文章目录
- 一、概念入门
- 1. 概念简介
- 2. DDD的核心理念
- 3. 范式
- 4. 模型
- 5. 框架
- 6. 方法论
- 7. 软件设计的主要活动
- 二、DDD核心理论
- 1. Domain领域层都包含什么?
- 2. 聚合、实体和值对象
- 3. 仓储,封装持久化数据
- 4. 适配(端口),调用外部接口
- 5. 事件,触发异步消息
- 6. 领域服务,实现约定
一、概念入门
1. 概念简介
DDD是领域驱动设计(Domain-Driven Design)的缩写,这是一种主要软件开发方法,由Eric Evans在它的书《领域驱动设计:软件核心负责性应对之道》中首次提出。DDD主要关注于创建与业务领域紧密相关的软件模型,以确保能够准确地解决实际问题。
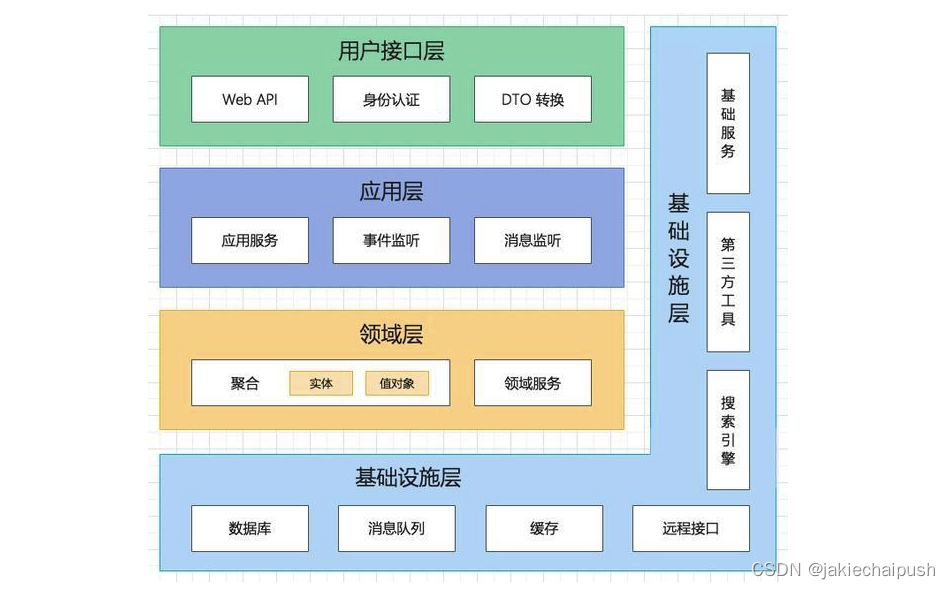
2. DDD的核心理念
- 领域模型(Domain Model)
领域模型是对特定业务领域知识的精确表示,它包括了业务中的实体(Entities)、值对象(Value Objects)、服务(Services)、聚合(Aggregates)、聚合根(Aggregate Roots)等概念。领域模型是DDD的核心,它反映了业务专家的语言和决策。
- 统一语言(Ubiquitous Language):
统一语言是开发团队和业务专家之间共同使用的语言,它在整个项目中保持一致。统一语言确保所有人对业务概念有着相同的理解,减少沟通成本和误解。
- 限界上下文(Bounded Context)
限界上下文是明确界定的系统边界,在这个边界内部有一套统一的模型和语言。不同的限界上下文之间可能有不同的模型,它们通过上下文映射来进行交互和集成。
- 聚合(Aggregate)
聚合是一组相关对象的集合,它们被视为数据修改的单元,每个聚合都有一个聚合根,它是外部对象与聚合内部对象交互的唯一入口。
- 领域服务
当某些行为不自然属于任何实体或值对象时,这些行为可以被定义为领域服务,领域服务通常表示领域中一些操作或业务逻辑。
- 应用服务
应用服务是软件的一部分,它们协调领域对象来执行任务。它们负责应用程序的工作流程,但不包含业务规则和知识。
- 基础设施
基础设施包括为领域模型提供持久化机制(如数据库)、消息传递、应用程序配置等技术组件
- 领域事件
领域事件是领域中发生的有意义的业务事件,它们可以触发其他子系统的反应和流程。
DDD的目标是通过将软件的关注点集中在核心领域上,并通过丰富的领域模型来管理复杂性,从而提高软件的质量和维护性。DDD强调与业务专家的紧密合作,以确保软件解决方案能够准确反映业务需求。通过这种方法,软件开发团队可以创建更加灵活、可扩展且与业务紧密结合的系统。
其中DDD所提到的软件设计方法涵盖了:范式、模型、框架、方法论,主要活动包括建模、测试、工程、开发、部署、维护。
软件设计方法是指一系列用于指导软件开发过程的原则、概念和实践,这些方法通常包括范式、模型、框架、方法论。下面一一介绍:
3. 范式
范式是指软件设计和开发的基本风格和哲学。它通常定义了编程的基本原则和模式。常见的软件设计范式包括:
- 结构化编程:强调程序结构的重要性,使用顺序、选择和循环控制结构
- 面向对象编程:基于对象的概念,将数据和处理数据的方法封装到一起
- 函数式编程:将计算视为函数的评估,避免状态改变和可变数据
- 事件驱动编程:以事件为中心,响应用户操作、消息或其他系统事件
4. 模型
模型是对软件系统的抽象表示,用于帮助理解、设计和测试系统。常用的软件设计模型包括:
- UML统一建模语言:一套图形化的建模语言,用于描述、设计和文档化软件项目
- ER模型:用于数据库设计,描述数据的实体及其之间的关系
- 状态机模型:描述系统可能的状态、事件和这些事件发生时的转换
5. 框架
框架是一套预先定制的代码和组件,用于提供软件开发的骨架。框架通常定义了应用程序的结构,提供了一组通用的功能和模式,以便开发者可以专注于实现特定的业务逻辑。
- Spring Framework
- Ruby on Rails:一个用于快速开发web应用程序的Ruby框架
- Django:一个高级的Python Web框架
6. 方法论
方法论是指一套指导软件开发过程的规则和实践。它包括项目管理、开发流程、团队协作等方面。常用的软件开发方法论如下:
- 敏捷开发:一种迭代和增量的开发方法,强调灵活性和客户合作
- Scrum:一种敏捷开发框架,用于管理复杂的软件和产品开发
- 瀑布模型:一种线性顺序的开发方法,将项目分为不同阶段,每个阶段完成后进入下一个阶段
7. 软件设计的主要活动
软件设计的主要活动包括:
- 建模:通过创建模型来表示系统的不同方面,如使用UML图来描述系统架构
- 测试:确保软件的质量,包括单元测试、集成测试、系统测试和验收测试
- 工程:应用工程原则和实践来构建软件,包括需求分析、设计、实现和测试
- 开发:编写代码和实现功能,将设计转换为实际的软件产品
- 部署:将软件发布到生产环境,使其可供用户使用
- 维护:对软件发布后对其进行更新和改进,修复缺陷,提升性能和适应性
每个活动都是软件开发生命周期的重要组成部分,它们相互依赖,共同确保软件项目的成功。
二、DDD核心理论
1. Domain领域层都包含什么?
在DDD中,领域是指具体业务领域的知识、业务逻辑、数据以及业务规则的集合。它是软件要解决问题的业务环境,通常由一系列子领域组成,每个子领域代表一个业务中的一个特定的部分。它包括以下特性:
- 业务中心:领域是围绕业务需求和业务规则构建的,它是软件设计的核心
- 模型驱动:领域模型是对业务知识的抽象,它通过领域实体、值对象、服务、聚合等概念来表示
- 语言一执性:领域模型的构建基于统一语言,这是开发团队和业务专家共同使用的语言,确保沟通无歧义
- 边界清晰:领域模型定义了清晰的边界,这些边界划分了不同的子领域和聚合,有助于管理复杂性和维护性
领域的用途主要包括下面三种:
- 业务逻辑和封装:领域模型封装了业务逻辑,使得业务规则和数据操作集中管理,便于理解和维护。
- 沟通工具:领域模型作为开发团队于业务专家之间的共同语言,有助于提高沟通效率,确保软件开发紧密跟随业务需求
- 软件设计的基础:领域模型是软件设计的基础,它指导着软件的架构和实现
领域模型的实现手段如下:
- 实体(Entity):具有唯一标识的领域对象,代表业务中的实体
- 值对象(Value Object):描述领域中的一些特性和概念,没有唯一标识,通常是不可变的
- 聚合(Aggregate):一组相关实体和值对象的集合,它们一起构成了一个数据和业务规则的单元
- 领域服务(Domain Service):在领域模型中执行特定业务逻辑的无状态服务,通常操作多个实体或聚合
- 领域事件(Domain Event):表示领域汇总发生的重要业务事件,用于解耦系统的不同部分
- 仓储(Repository):提供对聚合根的持久化操作,如保存和检索,通常于数据库交互
- 领域适配器(Domain Adapter):领域适配器是
适配器模式在DDD的应用,他的目的是使的领域模型能够与外部系统或技术细节进行交互,而不受到污染 - 工厂(Factory):用于创建复杂的聚合或实体,封装创建逻辑。
通过上面介绍的手段,DDD使的软件设计更加贴近业务需求,提高了软件的质量和维护性。开发团队可以更好的理解业务逻辑,从而设计出更加健壮和灵活的系统。
2. 聚合、实体和值对象
在领域驱动设计中,领域模型是和核心概念之一。领域模型是对现实世界中业务领域的抽象,它包含了业务领域聚合、实体和值对象等概念。
- 聚合对象
聚合是一组相关对象的集合,它们一起形成一个单一的单元。聚合是领域模型中一个关键概念,它是一组具有内聚性的相关对象的结合,这些对象一起工作以执行某些业务规则和操作。聚合定义了一组对象的边界,这些对象可以被视为一个单一的单元进行处理。
关键:聚合那实现事务一致性、聚合外实现最终一致性
聚合对象有如下特性:
一致性边界:聚合确保内部对象的状态变化是一致的,当对聚合那的对象进行操作时,这些操作必须保持聚合内所有对象的一致性
根实体:每个聚合都有一个根实体,它是聚合的入口点。根实体拥有一个全局唯一的标识符,其他对象通过根实体与聚合交互
事务边界:聚合也定义了事务的边界,在聚合内部,所有的变更操作都是原子的,即它们要么全部成功要么全部失败,以此来保证数据的一致性
聚合对象的用途有如下几种:
封装业务逻辑:聚合通过将相关对象和操作封装在一起,提供了一个清晰的业务逻辑模型,有助于业务规则的实施和维护
保证一致性:聚合确保内部状态的一致性,通过定义清晰的边界和规则,聚合在内部强制执行业务规则,从而保证数据的一致性
简化复杂性:聚合通过组织相关的对象,简化了领域模型的复杂性,有助于开发者更好的理解和扩展系统
聚合的实现手段如下:
定义聚合根:选择合适的聚合根是实现聚合的第一步。聚合根是能够代表整个聚合的实体,并且拥有唯一的标识
限制访问路径:只能通过聚合根来修改聚合内的对象,不允许直接修改聚合内部对象的状态,以此来维护边界的一致性
设计事务策略:在聚合内部实心啊事务一致性,确保操作要么全部成功要么全部回滚。对于聚合之间的交互,可以采用领域事件或其他机制来实现最终一致性
封装业务规则:在聚合内部实现业务逻辑和规则,确保所有的业务操作都遵循这些规则
持久化:聚合根通常与数据持久化层交互,以保持聚合的状态,这通常涉及到对象-关系映射(ORM)或其它数据映射技术。
通过上面这些手段,DDD的聚合模型能够帮助开发者构建出既符合业务需求又具有良好架构设计的软件系统。
上面的概念直接理解还是有点晦涩,下面通过一个案例来分析我们如何在DDD中实现一个聚合。在这个例子中,我们将创建一个简单的订单系统,其中包含订单聚合和订单项作为内部实体。订单聚合根将封装所有的业务规则,并通过聚合根进行所有交互。
首先我们定义实体和值对象:
//实体基类
public abstract class BaseEntity{//订单idprotected Long id;public Long getId(){return id;}
}//值对象基类
public abstract class ValueObject{//值对象通常是不可变的,所以没有setter方法
}
然后我们定义订单项作为实体:
public class OrderItem extends BaseEntity{//商品名称private String productName;//商品数量private int quantity;//商品价格private double price;public OrderItem(String productName, int quantity, double price){.....构造方法}//getter和setter方法.....
}
下面我们定义聚合根
public class OrderAggregate extends BaseEntity{//所有的订单集合private List<OrderItem> orderItems;//顾客昵称private String customerName;//订单是否支付了private boolean isPaid;//构造方法...//聚合根里面需要封装具体的业务规则//业务规则:订单未支付时才能添加订单项目public void addItem(OrderItem item){if(!isPaid){orderItems.add(item);}else{throw new IllegalStateException("订单项已经支付了无法添加");}}//业务规则:获取订单的总价格public double getTotalAmount(){return orderItems.stream().mapToDouble(OrderItem::getTotalPrice).sum;}//业务规则:订单总金额大于0时才能支付public void markAsPaid(){if(getTotalAmount()>0){isPaid=true;}else{throw new IllegalStateException("Order total must begreate than 0 to bepaid");}}//省略getter和setter方法
}
最后我们可以创建一个订单系统,并添加一些订单项
public class OrderDemo{//下面就是订单支付的整个业务流程public static void main(String[] args){//创建聚合订单OrderAggregate orderAggregate=new OrderAggregate("Jackiechai");//添加订单项目orderAggregate.addItem(new OrderItem("手机",1,1000.00);//获取订单总金额System.out.println("Total amout:"+orderAggregate.getTotalAmount());//标记订单已支付orderAggregate.makeAsPaid();}}
上面例子我们展示了如何在DDD中定义聚合根和实体,并且如何封装业务规则。订单聚合根(Order)确保了订单项的一致性,并且只有通过绝好根才能修改订单的状态。这个例子还展示了如何在聚合内部实现事务一致性,例如订单只能在订单未支付时候添加,订单必须有一个大于0的总金额才能标记为支付。
- 实体
实体在领域驱动设计中同样是一个核心概念,用于标识具有唯一标识的领域对象。实体=唯一标识+状态属性+行为动作,是DDD中的一个基本构建模块,它代表了具有唯一标识的领域对象,实体不仅仅包含数据(状态属性),还包括了相关的行为(功能),并且它的标识在整个生命周期中保持不变。
实体具有以下特性:
唯一标识:实体具有一个可以区别其他实体的标识,这个标识符可以是一个ID、一个复合键或者是一个自然键,关键是它能唯一的标识实体实例
领域标识:实体的标识来源于业务领域,例如用户id、订单ID等,这些标识符在业务上有特定的含义,并且在系统中唯一
委派标识:在某些情况下,实体的标识可能是由ORM框架自动生成的,如数据库自增键,这种标识虽然可以唯一标识一个实体,但是它并不直接来源于业务领域
实体的用途主要有以下几种:
表达业务概念:实体用于在软件中表达具体的业务概念,如用户、订单、交易等。通过实体的属性和行为,可以描述这些业务对象的特征和能力
封装业务逻辑:实体不仅仅承载数据,还封装了业务的逻辑和规则,这些逻辑包含验证数据的有效性、执行业务规则、计算属性值等。这样做的目的是确保业务逻辑的几种和一致性
保持数据的一致性:实体负责维护自身的状态和数据一致性。它确保自己的属性和关联关系在任何时候都是正确和完整的,从而避免数据的不一致性。
实现实体的手段如下:
定义实体类:在代码中定义一个类,该类包含实体的属性、构造函数和方法等
实现唯一标识:为实体类提供一个唯一标识的属性,如ID,并确保在实体的生命周期中这个标识保持不变
封装行为:在实体类中实现业务逻辑方法,这些方法主要是用于操作实体的状态,并执行相关的业务规则
使用ORM框架:利用ORM框架,将实体映射到数据库表中,这样可以简化数据持久化操作
实现领域服务:对于跨实体或跨聚合的操作,可以实现领域服务来处理这些操作,而不是在实体中直接实现
使用领域事件:当实体的状态发生变化时,可以发布领域事件,这样可以通知其他部分的系统进行相应的处理
通过上述手段,实体在DDD架构中扮演着重要的角色,它不仅代表了业务概念,还封装了业务逻辑,并通过唯一标识确保了数据的一致性。
我们同样用一个案例来展示如何在DDD中实现一个实体,我们将创建一个User实体,它代表一个用户,具有唯一的用户ID、姓名和电子邮件,并且可以执行一些基本的行为。
//user实体
public class UserEntity{//实体唯一的标识符private final String UUIDid;//user的属性状态private String name;private String email;//构造函数用于创建实体实例.....//实体的行为方法:例如更新用户姓名public void updateName(String newName){//可以在这里添加业务规则,例如验证新姓名是否合理this.name=name;}//实体的行为方法:例如更新用户的电子邮件......//getter方法.......//实体的equals和hashcode方法,基于唯一标识符实现@Overridepublic boolean equals(Object o){//判断引用是否相等if(this==0) return true;if(o==null || getClass()!=o.getClass()) return false;UserEntity user=(UserEntity)o;return id.equals(user.id);}@Overridepublic int hashCode(){return Objects.hash(id);}
}
上面就是一个充血模型
在这个例子中,User类代表了用户实体,它有一个唯一的标识符id,这个标识符在实体的整个生命周期中保持不变。name和email是用户的状态属性,updateName是封装了业务逻辑的行为放啊否。equals和hashCode方法基于唯一标识符实现,以确保实体的正确比较和散列。
- 值对象
在DDD中,值对象是一个核心概念,用于封装和标识领域中的概念,其特点是他们描述了领域中的某些属性或度量,单部具有唯一标识。值对象=值+对象,用于描述对象属性的值,表示具体固定不变的属性值信息。值对象是由一组属性组成的,它们共同描述了一个领域概念。与实体不同,值对象不需要唯一标识符来区分它们。值对象通常是不可变的,这意味着一旦创建,它们的状态就不应该改变。
值对象有如下特性:
不可变性:值对象一旦被创建,它的状态就不应该发生变化。这有助于保证领域模型的一致性和线程安全性
等价性:值对象的等价性不是基于身份或引用,而是基于值对象的属性值。如果两个值对象的所有属性值相同,那么就认为这两个值对象是等价的
替换性:由于值对象是不可变的,任何需要改变值对象的操作都会导致创建一个新的值对象实例,而不是修改现有的实例
侧重于描述事务状态:值对象通常用于描述事务的状态,而不是事务的唯一身份
可复用性:值对象可以在不同的领域实体或其他值对象中重复使用
值对象有如下用途:
金额和货币(例如价格、工资、费用等)
度量和数据(如重量、长度和体积等)
范围和区间(如日期范围,温度区间等)
复杂的数学模型(如坐标、向量等)
任何其他需要封装的属性集合
值对象的实现手段如下:
定义不可变类:确保类的所有属性都是私有的,并且只能通过构造函数来设置属性值
重写equals和hashcode方法:这样可以确保值对象的等价性是基于它们的属性值,而不是对象的引用
提供只读访问器:只提供获取属性值的方法,不提供修改属性值的方法
使用工程方法或者构造方法创建实例:这有助于确保值对象的有效性和一致性
考虑序列化的支持:如果值对象需要在网络上传播,需要提供序列化和反序列化支持
下面给出了值对象的例子:
//枚举类它的每一个实例都是一个单例。由于单例的特性,枚举类不能有任何构造函数。枚举类的所有实例必须在枚举类的定义内显式列出,并且它们默认都是public static final的。
public enum OrderStatusVo{//枚举类的四个实例PLACED(0,"下单");PAID(1,"支付");COMPALETED(2,"完成");CNACELLED(3,"退单");private final int code;private final String description;OrderStatusVo(int code, String description){....}//get方法....//根据code获取对应的OrderStatuspublic static OrderStatusVOfromCode(int code){for(OrderStatusVO status: OrderStatusVO.values()){if(status.getCode==code{return status;}else{throw newIllegalArgumentException("Invalid code for OrderStatus:"+code);}}}
}
在这个例子中,OrderStatusVo是一个美剧类型的值对象,它封装了订单状态的代码描述。并且提供了机遇属性值的等价性,通过定义一个枚举,我们可以确保订单状态的值是受限的,并且每一个状态都有一个明确的含义。
3. 仓储,封装持久化数据
Repository(仓储)模式是一种设计模式,它用于将数据访问逻辑封装起来,使的领域层可以通过一个简单、一致的接口来访问聚合根和实体对象。这个模式的关键在于提供了一个抽象的接口,领域层通过这个接口于数据存储层进行交互,而不需要知道背后的实现细节。
仓储具有以下特性:
封装持久化操作:仓储复杂封装所有与数据源交互的操作,如创建、读取、更新和删除(CRUD)操作。这样,领域层的代码可以避免直接处理数据库或其他存储机制的复杂性。
领域对象的集合管理:仓储通常被视为领域对象的集合,提供了查询和过滤这些对象的方法,使的领域对象的获取和管理更加方便
抽象接口:仓储定义了一个与持久化机制无关的接口,这使的领域层代码可以在不同的持久化机制之间切换,而不需要修改业务逻辑
仓储的用途如下:
数据访问抽象:仓储为领域层提供了一个清晰的数据访问接口,使的领域对象可以专注于业务逻辑实现,而不是数据访问的细节
领域对象的查询和管理:仓储使对领域对象的查询和管理变得更加方便和灵活,支持复杂的查询逻辑
领域逻辑于数据存储分离:通过仓储模式,领域逻辑于数据存储就分离了,提高了领域模型的纯粹性和可测试性
优化数据访问:仓储实现可以包含数据访问的优化策略,如缓存、批处理操作等,以提高应用程序的性能。
在实践中,仓储模式通常通过以下方式实现:
定义Repository接口:在领域层定义一个或多个仓储接口,这些接口声明了所需的数据访问方法
实现Repository接口:在基础设施层或数据访问层实现这些接口,具体实现可能是使用ORM框架,如Mybatis等,或者直接使用数据库访问API,如JDBC
依赖注入:在应用程序中使用依赖注入来将具体的仓储实现注入到需要它们的领域服务或应用服务中。这样做可以进一步解耦领域层和数据访问层,同时也便于单元测试
使用规范模式:有时候,为例构建复杂的查询,可以结合使用规范模式,这是一种运行将业务规则封装为单独的业务逻辑单元的模式,这些单元可以被仓储用来构建查询
下面的案例实现了在DDD架构中实现仓储模式。这个例子我们创建了一个简单的用户管理系统,其中包含用户实体和用户仓储接口,以及一个机遇内存的仓储实现。
首先我们定义一个用户实体:
public class UserEntity{private Long id;private String username;private String email;//构造函数、set方法和get方法
}
接下来,我们定义用户仓储的接口
public interface UserRepository{UserEntity findByid(Long id);List<UserEntity> findAll();void save(UserEntity user);void delete(UserEntity user);
}
然后我们提供一个基于内存的仓储实现:
public class InMemoryUserRepository implements UserRepository{private Map<Long, User> database=new HashMap<>();private AtomicLong idGenerator=new AtmicLong();@Overridepublic UserEntity findById(Long id){return database.get(id);}@Overridepublic List<UserEntity> findAll(){return new ArrayList<>(database.values);}@Overridepublic void save(UserEntity user){if(user.getId()==null){user.setId(idDenerator.incrementAndGet());}database.put(user.getId(),user);}@Overridepublic void delete(User user){database.remove(user.getId());}
}
最后我们可以在应用服务中使用这个仓储
public class UserService{private final UserRepository userRepository;....
}
这个例子就展示了仓储模式的基本结构和用法,在实际项目中,仓储的实现可能会连接到数据库,并使用ORM框架来处理数据持久化细节。此外,仓储接口可能会包含更复杂的查询方法,以支持各种业务需求。
4. 适配(端口),调用外部接口
在DDD上下文中,适配器(Adapter)模式扮演着至关重要的角色。适配器模式允许将不兼容的接口转换为另一个预期的接口,从而使原本由于接口不兼容而不能一起工作的类可以协同工作,在DDD中,适配器通常与端口概念结合使用,形成端口和适配器架构,也称为六边形架构。这种架构目的是将应用程序的核心逻辑与外部世界的交互耦合。端口在这种架构中代表类应用程序的一个入口或出口。它定义了一个与外部世界交互的接口,但不关心具体的实现逻辑。端口可以是驱动端口(输入端口)或被驱动端口(输出端口)。
端口的特性:
抽象性:端口提供了服务行为的抽象描述,明确了服务的功能和外部依赖
独立性:端口独立于具体实现,运行服务实现的灵活替换和扩展
灵活性:可以为同一端口提供不同的适配器实现,一适应不同的运行环境和需求
端口的用途:
标准定义:端口和适配器定义了服务的标准行为和外部依赖,提高了代码的可读性和可维护性
隔离定义:当外部系统发生变化的时候,只需要更换或修改适配器,无需改动核心业务逻辑
促进测试:可以使用模拟适配器来测试核心逻辑,而不依赖真实的外部系统
端口的实现步骤:
定义端口:在领域层定义清晰的接口,这些接口代表了应用程序和外部世界的交互点
创建适配器:在基础层或应用成实现适配器,这些适配器负责将端口的抽象操作转换为具体的外部调用
依赖倒置:应用程序的核心逻辑依赖于端口接口,而不是适配器的实现,这样是适配器可以随时被替换,而不影响核心逻辑
配置和组装:在应用程序启动时,根据需要将适配器和相应的端口连接起来
下面的案例就介绍了如何在DDD中实现适配器。这个例子中,我们将创建一个简单的支付系统,其中包含一个支付端口和适配器,该适配器负责调用外部支付服务的接口:
首先定义一个支付端口,它是一个接口,描述了支付服务应该提供的操作:
public interface PaymentPort{boolean processPayment(double amount);
}
接下来创建一个适配器,实现了支付端口,并负责调用外部支付服务的接口:
public class ExtenalPaymentService{public boolean makePayment(double amount){//这里是外部支付服务的具体调用逻辑System.out.println("calling external payment service for amount:"+amount);//假设总是支付成功return true;}
}public class PaymentAdapter implements PaymentPort{private ExternalPaymentService externalPaymentService;public PaymentAdapter(ExternalPaymentService externalPaymentService){//构造函数}@Overridepublic boolean processPayment(double amount){//调用外部支付接口return externalPaymentService.makePayment(amount);}
}现在我们可以在应用程序的核心逻辑中使用支付端口,而不依赖适配器的具体实现,这样,如果将来需要更换外部支付服务,我们只需要提供一个新的适配器实现即可:
public class PaymentService{private PaymentPort paymentPort;public PaymentService(PaymentPort paymentPort){//构造函数}public void processUserPayment(double amount){if(paymentPort.processPayment(amount)){System.out.println("sucess");}else{System.out.println("faild");}}
}
5. 事件,触发异步消息
在DDD中,领域事件是一种模型,用于表示领域中发生的有意义的事件。这些事件对业务来说是重要的,并且通常表示领域状态的变化。适配器在这个上下文中扮演着将领域事件与系统其他部分或外部系统连接起来的角色。领域事件是DDD中的一个关键概念,它代表了领域中发生的一个具有业务意义的事件。这些事件通常是由领域实体或聚合根的状态变化触发的。领域事件不仅仅是数据的变化,它们还承载了业务上下文和业务意图。
它具有一下特性:
- 意义明确:领域事件通常具有明确的业务含义,例如“用户已下单”、“商品已支付”等。
- 不可变性:一旦领域事件被创建,它的状态就不应该被改变。这有助与确保事件的一致性和可靠性。
- 时间相关性:领域事件通常包括事件发生的时间戳,这有助于追踪事件的顺序和时间线
- 关联性:领域事件可能被特定的领域实体和聚合根相关联,者有助于完成事件上下文
- 可观察性:领域事件可以被其他部分的系统监听和响应,有助于实现系统间解耦
它具有一下用途:
- 解耦:领域事件可以帮助系统内部或系统间的不同部分解耦,因为它们提供了一种基于事件的通信机制
- 业务逻辑触发:领域事件可以触发其他业务逻辑的执行,例如推送消息(优惠券到账)、更新其他聚合或生成数据流式报告等
- 事件溯源:领域事件可以用于是心啊事件溯源,这是一种存储系统状态变化的方法,通过重放事件来恢复系统状态
- 集成:领域事件可以用于系统与外部系统集成,通过发布事件来通知外部系统领域中发生的变化
它的实现方式如下:
- 领域层
定义事件接口:创建一个或多个接口来定义领域事件的结构和行为
创建领域事件类:基于定义的接口,实现具体的领域事件类,包含必要的属性和方法
触发领域事件:在离领域逻辑中的适当位置,实例化并发布领域事件
- 基础层
实现领域接口:使用消息队列来实现领域事件发布和订阅
- 出发器层/接口层
监听领域事件消息:在系统的其他部分或外部系统中,监听领域事件并根据事件来执行相应的业务逻辑或集成逻辑
下面是一个简单案例,模拟JAVA事件消息,展示了如何在DDD架构中定义领域事件、发布事件以及如何通过适配器模式将事件传递给外部系统或服务。
首先我们定义一个领域事件接口和一个具体的领域事件类:
//领域事件接口
public interface DomainEvent{//事件发生的时间Date occurredOn();
}//领域事件类
public class OrderCreatedEvent implements DomainEvent{private final String orderId;private final Date occurredOn;public OrderCreatedEvent(String orderId){//构造函数...}@Overridepublic Date occurredOn(){return this.occurredOn;}public String getOrderId(){return orderId;}
}
接下来我们创建一个事件发布器接口和一个基于消息队列的实现:
public interface DomainEventPublisher{void publish(DomainEvent event);
}public class MessageQueueEventPublisher implements DomainEventPublisher{//模拟消息队列客户端private final MessageQueueClient messageQueueClient;//构造函数.....@Overridepublic void publish(DomainEvent event){//将领域事件转换为消息并发送给消息队列messageQueueClient.send(serialize(event));}private String serialize(DomainEvent event){return event.toString();}
}现在我们可以在领域逻辑中触发领域事件:
//领域服务
public class OrderService{private final DomainEventPublisher eventPublisher;//构造函数public void createOrder(String orderId){//创建订单业务逻辑....//创建并发布订单创建事件OrderCreatedEvent event=new OrderCreatedEvent(orderId);eventPublisher.publish(event);}}
现在我们可以外部系统实现一个适配器,它是消息队列的客户端,就可以来消费这些事件了。
public class ExternalSystemAdapter{private final MessageQueueClient messageQueueClient;public ExternalSystemAdapter(MessageQueueClient messageQueueClient){this.messageQueueClient=newssageQueueClient;//假设这里有个方法来监听消息队列messageQueueClient.onMessage(this::onEventReceived);}private void onEventReceived(String message){//处理接受到的事件消息.....}}
6. 领域服务,实现约定
在DDD的上下文中,领域服务是一种封装了特定领域操作的服务。它是实现领域模型中的业务逻辑的一种手段,特别是当这些逻辑不属于任何一个实体或值对象时。领域服务通常用于是心啊跨越多个实体或值对象的行为,或者是那些不适合放在单个实体中的操作。
它具有以下特性:
- 领域逻辑的封装 :领域服务封装了领域特定的业务逻辑,这些逻辑通常涉及多个领域对象的交互,这种封装有助于保持实体和值对象的职责单一和清晰
- 无状态:领域服务通常是无状态的,它们不保存任何业务数据,而是操作领域对象来完成业务逻辑。这有助于保持服务的可重用性和可测试性。
- 独立性:领域服务通常与特定的实体或值对象无关,它们提供了一种独立于领域模型的其他部分的方式来实现业务规则
- 重用性:领域服务可以被不同的应用请求重用,例如不同的应用服务编排或领域事件处理器
- 接口清晰:领域服务的接口应该清晰的反映其提供的业务能力,参数的返回值应该是领域对象或基本数据类型
它的主要用途如下:
- 当一个操作不属于任何一个实体或值对象时
- 当一个操作需要协调多个实体或值对象时
- 当实现某个业务规则需要访问基础设施层(如数据库、外部服务等),可以通过领域服务来抽象这些操作,保持领域模型的纯粹性
它的实现方式如下:
- 设计原则和模式
通过使用设计原则(如单一职责原则、开闭原则)和设计模式(工厂、策略、模版、组合、责任链)对功能逻辑进行解耦,可以提高领域服务的灵活性和可维护性
- 功能拆分
不应该只定义一个service接口,然后在实现类下编写所有的逻辑,相反,应该对功能进行子包的拆分,以保持领域服务的职责清晰和管理易于维护
- 依赖抽象
领域服务应该依赖于抽象而不是具体的实现,这意味着领域服务应该通过接口或外部资源(如数据库、外部API)交互,而不是依赖于具体的实现。这样可以提高领域服务的可测试性和灵活性
- 协作和编排
领域服务可能需要与其他的领域服务协作以完成复杂的业务操作,在这种情况下,应该设计清晰的协作和编排机制,以确保业务逻辑的正确性和一致性。
领域服务实践建议:在设计领域服务时应遵循下面的这些建议:
- 识别领域服务:在设计领域模型时,应该识别出那些不自然属于任何实体或值对象的行为,并将这些行为抽象为领域服务。这通常设计到对业务规则的深入理解和分析。
- 界限清晰:确保领域服务的职责界限清晰。领域服务不应该变成大杂烩,承担过多的职责。每个领域服务应该专注于一个具体的业务能力或一组紧密相关的业务行为。
- 依赖注入:使用依赖注入来管理领域服务的依赖关系。这有助于保持领域服务的可测试性,并使其更容易与其他组件集成
- 事务管理:虽然领域服务不直接管理事务,但它们可能会参与到事务的操作中,在这种情况下,应该确保领域服务的操作可以与外部事务机制协同工作
- 测试和验证:领域服务应该通过单元测试和集成测试,这有助于验证领域服务的行为符合预期,并确保在重构或扩展下不会破坏现有功能
下面结合一个案例,分析如何在DDD中实现领域服务,假设我们有一个银行应用程序,其中包含账户实体和转账的领域服务。
首先我们定义账户实体:
public class Account{private String id;private BigDecimal balance;//构造函数....public String getId(){return id;}public BigDecimal getBalance(){return balance;}public void debit(BigDecimal amount){if(balance.caompareTo(amount)<0){//抛出异常}balance=balance.subtract(amount);}public void credit(BigDecimal amount){balance=balance.add(amount);}}
接下来,我们定义转账领域服务:
public class TransferService{private final AccountRepository accountRepository;public TransferService(AccountRepository accountRepository){//构造函数}public void transfer(String fromAccountId,String toAccountId, BigDecimal amount){Account fromAccount=accountRepository.findById(fromAccountId);Account toAccount=accountRepository.findById(toAccountId);if(fromAccount==null || toAccount==null){//抛出异常}fromAccount.debit(amout);toAccount.credit(amount);accountRepository.save(fromAccount);accountRepository.save(toAccount);}
}
然后我们定义账户仓库接口(仓储):
public interface AccountRepository{Account findById(String id);void save(Account account);
}
最后,我们在应用服务层使用转账领域服务:
public class BankingApplicationService{private final TransferService transferService;//构造函数public void handleTransferRequest(String fromAccountId,String toAccountId,BigDecimal amount){//这里可以添加额外的应用逻辑,如验证、权限检查、事务管理等transferService.transfer(fromAccountId,toAccountId,amount);}}






)


)


)



)


