文章目录
- cut
- 参数
- 指定范围
- 命令
- awk
- 参数
- 内置变量
- 命令
- wc
- 参数
- 命令
- uniq
- 参数
- 命令
- sort
- 参数
- 命令
- head
- 参数
cut
参数
| 选项 | 含义 |
|---|---|
| -b | 仅显示行中指定直接范围的内容 |
| -c | 仅显示行中指定范围的字符 |
| -d | 指定分割符, 默认为“TAB”制表符 |
| -f | 显示指定字段的内容 |
| -n | 与“-b”连用,不分割多字节字符 |
| –complement | 补足被选择的字节,字符或字段 |
| –out–delimiter=<字段分割符> | 指定输出内容是的字段分割符 |
指定范围
N-:从第N个字节、字符、字段到结尾;
N-M:从第N个字节、字符、字段到第M个(包括M在内)字节、字符、字段;
-M:从第1个字节、字符、字段到第M个(包括M在内)字节、字符、字段。
对应选项:
-b 表示字节;
-c 表示字符;
-f 表示定义字段
命令
cat test
NAME GENDER HEIGHT(cm) MONTH SALARY
zhao male 150 1 1000
qian female 165 0 500
zhou male 155 5 3000
zheng female 167 4 3400
wang male 158 3 8000
cut test -c1,3
cut test -b1,3
NM
za
qa
zo
ze
wn
cut -c1-3 test
cut -b1-3 test
NAM
zha
qia
zho
zhe
wan
cut -f1-3 test
NAME GENDER HEIGHT(cm)
zhao male 150
qian female 165
zhou male 155
zheng female 167
wang male 158
cut -c1-3 --complement test
E GENDER HEIGHT(cm) MONTH SALARY
o male 150 1 1000
n female 165 0 500
u male 155 5 3000
ng female 167 4 3400
g male 158 3 8000
cut -f3- --complement test
NAME GENDER
zhao male
qian female
zhou male
zheng female
wang male
cut -b3- --complement test
NA
zh
qi
zh
zh
awk
参数
awk [选项参数] 'pattern1{action1} pattern2{action2}...' filename
-F:指定输入文件拆分隔符。
-v:赋值一个用户定义变量。
-f:引入awk执行脚本。读入有’\n’换行符分割的一条记录,然后将记录按指定的域分隔符划分域,填充域,$0则表示所有域,$1表示第一个域,$n表示第n个域,$NF表示文本行中的最后一个数据字段。默认域分隔符是"空白键" 或 “[tab]键”
内置变量
| 变量 | 说明 |
|---|---|
| FILENAME | awk浏览的文件名 |
| NR | 已读的记录数 |
| NF | 浏览记录的域的个数 |
命令
cat test
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
awk -F: '/^root/{print $7}' test
/bin/bash
^在root前,表示以指定字符开头,如果没有,则表示有指定字符的行,位置不限
awk -F: '/^root/{print $1","$7}' test
root,/bin/bash
awk -v i=1 -F: '{print $3+i}' test
1
2
3
4
5
6
7
8
awk -F : -f a test
root 0 /bin/bash
bin 1 /sbin/nologin
daemon 2 /sbin/nologin
adm 3 /sbin/nologin
lp 4 /sbin/nologin
sync 5 /bin/sync
shutdown 6 /sbin/shutdown
halt 7 /sbin/haltcat a
{print $1,$3,$NF}
awk -F : 'BEGIN{print "user, shell"} {print $1","$7} END{print "coleak,/bin/xixixi"}' test
user, shell
root,/bin/bash
bin,/sbin/nologin
daemon,/sbin/nologin
adm,/sbin/nologin
lp,/sbin/nologin
sync,/bin/sync
shutdown,/sbin/shutdown
halt,/sbin/halt
coleak,/bin/xixixi
awk -F: '{print "filename:" FILENAME ", linenumber:" NR ",columns:" NF}' test
filename:test, linenumber:1,columns:7
filename:test, linenumber:2,columns:7
filename:test, linenumber:3,columns:7
filename:test, linenumber:4,columns:7
filename:test, linenumber:5,columns:7
filename:test, linenumber:6,columns:7
filename:test, linenumber:7,columns:7
filename:test, linenumber:8,columns:7
awk '/^$/{print NR}' test
查询test中空行所在的行号
awk 'NR==3{print $0}' test
输出test第3行的所有数据
awk -F: '$1=="root"{print $0}' test
输出第一个字段为root所在的行
head -2 /proc/meminfo | awk 'NR==1{a=$2}NR==2{b=$2;print (a-b)\*100/a "%"}'
查看已使用的内存
wc
参数
-l , --lines : 显示行数;
-w , --words : 显示字数;
-m , --chars : 显示字符数;
-c , --bytes : 显示字节数;
-L , --max-line-length : 显示最长行的长度;
命令直接执行,输出包含四项,分别代表:行数、字数、字节数、文件。
字数是指以空格、tab、换行分隔的非零长度字符。例子中每行属于一个字,所以输出10。
命令
wc test test2
8 8 293 test10 10 444 test218 18 737 总计
wc -l test
wc -w test
wc -m test
wc -c test
wc -L test
uniq
uniq命名用于比较相邻的行并去掉重复的行,对不相邻的行无效;如果使用该命令不加任何命令行参数,则视为删除文本文件中重复的行之后进行输出;如果指定输出文件,则删除到指定文件当中;
参数
-c:uniq的命令行参数,在每列旁边显示重复出现的次数;
-u:uniq的命令行参数,显示文件当中只出现一次的行
-d:uniq的命令行参数,显示文件当中重复的行
命令
cat test
root:x:0:0:root:/root:/bin/bash
root:x:0:0:root:/root:/bin/bash
root:x:0:0:root:/root:/bin/bash
adm:x:3:4:adm:/var/adm:/sbin/nologin
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
uniq test
root:x:0:0:root:/root:/bin/bash
adm:x:3:4:adm:/var/adm:/sbin/nologin
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
uniq test test3
输出内容放到test3
uniq test -c
3 root:x:0:0:root:/root:/bin/bash
1 adm:x:3:4:adm:/var/adm:/sbin/nologin
1 bin:x:1:1:bin:/bin:/sbin/nologin
1 daemon:x:2:2:daemon:/sbin:/sbin/nologin
2 adm:x:3:4:adm:/var/adm:/sbin/nologin
1 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
1 sync:x:5:0:sync:/sbin:/bin/sync
1 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
1 halt:x:7:0:halt:/sbin:/sbin/halt
uniq test -dc
3 root:x:0:0:root:/root:/bin/bash
2 adm:x:3:4:adm:/var/adm:/sbin/nologin
sort
参数
| 选项 | 说明 |
|---|---|
| -n | 依照数值的大小排序 |
| -r | 以相反的顺序来排序 |
| -t | 设置排序时所用的分隔字符 |
| -k | 指定需要排序的列 |
| -u | 在输出行中排序并去除重复行 |
| -o | 将排序结果写入文件中 |
- -f会将小写字母都转换为大写字母来进行比较,亦即忽略大小写
- -c会检查文件是否已排好序,如果乱序,则输出第一个乱序的行的相关信息,最后返回1
- -C会检查文件是否已排好序,如果乱序,不输出内容,仅返回1
- -M会以月份来排序,比如JAN小于FEB等等
- -b会忽略每一行前面的所有空白部分,从第一个可见字符开始比较。
命令
cat sort.txtbxmb:20:4.2
xfet:50:2.3
clsuh:10:3.5
sewp:30:1.6
xfam:50:2.3
xfet:50:2.3
sort sort.txt -t : -nrk 3
bxmb:20:4.2
clsuh:10:3.5
xfet:50:2.3
xfet:50:2.3
xfam:50:2.3
sewp:30:1.6
sort -t: -uk 1 sort.txt
bxmb:20:4.2
clsuh:10:3.5
sewp:30:1.6
xfam:50:2.3
xfet:50:2.3
sort -t: -rk 1.2 sort.txt
bxmb:20:4.2
clsuh:10:3.5
xfet:50:2.3
xfet:50:2.3
xfam:50:2.3
sewp:30:1.6
"-k 1.2"表示对第一个域的第二个字符开始到本域的最后一个字符为止的字符串进行排序。
sort -t: -rk 1.2,1.2 sort.txt -o sort2.txt
bxmb:20:4.2
clsuh:10:3.5
xfet:50:2.3
xfet:50:2.3
xfam:50:2.3
sewp:30:1.6
"-k 1.2,1.2"表示只对第一个域的第二个字符进行排序
head
参数
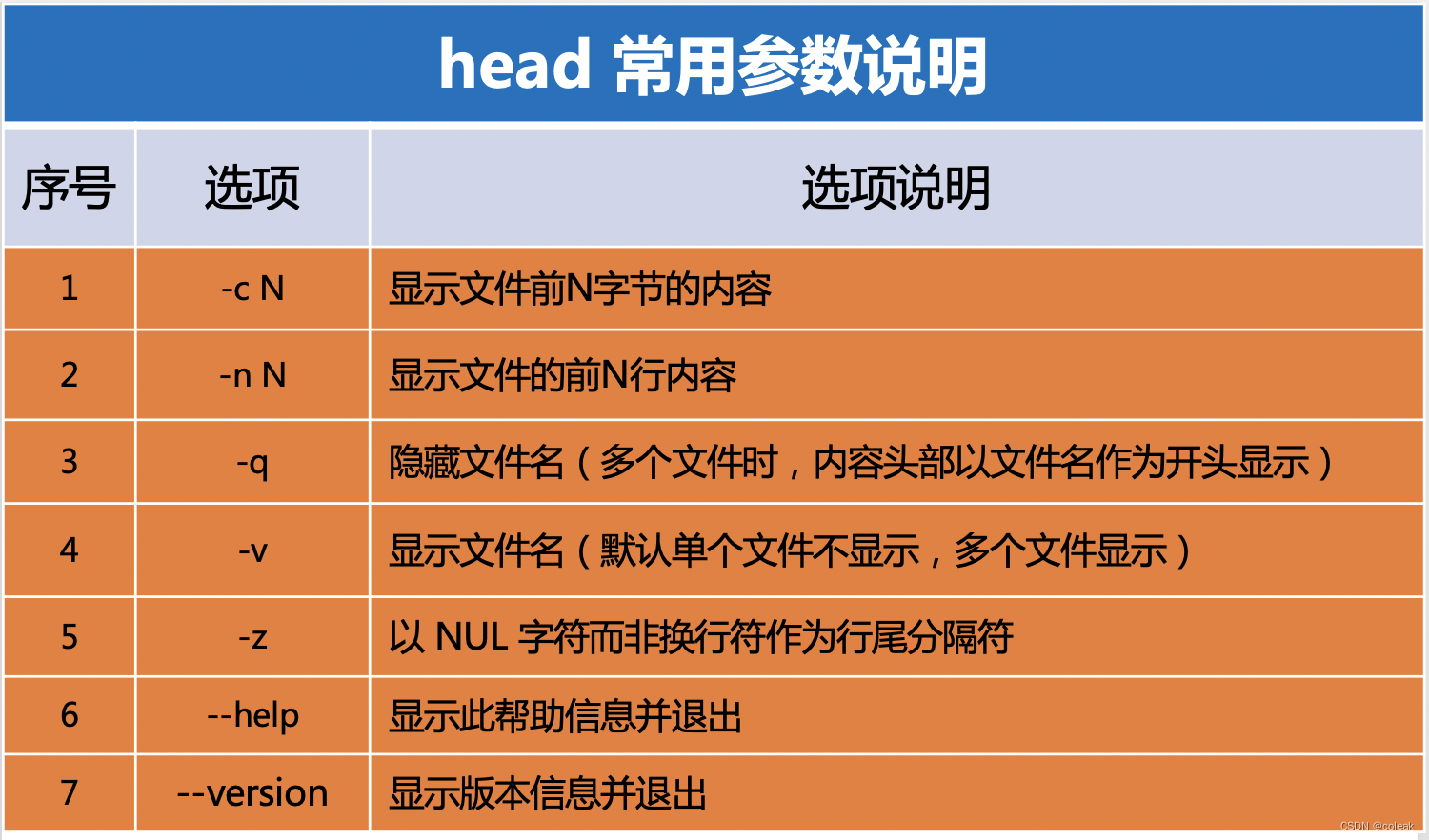
head -n 10 test
head -n -5 test #显示文件除了最后5行以外的全部内容
head -n -5 ./* -v


安装部署)









 — unrecognized opcode `csrr t0,mhartid‘报错问题)




-- gtfont - 高通字库芯片)
![[天翼杯 2021]esay_eval - RCE(disabled_function绕过||AS_Redis绕过)+反序列化(大小写wakeup绕过)](http://pic.xiahunao.cn/[天翼杯 2021]esay_eval - RCE(disabled_function绕过||AS_Redis绕过)+反序列化(大小写wakeup绕过))
)