目录
一 缓存穿透问题
二 缓存击穿问题
三 缓存雪崩问题:
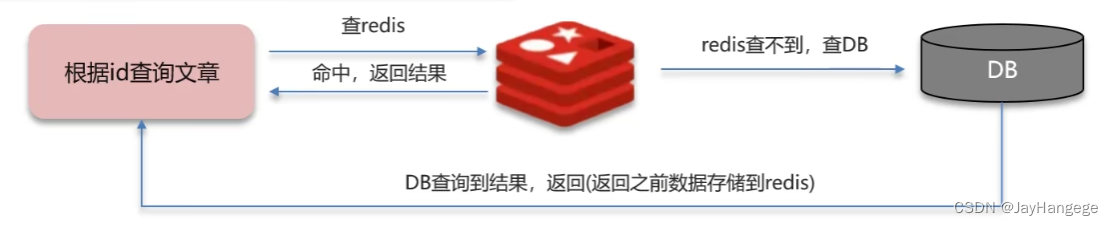
图1 正常的Redis缓存流程
一 缓存穿透问题
我们都知道Redis是一个存储键值对的非关系型数据库,那么当用户进行查询的时候,势必会从前端发起请求,从而数据从Redis缓存中进行查找,查找不到则会在数据库中进行查找。
那么此时就会出现一个问题,就是当有人恶意访问不存在的key时,此时Redis的缓存中没有该值,那么就会一致把请求发送到数据库中。当大量出现上述情况时,此时数据库的负载就会过大,从而发生缓存穿透的问题。
解决方案:
要解决上述问题,一般会使用布隆过滤器或者缓存null值的方法,来避免数据库被攻击。首先我们来讲讲布隆过滤器。

图2 布隆过滤器(详情请查看 布隆过滤器详解Blog)
布隆过滤器是搭建在访问Redis服务器之前的,布隆过滤器就是在请求到达Redis之前过滤掉一些Redis缓存中不存在的请求。

图3 位图
首先,请求访问Redis时会携带要访问的key值,此时布隆过滤器会使用不同的hash函数对该key进行哈希,并且存储在位图中,假如每一位都对上了,那么就说明Redis中存在该key那么就可以访问Redis服务器,否则就会直接返回null,从而避免了Redis缓存穿透的问题。
当然,布隆过滤器也会有缺点,就是出现误判的问题,如下图
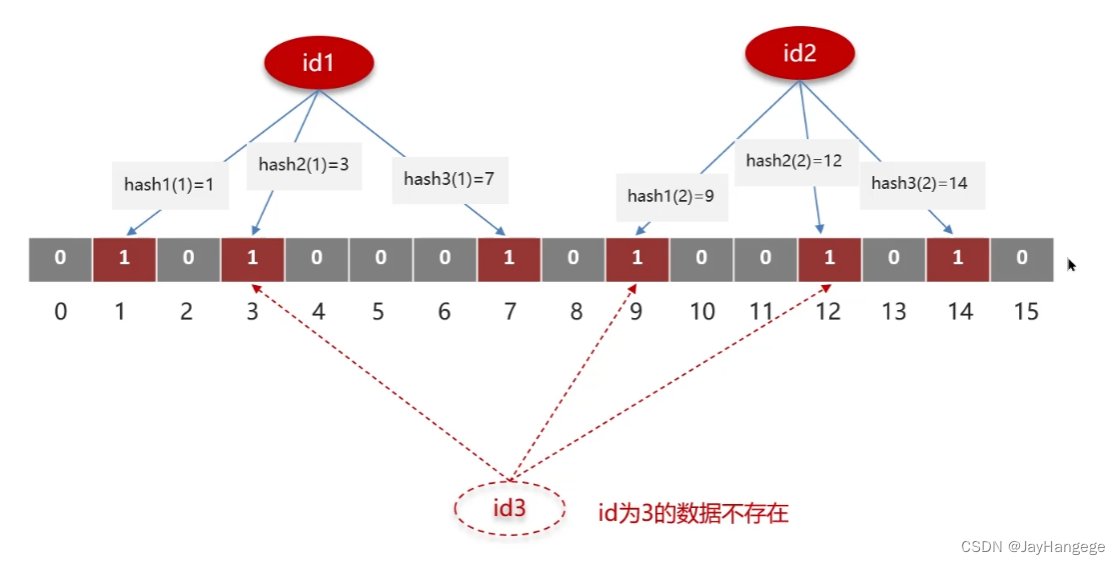
图4 不同的id误判情况
id=3的数据是不存在的,但是经过不同的hash之后发现,对应的位置恰好为1,那么此时就会出现误判的问题。解决方法当然有,就是增加位图的长度,长度越长误判率就越小,但是此时也出现了额外的内存消耗。当布隆过滤器判断一个元素不存在时,就说明该元素是真的不存在,但是判断存在的时候,也不一定存在。
第二个方法就是在Redis中直接缓存key:null这个键值对,一般时间会设置到5分钟左右,从而避免数据库的压力。当然这样的方式就有些简单粗暴了。
二 缓存击穿问题
当一个热点的key被多个用户频繁访问时,此时如果该key处于过期并且重建的过程中,那么会面临多个请求一起发送到数据库的情况,那么此时就会对数据库造成极大的负载,此时就出现了缓存击穿的问题。

图 5 缓存击穿
针对该问题也有两种方案进行解决,互斥锁和逻辑过期
互斥锁:
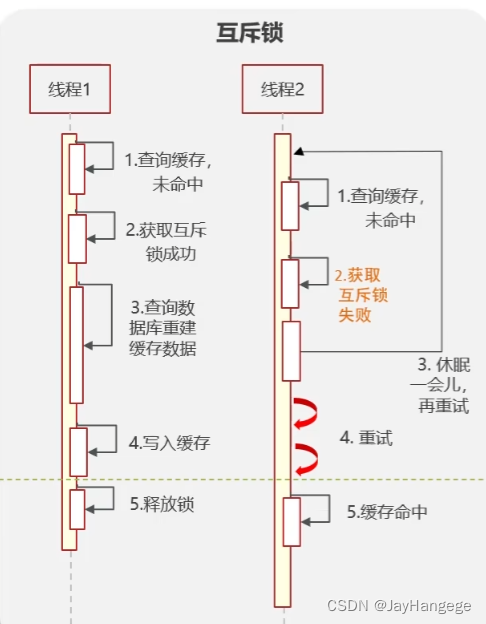
图 6 互斥锁
互斥锁是通过对多个线程进行加锁操作从而避免缓存击穿问题的。大致流程如下:
1.当线程1查询缓存时,如果缓存未命中,那么此时就会获取到一把锁,然后去数据库中进行查询数据并且试图重建缓存。
2.线程2也刚好访问该key,它也想拿到锁对数据库进行查询,但是获取锁失败了,就休眠一会再试。
3.当线程1完成一系列操作以后,重建了缓存,此时线程2也可以获取到Redis新建的缓存,那么此时就缓存命中了,就避免了与数据库直接交互的过程,也就避免了缓存击穿的问题。
第二个方法就是逻辑过期
就是将热点的key不设置过期时间。
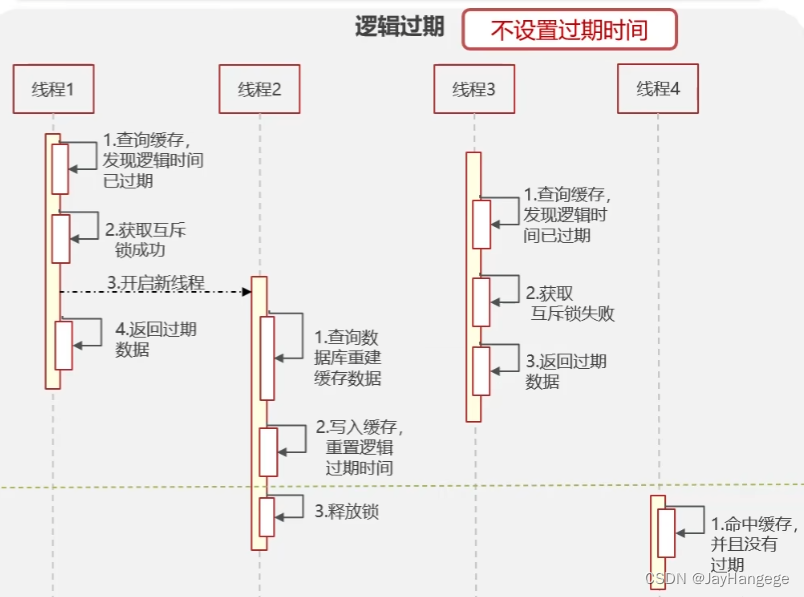
图 7 逻辑过期
如图:
1.当线程1查询数据时,会获取到互斥锁,然后返回过期数据
2.但是在此之间它还会开启一个新的线程2来重建缓存,重置逻辑过期时间
3.当线程2重写缓存时,线程3刚好来访问,那么线程3会返回一个过期的数据
4.当线程4来访问的时候,因为是在线程2释放锁之后进行的,所以线程4获取的是新的数据。
这就是逻辑过期的原理。
看到这里,其实肯定有疑问,为什么我不选择互斥锁,而选择逻辑过期呢?
其实这还和使用场景有关系,比如说,当写转账,或者京东,淘宝这种秒杀逻辑时,就需要数据的强一致性,那么就需要使用互斥锁,但是一些其他的场景,则有可能用历史的数据就可以完成。那么逻辑过期就可以解决这个问题。主要还是具体场景具体用法。
三 缓存雪崩问题:
听起来名字很可怕,雪崩,但是其实也是由于大量缓存的key同时失效或者Redis服务器宕机所带来的问题,请求会直接到达数据库,从而产生巨大的压力。
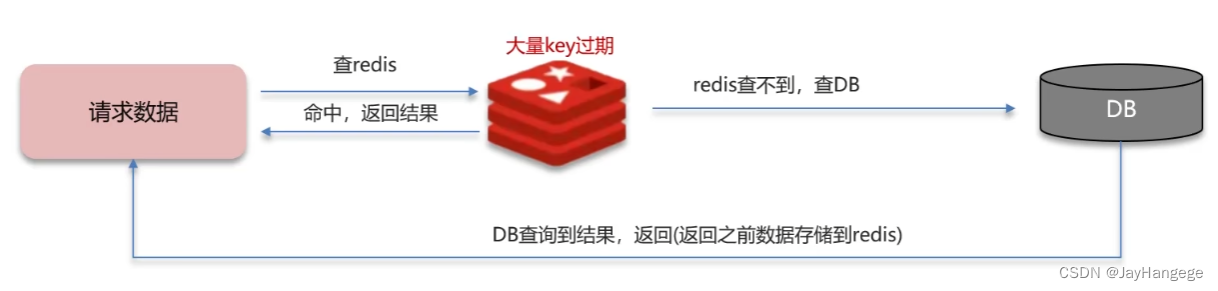
图8 缓存雪崩
解决方案:
1.给不同的key添加所及的TTL值:可以让不同的key不会同时达到过期时间。
2.利用Redis集群来提高服务的可用性:比如哨兵模式,主从模式等等
3.给缓存业务添加降级限流策略(系统保底策略。可以解决上面提到的三个问题)
4.添加多级缓存
-上线)




)




)




)



