为什么要使用B+树?
可以进行数据查询的数据结构有二叉搜索树、哈希表等。对于前者来说,树的高度越高,进行查询比较的时候访问磁盘的次数就越多。而后者只有在数据等于key值的时候才能进行查询,不能进行模糊匹配。所以出现了B+树来解决这些问题
B+树的前身——B树
B树可以认为是一个N叉搜索树。树的高度越高,进行查询比较的时候访问磁盘的次数就越多。
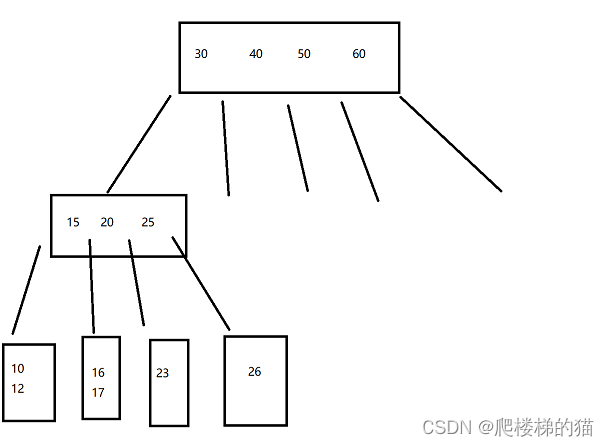
存放N个key,引出N+1个节点。例如:30引出的节点都要满足(X < 30) ,30和40之间引出的节点要满足(30<X<40)
当节点的子树多了之后,节点上保存的key多了,意味着在同样key的个数的前提下,B树的高度要比二叉搜索树低很多
B+树
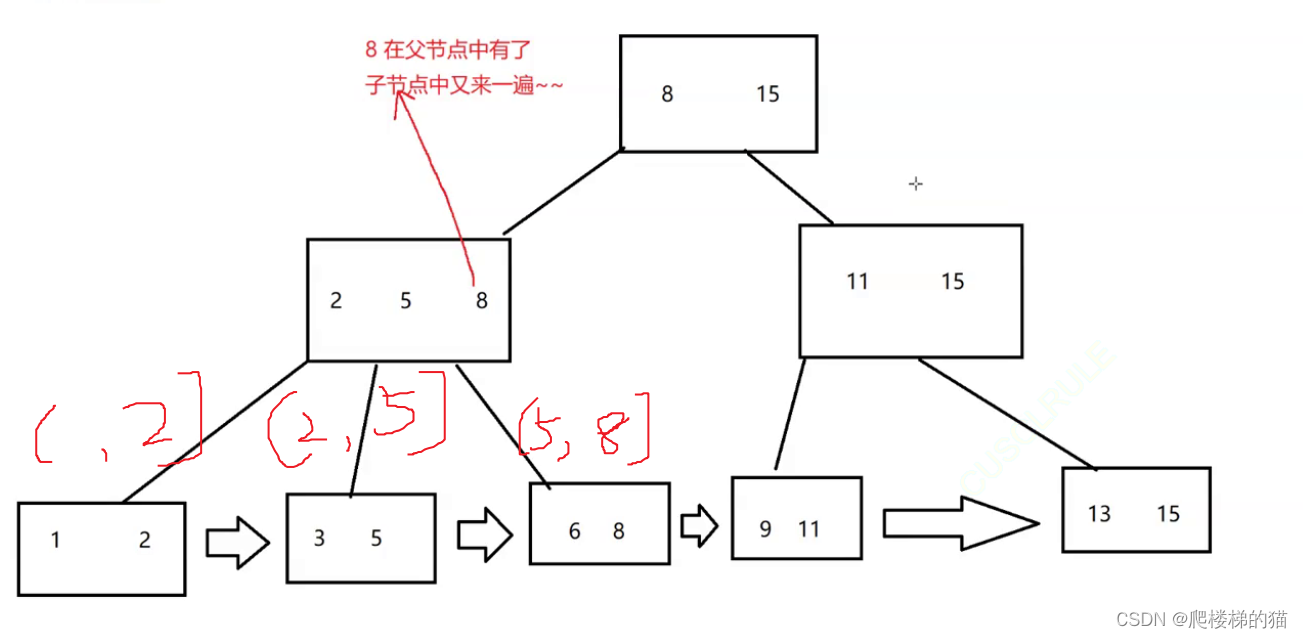
B+树是存了N个key,引出N个节点。且底层的节点连接成类似于链表的结构
B+树的特点
- 一个节点可以存储N个key,N个key划分出了N个区间;
- 每个节点中的key的值,都会在子结点中也存在(同时该key是子节点的最大值)
- B+树的叶子节点,是首尾相连,类似于一个链表
- 由于叶子节点是完整的数据集合,只在叶子节点这里存储数据表的每一行的数据。而非叶子节点,只存key值本身即可
B+树的优点
- 当前一个节点保存更多的key,最终树的高度是相对更矮的。查询的时候减少了IO访问次数
- 所有的查询最终都会落在叶子节点上,这意味着查询任何一个数据,经过的IO访问次数是一样的
- B+树的所有叶子节点构成链表,此时比较方便进行范围查询
- 由于数据都在叶子节点上,非叶子节点只存储key,导致非叶子节点占用空间较小。这些非叶子节点就可能在内存中缓存,又进一步减少了IO次数




)



)




屏幕判断)


Burpsuite)

、忽略(gitignore)、隐藏(Stash)、合并冲突(merge)的解决方法)
