每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/

语音识别中的可理解性评估:超越词错误率的意义保留
在自动语音识别(ASR)模型的评估中,词错误率(WER)及其逆值词准确率(WACC)是衡量句法准确性的常用指标。然而,这些指标未能反映ASR性能的一个关键方面:可理解性。这种局限性在针对具有非典型言语模式的用户时尤为明显,他们的WER往往超过20%,在某些情况下甚至超过60%。尽管如此,如果ASR模型能较好地保留其言语的意义,这些用户仍能从中受益。这在实时对话、语音输入文本信息、家庭自动化等对语法错误容忍度较高的应用中尤为重要。实际上,这些用户和应用场景最能从保留意义的ASR模型中获益,因为它们能显著改善交流。
WER的局限性与意义保留的重要性
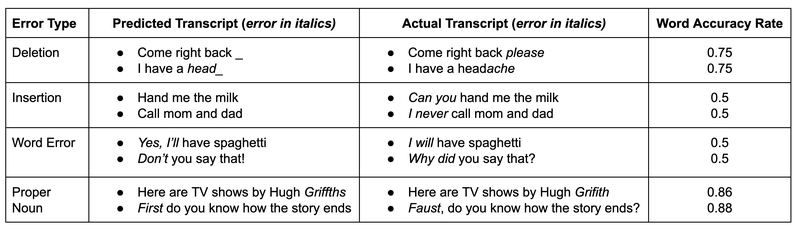
尽管WER和WACC可以衡量语音识别的句法准确性,但它们并不总能准确反映转录错误的严重性。以下是一些示例,展示了WACC如何未能准确反映转录错误的严重性。在两个例子中,尽管WACC相似,第一个例子的错误相对无害,而第二个例子的错误则更为严重。
创建意义保留评估系统
为了解决这一问题,开发了一种新系统,以自动评估ASR模型有效传达用户意图的能力。在论文《利用大型语言模型评估语音转录的可理解性》(ICASSP 2024)中,介绍了一种新方法,使用大型语言模型(LLM)来确定转录是否准确捕捉了与参考文本相比的预期意义。基于这一方法,还报告了使用Gemini模型如何在不显著损失性能的情况下使用更小的模型,并在无需额外训练的情况下实现多语言意义评估。
意义保留作为替代指标
研究利用了Project Euphonia语料库,这是一个包含约2000名具有各种言语障碍的个体超过120万条语句的语料库。为了扩展对西班牙语使用者的数据收集,Project Euphonia与ALS/MND国际联盟合作,收集了来自墨西哥、哥伦比亚和秘鲁ALS患者的语音样本。同样,通过与巴黎脑科学研究所的Romain Gombert合作,Project Euphonia扩展到法国,收集了法国非典型言语者的数据。
在实验中,生成了4731个包含真实值和转录错误对的示例数据集,并附有人类标注,指示这些对是否保留了意义。将数据集分为训练集、测试集和验证集(分别为80% / 10% / 10%),确保三个数据集在真实语句级别上没有重叠。
训练与评估
在基础LLM上训练了意义保留分类器。通过提示微调(一种参数高效的LLM适应方法),将基础LLM调整为能够预测“是”或“否”的标签,以指示是否保留了意义。

在推理过程中,没有生成响应,而是获取LLM的logits作为两个类别标签(“是”和“否”)的分数。可以选择得分较高的标签,或在评估意义保留分类器时,使用“是”类别的得分。
使用Gemini进行意义保留评估
尽管在PaLM模型上取得的结果令人鼓舞,但最近AI模型的巨大进步激励评估其在此任务中的适用性。重新训练了意义保留分类器,现在使用Google的Gemini作为基础LLM。对于许多相关的用例,这一评估任务最好使用小模型(例如用于设备上的应用)。因此,选择了Google的Gemini小版本(Gemini Nano-1,具有1.8B参数,详见Gemini 1.0技术报告)进行更高效的推理,其参数量不到最初使用的PaLM 62B模型的3%。在意义保留测试集上评估时,微调后的Gemini Nano-1表现非常竞争,AUC ROC得分为0.88,尽管其规模较小。
多语言意义保留评估
还创建了法语和西班牙语的意义保留测试集,作为Project Euphonia扩展数据收集工作的一部分。这些测试集基于收集的语句、说话者言语障碍的严重程度和病因学的元数据,以及从Google的高度多语言通用语音模型(USM)获得的真实转录和ASR转录。
西班牙语测试集由来自六名说话者的518个示例组成,而法语测试集由来自十名说话者的199个示例组成。对于两种语言,不同说话者具有不同的病因学和言语障碍程度,包括轻度、中度和重度。
基于Gemini Nano-1模型的意义保留分类器在法语和西班牙语测试集上获得了约0.89的ROC AUC性能。鉴于该分类器仅用英文示例进行训练,这一结果相当显著。由于基础Gemini模型的多语言能力,这些能力在无需重新训练模型或创建新语言的训练数据集的情况下得以显现。
结论
提出使用意义保留作为比WER更有效的ASR系统评估指标,特别是在高错误率的情况下,如非典型言语和其他低资源领域或语言。通过关注意义保留,可以更好地评估模型对个体用户的有用性,尤其是在Project Relate等助听技术中,这些技术旨在通过训练完全个性化的语音识别模型使非典型言语者得到更好的理解。
为了进一步推进意义保留工作,并将其惠及更多用户和语言,还探索了Google Gemini模型的能力。Gemini Nano-1使能够在使用显著较小模型的情况下实现类似的分类器性能。尽管仅在英文示例上训练,分类器显示出在其他语言中准确评估意义保留的能力,如法语和西班牙语的测试所示。这一激动人心的发展为构建更高效、更通用的模型开辟了新的可能性,使更多用户受益。
表达式(3)PAYLOAD EXPRESSIONS)



)
及同类型软件介绍)










)


