
redo log
redo log (重做日志) 是 InnoDB 存储引擎独有的,它让 MySQL有了崩溃恢复的能力,是事务中实现 持久化的重要操作
比如 MySQL 实例宕机了,重启时,InnoDB 存储引擎会使用 redo log 恢复数据,保证数据的持久性与完整性。

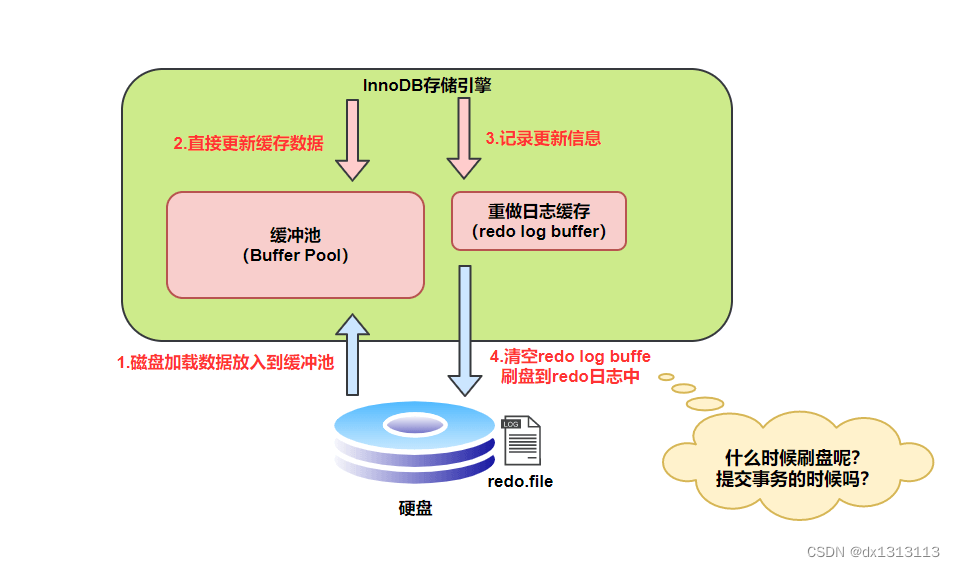
MySQL 中数据时以页为单位,查询一条记录,会从硬盘中把该页的数据都加载出来,加载出来的页叫做数据页,会放入 Buffer Pool 中。
后续的查询都是先从 Buffer Pool 中找,没有命中再去硬盘加载,减少硬盘 IO 的开销,提升性能。
更新表数据的时候也是如此,如果 Buffer Pool 中存在需要更新的数据,就会直接在 Buffer Pool 中更新。
然后会把 在某个数据页中做了什么修改 记录到重做日志缓存(redo log buffer )中 ,接着刷盘到 redo log 文件里。
输盘时机:
InnoDB 将 redo log 刷盘到磁盘上有以下几种情况:
- 事务提交:当事务提交时,log buffer 里的 redo log 会被刷新到磁盘
- log buffer 空间不足时:log buffer 中缓存的 redo log 已经占满了 log buffer 总容量的大约一半左右,就需要把这些日志刷新到磁盘上。
- 事务日志缓冲区满:InnoDB 使用一个事务日志缓冲区来暂时存储事务的重做日志。当缓冲区满时,会触发日志的刷新,将日志写入磁盘
- CheckPoint (检查点):InnoDB 定期会执行检查点操作,将内存中的脏数据刷新到磁盘,并且会相应的重做日志一同刷新,以确保数据的一致性
- 后台刷新线程:InnoDB 启动了一个后台线程,负责周期性地将脏页刷新到磁盘,并将相关的重做日志一同刷新。
- 正常关闭服务器:MySQL 在关闭的时候,redo log 都会刷入到磁盘里去。
总之,InnoDB 会在多种情况下刷新重做日志,以确保数据的持久性和一致性。
日志文件组
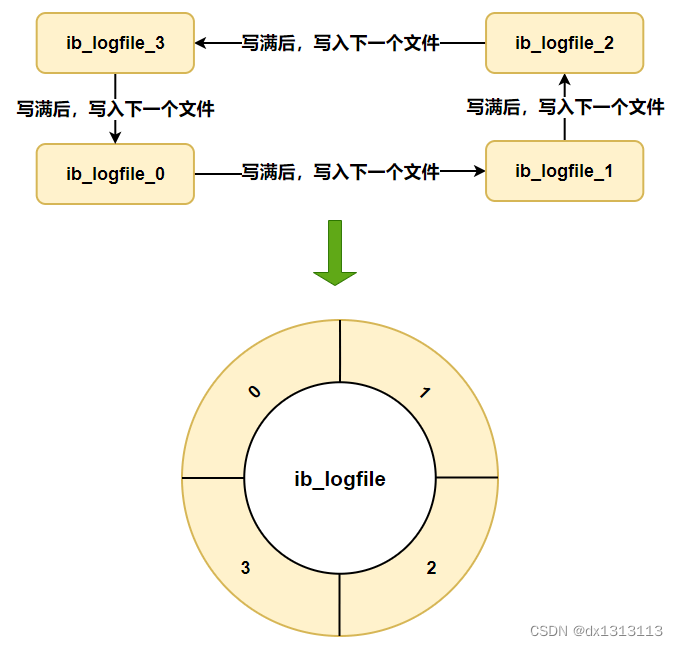
硬盘上存储的 redo log 日志文件不止一个,而是以一个日志文件组的形式出现,每个 redo 日志文件大小是一样的。
比如可以配置为一组 4 个文件,每个文件的大小是 1 GB ,整个 redo log 日志文件组可以记录 4G 的内容。它采用的是环形数组的形式,从头开始写,写到末尾又回到头循环写,如下图:
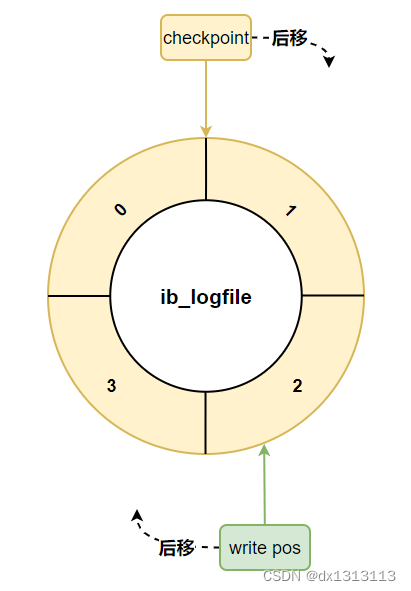
日志文件组中还有两个重要的属性,分别是 write pos、checkpoint
- write pos 是当前记录的位置,一边写一边后移
- checkpoint 是当前要擦除的位置,也是往后推移
每次刷盘 redo log 记录到日志文件组中,write pos 位置就会后移更新
每次 MySQL 加载日志文件组恢复数据时,会清空加载过的 redo log 记录,并把 checkpoint 后移更新。
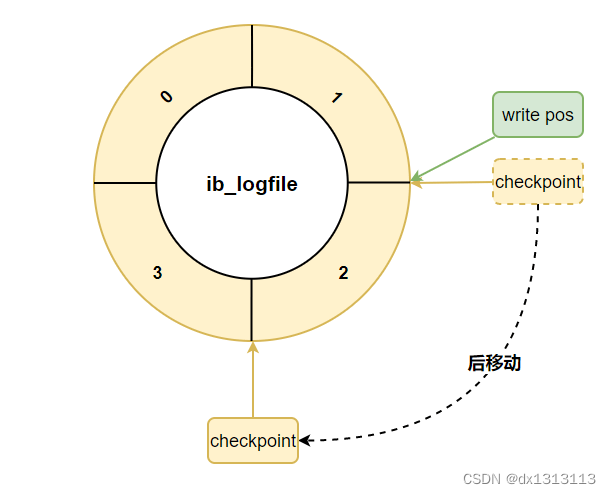
如果 write pos 追上了 checkpoint ,表示 日志文件组满了,这时候不能再写入新的 redo log 记录了,MySQL 需要停下来,清空一些记录并把 checkpoint 推进一下。
只要每次把修改后的数据页直接刷盘不就好了,为什么需要经过redo log 刷盘呢?
数据页的大小是 16KB ,刷盘比较耗时,可能就修改了数据页中的 几 Byte 数据,为了这些数据而重新刷盘整个页,有所不值。
而且数据页刷盘是随机写的,因为一个数据页对应的位置可能在硬盘文件的随机位置,所以性能很差。
如果是写 redo log ,一行记录可能就占几十 Byte,只需要记录表空间号、数据页号、磁盘文件偏移量、更新值,再加上是顺序写,所以刷盘速度很快。
所以使用 redo log 形式记录修改的内容,性能会远远超过刷数据页的方式,这也让数据库的并发能力更强。
bin log
redo log 属于物理日志,记录的内容是“在某个数据页上做了什么修改”,属于 InnoDB 存储引擎。
而 bin log 属于逻辑日志,记录的内容是语句的原始逻辑,比如:“给id 为 2 的这一行的 a 字段 加 1”,属于 Server 层
不管使用什么存储引擎,只要发生了表数据更新,都会产生 binlog 日志。
binlog 在数据库中可以起到保证数据一致性的作用,因为 数据库的数据备份、主备、主主、主从都离不开 bin log ,需要bin log 来同步数据。

binlog 会记录所有涉及更新数据的逻辑操作,并且是顺序写。
undo log
undo log(回滚日志),它保证了事务的原子性。
undo log 是一种用于撤销回退的日志。在事务没提交之前,MySQL 会先记录更新前的数据到 undo log 日志文件里面,在事务回滚时,可以利用undo log 来进行回滚。
- 在插入一条记录时,会把这条记录的主键值记录下来,这样之后回滚时,只需要把这个主键值对应的记录删掉即可
- 在删除一条记录时,要把这条记录中的内容都记录下来,这样之后回滚时再把这些内容组成的记录插入到表中即可
- 在更新一条记录时,会把被更新的列的旧值记录下来,这样之后回滚时在再把这些列更新为旧值即可
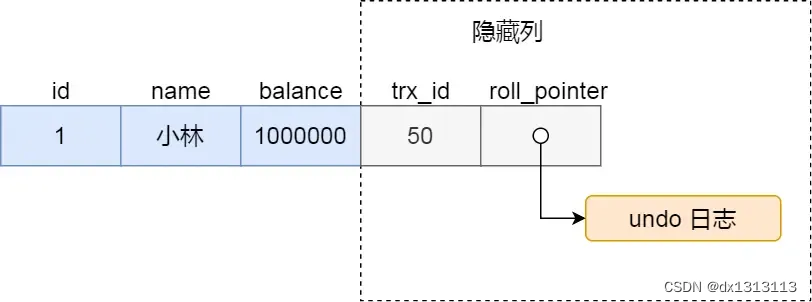
undo日志的存在形式如上图所示,使用 InnoDB 存储引擎的数据库表,它的聚簇索引记录都包含下面两个隐藏列:
- trx_id,当一个事务对某条聚簇索引进行改动时,就会把该事务的id记录在 trx_id 隐藏列里;
- roll_pointer,每次对某条聚簇索引记录进行改动时,就会把旧版本的记录写入到 undo 日志中,然后这个隐藏列是个指针,指向每一个旧版本记录,于是就可以通过它找到修改前的记录
另外,undo log 还有一个作用,就是通过 Read View 实现 MVCC(多版本并发控制),具体操作可见:事务隔离级别是怎么实现的?_dx1313113的博客-CSDN博客












)




)

