目录
- 选择、多选
- SQL
- 题目描述
- 输入
- 目标
- 解答
- 解析
- 题目分享
选择、多选
Java, int x = 1, float y = 2, x/y =
0.5
2. Hive 的数据结构
基本数据类型
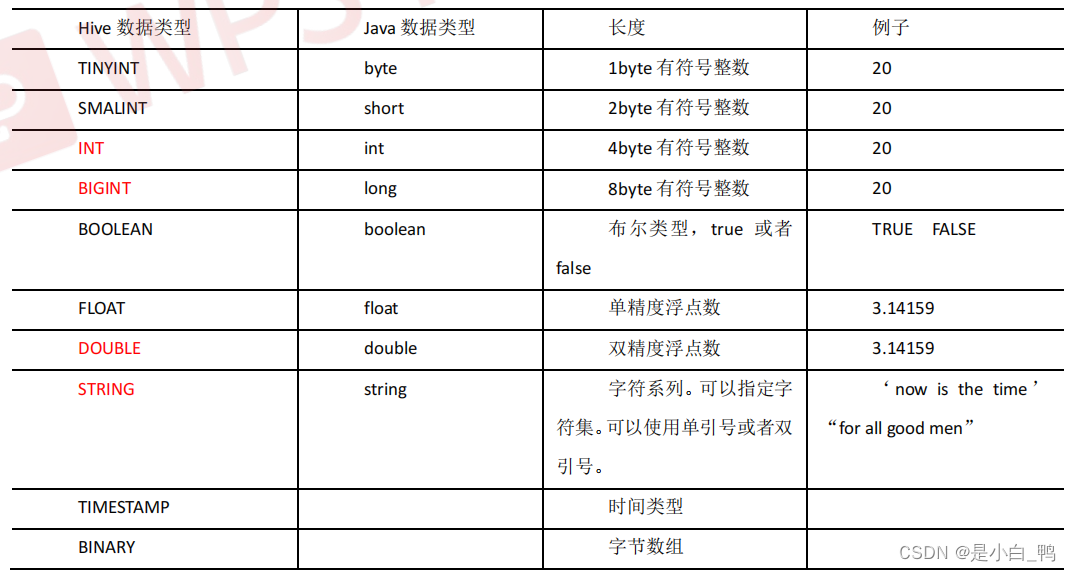
复合数据类型
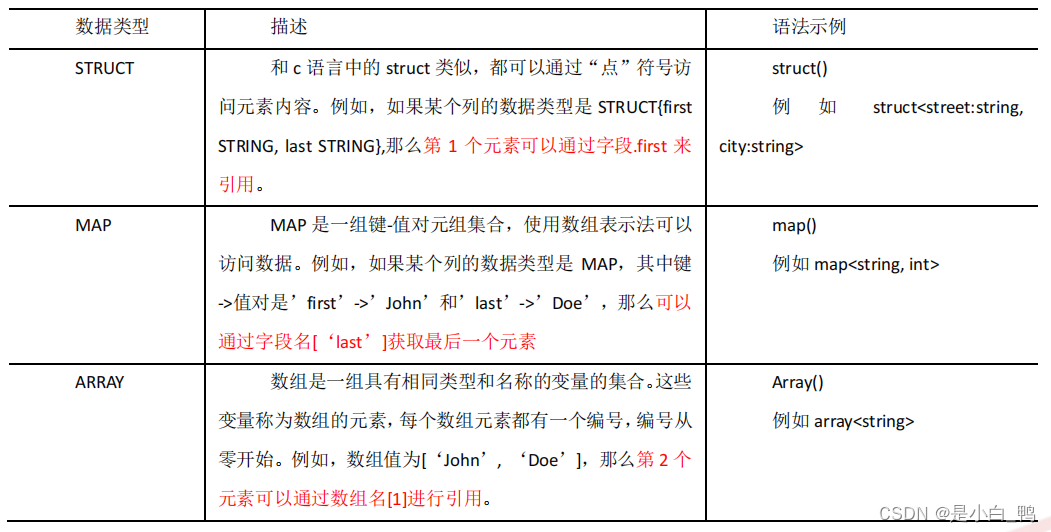
text 不是
-
Hive 内外表
建表时如果不显示声明表的类型为 外表 -
Kafka 通过()避免任务重复执行
对每个Producer分配唯一ID -
雪花模型比星型模型更适合于多维分析 ?不确定,应该是对的
-
HDFS中的block默认保存
3份 -
LSM的含义是
日志结构合并树 -
HIve实现连续排序,相同值并列排名
dense_rank()
速记
row_number() over(): 123
dense_rank() over(): 112
rank() over(): 113 -
Hive存储格式是列存储的有哪些
orc(列式存储)、parquet(列式存储)
速记
textfile(行式存储) 、sequencefile(行式存储)、orc(列式存储)、parquet(列式存储) -
属于TCP/IP协议应用层是有
HTTP、FTP、SMTP、POP3 等协议
SQL
题目描述
求每个部门的用户访问量Top3
输入
visit_log
| user_id | shop |
|---|---|
| u1 | a |
| u1 | a |
| u1 | b |
| u2 | a |
| u2 | a |
| u2 | b |
| u3 | a |
| u3 | a |
| u3 | a |
| u3 | b |
| … | … |
目标
| shop | user_id | cnt |
|---|---|---|
| a | u3 | 3 |
| a | u1 | 2 |
| a | u2 | 2 |
| b | u1 | 1 |
| b | u2 | 1 |
| b | u3 | 1 |
| … | … |
解答
with tmp as(select shop, user_id, count(*) cntfrom visit_log), tmp2 as(select shop, user_id, cnt, row_number() over(partition by shop order by cnt desc) rnfrom tmp)select shop, user_id, cntfrom tmp2where rn <= 3group by shoporder by cnt desc;
解析
tmp 表统计每个部门的用户访问量
tmp2 表添加伪列排序
然后再筛选前三即可
题目分享
Hive 精选选择题





![[Leetcode学习-C语言]Two Sum](http://pic.xiahunao.cn/[Leetcode学习-C语言]Two Sum)







收发数据(三))

)


