1. 数据集和任务部分
SimVG用的六个数据集:RefCOCO/+/g, ReferIt, Flickr30K, and GRefCOCO
| 数据集名称 | 图像数量 | 参照表达式数量 | 参照对象实例数 | 语言特性 | 主要任务 |
|---|---|---|---|---|---|
| RefCOCO | 19,994 | 142,209 | 50,000 | 基于 MS COCO 图像,采用 ReferItGame 收集的指代表达数据集。表达通常简短,包含位置词,适用于实时交互场景 | 指代表达理解、分割、视觉指引 |
| RefCOCO+ | 19,994 | 141,564 | 50,000 | 在 RefCOCO 的基础上,禁止使用位置词,强调对象的外观/属性特征,挑战模型在无位置信息下的识别能力。 | 外观驱动的指代表达理解与分割 |
| RefCOCOg | 25,799 | 95,010 | 49,822 | 有两个分区(Google和umd),这里是由 Google split,表达更长,描述更详细,适合研究复杂关系建模和自然语言理解。 | 自然语言理解、复杂关系建模 |
| gRefCOCO | 19,994 | 278,232 | 60,287 | 部分单目标表达式继承自 RefCOCOg,支持单目标、多目标和无目标的表达,适用于泛化指代表达理解(GREC)和分割(GRES)任务。该数据集旨在提高模型在复杂表达下的泛化能力。 | 泛化指代表达理解与分割(GREC/GRES) |
| ReferIt/ReferItGame | 20,000+ | 130,525 | 96,654 | 早期的指代表达数据集,基于 SAIAPR TC-12 图像,表达自由,包含对背景和场景的描述。适用于区域定位和早期视觉指引研究 | 早期视觉指引、区域定位 |
| Flickr30K Entities | 31,783 | 158,000+ | 427,000 | 以短语作为语言查询,而不是完整的句子。在 Flickr30K 数据集的基础上,添加了实体标注和共指链,支持短语定位、图文对齐和多模态检索等任务。 | 短语定位、图文对齐、多模态检索 |
在RefCOCO和RefCOCO +遵循train / validation / test A / test B的拆分,RefCOCOg只拆分了train / validation集合。

The blue and red bounding boxes are correct and incorrect comprehension respectively, while the green boxes indicate the ground-truth regions.
蓝色和红色的边框分别表示正确和错误的理解,而绿色的边框则表示真实区域。

下图中,红色表示真实框,蓝色表示预测框

评测指标
Precision@0.5 [Prec@0.5]: 对于REC和短语定位,我们使用Precision@0.5评估性能。如果预测框与ground-truth框的IoU大于0.5,则认为预测是正确的。
Precision@(F 1 _1 1=1, IoU ≥ 0.5 \ge0.5 ≥0.5) [Prec@(F 1 _1 1=1, IoU ≥ 0.5 \ge0.5 ≥0.5)]: 计算在IoU阈值为0.5时F 1 _1 1得分为1的样本百分比。如果一个预测边界框与ground-truth边界框匹配且IoU ≥ 0.5 \ge0.5 ≥0.5,则认为它是TP。如果多个预测边界框与一个ground-truth边界框匹配,则只有IoU最高的那个被视为TP,其余的为FP。没有匹配预测边界框的ground-truth边界框为FN,而没有匹配ground-truth边界框的预测边界框为FP。样本的F 1 _1 1得分计算公式为F 1 _1 1 = 2 T P 2 T P + F N + F P \frac{2TP}{2TP+FN+FP} 2TP+FN+FP2TP。如果样本的F 1 _1 1得分为1,则认为样本被成功预测。对于没有目标的样本,如果没有预测边界框,则F 1 _1 1得分为1,否则为0。然后将成功预测样本的比例计算为Precision@(F 1 _1 1=1, IoU ≥ 0.5 \ge0.5 ≥0.5)。
N-acc: 无目标准确率 (N-acc) 评估模型识别没有目标的样本的能力。在一个无目标样本中,没有预测边界框为TP,否则为FN。N-acc计算公式为 T P T P + F N \frac{TP}{TP+FN} TP+FNTP,反映了模型在识别无目标样本方面的性能。
- 核心概念:框和重叠度
- Ground-truth box (真实框): 这是“正确答案”,是人工标记的指代实例位置的框。
- Predicted box (预测框): 这是模型推理后自己画出来的框。
- IoU (Intersection over Union,交并比): 这是衡量你的预测框画得有多准的关键。它计算的是你的预测框和真实框“重叠区域”的大小除以它们“总共占有的区域”的大小。
IoU = 重叠区域面积 总区域面积(预测框与真实框的并集面积) \text{IoU} = \frac{\text{重叠区域面积}}{\text{总区域面积(预测框与真实框的并集面积)}} IoU=总区域面积(预测框与真实框的并集面积)重叠区域面积
IoU 的值在 0 到 1 之间。IoU 越接近 1,说明你的预测框和真实框重叠得越多,画得越准。IoU 为 0 表示完全没有重叠,IoU 为 1 表示完全重合。
- Precision@0.5 [Prec@0.5]:以0.5重叠度为标准的准确率
- 这个指标关注的是模型“找对”的预测。
- 它设定了一个门槛:如果你的预测框和某个真实框的 IoU 大于 0.5,我们就认为这个预测是“正确的”(True Positive, TP 的一种判断标准)。你的框至少要和指代实例的实际位置有超过一半的重叠,才算你找到了。
- Precision@0.5 是衡量在这种“大于0.5重叠”的条件下,模型预测的准确程度。它通常可以理解为:在模型所有声称找到了指代实例的预测中,有多少是真正找到了(IoU > 0.5)。(虽然原文没有直接给出 Precision@0.5 的公式,但在检测任务中,通常是 TP / (TP + FP),这里的 TP 就是指 IoU > 0.5 的预测。)
- Precision@(F 1 _1 1=1, IoU ≥ 0.5 \ge0.5 ≥0.5) [Prec@(F 1 _1 1=1, IoU ≥ 0.5 \ge0.5 ≥0.5)]:以IoU ≥ 0.5 \ge0.5 ≥0.5为标准,F 1 _1 1得分为1的样本比例
- 这个指标更严格,它不只看单个预测是否正确,而是看整个样本(一张图片)的指代定位任务完成得有多好。
- 这里引入了 TP, FP, FN 来衡量整个样本的预测情况:
- TP (True Positive,真阳性): 模型成功找到并正确圈出了一个指代实例(预测框与真实框匹配且 IoU ≥ 0.5 \ge0.5 ≥0.5 )。如果一个真实框有多个预测框匹配,只算 IoU 最高的那个是 TP。
- FP (False Positive,假阳性): 模型圈了一个框,但那个位置根本没有指代实例(预测框没有匹配的真实框),或者它圈错了(匹配的真实框已经被更高 IoU 的预测框“认领”了)。这是“误报”。
- FN (False Negative,假阴性): 指代实例就在那里(有一个真实框),但模型没有找到它(没有预测框与它匹配)。这是“漏报”。
- F 1 _1 1 Score: 这是一个综合 Precision(准确率,衡量误报少不多)和 Recall(召回率,衡量漏报少不多)的指标。F 1 _1 1得分高意味着模型既少误报也少漏报。公式是 F 1 _1 1 = 2 T P 2 T P + F N + F P \frac{2TP}{2TP+FN+FP} 2TP+FN+FP2TP。
- F 1 _1 1 = 1: 意味着完美!TP 很高,而 FP 和 FN 都为 0。也就是说,模型找到了所有的指代实例,而且一个多余的、错的框都没有画。
- 指标含义: Precision@(F 1 _1 1=1, IoU ≥ 0.5 \ge0.5 ≥0.5) 计算的是:在所有图片中,有多少张图片模型能够完美地完成任务(即 F 1 _1 1 得分为 1,基于 IoU ≥ 0.5 \ge0.5 ≥0.5 的判断标准)。对于没有指代实例的图片,如果没有画任何框,F 1 _1 1 也算 1;如果画了框,F 1 _1 1 算 0。这个指标衡量的是模型在多大程度上能够在一个样本内做到“一个不漏,一个不错”。
- N-acc (No-target accuracy,无指代实例准确率):
-
这个指标专门关注那些图片中根本没有指代实例的情况。
-
模型的任务是识别出“这里什么都没有”。
-
这里的 TP 和 FN 定义针对的是“没有预测框”这个行为:
- TP (True Positive): 在一张没有指代实例的图片里,模型没有画任何框。这是正确的判断。
- FN (False Negative): 在一张没有指代实例的图片里,模型画了框。这是错误的判断(误以为有指代实例)。
-
指标含义: N-acc = T P T P + F N \frac{TP}{TP+FN} TP+FNTP。这计算的是在所有没有指代实例的图片中,模型成功判断出“没有指代实例”的比例。它衡量模型识别空白场景的能力。
-
Precision@0.5 看的是模型画出来的单个框有多大比例是有效地找到了目标(重叠度超过0.5)。
-
Precision@(F 1 _1 1=1, IoU ≥ 0.5 \ge0.5 ≥0.5) 看的是模型在多大比例的图片上能够完美地(既不漏也不错地,基于0.5重叠度)完成指代检测任务。这是一个更严格的整体任务完成度指标。
-
N-acc 专门评估模型在没有目标出现时,能否正确地判断出“什么都没有”。
其他实验细节
通用的模型描述:训练 SimVG,对于 REC(指代表达式理解)和短语定位任务,训练 30 个 epoch;对于 GREC 任务,训练 200 个 epoch。所有这些训练都使用批量大小为 32。遵循标准做法,图像被调整大小至 640×640,并且所有数据集的语言表达式长度都被截断至 20。对于预训练阶段,SimVG 训练 30 个 epoch,然后进行额外的 10 个 epoch 的微调。预训练实验在 8 块 NVIDIA RTX 3090 GPU 上运行。所有其他实验在 2 块 NVIDIA RTX 4090 GPU 上进行。
- 通用设置:
- 所有消融实验使用 512×512 尺寸的图像作为输入。
- 所有训练均不使用指数移动平均 (EMA) 策略。
- 基础模型 (SimVG-base):
- 通用的模型描述适用于 SimVG-base 模型。
- 蒸馏参数设置为 λ 1 = 2 \lambda_1 = 2 λ1=2 和 λ 2 = 1 \lambda_2 = 1 λ2=1。
- 大型模型:
- 由于内存使用量较高,所有大型模型都使用大小为 4 的批量进行训练。
- 解码器的投影输入维度从 768 增加到 1024。
- 其他设置(除批量大小、解码器维度和 epoch 数外)与基础模型保持一致。
- 蒸馏参数设置为 λ 1 = 1 \lambda_1 = 1 λ1=1 和 λ 2 = 0.4 \lambda_2 = 0.4 λ2=0.4。
- 训练 Epoch 数调整:
- ViT-B 两阶段蒸馏实验: 额外增加 20 个 训练 epoch。
- 大型模型预训练实验 (如表 3):
- 总训练 epoch 数从 30 减少到 20 (由于训练成本增加)。
- Token 分支蒸馏 epoch 数从 20 减少到 10。
- SimVG 不同变体的结果获取方式:
- SimVG-TB: 结果是通过在两阶段蒸馏过程中使用 DWBD 获得的。
- SimVG-DB: 结果是通过使用 ground truth 监督解码器分支 获得的。
- 特定实验设置:
- GREC 实验: 将对象查询 (Object Queries) 的数量设置为 10。
- 特别强调:
- 本文使用的 BEiT-3 预训练模型未在用于本研究验证的六个数据集上进行训练。
2. 方法部分
将图文理解与下游任务解耦
In this paper, we improve the performance of visual grounding by decoupling multi-modal fusion from downstream tasks into upstream VLP models
在本文中,我们通过将多模态融合从下游任务解耦到上游 VLP 模型中,提高了视觉 Grounding 的性能。
we re-examine the visual grounding task by decoupling image-text mutual understanding from the downstream task. We construct a simple yet powerful model architecture named SimVG, which leverages the existing research in multimodal fusion to fully explore the contextual associations between modalities
我们通过将图像-文本相互理解与下游任务解耦,重新审视了视觉定位任务。我们构建了一个简单而强大的模型架构,命名为 SimVG,它利用了多模态融合领域的现有研究,以充分探索不同模态之间的上下文关联。
-
多模态融合 (Multi-modal fusion): 这是指将不同模态(这里主要是图像和文本)的信息结合起来的过程。在视觉 Grounding 中,就是要融合图像内容和文本描述,以便理解文本指的是图像中的哪个物体。
-
下游任务 (Downstream tasks): 指的是我们最终要解决的特定问题,在这里就是视觉 Grounding 这个任务本身。模型的目标是根据图像和文本,输出目标物体的边界框。
-
上游 VLP 模型 (Upstream VLP models): VLP 是 Vision-Language Pre-trained Models 的缩写,即视觉-语言预训练模型。这些模型通常是在大量的图像-文本数据上进行预训练的,学习图像和文本之间的通用关系和表示。它们是“上游”的,因为它们的训练发生在具体的下游任务(如视觉 Grounding)之前。VLP 模型本身就已经具备了一定的多模态融合和理解能力。
-
解耦 (Decoupling): 指的是将本来紧密联系的两部分分开。在这里,就是把“多模态融合”这个能力,从“视觉 Grounding 这个具体任务的模型”中分离开来。
传统的视觉 Grounding 方法通常是在构建解决视觉 Grounding 任务的模型时,顺便在模型的某些层里面进行图像和文本的融合。这种融合是为了视觉 Grounding 这个特定任务而设计的,并且训练时主要依赖视觉 Grounding 数据集。
在论文中提出的 SimVG中则不是这样。它利用了已经预训练好的、强大的 VLP 模型(也就是“上游 VLP 模型 [64]”)本身就具备的多模态融合能力。换句话说,模型不再自己从零开始或者用有限的数据学习如何融合图像和文本,而是借用了上游 VLP 模型在大规模数据上学到的、更通用的融合能力。
通过这种方式,将多模态融合这个复杂的步骤,“解耦”出来,让它主要由强大的上游 VLP 模型来完成,而不是让下游的视觉 Grounding 模型自己负担这个任务。这样可以利用 VLP 模型在大规模预训练中获得的更强大和通用的多模态理解能力,从而提高视觉 Grounding 在处理复杂情况(比如长文本描述)时的性能。
就像是:
- 传统方法:找一个普通的工人,教他怎么同时看图和看文字来找东西(融合和下游任务是绑定的)。
- 新方法:找一个已经学会了如何很好地理解图片和文字关系的专家(上游 VLP 模型),然后让他在找东西这个具体任务上发挥这个能力(融合从下游任务中解耦出来,由专家来做)。
Unlike previous methods that guide a lightweight student model using a pre-trained teacher model, this paper introduces knowledge distillation during synchronous learning to enhance the performance of the lightweight branch.
与以往利用预训练教师模型指导轻量级学生模型的方法不同,本文在同步学习过程中引入了知识蒸馏,以提升轻量级分支的性能。
在机器学习(特别是在深度学习模型训练)的上下文中,“同步学习” (Synchronous Learning) 通常指的是 同时训练模型或模型的多个组成部分(例如,不同的分支或多个独立的模型),并且这些组成部分在训练过程中 以协调一致的方式进行更新或交互。
这种蒸馏方法与传统的顺序训练(比如,先完全训练一个模型,再用它的输出去训练另一个模型)不同,同步学习意味着多个部分是 一起、并行 地进行训练的。
“同步学习中的知识蒸馏” 意味着:
- 教师模型和学生模型(轻量级分支)是同时被训练的。参数更新是同步进行的,或者至少它们的训练过程是同时启动并进行的,且通过知识蒸馏信号相互影响。(其实作者也有采用两阶段的蒸馏方法,即也会预先训练一下教师模型)
- 在训练的每一步或每隔一定的步数,教师模型会将其知识(通常是其输出的概率分布,即软目标)传递给学生模型。
- 学生模型的损失函数在包含自身对真实标签的损失的同时,也包含了与教师模型输出之间的蒸馏损失。
The decoder is divided into two branches: one is similar to the transformer decoder in DETR (decoder branch), and the other utilizes a lightweight MLP (token branch). The head is referred to as the “Distillation Head”. Unlike conventional prediction heads, to reduce the performance gap between the token and decoder branches, we employ a dynamic weight-balance distillation (DWBD) to minimize the performance difference between the two branches during synchronous learning.
解码器被分为两个分支:一个类似于 DETR 中的 Transformer 解码器(称为解码器分支),另一个则使用轻量级 MLP(称为 token 分支)。头部被称为“蒸馏头”。与传统的预测头部不同,为了减少 token 分支和解码器分支之间的性能差距,我们在同步学习过程中采用了一种动态权重平衡蒸馏(DWBD)来最小化两个分支的性能差异。
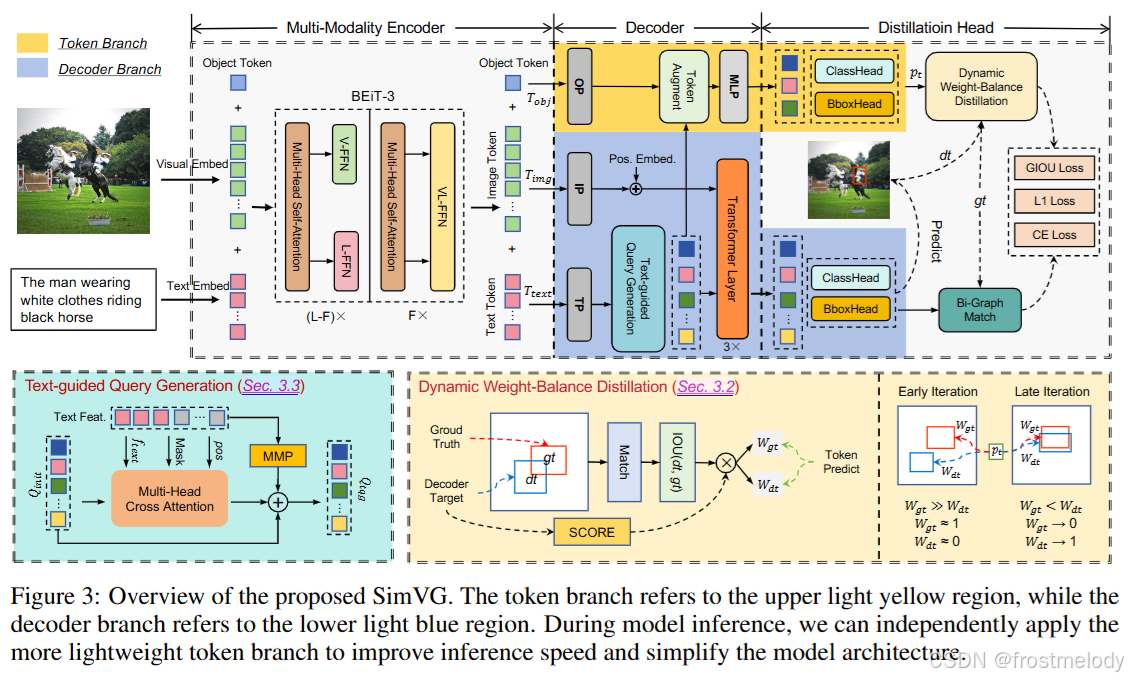
多模态编码器

多模态编码器: SimVG 的输入包括一个图像 I ∈ R 3 × H × W I \in \mathbb{R}^{3 \times H \times W} I∈R3×H×W 和一段描述文本 T ∈ Ω M = { t 1 , t 2 , . . . , t M } T \in \Omega^M = \{t^1, t^2, ..., t^M\} T∈ΩM={t1,t2,...,tM},其中 Ω \Omega Ω 表示词汇集合。首先,使用视觉嵌入将图像压缩到原始尺寸的 1/32,得到 P i m g = { p 1 , p 2 , . . . , p N } P_{img} = \{p^1, p^2, ..., p^N\} Pimg={p1,p2,...,pN}。然后将文本映射到向量空间 L t e x t = { l 1 , l 2 , . . . , l K } L_{text} = \{l^1, l^2, ..., l^K\} Ltext={l1,l2,...,lK} 和一个文本填充掩码 L m a s k = { l m 1 , l m 2 , . . . , l m K } L_{mask} = \{l^1_m, l^2_m, ..., l^K_m\} Lmask={lm1,lm2,...,lmK}。此外,我们定义一个可学习的对象 token T o b j T_{obj} Tobj 作为 token 分支的目标特征。Transformer 的 query 和注意力填充掩码可以生成为:
Query = { T o b j , p 1 , . . . , p N , l 1 , . . . , l K } \{T_{obj}, p^1, ..., p^N, l^1, ..., l^K\} {Tobj,p1,...,pN,l1,...,lK},Mask = { T o b j m , p m 1 , . . . , p m N , l m 1 , . . . , l m K } \{T_{obj_m}, p^1_m, ..., p^N_m, l^1_m, ..., l^K_m\} {Tobjm,pm1,...,pmN,lm1,...,lmK}。(1)
在图像没有填充的情况下, T o b j m T_{obj_m} Tobjm 和 { p m 1 , p m 2 , . . . , p m N } \{p^1_m, p^2_m, ..., p^N_m\} {pm1,pm2,...,pmN} 被设置为 0。在独立的编码部分,FFN 采用图像和文本模态之间不共享权重的设置,而其余部分与原始的 ViT 模型大致相同。
解码器分支,Token分支,蒸馏头

解码器分支: 我们首先使用一个不共享权重的线性层,映射图像 token T i m g ∈ R H 32 × W 32 × C T_{img} \in \mathbb{R}^{\frac{H}{32} \times \frac{W}{32} \times C} Timg∈R32H×32W×C 和文本 token T t e x t ∈ R N t e x t × C T_{text} \in \mathbb{R}^{N_{text} \times C} Ttext∈RNtext×C 的通道维度。然后,在文本侧,我们应用文本引导查询生成(TQG)模块,使预定义的对象查询 Q o b j ∈ R N o b j × C Q_{obj} \in \mathbb{R}^{N_{obj} \times C} Qobj∈RNobj×C 与文本 token 进行交互。在图像侧,应用额外的全局位置编码。最后,通过 Transformer 模块执行交叉注意力交互。整个过程可以表示为:
Q d e c o d e r = MCA ( IP ( T i m g ) + pos , TQG ( TP ( T t e x t ) , Q o b j ) ) Q_{decoder} = \text{MCA}(\text{IP}(T_{img}) + \text{pos}, \text{TQG}(\text{TP}(T_{text}), Q_{obj})) Qdecoder=MCA(IP(Timg)+pos,TQG(TP(Ttext),Qobj)),(2)
其中 TP 和 IP 指文本投影和图像投影。MCA 指多头交叉注意力。pos 指位置编码,它应用 2D 绝对正弦编码。
Token 分支: 我们采用一个线性层 OP 来投影对象 token T o b j ∈ R 1 × C T_{obj} \in \mathbb{R}^{1 \times C} Tobj∈R1×C,并使用 TQG 的结果来增强对象 token。最后,我们使用一个 MLP 层来进一步交互并丰富对象 token 的表示。这个分支的过程可以定义为:
Q t o k e n = MLP ( OP ( T o b j ) + TQG ( TP ( T t e x t ) , Q o b j ) ) Q_{token} = \text{MLP}(\text{OP}(T_{obj}) + \text{TQG}(\text{TP}(T_{text}), Q_{obj})) Qtoken=MLP(OP(Tobj)+TQG(TP(Ttext),Qobj))。(3)
蒸馏头: 我们对解码器分支采用与 DETR [2] 相同的匈牙利匹配。匹配成本包含三部分:二元交叉熵损失、L1 损失和 giou 损失 [54]。然而,为了进一步简化推理流程,我们在整个训练过程中使用解码器分支作为教师来指导 token 分支的学习。因此,完整的损失可以表示为:
L t o t a l = L d e t ( p d , g t ) + L d w b d L_{total} = L_{det}(p_d, gt) + L_{dwbd} Ltotal=Ldet(pd,gt)+Ldwbd, L d e t = λ 1 L c e + λ 2 L l 1 + λ 3 L g i o u L_{det} = \lambda_1 \mathcal{L}_{ce} + \lambda_2 \mathcal{L}_{l1} + \lambda_3 \mathcal{L}_{giou} Ldet=λ1Lce+λ2Ll1+λ3Lgiou,(4)
其中 λ 1 \lambda_1 λ1, λ 2 \lambda_2 λ2, 和 λ 3 \lambda_3 λ3 分别设置为 1, 5, 和 2。 p d p_d pd 指解码器分支的预测。 L d w b d L_{dwbd} Ldwbd 指动态权重平衡蒸馏损失,这将在下一部分解释。
Dynamic Weight-Balance Distillation(DWBD)


为了使 SimVG 同时具有效率和有效性,引入了知识蒸馏,它利用解码器分支的预测作为教师来指导 token 分支的预测。由于这两个分支共享多模态编码器的特征,使用传统的知识蒸馏方法独立训练教师模型是不可行的。取而代之的是,我们对两个分支采用了同步学习的方法。这种方法需要一个精妙的平衡,确保教师模型的性能不会受到影响,同时最大化知识从教师分支到学生分支的转移。
核心思想:
- 用一个更强的分支(解码器分支)来动态地指导一个更轻量的分支(token 分支)学习,让它们在同步训练中共同进步。
- 两个学生同时学习,一个学得比较快(解码器分支),另一个学得慢一些(token 分支)。DWBD 的目标就是让学得快的学生在学习过程中,也能去辅导学得慢的学生。两个分支共享前面的特征(多模态编码器)
- 作者希望轻量的 token 分支也能学好,最好能接近复杂解码器分支的性能。所以在它们一起训练时,需要一种机制让强的指导弱的。
DWBD 是怎么指导的?
- 引入一个特殊的损失项 L d w b d L_{dwbd} Ldwbd: DWBD 主要体现在总损失函数中多了一个 L d w b d L_{dwbd} Ldwbd 项。这个项专门用来衡量 token 分支的学习是否得到了有效的指导。
- 两种指导来源: L d w b d L_{dwbd} Ldwbd 并不是只让 token 分支模仿解码器的预测,它结合了两种信息:
- Token 分支预测 p t p_t pt 对比 解码器分支的“目标” ( d t dt dt) 的损失 L d e t ( p t , d t ) L_{det}(p_t, dt) Ldet(pt,dt)。这个“目标”是解码器分支通过匈牙利匹配的方式找到的与地面真实匹配后的预测结果,可以看作是解码器学习到的更精细、更接近目标的表示。
- Token 分支预测 p t p_t pt对比 地面真实 g t gt gt的损失 L d e t ( p t , g t ) L_{det}(p_t, gt) Ldet(pt,gt)。这是最直接的标准答案。
- 动态权重平衡(Dynamic Weight-Balance)是关键: DWBD 的名字就包含了“动态权重平衡”。它不是简单地将上面两种损失相加,而是给它们乘以动态变化的权重 ( W d t W_{dt} Wdt 和 W g t W_{gt} Wgt)。
- L d w b d = γ 1 ( W d t × L d e t ( p t , d t ) ) + γ 2 ( W g t × L d e t ( p t , g t ) ) L_{dwbd} = \gamma_1(W_{dt} \times L_{det}(p_t, dt)) + \gamma_2(W_{gt} \times L_{det}(p_t, gt)) Ldwbd=γ1(Wdt×Ldet(pt,dt))+γ2(Wgt×Ldet(pt,gt))
- W g t = 1 − W d t W_{gt} = 1 - W_{dt} Wgt=1−Wdt
- γ 1 \gamma_1 γ1 和 γ 2 \gamma_2 γ2 是固定的系数(论文里设为 2 和 1),用来调整两种损失项的整体比例。
因此,我们设计了一种动态权重平衡蒸馏(DWBD),其架构如图 3 所示。我们将地面真实(ground truth)记为 y i y_i yi,将 N q N_q Nq 个解码器预测集合记为 y ^ d = { y ^ i d } i = 1 N q \hat{y}^d = \{\hat{y}_i^d\}_{i=1}^{N_q} y^d={y^id}i=1Nq。为了在这两个集合之间找到二分匹配,我们寻找一个具有最低成本的、 N q N_q Nq 个元素的排列 σ ∈ Σ N q \sigma \in \Sigma_{N_q} σ∈ΣNq:
σ ^ = ARGMIN σ ∈ Σ N q ∑ i N q L match ( y i , y ^ σ ( i ) d ) \hat{\sigma} = \text{ARGMIN}_{\sigma \in \Sigma_{N_q}} \sum_{i}^{N_q} \mathcal{L}_{\text{match}}(y_i, \hat{y}_{\sigma(i)}^d) σ^=ARGMINσ∈ΣNq∑iNqLmatch(yi,y^σ(i)d),(5)
其中 L match ( y i , y ^ σ ( i ) d ) \mathcal{L}_{\text{match}}(y_i, \hat{y}_{\sigma(i)}^d) Lmatch(yi,y^σ(i)d) 是地面真实 y i y_i yi 与索引为 σ ( i ) \sigma(i) σ(i) 的预测之间的成对匹配成本。配对后,下一步是评估解码器分支在当前阶段的理解能力。这是通过衡量解码器目标 d t dt dt (解码器分支的预测中,与某个地面真实(ground truth, g t gt gt)目标成功匹配(paired)的那个预测结果。)和地面真实 g t gt gt 的联合目标框基于其配对的 IOU 的置信度来完成的:
W d t = 1 N g t ∑ i N g t [ IOU ( b t i , b σ ^ ( i ) d ) × SCORE ( p ^ σ ^ ( i ) d ) ] W_{dt} = \frac{1}{N_{gt}} \sum_{i}^{N_{gt}} [\text{IOU}(b_{ti}, b_{\hat{\sigma}(i)}^d) \times \text{SCORE}(\hat{p}_{\hat{\sigma}(i)}^d)] Wdt=Ngt1∑iNgt[IOU(bti,bσ^(i)d)×SCORE(p^σ^(i)d)],(6)
其中 N g t N_{gt} Ngt 是地面真实框的数量,SCORE 表示从预测中提取的前景得分。 W d t W_{dt} Wdt 可以看作当前阶段解码器分支能力的反映,值越高表示置信度越强。最后, L d w b d L_{dwbd} Ldwbd 可以表达为:
L d w b d = γ 1 ( W d t × L d e t ( p t , d t ) ) + γ 2 ( W g t × L d e t ( p t , g t ) ) L_{dwbd} = \gamma_1(W_{dt} \times L_{det}(p_t, dt)) + \gamma_2(W_{gt} \times L_{det}(p_t, gt)) Ldwbd=γ1(Wdt×Ldet(pt,dt))+γ2(Wgt×Ldet(pt,gt)), W g t = 1 − W d t W_{gt} = 1 - W_{dt} Wgt=1−Wdt,(7)
权重 ( W d t W_{dt} Wdt, W g t W_{gt} Wgt) 是如何动态变化的?
- 衡量解码器能力 W d t W_{dt} Wdt: W d t W_{dt} Wdt 是一个动态计算出来的数值,用来衡量解码器分支在 当前训练阶段 的能力或置信度。它是根据解码器的预测框与地面真实框的 IOU(交并比)和得分计算出来的。解码器预测得越准、得分越高, W d t W_{dt} Wdt 就越大,表示解码器当前能力越强,越值得信任。
- 权重的含义:
- W d t W_{dt} Wdt 越大,乘以它的项 ( W d t × L d e t ( p t , d t ) W_{dt} \times L_{det}(p_t, dt) Wdt×Ldet(pt,dt)) 的权重就越大,这意味着 token 分支更多地跟着 解码器目标 学习。
- W g t = 1 − W d t W_{gt} = 1 - W_{dt} Wgt=1−Wdt。 W d t W_{dt} Wdt 越大, W g t W_{gt} Wgt 就越小。这意味着 token 分支跟着 地面真实 学习的权重会变小。
- 动态调整的过程:
- 训练早期: 解码器分支刚开始训练,能力还比较弱, W d t W_{dt} Wdt 会比较小, W g t W_{gt} Wgt 会比较大。此时, L d w b d L_{dwbd} Ldwbd 主要侧重于 W g t × L d e t ( p t , g t ) W_{gt} \times L_{det}(p_t, gt) Wgt×Ldet(pt,gt) 这一项,即 token 分支主要依靠 >地面真实 来学习。这是合理的,因为老师(解码器)还不靠谱时,学生跟着标准答案学最保险。
- 训练后期: 随着训练进行,解码器分支的能力不断增强, W d t W_{dt} Wdt 会变大, W g t W_{gt} Wgt 会变小。此时, L d w b d L_{dwbd} Ldwbd 会逐渐侧重于 W d t × L d e t ( p t , d t ) W_{dt} \times L_{det}(p_t, dt) Wdt×Ldet(pt,dt) 这一项,即 token 分支更多地向 解码器学到的精细目标 学习。这是知识蒸馏的核心,让学生学习老师的知识。
其中 L d e t L_{det} Ldet 的计算方式与公式 4 完全相同。 p t p_t pt 指 token 分支的预测。本文中 γ 1 \gamma_1 γ1 和 γ 2 \gamma_2 γ2 分别设置为 2 和 1。根据设计,在网络训练的早期阶段, W g t ≫ W d t W_{gt} \gg W_{dt} Wgt≫Wdt,整个 token 分支的训练过程由地面真实指导。然而,在训练的后期阶段, W g t < W d t W_{gt} < W_{dt} Wgt<Wdt,来自解码器目标的指导变得更加重要。这种在训练过程中权重的动态调整是本文提出的 DWBD 的核心思想。我们将在 4.4.3 节中进一步分析 W d t W_{dt} Wdt 和 L d w b d L_{dwbd} Ldwbd 的变化。此外,为了进一步提升 token 分支的性能,我们采用了两阶段的蒸馏方法。在第一阶段,我们单独训练解码器分支。在第二阶段,我们在同步学习的前提下对两个分支应用 DWBD。
两阶段训练的作用
论文提到使用了两阶段训练:
- 第一阶段: 单独训练解码器分支。这可能是为了让解码器分支在开始同步训练(第二阶段)之前,就具备一定的基础能力,不至于在第二阶段一开始就是一个完全不懂的“弱鸡老师”,这样动态权重 W d t W_{dt} Wdt 即使在早期也不会是零,能更好地启动 DWBD 机制。
- 第二阶段: 在同步学习的前提下,应用 DWBD 训练两个分支。
- 总结来说,DWBD 设计了一个巧妙的损失函数项,通过动态调整地面真实和解码器分支目标这两种指导信号的权重,使得轻量级分支能够在同步训练过程中,根据更强分支(解码器)能力的提升,逐步从主要学习地面真实过渡到更多地学习更强分支提炼出的知识,从而实现有效的知识迁移和性能提升。
Text-guided Query Generation(TQG)

初始对象查询 Q i n i t Q_{init} Qinit 是使用可学习嵌入定义的,没有任何先验信息来指导它们。从宏观角度看,视觉定位涉及使用文本作为查询来定位图像中的最佳区域。将文本嵌入到查询中以自适应地提供先验信息是一种可行的解决方案。因此,我们提出了一个文本引导查询生成(TQG)模块,用于生成带有文本先验信息(priors)的对象查询。如图 3 所示,通过 TQG 生成查询的过程可以表达为:
Q t q g = MCA ( Q i n i t , f t e x t + pos , Mask ) + MMP ( f t e x t , Mask ) + Q i n i t (8) Q_{tqg} = \text{MCA}(Q_{init}, f_{text} + \text{pos}, \text{Mask}) + \text{MMP}(f_{text}, \text{Mask}) + Q_{init} \quad\text{(8)} Qtqg=MCA(Qinit,ftext+pos,Mask)+MMP(ftext,Mask)+Qinit(8)
其中 f t e x t ∈ R K × C f_{text} \in \mathbb{R}^{K \times C} ftext∈RK×C 是文本投影后的特征,Mask 与公式 1 一致,这里的 pos 是 1D 绝对正弦位置编码。MMP 是使用 Mask 从 f t e x t f_{text} ftext 中过滤出有效 token 并应用最大值操作的过程:MMP( f , m f, m f,m) = max i [ f i × ( ∼ m i ) ] \max_i [f_i \times (\sim m_i)] maxi[fi×(∼mi)]。
核心思想:TQG 让模型在寻找图像中的目标之前,先通过文本描述来“理解”要找什么,并将这种理解融入到搜索目标用的“查询”中。
简单来说,TQG 就像一个“指示器生成器”。它接收一个通用的“去找东西”的请求(初始查询),然后阅读“要找什么东西”的说明书(文本特征),最后生成一个更具体的、带着“去帮我找那个蓝色的猫”指令的请求(TQG 生成的查询),然后再把这个更智能的请求送去模型后面搜索图片。** 这样,模型在解码阶段使用这些文本引导过的查询,就能更高效、更准确地找到与文本描述对应的目标物体。
什么是“对象查询”(Object Queries)?
在一些现代的检测模型(比如 DETR 及其变体,SimVG 参考了 DETR 的一些思想)中,模型不是直接在图片的所有位置进行预测,而是使用一组特殊的向量,称为“对象查询”(Object Queries)。这些查询向量可以看作是模型内部发出的“请帮我找一个潜在物体”的请求。解码器部分会利用这些查询去“扫描”图像特征,并为每一个查询预测一个可能的物体(它的位置、类别等)。
论文中提到,初始的对象查询 Q i n i t Q_{init} Qinit 只是简单的、可学习的向量,它们本身不包含任何关于“要找什么”的先验信息。它们是通用的“占位符”。
问题:视觉定位需要“文本先验”
在视觉定位任务中,模型需要根据一段文本描述来找到图片中对应的物体。这意味着文本描述本身就包含了关于目标物体的关键信息(比如物体的类型、颜色、位置关系等)。如果能把这些文本信息用到“对象查询”中,让查询在去看图片之前就带着这些提示,岂不是更好?这就是“文本先验”(text priors)的概念。
TQG 的作用:将文本信息注入查询
TQG 模块的目的就是解决上述问题:它接收初始的、不带偏见的对象查询 ( Q i n i t Q_{init} Qinit),并利用文本描述的特征 ( f t e x t f_{text} ftext),生成新的、带有文本先验信息、更有针对性的对象查询 ( Q t q g Q_{tqg} Qtqg)。
TQG 是怎么工作的
- 输入: 初始对象查询 ( Q i n i t Q_{init} Qinit) 和文本的特征表示 ( f t e x t f_{text} ftext,以及它的位置编码 p o s pos pos 和掩码 Mask)。
- 关键步骤:
- 交叉注意力 (MCA): TQG 使用一个多头交叉注意力机制。这里的操作是让 初始对象查询 ( Q i n i t Q_{init} Qinit) 去关注 文本特征 ( f t e x t + p o s f_{text} + pos ftext+pos)。这就像让那些通用的查询“阅读”一遍文本描述,从中提取与寻找目标相关的信息,并融入到查询本身的表示中。掩码 (Mask) 用于确保只关注有效的文本部分,忽略填充符。
- 文本特征聚合 (MMP): 还有一个 MMP 操作,它从文本特征中提取一个代表性的特征(通过对有效 token 进行最大值操作。最大值操作通常是沿着序列的维度进行的,也就是对所有有效 token 的 同一个维度 的值进行比较,选出最大的那个值。)。这可以看作是文本信息的一种全局或重点摘要。
- 输出: 最终的文本引导查询 ( Q t q g Q_{tqg} Qtqg) 是由 初始查询 ( Q i n i t Q_{init} Qinit)、交叉注意力后得到的查询(包含了从文本中提取的信息)以及 文本特征聚合结果 相加得到的(公式 8)。这意味着新的查询结合了原始查询的通用性、从文本中学习到的具体信息以及文本的概括性特征。
3. 实验部分
主实验
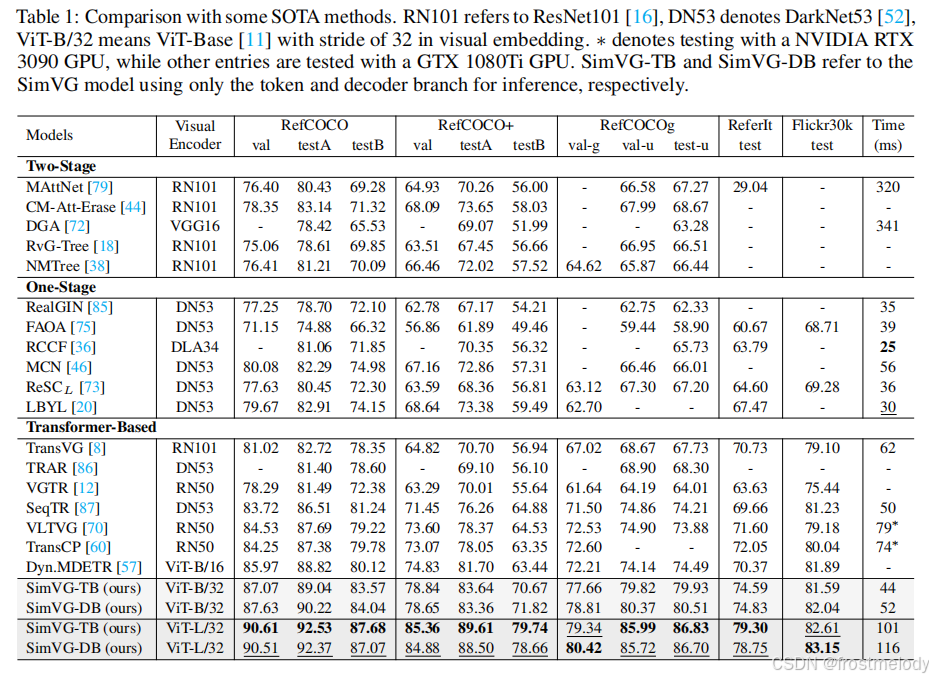
- SimVG 与六个主流数据集上的 SOTA(最先进)方法进行了比较。我们将 RefCOCO/+/g、ReferItGame 和 Flickr30K 数据集的结果合并呈现在表 1 中,而 GREC 的结果则在表 2 中报告。表 3 报告了在大型语料库数据上进行预训练的结果。
- 将模型从基础版本扩展到大型版本,在所有数据集上都带来了显著提升。
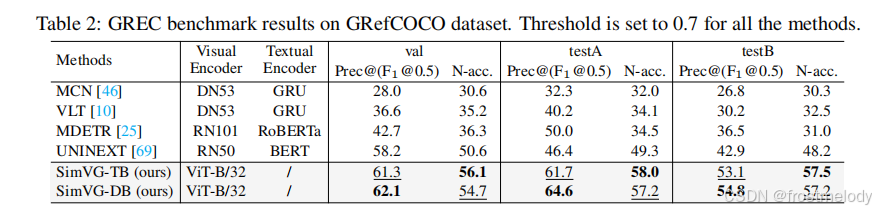
- SimVG 可以无缝扩展到 GREC 任务,无需任何网络修改。如表 2 所示,SimVG 在 GRefCOCO 数据集上相较于现有公开可用方法实现了显著提升,平均提高了 9 个百分点,超越了 UNINEXT
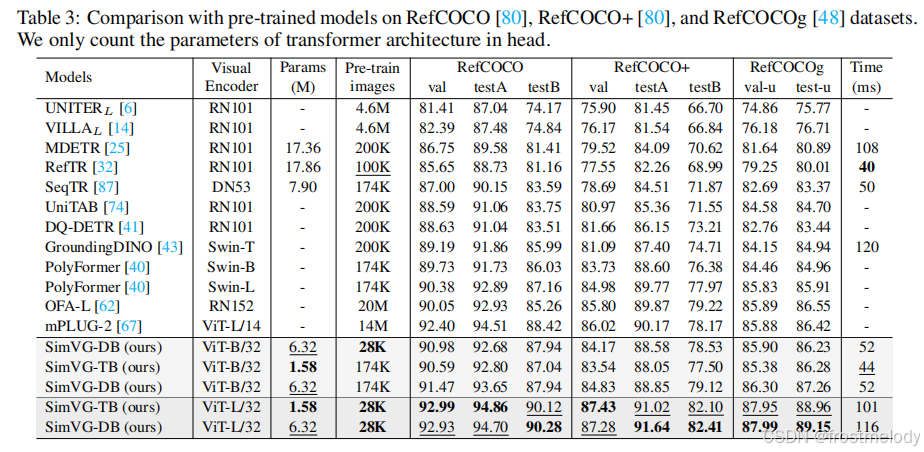
- 在大型图文对语料库上进行预训练时,与大多数现有 SOTA 方法相比,SimVG 表现出更高的数据效率。尽管仅使用了 28K 张图像,这比 MDETR少了近六倍,比 RefTR 少了三倍,SimVG 仍然达到了 SOTA 性能,大幅度超越了大多数现有方法。与 MDETR 相比,SimVG 平均提升了 5 个百分点;与最近的 SOTA 模型 GroundingDINO 相比,平均提升了 2 个百分点。此外,增加预训练数据量进一步提升了性能。
- SimVG 在头部应用了更轻量的 Transformer 结构。具体而言,SimVG-TB 仅使用 1.58 百万参数,这比一些轻量级模型更小。最后,我们观察到,将多模态编码器从 ViT-B 扩展到 ViT-L 后,轻量级 token 分支的性能超越了其教师模型。我们假设,随着模型规模的增大,解码器分支性能的可靠性提高,有助于减轻错误标注 ground truth 数据的影响。这反过来又增强了 token 分支的泛化能力,进一步证明了 DWBD 方法的有效性。
消融实验
1. Multi-Modality Encoder Architecture
- 为了研究将多模态融合与视觉 grounding 解耦的优势,我们设计了三种架构进行实验验证。为确保公平性,我们一致采用 ViT-B/32 模型进行特征提取,并使用 VGTR的头部进行预测。“CLIP”代表一种典型的双流多模态预训练结构。“ViLT”代表一种单流多模态融合方法。“BEiT-3”代表一种带有融合编码器的双流方法。实验结果报告在表 4 中。像 ViLT 和 BEiT-3 这样将多模态融合过程与下游任务解耦的方法,相较于采用多模态独立编码器架构的方法显示出显著提升。
- ViLT 和 BEiT-3 通过解耦多模态融合,表现出显著加速的收敛。相比之下,尽管 CLIP 利用了大量的图文数据进行预训练,但它只进行跨模态对齐,而没有整合图像和文本模型的信息来获得融合表示。
- 将原始视觉嵌入的步长从 16 增加到 32 并对卷积核应用双线性插值,能够显著提升性能。这是因为双线性插值在压缩后保留了原始特征分布,从而加速了收敛。此外,来自解码器和 token 分支的实验结果揭示了显著的性能差距,突显了设计动态权重平衡蒸馏(dynamic weight-balance distillation)来缓解这种差异的必要性。
2. Text-guided Query Generation(TQG)
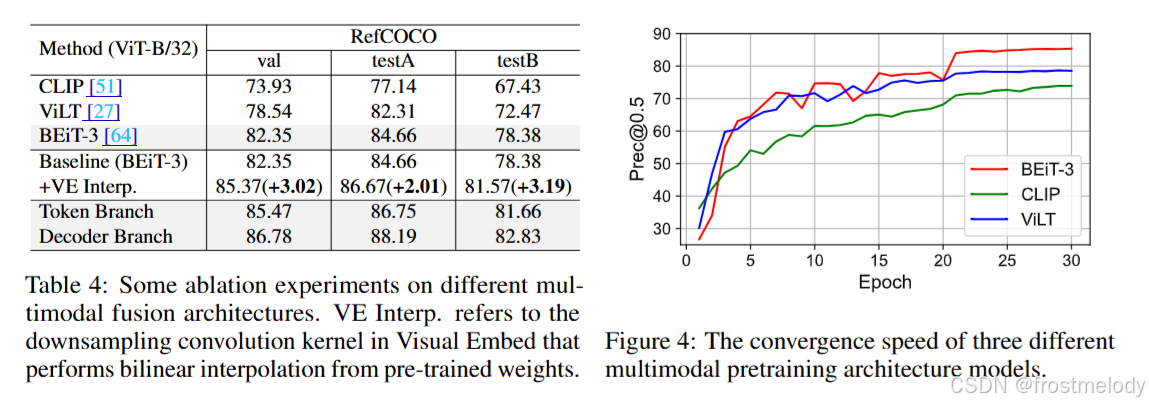
- 如表5所示,实验结果表明,TQG模块对token分支和解码器分支都有明显的积极影响,平均绝对提升了0.8个点。这种引导机制与DAB-DETR 的概念一致,后者将文本先验注入查询中,使其具备指向目标的特性。“Mask Max Pool”涉及使用文本掩码选择有效的文本token,然后执行最大池化以压缩维度,如第3.3节所述。此外,图5说明了transformer层对TQG的影响。采用2层transformer结构以平衡效率和性能。
3. Dynamic Weight-Balance Distillation(DWBD)
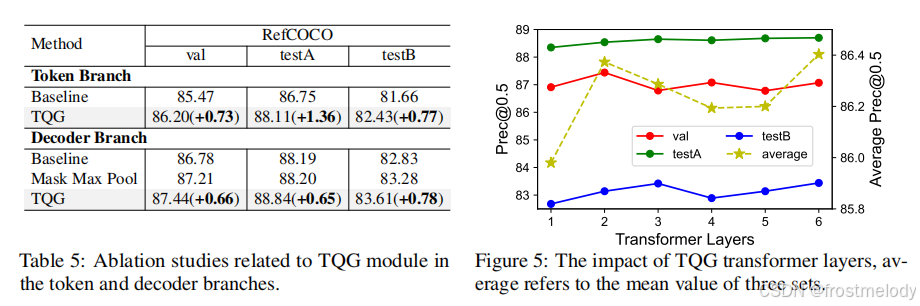
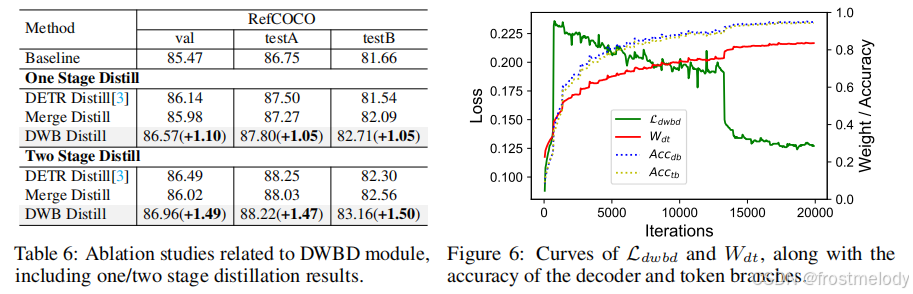
- 蒸馏实验结果如表6所示,“DETR Distill”使用解码器分支的预测作为教师进行学习。“Merge Distill”将ground truth与解码器预测结合,使token分支能够自适应地选择匹配的目标。可以看出,所有这三种蒸馏方法都提高了token分支的性能,其中两阶段蒸馏方法进一步提升了其性能。最终,我们提出的DWBD相比基线平均提升了1.5个点。从表1和表3我们观察到,当使用ViT-L作为教师模型时,轻量级的token分支在同步学习期间,在某些指标上的性能甚至可以超越解码器分支。我们假设这主要是因为随着教师认知能力的提高,token分支蒸馏了更鲁棒的特征表示。此外,图6展示了DWBD在训练过程中的动态平衡过程。我们可以观察到,随着解码器分支置信度的增加,Wdt的值相应升高,这表明解码器分支为token分支提供了更多的指导。这种机制允许在ground truth和解码器预测之间动态调整指导分布。
可视化实验
- 作者从两个角度对SimVG进行注意力分析,如图7所示。首先,作者使用GradCAM可视化BEiT-3的多模态表示,生成热力图,揭示BEiT-3主要关注全局前景信息。此外,作者还可视化了解码器的注意力图,这些图突出了模型对文本所提及区域的关注。

4. Limitations and Broader Impacts
- 我们的方法未能充分探索或利用特征中的层级信息。可以考虑采用类似ViTDet 中FPN等扩展特征层级的方法,以进一步增强模型捕获不同尺度目标的能力。我们的方法不仅可以应用于检测相关任务,还可以应用于分割相关任务。需要对更多的下游任务进行进一步验证,以证明其稳定的有效性。
- 在使用这项技术时,需要进行进一步的研究和审慎的考虑,因为本文提出的方法依赖于从训练数据集中提取的统计信息,这些数据集可能存在偏差,并可能导致负面的社会影响。
5. 其他知识附录
附1:DETR 中的匈牙利匹配
在 DETR 中,匈牙利算法的主要作用是解决预测框与真实框的匹配问题,即在每个训练步骤中如何正确地将模型输出的预测框与真实标签框进行匹配,以便进行有效的损失计算和梯度更新。具体来说,DETR 将目标检测任务看作集合预测问题,对于一张图片,固定预测一定数量的物体(原作是100个,在代码中可更改),模型根据这些物体对象与图片中全局上下文的关系直接并行输出预测集,也就是 Transformer 一次性解码出图片中所有物体的预测结果。
- 一对一匹配:每个预测框最多对应一个真实目标,避免多个预测框指向同一个目标。
- 最小化总损失:通过最优匹配,确保模型关注于最相关的预测与真实目标之间的关系。
- 简化后处理:由于匹配过程已经处理了重复预测的问题,DETR 不再需要传统的非极大值抑制(NMS)步骤。
DETR模型看了一张图片,然后它“猜”出了图片里有哪些物体,比如猜出了3个物体(比如一个猫、一个狗、一个杯子)。但是,模型可能猜得不是那么准,比如它可能猜出了4个物体,或者只猜出了2个物体。而且,它猜出的物体位置和真实物体也不完全重合。现在的问题就是:如何把模型猜出的物体(比如4个)和图片里真实存在的物体(比如3个)对应起来? 也就是说,我们要确定模型猜出的第1个物体对应的是真实的哪个物体?第2个对应哪个?以此类推。匈牙利匹配就是用来解决这个“对应”问题的工具。
1. 二分图的概念:我们可以把这个问题画成一个特殊的图,叫做“二分图”。
- 图的一边(比如左边)代表模型猜出的所有物体(假设有N个)。
- 图的另一边(比如右边)代表图片里真实存在的所有物体(假设有M个)。
- 如果模型猜出的某个物体和真实的某个物体比较像(比如位置重叠比较多,或者类别相同),我们就在它们之间画一条线,这条线代表一种“可能的对应关系”。这条线有一个“分数”,表示这种对应关系有多好(比如可以用IoU,即交并比来衡量)。
2. 匹配的目标:我们的目标是在这个图上找到一种“最佳对应关系”。
- 每个模型猜出的物体最好能对应到一个真实的物体。
- 每个真实的物体最好能被一个模型猜出的物体对应到。
- 整体上,所有对应关系的“分数”加起来要尽可能大(或者说,对应关系要尽可能“好”)。
3. 匈牙利算法的作用:匈牙利算法就是专门解决这种“二分图匹配”问题的数学方法。它会计算出一种最优的对应方案,告诉你模型猜出的第1个物体应该对应真实的哪个物体,第2个对应哪个,依次类推,使得整体匹配效果最好。
附2:GIOU
GIoU DIoU CIoU loss 损失函数
IoU、GIoU、DIoU、CIoU损失函数的那点事儿
GIoU(Generalized Intersection over Union) 是一种用于目标检测任务的性能评估指标和损失函数,旨在改进传统的 IoU(Intersection over Union),特别是在处理不重叠或形状差异较大的边界框时。GIoU 是 IoU 的一个泛化版本,通过引入最小外接矩形,能够更全面地衡量预测框与真实框之间的相似度,包括重叠程度和相对位置关系,解决了 IoU 在非重叠情况下的局限性。
-
基本概念:
- IoU 是通过计算两个边界框(预测框和真实框)的交集面积与并集面积的比值来衡量它们的重叠程度。
- GIoU 在 IoU 的基础上进行了扩展,引入了包含两个边界框的最小凸包(对于矩形框,就是最小外接矩形)的概念。
-
计算方法:
- 首先,计算两个边界框 A(预测框)和 B(真实框)的 IoU:
IoU(A, B) = Area(A ∩ B) / Area(A ∪ B)。 - 然后,找到同时包含 A 和 B 的最小凸包 C(最小外接矩形)。
- 最后,计算 GIoU:
GIoU(A, B) = IoU(A, B) - Area(C - (A ∪ B)) / Area(C)。或者更简洁地表示为:GIoU(A, B) = IoU(A, B) - (Area(C) - Area(A ∪ B)) / Area(C)。
- 首先,计算两个边界框 A(预测框)和 B(真实框)的 IoU:
-
核心优势:
- 衡量距离:与仅关注重叠区域的 IoU 不同,GIoU 不仅考虑了重叠部分,还考虑了两个框之间的“距离”或“非重叠区域”。当两个框完全不重叠时,GIoU 的值会小于 0,并且其值能反映它们相距多远。
- 解决 IoU 梯度消失问题:当预测框和真实框完全不重叠时,IoU 为 0,如果用作损失函数会导致梯度消失,无法有效优化模型。GIoU 在这种情况下仍然可以提供有效的梯度信息,有助于模型学习。
- 更全面的评估:GIoU 能更好地反映两个边界框的整体重合程度,即使它们的形状或方向差异较大。
附3:MMP操作的细节
假设我们有一段经过处理的文本序列及其特征,以及对应的掩码:
文本序列:[“猫”, “坐”, “垫子”, “[PAD]”, “[PAD]”] (其中 “[PAD]” 是填充符)
对应的 掩码 (Mask):[1, 1, 1, 0, 0] (1 表示有效 token,0 表示填充符)
假设每个 token 的 特征向量 是一个简单的 3 维向量(实际模型中维度会高很多,例如 768 维):
- “猫” 的特征 f 1 f_1 f1: [0.5, 0.1, 0.8]
- “坐” 的特征 f 2 f_2 f2: [0.6, 0.9, 0.2]
- “垫子” 的特征 f 3 f_3 f3: [0.7, 0.2, 0.5]
- “[PAD]” 的特征 f 4 f_4 f4: [0.1, 0.1, 0.1] (填充符的特征值通常不重要,因为会被掩码忽略)
- “[PAD]” 的特征 f 5 f_5 f5: [0.0, 0.0, 0.0] (填充符的特征值通常不重要)
根据掩码 [1, 1, 1, 0, 0],有效 token 是 “猫”, “坐”, “垫子”,它们对应的特征向量是 f 1 f_1 f1, f 2 f_2 f2, f 3 f_3 f3。
“通过对有效 token 进行最大值操作”的意思是:我们只看 f 1 f_1 f1, f 2 f_2 f2, f 3 f_3 f3 这三个向量,然后对它们的 每个维度 分别找出最大值。
- 看第一个维度: f 1 f_1 f1 的第一个维度是 0.5, f 2 f_2 f2 的第一个维度是 0.6, f 3 f_3 f3 的第一个维度是 0.7。这三个值中的最大值是 max ( 0.5 , 0.6 , 0.7 ) = 0.7 \max(0.5, 0.6, 0.7) = 0.7 max(0.5,0.6,0.7)=0.7。
- 看第二个维度: f 1 f_1 f1 的第二个维度是 0.1, f 2 f_2 f2 的第二个维度是 0.9, f 3 f_3 f3 的第二个维度是 0.2。这三个值中的最大值是 max ( 0.1 , 0.9 , 0.2 ) = 0.9 \max(0.1, 0.9, 0.2) = 0.9 max(0.1,0.9,0.2)=0.9。
- 看第三个维度: f 1 f_1 f1 的第三个维度是 0.8, f 2 f_2 f2 的第三个维度是 0.2, f 3 f_3 f3 的第三个维度是 0.5。这三个值中的最大值是 max ( 0.8 , 0.2 , 0.5 ) = 0.8 \max(0.8, 0.2, 0.5) = 0.8 max(0.8,0.2,0.5)=0.8。
将每个维度的最大值组合起来,就得到了最终的结果向量: [0.7, 0.9, 0.8]。
这个结果向量就是一个单一的、固定长度的向量,它浓缩了有效文本(“猫 坐 垫子”)中在每个维度上最强的激活信息。在 TQG 中,这个向量会被用来帮助生成带有文本先验信息的查询。
附4:多模态模型训练常用的数据集

附5:We only count the parameters of transformer architecture in head?
- Head (头部): 在深度学习模型中,“头部”通常指模型末端负责执行特定任务(比如分类、检测、定位等)的层或模块。它接收主干网络(backbone)提取的特征,并输出最终结果。
- Transformer architecture in head: 这指的是模型头部中使用了 Transformer 结构的那些部分。
作者在报告模型的参数数量时(前面提到 SimVG-TB 只有 1.58 百万参数),他们没有计算整个模型的参数(包括主干网络等),而是只统计了位于模型“头部”并且采用了 Transformer 结构的那些层的参数。
附6:将原始视觉嵌入的步长从 16 增加到 32 并对卷积核应用双线性插值,能够显著提升性能
仅仅增加步长(进行压缩)可能不够,如果在进行这种“步长增加”导致的压缩转换时,同时使用一种基于双线性插值原理的方法来处理卷积过程,那么最终模型的性能会显著提升。原因正如原文后面解释的:“这是因为双线性插值在压缩后保留了原始特征分布,从而加速收敛。” 也就是说,这种结合双线性插值的处理方式,使得用更大步长(32)生成的视觉嵌入,虽然数量少了,但质量更高,更好地代表了原始图像的信息,因此对后续任务更有利,不仅能提升最终性能,还能加速训练收敛。
- 双线性插值 (Bilinear Interpolation):
- 这是一种常用的图像缩放或采样的方法。
- 它的基本思想是,当你需要计算新图像(或者缩放后的特征图)上一个点的值时,不是简单地取原始图像最近的一个点(最近邻插值),而是根据这个点在原始图像中四个最近邻点的位置和值,进行加权平均来计算。
- 双线性插值计算出的值更平滑,能更好地保留原始图像的细节和过渡,避免缩放时出现锯齿状或块状的伪影。
- 卷积核 (Convolutional Kernel):
- 卷积核是一个小的权重矩阵,在卷积操作中用于扫描输入特征图。它定义了如何将输入区域的信息聚合成一个输出值。
作者在提取图像最初的特征向量时,改变了提取的方式:增加了提取的“步子”大小(从 16 到 32,即减少了提取的向量数量),但为了弥补信息损失,同时使用了双线性插值这种更精细平滑的方式来处理提取过程。结果是,虽然提取的向量变少了,但因为提取得更“聪明”(用了双线性插值),反而让模型性能变好了。
- 原始视觉嵌入 (Original visual embedding): 这是指模型最开始处理图像的方式。在 ViT 模型中,通常是将图像分割成小块(patch),然后将每个小块转换成一个向量(embedding)。这个过程通常涉及一个卷积操作来完成。
- 步长 (Stride): 这个“步长”是指在生成这些视觉嵌入时,卷积核(或 patch 提取窗口)在图像上移动的距离。
- 步长 16 意味着窗口每次移动 16 个像素。
- 步长 32 意味着窗口每次移动 32 个像素。
- 步长从 16 增加到 32 的影响: 增加步长意味着在相同大小的图像上,提取的视觉嵌入(或 patch)的数量会减少。比如,如果 patch 大小是 32x32,步长 16 会导致 patch 之间有重叠(小于卷积核窗口大小 32x32),提取的 token 更多;步长 32 则可能没有重叠,提取的 token 数量会减少。这是一种空间上的降采样或压缩,会减少模型处理的 token 数量,可能加快速度,但也可能丢失信息。
对卷积核应用双线性插值”这句话,听起来有点不寻常,因为双线性插值通常是应用于数据(像素值或特征值),而不是直接应用于卷积核的权重本身。结合之前的上下文(步长从 16 增加到 32,这是压缩/降采样的过程),这句话更可能是指:
在执行那个将原始图像(或初步特征)转换为步长为 32 的视觉嵌入的卷积操作时,这个卷积过程(或者说这个卷积核的设计/作用方式)融入了双线性插值的原理。
这可能意味着以下几种情况(或它们的组合):
- 卷积核权重的生成或设计方式借鉴了插值原理: 卷积核的权重值不是随机初始化或简单学习,而是根据某种插值(类似于双线性插值)的数学函数来预设或影响。这样,卷积核在处理输入区域时,就倾向于以一种平滑、插值式的方式来聚合信息。
- 卷积操作本身被修改以执行插值式采样: 虽然表面是卷积,但底层的实现机制在从输入区域采样并聚合时,使用了类似于双线性插值加权平均的逻辑。当步长增加(导致输入区域被压缩到更少的输出点)时,这种插值式的聚合可以确保每个输出点更平滑地代表它对应的更大输入区域的信息。
就像前面提到的,增加步长(从 16 到 32)是一种压缩。如果只是简单地跳着采样或进行普通的卷积,可能会丢失很多细节或引入采样误差。应用双线性插值原理,即使是在压缩过程中,也能更“聪明”地聚合信息。它能帮助:
- 保留更多的原始特征分布信息: 使得压缩后的特征(步长为 32 的视觉嵌入)更好地反映原始图像区域的面貌。
- 使特征过渡更平滑: 避免了因为大步长导致的突变或信息断层。
通过这种方式(增加步长进行压缩 + 应用双线性插值原理进行高质量聚合),模型能够在处理更少的 token(因为步长大了)的同时,依然获得高质量的视觉嵌入,从而显著提升后续任务(如视觉 grounding)的性能,并加速模型收敛。
附7:各backbone模型比较
| 模型 | 参数量(M) | 主要架构 |
|---|---|---|
| DLA-34 | 15.7 | 34 层深度层聚合网络,通过 Iterative Deep Aggregation(IDA)与 Hierarchical Deep Aggregation(HDA)节点融合不同深度特征,使用基本卷积块 |
| DarkNet-53 | 41.6 | 53 层 DarkNet 主干,交替使用 1×1 和 3×3 卷积并配以残差连接,开始是用于 YOLOv3 |
| ResNet-101 | 45.0 | 101 层残差网络,采用 Bottleneck 残差块(1×1 → 3×3 → 1×1 卷积),堆叠于 conv2_x(3 块)、conv3_x(4 块)、conv4_x(23 块)、conv5_x(3 块)中 |
| ResNet-152 | 60.0 | 152 层深度残差网络,同样基于三层 Bottleneck 结构,按 conv2_x(3 块)、conv3_x(8 块)、conv4_x(36 块)、conv5_x(3 块)堆叠 |
| ViT-B/32 | 88.0 | Vision Transformer Base:12 层自注意力编码器,隐藏维度 768,MLP 隐层 3072,12 个头,Patch 大小 32,添加 CLS token 与位置嵌入 |
| CLIP-ViT-Base | 88.0 | 基于 ViT-B/32,外加 512 维投影头将视觉 CLS token 映射到多模态对齐空间,用于图文对比学习 |
| Swin-B | 88.0 | 层级化 Shifted-Window Transformer:Patch 分区(4×4 卷积),4 个阶段深度 [2,2,18,2],Embed dims [96,192,384,768],Window 大小 7,MLP ratio 4,GELU + LayerNorm |
| VGG16 | 138.0 | 13 层 3×3 卷积(通道依次为 64,64 → 128,128 → 256×3 → 512×3 → 512×3)、5 个 2×2 池化,末尾 3 层全连接(4096→4096→1000) |
| Swin-L | 197.0 | 更大版 Swin:Patch 分区(4×4 卷积),4 个阶段深度 [2,2,18,2],Embed dims [192,384,768,1536],Heads [6,12,24,48],Window 大小 7,MLP ratio 4 |
| CLIP-ViT-Large | 307.0 | 基于 ViT-L/14,外加 512 维投影头,同样用于多模态对比训练 |
| ViT-L/32 | 307.0 | Vision Transformer Large:24 层自注意力编码器,隐藏维度 1024,MLP 隐层 4096,16 个头,Patch 大小 32 |

)






spark和Hadoop的区别)








:权衡数据运用,精准把握创业方向)

之旅——String类⑩)