文章目录
- 约束
- 空属性约束
- 默认值约束
- zerofill
- 主键约束
- 自增长约束
- 唯一键约束
- 外键约束
- 查询
- select的执行顺序
- 单表查询
- 排序
- update
- delete
- 整张表的拷贝
- 复合语句
- group by分组查询
- 函数
- 日期函数
- 字符串函数
- 数学函数
- 其他函数
- 复合查询
- 合并查询union
约束
空属性约束
两个值:null和not null
属性的默认字段基本为空,数据为空时无法参数运算
用not null限制列属性不能为空(约束),即无法插入默认值


注意空串和NULL不一样
默认值约束
default约束:保证数据的完整性
建表时为列属性添加默认值:忽略该列属性时,自动填充默认值
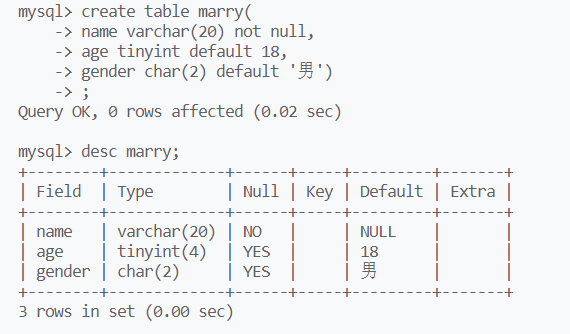
default vs not null
default和not null可以一起设置,表示不允许显式的插入null数据,但是可以忽略该数据
设置列值的具体情况:
- 插入
- 插入具体值
- 插入NULL:此时not null将进行约束
- 不插入:和default有关
列描述:
comment字段,没有实际意义,作为描述语句,会保存在创建语句中
执行以下语句会显示建表的具体语句,能看到comment字段
show create table 表名 \G
zerofill
int和unsigned int的区别
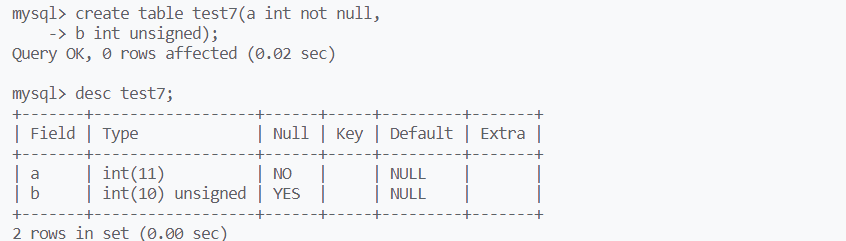
默认情况下,int类型后面括号数字为10,unsigned后为11
也可以在建表时显示声明
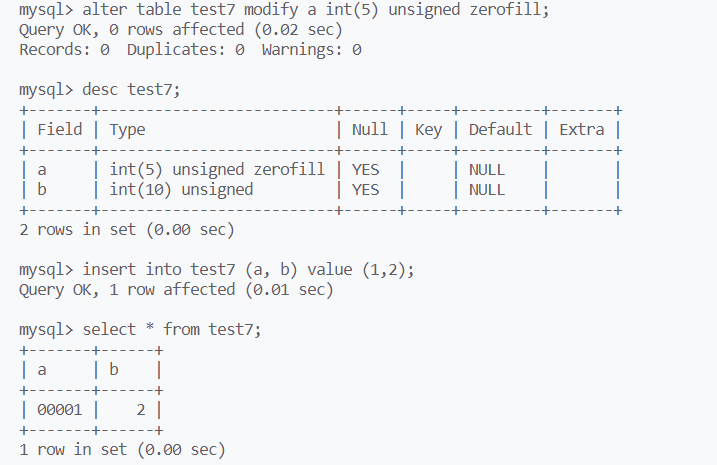
zerofill作为一种格式化输出关键字,需要在创建列属性时声明,当数字小于类型后的括号数字时,这些位置将用0填充
int最大的值为42亿多,一共是10位,因为int有符号,还需要使用一个符号位
主键约束
表中的一行信息叫做记录,一列叫做属性
primary key,一张表中最多只有一个主键,主键不能为空,不能相同,通常是整数类型
主键保证每条记录的唯一性
创建表时直接指定主键:primary
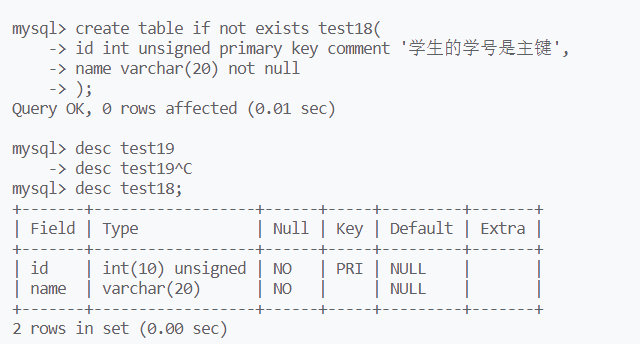
主键不允许为空,所以自带not null属性,可以看到Key属性中,id记录为PRI

主键不允许相同,除了主键之外的其他数据都可以相同
建表时,可以在属性定义后再声明主键

创建好表后,追加主键:
alter table 表名 add primary key(列名);
追加主键时,需要满足该字段的数据唯一
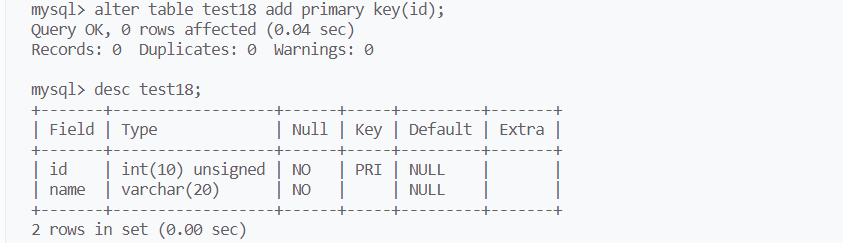
删除主键:
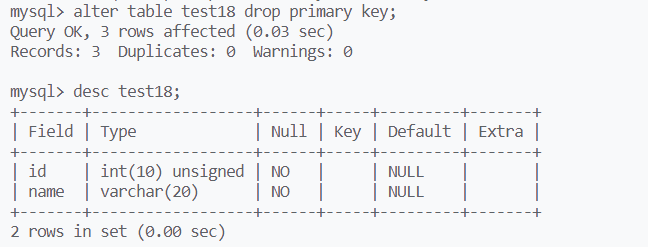
alter table 表名 drop primary key;
复合主键:
定义复合(多个)主键后,只有所有主键冲突,数据才会无法插入,任一主键冲突,都是允许插入的
可以将复合主键看成一种特殊的主键
如何选择主键?
- 选择与业务有关的主键,根据业务的具体信息选择
- 选择与业务无关的主键,主键值与业务无关,业务调整不影响表结构,实现解耦。比如qq号
自增长约束
表中有一个属性可以被设置为自增长auto_increment,一旦被设置为自增长,就成为主键
通常和主键配合使用作为逻辑主键,自增长的属性一般是整数类型
- 整数类型
- 一张表最多只有一个自增长
使用auto_increment时,必须和primary key配合使用,否则会报错

插入数据时,自增长默认从1开始,每插入就+1
mysql会记录auto_increment的值
show create table 表名 \G;
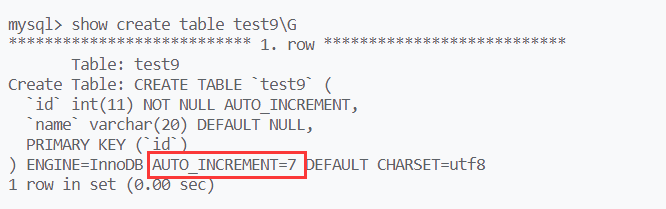
如果你插入了一个打乱规则的值,那么auto_increment的值将从它开始

auto_increment的值可以在建表的最后(右括号后)指定

唯一键约束
主键更多的是为了保证查找时,除了null值之外,能查找到唯一的记录
唯一键更多的是为了保证在表中,某一属性的数据互不相同
生活中有很多具有唯一性的属性,主键只是从这些唯一性属性中选择一个属性成为主键
当需要维护剩下属性的唯一性时,可以将其设置为唯一键
主键和唯一键互补
建表时添加unique字段

唯一键使得数据库的约束更强,更符合现实世界的要求
把唯一键设置为not null,在插入时的属性与主键一样(等价于主键)
外键约束
在建表时添加外键约束:
foreign key(从表属性) references 主表名(主表属性)
外键约束的Key列,值为MUL
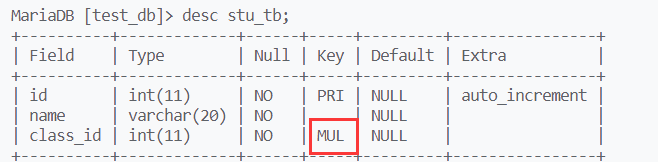
外键维护表与表之间的关系
现实世界中,一个学生隶属于某个班级,一个班级内部有多个学生
学生:班级 = n : 1。因此学生表与班级表之间存在关系,这就是关系型数据库
先有业务场景,再有这样的关系
在班级表出现学生信息,成本太大,所以选择在学生表中出现班级信息
学生表是从表,因为它有一个属性用来索引班级表,班级表是主表。外键定义在从表中
class_id作为外键,定义在从表中。外键列的数据必须在主表存在且唯一
所以外键通常是主表的主键或者唯一键
总之,一个表中的列信息域另一个表中的列信息出现关联,这就是外键


更新学生表的数据时,如果更新了外键且该数据在主表中不存在,那么更新不被允许,插入数据时也同理

不使用外键将带来的问题:
将班级表中的某个班级删除时,学生表中不应该存在学生隶属于该班级
当学生记录存在时,无法删除对应班级的记录
外键约束对于非法操作的拦截

在从表中创建外键,主表必须先存在该属性,且两者的类型必须一致
现实的业务逻辑中,不同业务之间可能具有外键,mysql中的表与表之间也可能具有外键,两者之间存在关联。因此mysql必须约束外键,以保证数据之间的完整性与一致性,这被称作外键约束
具有约束的关联字段,叫做外键
区分:外键vs外键约束
查询
select * from 表名,使用通配符*进行全列查找,但通常情况下数据库的数据庞大,不建议使用全列查找
将*替换成列属性的名称,如select id, name form exam_result,就能只显示id和name两列的内容
select的执行顺序
select * from exam_result where ...
- 根据表名(exam_result)确定要搜索的表
- 根据where条件遍历表,将所有符合条件的记录筛选出来
- 最后根据
*或者指定的列将所有记录中的对应列呈现
单表查询
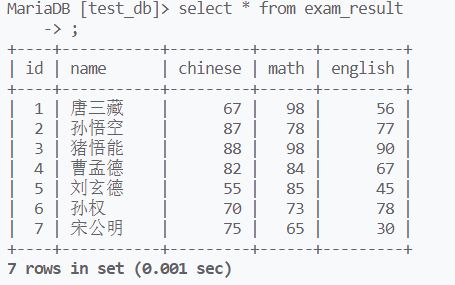

select支持使用表达式
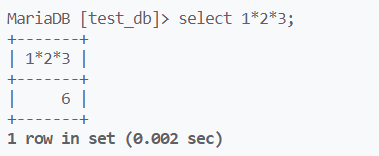
表达式的计算结果可以起别名
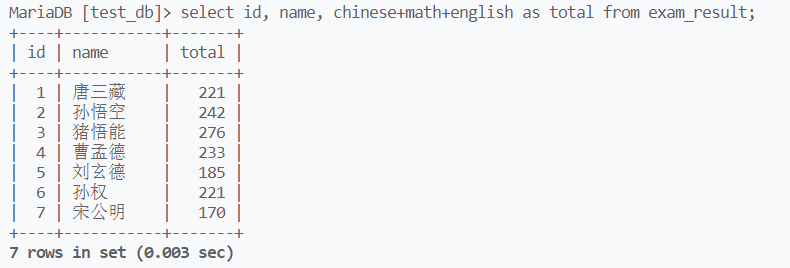
其中as可以省略,命名也可以是中文

distinct可以对查询结果进行去重,按照记录是否完全一致去重
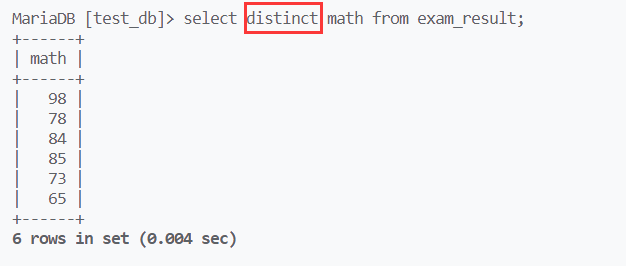
select结果可以用where进行进一步的筛选,mysql中不支持==,对于等于的判断需要使用=
NULL vs ‘’,NULL表示不存在,''表示存在,但没有值,并且NULL一般不参与计算
如果想要筛出列属性(不)为NULL的记录,需要用where 属性 is (not) NULL来判断
或者用<=>来判断
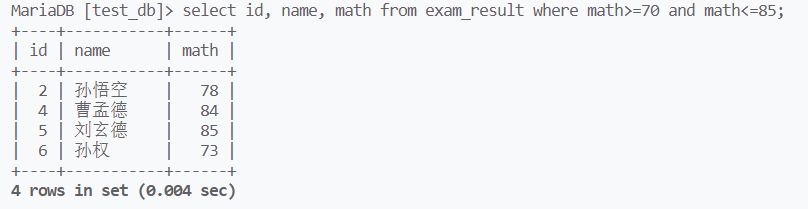
用between来进行区间筛选,左右区间为闭区间

用and(逻辑与)也能实现该操作,or(逻辑或)
in:查询某条记录是否在集合中

筛选条件与需要呈现出来的列可以不同

(not) like进行模糊匹配,查询姓孙的同学,%表示多个字符,_表示一个字符


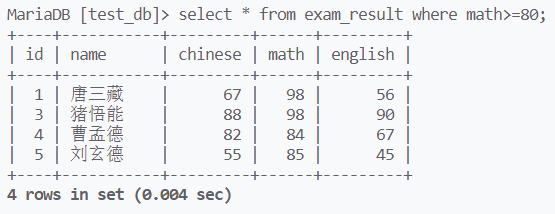
select的where条件中,不仅可以限制列属性为具体的值,还能将列属性中的值做比较

查找总分小于200的记录

为什么这样是错的,根据select的执行顺序,重命名total之前,就需要将total<200作为筛选条件进行筛选,显然此时的select不知道total是什么

并且因为执行顺序,不能在where中使用as重命名

排序
用order by 属性,根据该属性值进行排序,默认升序

在最后加asc和desc进行升序/降序排序
若排序的属性有多个,则表示按照第一个关键字排序时,若相等则按照第二个关键字排序,若相等则按照第三个关键字排序…

这里可以用total进行排序,是因为排序的执行顺序在重命名total后
limit x
只显示前x行的数据,limit必须写在最后

limit s offset n
从n+1行开始显示s行
update
对查询的结果进行列值更新
update 表名 set 属性=值,属性=值 where=...
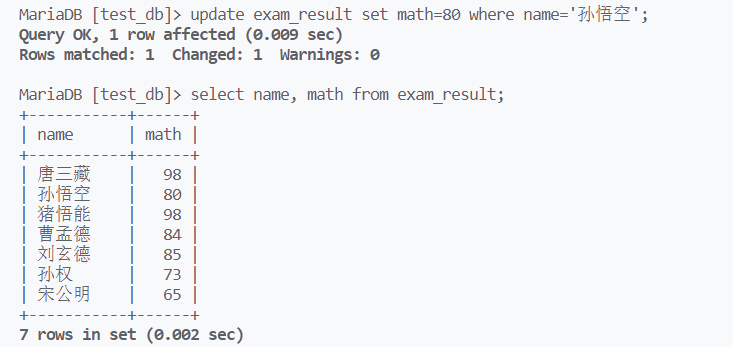
使用update时,一般都要跟上where限制,否则将更新所有记录

将总分倒数前三的人的数学成绩+30
update将修改存在于表中的列信息(不能修改总分,因为总分不存在,只能修改存在的数学,英语和语文)
delete
删除记录
delete from 表名 where=...
不用where限制,将删除整张表
删除总分前两名的同学

delete删除时,自增auto_increment的值不会被影响
但截断:truncate 表名将删除整张表(删除所有记录,保留表的原始结果),自增变量将被重置
整张表的拷贝
用like指令创建一个结构相同的表,数据不会拷贝

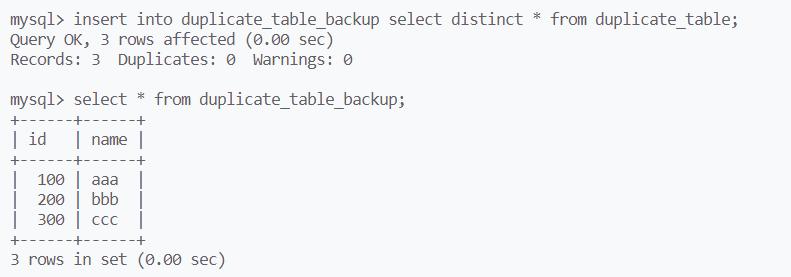
用insert和select复合指令,将原表的数据拷贝到新表

加上distinct,实现去重拷贝
用alter和rename对表进行重命名,重命名操作是原子的,本质是mv操作,mv操作本身就是原子的

复合语句
用count,统计结果的行数,NULL不会被统计
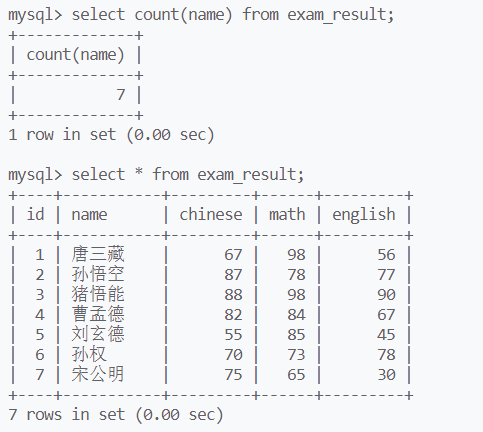

NULL vs ‘’

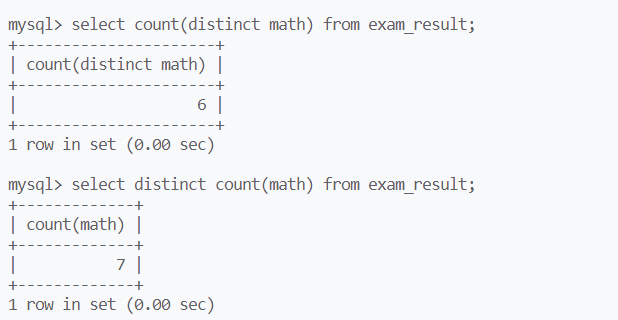
可以将distinct作为count的参数调用count

以下语句的执行结果为什么不同?执行顺序的问题:后者先执行count再执行distinct,此时distinct不起作用(因为count后没有完全相同的记录)
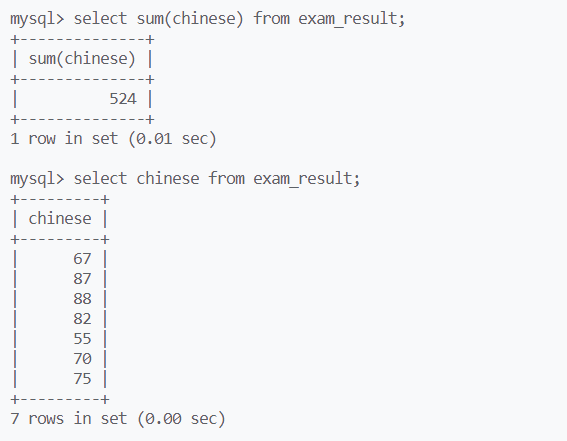
用sum函数统计总分
聚合函数:
一定是直接或者间接统计列方向的数据,这些数据具有相同属性
用avg计算英语平均成绩

用max求数学成绩最大值

group by分组查询
之前的查询都是将所有数据看成一组,分组查询顾名思义,将所有数据分组后再进行查询
按部门号分组后,查询(部门号,平均工资,最高工资)

以上语句中group by优先执行
使用group by时,除了聚合函数,只有分组的依据可以进行显示
如:按照deptno分组后,只能显示deptno的列信息,无法显示ename列信息

where和聚合函数是矛盾的,聚合函数需要先拿到所有数据(聚合)才能得到结果,而where的筛选是在拿到数据时进行筛选,where先执行,聚合后执行
显然,拿到数据时无法拿到所有的数据,因此以下语句是错误的
筛选平均工资小于2000的部门

用having解决此问题

where的执行顺序一定是靠前的,在遍历完所有数据时,where的筛选也随之结束
而聚合函数的执行一定是在遍历完所有数据时
而having的执行顺序靠后,将对聚合后的结果进行条件筛选
having通常与group by一起使用,不能单独使用
从工资大于1000的员工中筛选,平均工资小于2000的部门(where,having,聚合函数一起使用)

where和聚合函数不能一起使用指的是where的筛选条件不能是聚合函数
总结:
- group by通过分组的手段,为未来进行聚合统计提供支持,即group by一定是配合聚合统计使用的
- group by后跟的一定是分组的依据,只有在group by后出现的字段,才能在select后出现
- where vs having
函数
日期函数
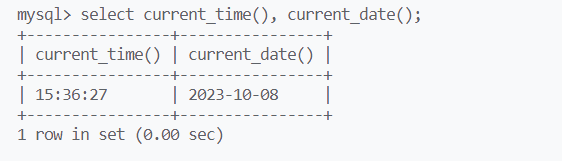
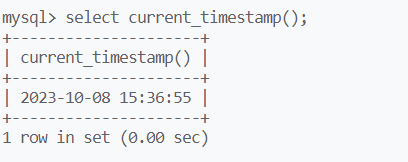
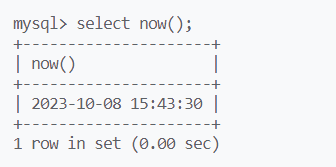
current_date(),current_time(),current_timestamp()
分别返回时间,日期,日期+时间
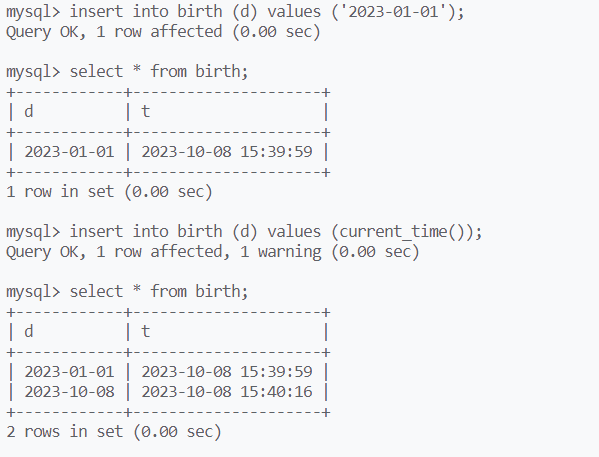
以time函数的结果为数据,进行插入
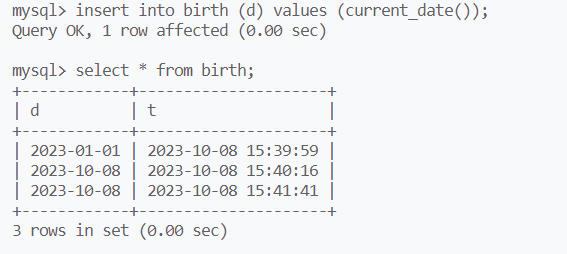
用date函数也可以,mysql会根据列属性,提取需要的时间
now = timestamp
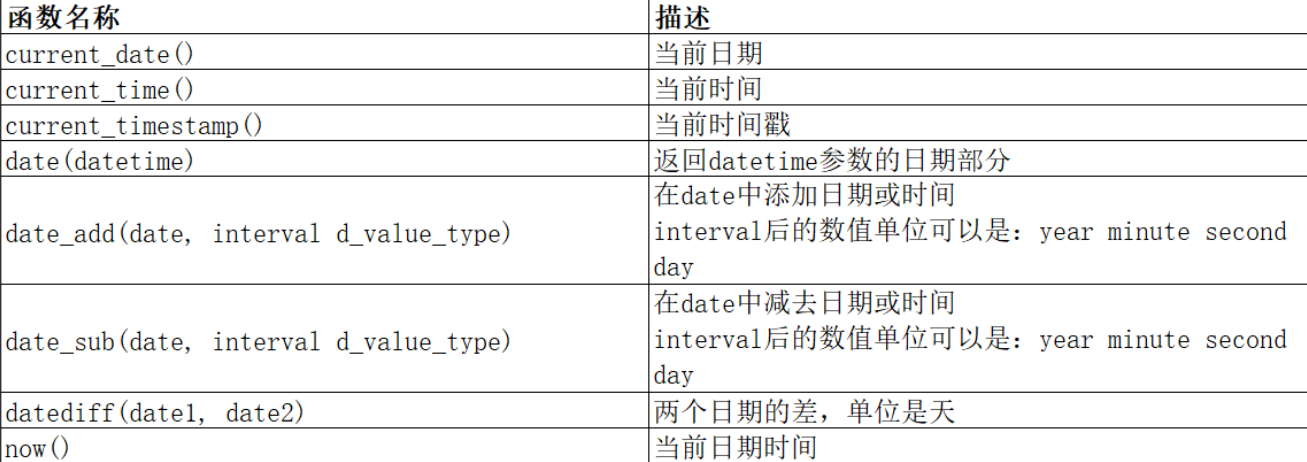
(日期还有加减函数)
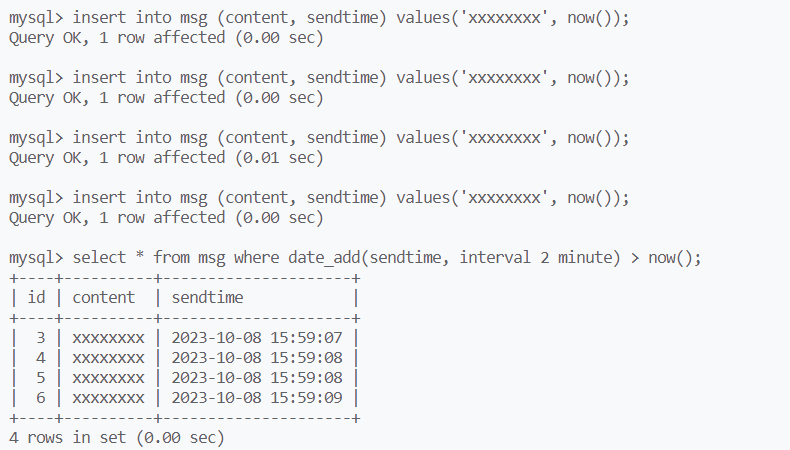
用datetime作为类型,now()作为值进行数据的插入

通过日期的加减函数,筛选2分钟内发布的信息
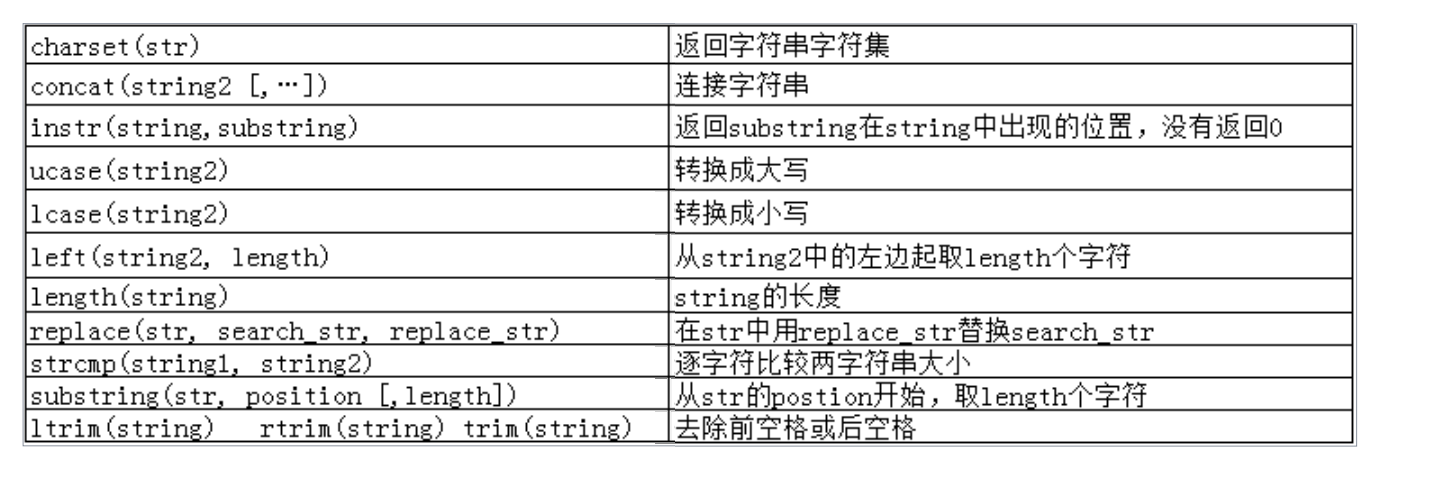
字符串函数
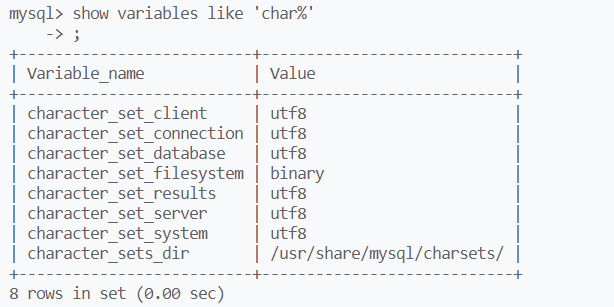
使用charset查看记录中的字符串使用的编码集

一般用来解决乱码问题,通过判断列属性使用的编码集和show variables like 'char%'显示的数据是否对应
concat(…),可以拼接多个字符串

length(str),求字符串长度

substring(str, i, len),从第i个字符截取开始长度为len的字符串,是字符不是字节
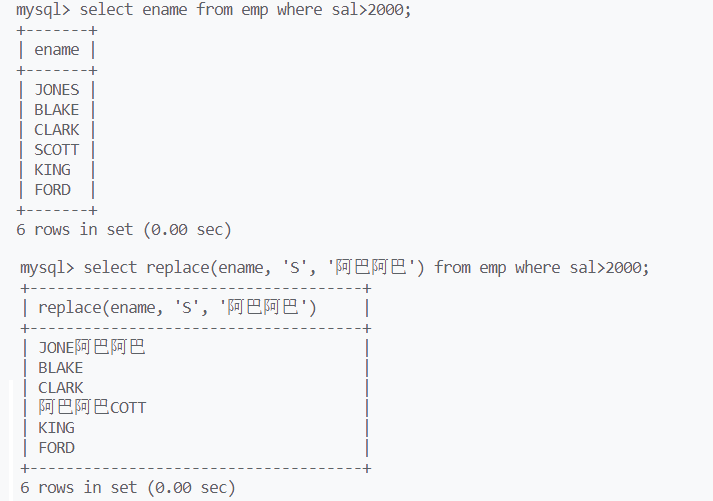
replace(str, str1, str2),将str中的所有str1替换成str2
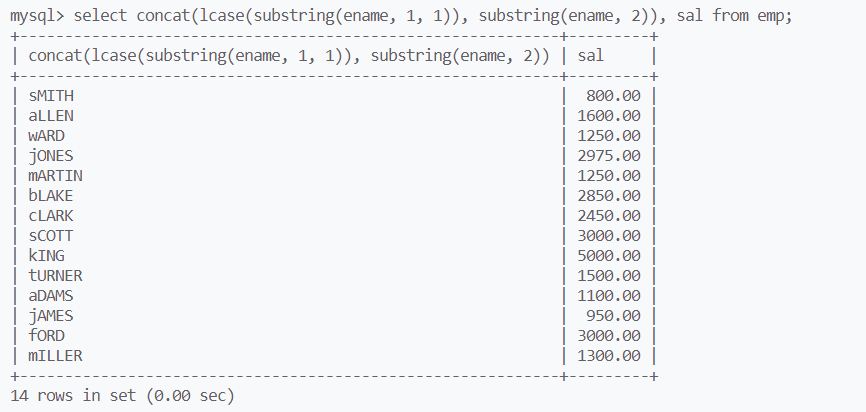
以首字母小写的方式显示名字,mysql中的函数可以嵌套使用
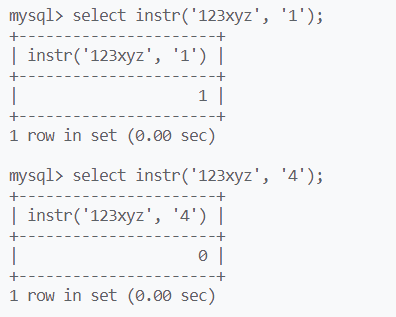
instr(str, str1)返回str1的首字母在str中第一次出现的位置,没有返回0
也可以做到like的模糊查找(函数可以出现在where筛选中)

strcmp,和c语言的接口一样,大于返回1,相等为0,不等为-1
trim(str),清洗字符串首尾的空格

数学函数
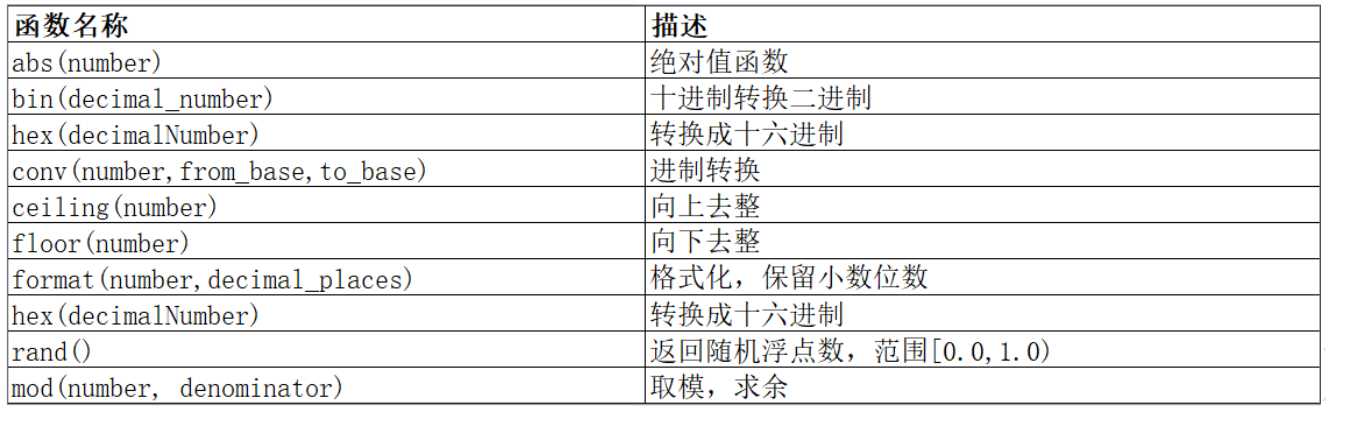
rand返回随机浮点数,可以通过运算返回指定范围中的数
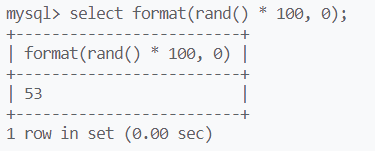
利用format格式化函数,输出整数
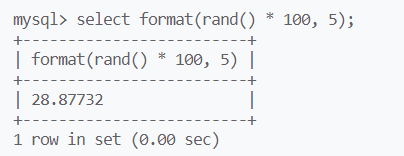
也能保留特定位数的小数
format函数为执行的最后一步,将数据进行格式化输出,给format的结果取别名没有意义
其他函数
mysql中有一个mysql数据库,其中有一张user表,里面记录了所有用户的权限信息,修改用户的权限本质上就是对这张表做修改
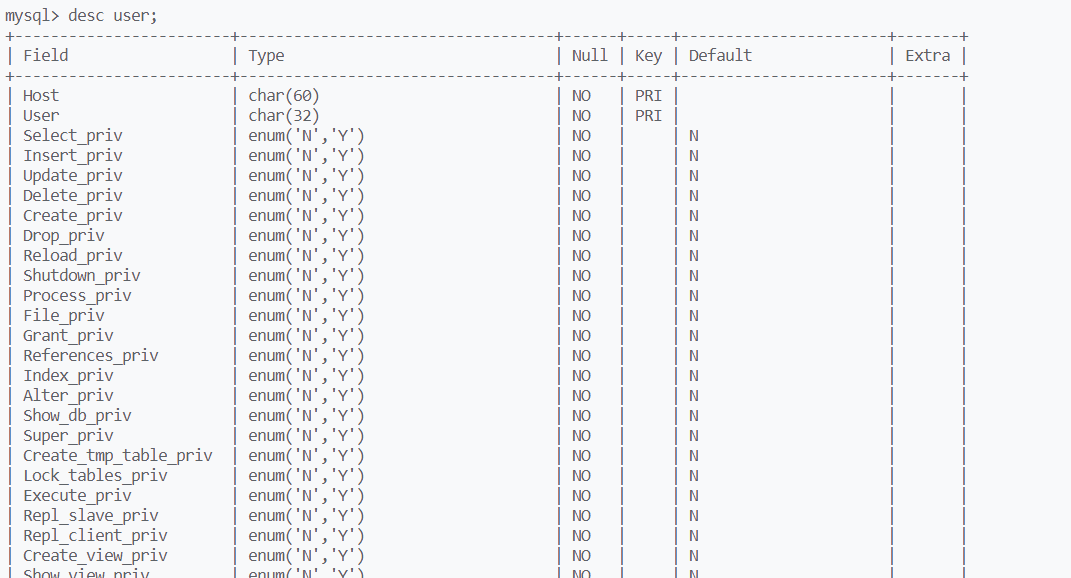
user()函数本质上是提取user表中的内容
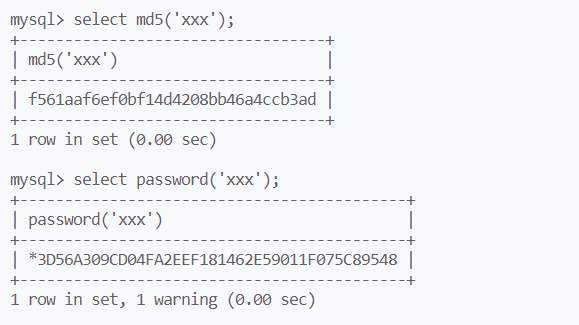
md5()通常用来进行数据摘要,在insert语句中,若存在md5()函数(字段),mysql不会保存该语句为历史语句(一般无法查询该语句),为了保证数据安全
在表中保存的敏感数据,通常都是用md5摘要过后的数据,当需要用原始数据进行比较(筛选)时,需要对原始数据使用md5函数
md5()形成的摘要长度为定长
password()为mysql自己的摘要函数
ifnull(val1, val2),类似于三目运算符,若第一个参数为空,返回第二个参数,否则返回第一个参数

显示工资最高的员工的姓名以及岗位,select嵌套查询

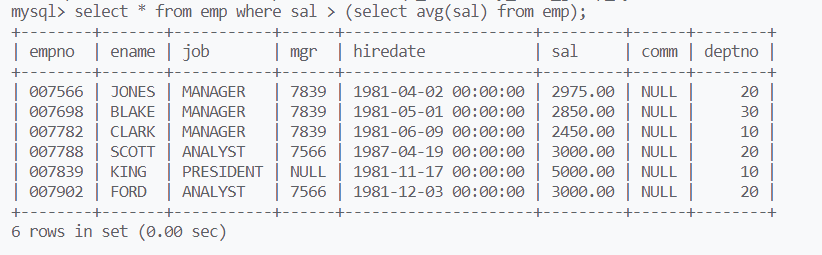
工资大于平均工资的员工信息
每种岗位的平均工资和人数,count(*)为一种运算技巧

复合查询
select from 表1, 表2,结果为两张表记录的笛卡尔积,可以将结果也看成一张表
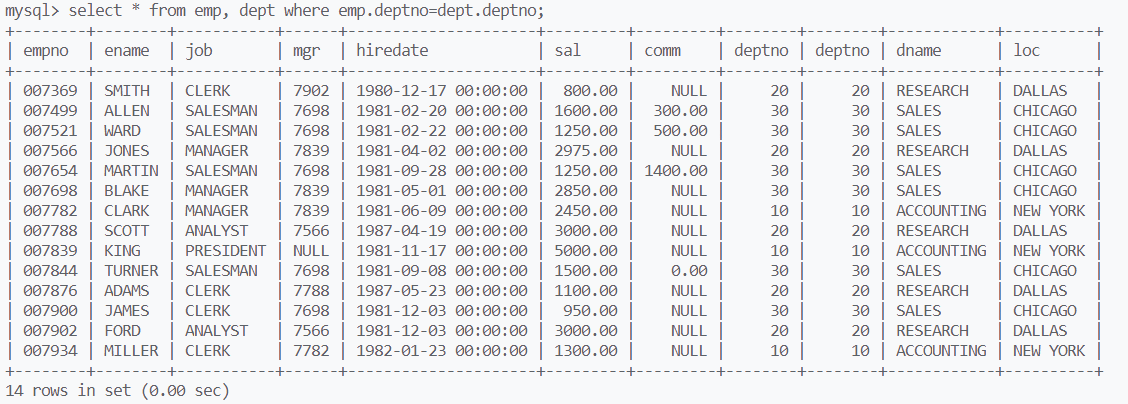
当两张表存在相同的列属性时,用表名.属性名区分两者
自链接:
表自身与自身做笛卡尔积,需要对表进行重命名,否则无法执行语句(自链接)
查询员工’FORD’的领导的信息(名字,职工号)

自链接时,所有的属性都要限制表名,否则将像上图一样报错
查询和10号部门的岗位相同的员工信息(名字,岗位,工资,部门号),但是这些雇员不属于10号部门
当可选条件有多个时,使用in关键字,用于多行记录的子查询

查询工资大于30号部门所有员工的员工信息(名字,工资,部门号)
all关键字,将筛选出的数据(单列多行)看成一个集合,也可以用max完成

多个条件比较的技巧:可以通过括号进行多个数据的比较,不需要用and(括号比较类似于c++11的初始化列表)

还能将查询结果作为一张表,与其他表进行笛卡尔积,不过查询结果需要重命名
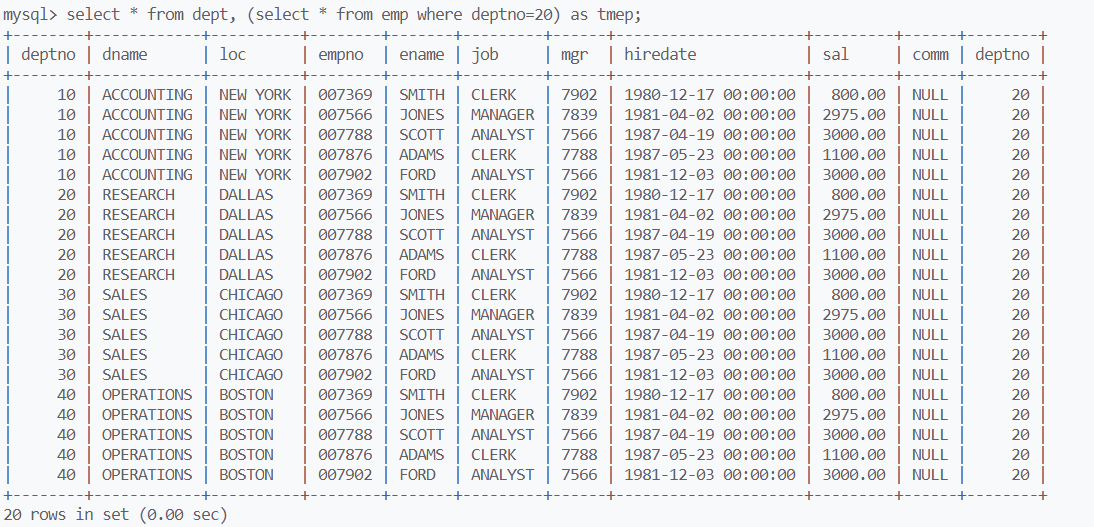

合并查询union
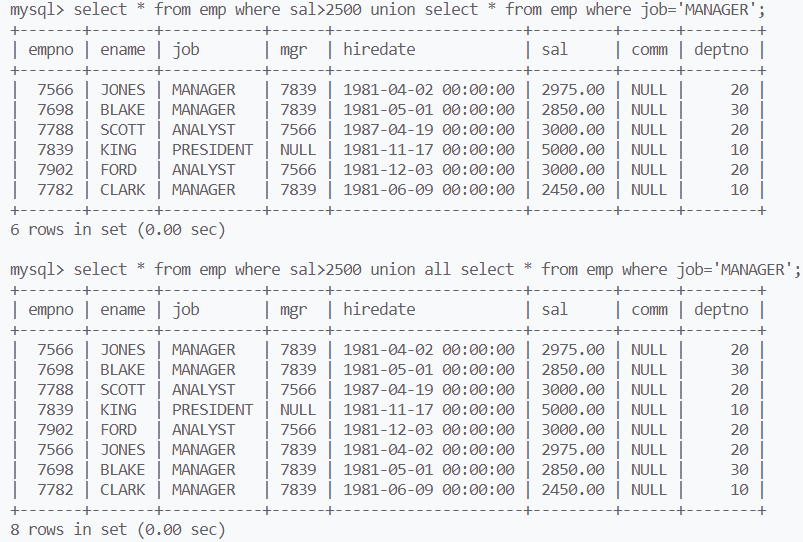
将工资大于2500或者岗位为MANAGER的人找出
用where … or … 能解决该问题,用union也能解决,其中union all可以不对结果进行去重
union默认对结果进行去重
使用union的前提是表结构相同,否则运算结果没有意义
union相当于并集运算


)






)



之轻量化模型Ghostnet)


)

)
QT中使用QVTKOpenGLNativeWidget的简单教程以及案例,利用PCLVisualizer显示点云)