,在其中将所有归还内存内容覆盖为0,藉此增加应用程序的数据安全性。
总结
- 有许多理由需要写个自定的new和 delete,包括改善效能、对 heap 运用错误进行调试、收集 heap使用信息。
51 编写 new 和 delete 时需要固守常规
前一章说明了哪些情况需要自己重写 new 和 delete,当时没说明重写需要遵守的,此章讨论需要遵守的规则。
operator new
返回值
实现一致性(与全局 new 保持一致) operator new 必得返回正确的值,内存不足时必得调用 new-handling 函数(见条款49),必须有对付零内存需求的准备,还需避免不慎掩盖正常形式的new ——虽然这比较偏近 class 的接口要求而非实现要求。
operator new 的返回值十分单纯。如果它有能力供应客户申请的内存,就返回一个指针指向那块内存。如果没有那个能力,就遵循条款49描述的规则,并抛出一个bad_alloc 异常。
调用 new-handling
只有当指向new-handling 函数的指针是null,operatornew才会抛出异常。
处理0内存需求
即使客户要求0 bytes,operator new也得返回一个合法指针。这种看似诡异的行为其实是为了简化语言其他部分。
如下伪代码实现:
void* operator new(std::size_t size) throw(std::bad_alloc)
{using namespace std;if(size==0){size = 1;//当用户需要0字节时,按照1个字节进行分配}while(true){//这里尝试分配 size bytesif(分配成功)return (一个指向分配得来内存的指针);//分配失败:找出当前的 new-handling 函数new_handler globalHandler = set_new_handler(0);//没有其他更好更好的获取 new-handling 函数方法set_new_handler(globalHandler);//这种方法多线程的话需要加锁if(globalHandler)(*globalHandler)();elsethrow std::bad_alloc();}
}
"while (true)”是个无穷循环。退出此循环的唯一办法是:
- 内存被成功分配
- new-handling 函数做了一件描述于条款49的事情:让更多内存可用、安装另-一个new-handler、卸除new-handler、抛出 bad_alloc异常(或其派生物)
- 承认失败而直接return。
对于new-handler必须做出其中某些事。如果不那么做,operator new内的while循环永远不会结束。
继承
写出定制型内存管理器的一个最常见理由是为针对某特定class的对象分配行为提供最优化,却不是为了该class 的任何派生类。也就是说,针对class x而设计的 operator new,其行为很典型地只为大小刚好为 sizeof(x) 的对象而设计。然而一旦被继承下去,有可能 base class 的 operator new 被调用用以分配 derived class对象。
可以如下处理
class Base{
public:static void* operator new(std::size_t size) throw(std::bad_alloc);
};
class Derived:public Base//假设 Derived 没有声明 operator new
{};
Derived* p = new Derived; //这里调用的是 Base::operator newvoid* Base::operator new(std::size_t size) throw(std::bad_alloc)
{if(size!=sizeof(Base)) //如果大小错误,就调用标准的operator new 进行处理return ::operator new(size);...
}
由于c++规定,所有非附属(独立)的对象必须是非0大小,所以这里没有检测申请内存大小为0 的情况。
new []
这个函数通常被称为"array new",因为很难想出如何发音"operator new[ ]"。
其需要考量的内容如下:
如果决定写个operator new[],唯一需要做的一件事就是分配一块未加工内存(raw memory),因为你无法对array之内迄今尚未存在的元素对象做任何事情。实际上你甚至无法计算这个array 将含多少个元素对象。
首先你不知道每个对象多大,毕竟base class 的operator new[]有可能经由继承被调用,将内存分配给“元素为derived class对象”的array使用,而你当然知道,derived class对象通常比其 base class对象大。因此,不能在Base::operator new[] 内假设 array 的每个元素对象的大小是sizeof(Base),这也就意味你不能假设 array 的元素对象个数是(bytes申请数) / sizeof(Base) 。
此外,传递给operator new[]的 size_t 参数,其值有可能比“将被填以对象”的内存数量更多,因为条款16说过,动态分配的 arrays 可能包含额外空间用来存放元素个数。
operator delete
需要做到的事就是 保证 删除 NULL 指针永远安全。
全局 operator delete 函数伪代码如下:
void operator delete(void* rawMemory) throw()
{if(rawMemeber == 0) return; //如果将删除的是个null指针,就什么也不做归还 rawMember 所指内存
}
成员函数版的delete
class Base{
public:static void* operator new(std::size_t size) throw(std::bad_alloc);static void operator delete(void* rawMemory,std::size_t size) throw();
};void Base::operator delete(void* rawMemory,std::size_t size) throw()
{if(rawMemory == 0) return; //检测null指针if(size != sizeof(Base)){//大小错误,使用标准版的 delete::operator delete(rawMemory);return;}归还 rawMember 所指内存return;
}
如果即将被删除的对象派生自某个 base class ,而 base class 欠缺 virtual 析构函数,那么C++传给operator delete的 size_t 数值可能不正确。此刻要提高警觉,如果 base classes 遗漏 virtual 析构函数,operator delete可能无法正确运作。(理解为,调用的是派生类的析构,所以传递的大小是派生类对象的大小)
总结
- operator new 应该内含一个无穷循环,并在其中尝试分配内存,如果它无法满足内存需求,就该调用 new-handler。它也应该有能力处理 0 bytes 申请。Class专属版本则还应该处理“比正确大小更大的(错误)申请”(派生类继承问题,调用全局的new)。
- operator delete应该在收到null 指针时不做任何事。Class专属版本则还应该处理“比正确大小更大的(错误〉申请”(派生类继承问题,调用全局的delete)。
52 写了 placement new 也要写 placement delete
如果 operator new 接受的参数除了一定会有的那个 size_t 之外还有其他,这便是个所谓的placement new。众多placement new 版本中特别有用的一个是“接受一个指针指向对象该被构造之处”,那样的 operator new 长相如下:
void* operator new(std::size_t,void* pMemory) throw();
这个版本的new已被纳入C++标准程序库,你只要 #include 就可以取用它。这个new的用途之一是负责在vector的未使用空间上创建对象。它同时也是最早的 placement new版本。实际上它正是这个函数的命名根据:一个特定位置上的 new。以上说明意味术语 placement new 有多重定义。当人们谈到 placementnew,大多数时候他们谈的是此一特定版本,也就是“唯一额外实参是个void* ”,少数时候才是指接受任意额外实参的 operator new(也就是说自己定义的有额外实参的 new 吧)。一般性术语"placement new”意味带任意额外参数的 new,因为另一个术语"placement delete”直接派生自它。类似于new的placement版本,operator delete如果接受额外参数,便称为 placement deletes。
情景
Widget* pw = new Widget;
以上过程调用了两个函数:分配内存的 operator new,Widget的默认构造函数。
假设其中第一个函数调用成功,第二个函数却抛出异常。既然那样,步骤一的内存分配所得必须取消并恢复旧观,否则会造成内存泄漏(memory leak)。在这个时候,客户没有能力归还内存,因为如果widget构造函数抛出异常,pw尚未被赋值,客户手上也就没有指针指向该被归还的内存。取消步骤一并恢复旧观的责任因此落到C++运行期系统身上。(此时pw不会是NULL吗,如果new失败的话;正常过程不应该是 先分配好大小是Widget的内存,并返回指针指向这块内存地址,然后执行构造函数,在地址上赋值吗,这种情况应该也可以正常调用delete吧)
运行期系统会调用步骤一所调用的 operator new 的相应 operator delete 版本,前提当然是它必须知道哪一个(因为可能有许多个) operator delete 该被调用。如果目前面对的是拥有正常签名式(signature)的 new和 delete,这并不是问题,因为正常的operator new(void* operator new(std::size_t) throw(std::bad_alloc))对应正常的 operator delete (void* operator delete(void* rawMemory, std::size_t) throw(),void* operator delete(void* rawMemory) throw())
因此,当你只使用正常形式的 new和 delete,运行期系统毫无问题可以找出那个“知道如何取消new所作所为并恢复旧观”的delete。然而当你开始声明非正常形式的operator new,也就是带有附加参数的operator new,“究竟哪一个delete伴随这个new”的查找就出现问题
示例
class Widget{
public:static void* operator new(std::size_t size,std::ostream& logStream) throw(std::bad_alloc);//非正常形式的newstatic void* operator delete(void* pMemory,std::size_t size) throw();//正常形式的delete
};Widget* pw = new (std::cerr)Widget;//调用 new 并传递 cerr 为 ostream 实参;在 Widget 构造函数中抛出异常时内存泄漏
如果内存分配成功,而 widget 构造函数抛出异常,运行期系统有责任取消 operator new 的分配并恢复旧观。然而运行期系统无法知道真正被调用的那个 operator new 如何运作,因此它无法取消分配并恢复旧观。取而代之的是,运行期系统寻找“参数个数和类型都与 operator new 相同"的某个 operator delete。如果找到,那就是它的调用对象,既然这里的operator new接受类型为ostreams的额外实参,所以对应的operator delete就应该是void* operator delete(void* pMemory,std::ostream& logStream) throw();
现在,既然 widget 没有声明placement 版本的 operator delete,所以运行期系统不知道如何取消并恢复原先对 placement new 的调用。于是什么也不做。本例之中如果 widget 构造函数抛出异常,不会有任何operator delete被调用(那当然不妙)。
规则:如果一个带额外参数的 operator new 没有“带相同额外参数”的对应版operator delete,那么当new的内存分配动作需要取消并恢复旧观时就没有任何 operator delete 会被调用。
因此,为了消弭稍早代码中的内存泄漏,widget 有必要声明一个placement delete,对应于那个有志记功能(logging)的placement new:
class Widget{
public:static void* operator new(std::size_t size,std::ostream& logStream) throw(std::bad_alloc);static void* operator delete(void* pMemory,std::size_t size) throw();static void* operator delete(void* pMemory,std::ostream& logStream) throw();
};Widget* pw = new (std::cerr)Widget;
delete pw;//以上不出现异常时,此处调用delete为正常的delete,而非placement delete
placement delete只有在“伴随placement new调用而触发的构造函数”出现异常时才会被调用。
如果要避免 placement new 相关的内存泄漏,我们必须同时提供一个正常的operator delete(用于构造期间无任何异常被抛出)和一个placement版本(用于构造期间有异常被抛出)。后者的额外参数必须和operator new一样。
覆盖问题
类成员的new会掩盖全局的new
class Base{
public:static void* operator new(std::size_t size,std::ostream& logStream) throw(std::bad_alloc);//整个new会掩盖正常的global new
};
Base* pb = new Base; //错误,正常形式的 new 被掩盖
Base* pb = new (std::cerr)Base; //正确,调用 Base 的 placement new
派生类中声明的new 会掩盖 基类 中的 new
class Derived:public Base{
public:static void* operator new(std::size_t size) throw(std::bad_alloc);//重新声明正常形式的new 会掩盖基类 new
};
Derived* pb = new Derived; //正确,调用 Derived的 placement new
Derived* pb = new (std::cerr)Derived; //错误,基类的 new 被掩盖
c++ 在全局中提供以下默认的 new
void* operator new(std::size_t size) throw(std::bad_alloc); //正常 的 new
void* operator new(std::size_t size,void*) throw(); //placement new
void* operator new(std::size_t size,const std::nothrow_t&) throw(); //nothrow new
由于自己声明的new会掩盖全局的new,所以需要确保在使用声明自定义new 外的其他位置,可以正常调用全局new
class StandardDeleteForms{
public:static void* operator new(std::size_t size) throw(std::bad_alloc){return ::operator new(size);}static void* operator delete(void* pMemory) throw(){::operator delete(pMemory);}//placement new/deletestatic void* operator new(std::size_t size,void* ptr) throw(std::bad_alloc){return ::operator new(size,ptr);}static void* operator delete(void* pMemory,void* ptr) throw(){::operator delete(pMemory,ptr);}//nothrow new/deletestatic void* operator new(std::size_t size,const std::nothrow_t& nt) throw(std::bad_alloc){return ::operator new(size,nt);}static void* operator delete(void* pMemory,const std::nothrow_t& nt) throw(){::operator delete(pMemory);}
}
扩充基类的new,可以调用基类的可以使用using
class Widget: public StandardDeleteForms{
public:using StandardDeleteForms::operator new;using StandardDeleteForms::operator delete;//使继承的形式可见static void* operator new(std::size_t size,std::ostream& logStream) throw(std::bad_alloc);//添加自定义的placement newstatic void* operator delete(void* pMemory,std::ostream& logStream) throw();//对应的的placement delete}
不是特别明白,意思就是调用new时,不会覆盖基类的new了,相当于函数的重载了?
总结
- 当你写一个 placement operator new,请确定也写出了对应的placement operator delete。如果没有这样做,你的程序可能会发生隐微而时断时续的内存泄漏。
- 当你声明 placement new和 placement delete,请确定不要无意识(非故意)地遮掩了它们的正常版本。
九 杂项讨论
53 不要轻忽编译器的警告
如:
class B{
public:virtual void f() const;
};
class D:public B{
public:virtual void f();
};
这里可能会出现警告:
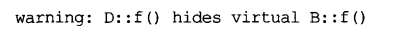
当然,D::f遮掩了B::f,那正是想象中该有的事,但是这个编译器试图告诉你声明于 B 中的 f 并未在 D 中被重新声明,而是被整个遮掩了(原本为const的函数,被改为非const,忽略这个警告,可能会导致使用上的错误)。
虽然有的警告看起来毫无影响,但是,学会看懂他们具体表示的含义后,再去忽略他们可以帮助更好的理解可能发生的故障、引起故障的点。
所以,尽量查看一些警告及其背后的含义
总结
- 严肃对待编译器发出的警告信息。努力在你的编译器的最高(最严苛)警告级别下争取“无任何警告”的荣誉。
- 不要过度倚赖编译器的报警能力,因为不同的编译器对待事情的态度并不相同。一旦移植到另一个编译器上,你原本倚赖的警告信息有可能消失。
54 让自己熟悉包括TR1在内的标准程序库
TR1代表 Technical Report 1。应该是很久远的库了,2008左右的标准了。
c++98之前的标准库
- STL ( Standard Template Library,标准模板库),覆盖容器( containers 如vector,string, map)、迭代器( iterators)、算法( algorithms 如find, sort, transform)、函数对象( function objects 如less,greater)、各种容器适配器( container adapters 如 stack, priority_queue)和函数对象适配器( function object adatpers如mem_fun, not1)。
- Iostreams,覆盖用户自定缓冲功能、国际化IO,以及预先定义好的对象cin, cout,cerr和 clog。
- 国际化支持,包括多区域(multiple active locales)能力。像wchar_t (通常是16 bits/char)和 wstring(由 wchar_ts组成的strings)等类型都对促进 Unicode有所帮助。
- 数值处理,包括复数模板( complex)和纯数值数组(valarray)。
- 异常阶层体系(( exception hierarchy),包括base class exception及其derived classes logic_error和runtime_error,以及更深继承的各个classes。
- C89标准程序库。1989 C标准程序库内的每个东西也都被覆盖于C++内。
介绍过的tr1组件
也就是std::tr1中
- 智能指针(smart pointers) tr1 : :shared_ptr 和 tr1 : : weak_ptr。前者的作用有如内置指针,但会记录有多少个 tr1 : :shared_ptrs共同指向同一个对象。就是所谓的reference counting (引用计数)。一旦最后一个这样的指针被销毁,也就是一旦某对象的引用次数变成0,这个对象会被自动删除。这在非环形( acyclic)数据结构中防止资源泄漏很有帮助,但如果两个或多个对象内含tr1 : :shared ptrs并形成环状(cycle),这个环形会造成每个对象的引用次数都超过0–即使指向这个环形的所有指针都已被销毁(也就是这一群对象整体看来已无法触及)。这就是为什么又有个 tr1 : : weak_ptrs的原因。tr1 : :weak ptrs 的设计使其表现像是“非环形tr1 : :shared_ptr-based 数据结构”中的环形感生指针(cycle-inducing pointers)。tr1 : : weak ptrs并不参与引用计数的计算;当最后一个指向某对象的tr1 : :shared_ptr被销毁,纵使还有个tr1 : :weak ptrs继续指向同-对象,该对象仍旧会被删除。这种情况下的tr1 : : weak_ptrs 会被自动标示无效。tr1 ::shared_ptr或许是拥有最广泛用途的TR1组件。(应该说的就是你中有我,我中有你的这种情况)
- tr1::function,此物得以表示任何 callable entity (可调用物,也就是任何函数或函数对象),只要其签名符合目标。假设我们想注册一个callback函数,该函数接受一个int并返回一个string,我们可以这么写:
void registerCallback(std::string func(int));//参数类型是函数,该函数接受一个int 并返回一个string,参数名称func也可以省略,就是void registerCallback(std::string (int));效果与前面的一致,这里的"std::string (int)" 是个函数签名。trl : :function 使上述的RegisterCallback有可能更富弹性地接受任何可调用物( callable entity),只要这个可调用物接受一个 int 或任何可被转换为 int 的东西,并返回一个string或任何可被转换为string的东西。tr1 : : function 是个template,以其目标函数的签名( target function signature)为参数:void registerCallback(std::trl : :function<std::string (int)> func);//参数"func”接受任何可调用物(callable entity 回调函数),只要该“可调用物”的签名与"std: :string (int)"一致 - tr1 ::bind,它能够做STL绑定器(binders) bindlst 和 bind2nd 所做的每一件事,还更多。和前任绑定器不同的是,tr1 : :bind可以和 const 及 non-const 成员函数协同运作,可以和 by-reference 参数协同运作。而且它不需特殊协助就可以处理函数指针,所以我们调用 tr1 : :bind 之前不必再被什么 ptr_fun,mem_fun 或 mem_fun_ref 搞得一团混乱了。简单地说,tr1 : :bind是第二代绑定工具( binding facility),比其前一代好很多。(没什么印象了)
独立的tr1组件
- Hash tables,用来实现 sets, multisets, maps 和 multi-maps。每个新容器的接口都以其前任(TR1之前的)对应容器塑模而成。最令人惊讶的是它们的名称: tr1 : :unordered_set, tr1 : :unordered_multiset , tr1 : : unordered_map 以及 tr1 : : unordered_multimap 。这些名称强调它们和set,multiset,map或 multimap 不同:以 hash为基础的这些TR1容器内的元素并无任何可预期的次序。(别的有顺序吗?)
- 正则表达式(Regular expressions),包括以正则表达式为基础的字符串查找和替换,或是从某个匹配字符串到另一个匹配字符串的逐一迭代(iteration)等等。
- Tuples(变量组),这是标准程序库中的 pair template 的新一代制品。pair 只能持有两个对象,tr1 : :tuple 可持有任意个数的对象。
- tr1 : :array,本质上是个“STL化”数组,即一个支持成员函数如 begin和end的数组。不过 tr1: :array 的大小固定,并不使用动态内存。
- tr1 : :mem_in,这是个语句构造上与成员函数指针(member function pointers)一致的东西。就像
tr1 : :bind纳入并扩充C++98的bind1st和bind2nd的能力一样,tr1 : :mem_fn纳入并扩充了C++98的mem_fun和mem_fun_ref的能力。tr1::reference_wrapper,一个“让 references的行为更像对象”的设施。它可以造成容器“犹如持有references”。而你知道,容器实际上只能持有对象或指针。 - 随机数(random number)生成工具,它大大超越了
rand,那是C++继承自C标准程序库的一个函数。 - 数学特殊函数,包括Laguerre多项式、Bessel函数、完全椭圆积分(complete ellipticintegrals),以及更多数学函数。
- C99兼容扩充。这是一大堆函数和模板(templates),用来将许多新的C99程序库特性带进C++。
编程技术类tr1组件
- Type traits,一组traits classes (见条款47),用以提供类型(types)的编译期信息。给予一个类型T,TR1的
type traits可以指出T是否是个内置类型,是否提供virtual析构函数,是否是个empty class(见条款39),可隐式转换为其他类型u吗……等等。TR1的type traits也可以显现该给定类型的适当齐位(proper alignment),这对定制型内存分配器(见条款50)的编写人员是十分关键的信息。 - tr1 : :result_of,这是个
template,用来推导函数调用的返回类型。当我们编写templates时,能够“指涉(refer to)函数(或函数模板)调用动作所返回的对象的类型”往往很重要,但是该类型有可能以复杂的方式取决于函数的参数类型。tr1 : :result_of使得“指涉函数返回类型”变得十分容易。它也被TR1自身的若干组件采用。
TRI 是对标准程序库的纯粹添加,没有任何TR1组件用来替换既有组件,所以早期(写于TR1之前的)代码仍然有效。
作者当时 tr1 还不一定由编译器提供,而且,部分tr1组件依赖boost库,tr1只是一份文档,所以,要使用tr1的组件,可能需要引入boost库,在boost命名空间中查找。
总结
- C++标准程序库的主要机能由STL、iostreams、locales 组成。并包含C99标准程序库。
- TR1 添加了智能指针(例如 tr1 : :shared_ptr) 、一般化函数指针(tr1::function)、 hash-based 容器、正则表达式(regular expressions)以及另外10个组件的支持。
- TR1自身只是一份规范。为获得TR1提供的好处,你需要一份实物。一个好的实物来源是Boost。
55 让自己熟悉Boost
大致介绍了boost的内容
- 字符串与文本处理,覆盖具备类型安全(type-safe)的
printf-like格式化动作、正则表达式(此为 TR1 同类机能的基础,见条款54),以及语汇单元切割( tokenizing)和解析( parsing) 。 - 容器,覆盖“接口与STL相似且大小固定”的数组(见条款54)、大小可变的
bitsets以及多维数组。 - 函数对象和高级编程,覆盖若干被用来作为TR1机能基础的程序库。其中一个有趣的程序库是
Lambda,它让我们得以轻松地随时随地创建函数对象:
using namespace boost::lambda;
std::vector<int> v;
std::for_each(v.begin(),v.end(),std::cout<<_1*2+10<<"\n");//针对v内的每一个元素x,打印x * 2 +10
//其中“1”是lambda 程序库针对当前元素的一个占位符
- 泛型编程(Generic programming),覆盖一大组 traits classes。
- 模板元编程(Template metaprogramming),覆盖一个针对编译期
assertions而写的程序库,以及Boost MPL程序库。MPL提供了极好的东西,其中支持编译期实物(compile-time entities)诸如 types 的STL-like数据结构,等等。
//创建一个 list-like 编译器容器,收纳三个类型:
//(float,double,long double)次容器名称为 floats
typedef boost::mpl::list<float,double,long double> floats;
//再创建一个编译器用以收纳类型的list,以floats 内的类型为基础
//最前面加上 int,新容器类型取名为 types
typedef boost::mpl::push_front<floats,int>::type types;
//这样的类型容器
- 数学和数值(Math and numerics),包括有理数、八元数和四元数(octonions andquaternions)、常见的公约数(divisor)和少见的多重运算、随机数。
- 正确性与测试(Correctness and testing),覆盖用来将隐式模板接口( implicittemplate interfaces,见条款41)形式化的程序库,以及针对“测试优先”编程形态而设计的措施。
- 数据结构,覆盖类型安全(type-safe》的
unions(存储各具差异之“任何”类型),以及tuple程序库(它是TR1同类机能的基础)。 - 语言间的支持(Inter-language support),包括允许C++和Python之间的无缝互操作性(seamless interoperability)。
- 内存,覆盖Pool程序库,用来做出高效率而区块大小固定的分配器(见条款50),以及多变化的智能指针(smart pointers,见条款13),包括(但不仅仅是)TR1智能指针。另有一个non-TR1智能指针是
scoped_array,那是个auto_ptr-like智能指针,用来动态分配数组;条款44曾经示范其用法。 - 杂项,包括CRC检验、日期和时间的处理、在文件系统上来回移动等等。
总结
- Boost 是一个社群,也是一个网站。致力于免费、源码开放、同僚复审的C++程序库开发。Boost在C++标准化过程中扮演深具影响力的角色。
- Boost 提供许多TR1组件实现品,以及其他许多程序库。



![利用TreeMap来解决P3029 [USACO11NOV] Cow Lineup S](http://pic.xiahunao.cn/利用TreeMap来解决P3029 [USACO11NOV] Cow Lineup S)


- 类型支持 (运行时类型识别,type_info ))


 构建标记流)

学习笔记(七)面向对象编程(进阶))

)




-沟通路径)
