随着大语言模型(LLM)在自然语言处理各领域取得突破性进展,越来越多开发者和企业开始关注模型的微调方式。然而,全参数微调不仅成本高昂、资源要求极高,还容易引发过拟合与知识遗忘等问题。为此,LoRA、QLoRA、PEFT 等轻量级微调技术迅速崛起,成为大模型落地实践的热门选择。
本文将全面梳理这些技术,从原理剖析到工程实战,逐步构建一套适用于大模型适配的完整知识体系,帮助读者以更低的资源代价、更快的速度掌握大模型微调的核心能力。
目录
第一部分:大模型微调背景与挑战
🧠 为什么需要微调?
📉 全参数微调的困境
🔍 微调的典型应用场景
🧭 微调的新思路:轻量化微调登场
第二部分:LoRA原理与实现全剖析
1. LoRA 背后的核心思想:低秩矩阵近似
编辑2. 数学原理简单解释(易懂版)
3. LoRA 训练的具体实现机制
插入位置:哪些层插 LoRA?
参数配置含义
4. 使用 HuggingFace + PEFT 实现 LoRA 微调
5. LoRA 的实际效果如何?
第三部分:QLoRA:轻量内存占用的黑科技
1. QLoRA 的核心创新点
2. 量化技术详解:什么是 NF4?
3. HuggingFace 生态下的 QLoRA 实现
✅ 安装环境
✅ 载入4bit模型 + 配置QLoRA参数
✅ 启动训练(可配合 Trainer 或 SFTTrainer)
4. 性能与显存对比实测
第四部分:PEFT 框架全家桶解析
1. PEFT 支持的微调方法一览
2. PEFT 架构与核心概念
3. 使用 PEFT 快速实现多种微调
4. PEFT 与 Checkpoint 存储机制
第五部分:实战案例:微调大模型对话助手
1. 项目目标与模型选择
2. 数据集准备
3. 配置训练流程(以 QLoRA + PEFT 为例)
4. 微调效果验证与评估
第一部分:大模型微调背景与挑战
在大语言模型(LLM, Large Language Models)迅速发展的浪潮下,越来越多的企业和开发者希望将预训练模型应用到特定领域,如法律、医疗、金融、客服等垂直场景。然而,尽管开源大模型如 LLaMA、Baichuan、ChatGLM 已经具备强大的通用语言能力,但“原地使用”往往无法满足实际业务中的专业需求和语境差异,这就引出了微调(Fine-tuning)的重要性。
🧠 为什么需要微调?
预训练语言模型是基于海量通用语料构建的,虽然具备强大的上下文理解能力,但在面对特定任务时,它往往表现得“知其然不知其所以然”:
-
例如,金融领域的问题“什么是量化宽松政策?”如果用未微调的LLM回答,可能泛泛而谈,而缺乏专业术语和精准表达。
-
医疗问答中,常见的模型输出有误诊、回答模糊等风险,显然不能直接投入使用。
-
电商客服中,常规大模型容易出现语气不一致、品牌信息错误等现象。
因此,通过微调使模型对特定数据、任务、语气风格进行定向强化,是大模型落地的重要一环。
📉 全参数微调的困境
最直观的微调方式就是“全参数微调(Full Fine-tuning)”,即对整个模型的所有权重进行再训练。但这也带来了以下致命问题:
| 问题 | 描述 |
|---|---|
| 显存消耗极大 | 微调一个 65B 参数模型,显存需求往往高达数百GB,普通A100也吃不消 |
| 成本高昂 | 全参数更新意味着参数量 × 训练步数 × 精度,云资源开销极高 |
| 更新慢 | 大模型训练速度慢,Checkpoint 体积庞大,调参周期长 |
| 参数冗余 | 实际上许多下游任务只需要调整小部分权重,更新全部参数效率极低 |
| 不易迁移 | 多任务微调时容易“遗忘”原有能力(catastrophic forgetting) |
尤其对于个人开发者或中小企业而言,全参数微调几乎是不可承受之重。
🔍 微调的典型应用场景
以下是一些典型的大模型微调应用案例,帮助读者理解这项技术的实际价值:
-
行业定制:基于财报数据微调模型,让它回答财务分析类问题
-
风格迁移:将原模型训练为具有特定语气风格的客服机器人(如京东、小米语气)
-
指令强化:通过指令微调(Instruction tuning)让模型学会“听话”:按照固定格式答复、按步骤思考
-
多轮对话:加入对话历史上下文信息,提升多轮问答的连贯性与上下文理解
这些场景有一个共同点:**只需“稍加调整”,就能大幅提升模型在特定任务下的表现。**这也促使我们思考——有没有可能做到“只调一小部分参数,就能获得很好的效果”?
🧭 微调的新思路:轻量化微调登场
针对上述问题,研究者提出了各种轻量化微调方案:
-
Adapter Tuning:在网络中插入额外模块,仅训练这部分参数;
-
Prompt Tuning / Prefix Tuning:冻结模型,仅训练“提示词前缀”;
-
LoRA(Low-Rank Adaptation):使用矩阵分解方法,仅训练插入的小矩阵;
-
QLoRA:结合量化压缩与LoRA,显存优化进一步升级;
-
PEFT(Parameter-Efficient Fine-Tuning):将上述方法统一成一个通用框架。
这些方法显著降低了计算资源消耗,同时还支持更灵活的多任务、增量更新,成为当前微调主流解决方案。
第二部分:LoRA原理与实现全剖析
在资源有限的现实情况下,想要“微调”一个大语言模型就像试图用一辆小车拖动一架飞机,几乎不可能。然而,自从LoRA(Low-Rank Adaptation of Large Language Models)被提出以来,轻量化微调不再是奢望。
1. LoRA 背后的核心思想:低秩矩阵近似
微调的本质,是更新神经网络中的权重矩阵,比如 Transformer 中的 Attention 权重 W∈Rd×dW \in \mathbb{R}^{d \times d}W∈Rd×d。全参数微调会更新所有权重,而 LoRA 的做法是:
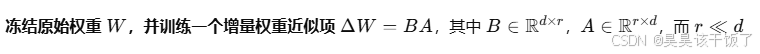 2. 数学原理简单解释(易懂版)
2. 数学原理简单解释(易懂版)
LoRA 的思想可以这样直观理解:
-
原始模型中有一个线性层:
y = W @ x -
使用 LoRA 之后,变成:
y = W @ x + B @ (A @ x)
最终,模型学的是一个“差值”,不会破坏预训练知识,又能精准适配新任务。
3. LoRA 训练的具体实现机制
插入位置:哪些层插 LoRA?
在 Transformer 架构中,最常用的插入位置是:
-
Attention中的 Query (Q) 和 Value (V) 子层
-
有时也包括 FFN中的第一层
参数配置含义
| 参数 | 含义 | 常用取值 |
r | 低秩矩阵的秩 | 4 / 8 / 16 |
lora_alpha | 缩放系数(相当于学习率倍率) | 16 / 32 |
lora_dropout | Dropout比率 | 0.05 / 0.1 |
target_modules | 作用模块(如q_proj、v_proj) | 依模型结构而定 |
4. 使用 HuggingFace + PEFT 实现 LoRA 微调
pip install transformers accelerate peft datasetsfrom transformers import AutoModelForCausalLM, AutoTokenizer
from peft import get_peft_model, LoraConfig, TaskTypemodel = AutoModelForCausalLM.from_pretrained("bigscience/bloomz-560m")
tokenizer = AutoTokenizer.from_pretrained("bigscience/bloomz-560m")lora_config = LoraConfig(r=8,lora_alpha=32,target_modules=["query_key_value"],lora_dropout=0.05,bias="none",task_type=TaskType.CAUSAL_LM
)model = get_peft_model(model, lora_config)from transformers import TrainingArguments, Trainertraining_args = TrainingArguments(per_device_train_batch_size=4,num_train_epochs=3,learning_rate=1e-4,fp16=True,logging_steps=10,output_dir="./lora_model"
)trainer = Trainer(model=model,args=training_args,train_dataset=train_dataset,eval_dataset=eval_dataset,
)
trainer.train()5. LoRA 的实际效果如何?
| 模型规模 | 全参数微调准确率 | LoRA微调准确率 | 参数数量对比 |
| 350M | 89.2% | 88.8% | ↓ 99.5% |
| 1.3B | 91.5% | 91.2% | ↓ 99.2% |
| 6.7B | 93.4% | 93.1% | ↓ 99.0% |
第三部分:QLoRA:轻量内存占用的黑科技
虽然 LoRA 极大降低了大模型微调的参数规模,但在面对数十亿乃至百亿参数模型时,显存占用依然是横亘在开发者面前的一座“大山”。QLoRA(Quantized Low-Rank Adapter)正是在这种背景下提出的,它结合了4-bit量化技术和 LoRA 的优点,大幅降低了训练时的内存占用,同时保留了性能表现。
1. QLoRA 的核心创新点
QLoRA 并不是一个全新的架构,而是一种 训练优化技术组合方案,主要包含三大技术:
| 技术名称 | 功能作用 |
|---|---|
| NF4 量化(4-bit NormalFloat) | 将权重压缩为 4bit,保留更多信息,降低内存 |
| Double Quantization | 进一步压缩优化器状态和梯度存储 |
| LoRA 插入 | 仅训练可调节的低秩权重,提高训练效率 |
通过这三者组合,QLoRA 实现了在单张 A100 显卡上训练 65B 参数模型的可能性。
2. 量化技术详解:什么是 NF4?
QLoRA 使用的是一种新的量化格式:NF4 (NormalFloat 4-bit),它不是普通的 int4,而是更接近浮点分布,能够更好保留权重信息。
| 对比项 | int4 | NF4 |
| 精度 | 较低 | 较高 |
| 表达能力 | 有限 | 接近 fp16 |
| 用途 | 推理为主 | 训练可用 |
NF4 是一种对称的、以正态分布为核心的编码方式,在保持低位宽的同时最大限度保留了参数分布的特征,适合用作权重矩阵的存储格式。
3. HuggingFace 生态下的 QLoRA 实现
目前,QLoRA 的训练流程已经由 HuggingFace 完整支持,依赖的核心库包括:
-
transformers -
bitsandbytes -
peft -
accelerate
以下是一个最小可运行的QLoRA训练样例:
✅ 安装环境
pip install transformers datasets peft bitsandbytes accelerate✅ 载入4bit模型 + 配置QLoRA参数
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import get_peft_model, LoraConfig, TaskTypemodel = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-hf",device_map="auto",load_in_4bit=True,quantization_config={"bnb_4bit_use_double_quant": True,"bnb_4bit_quant_type": "nf4","bnb_4bit_compute_dtype": "float16"}
)lora_config = LoraConfig(r=8,lora_alpha=32,lora_dropout=0.05,bias="none",task_type=TaskType.CAUSAL_LM
)model = get_peft_model(model, lora_config)✅ 启动训练(可配合 Trainer 或 SFTTrainer)
from transformers import TrainingArguments, Trainertraining_args = TrainingArguments(per_device_train_batch_size=4,gradient_accumulation_steps=8,warmup_steps=100,max_steps=1000,learning_rate=2e-4,fp16=True,logging_steps=10,output_dir="./qlora_model"
)trainer = Trainer(model=model,args=training_args,train_dataset=train_dataset,eval_dataset=eval_dataset,
)
trainer.train()4. 性能与显存对比实测
| 模型规模 | LoRA 显存占用 | QLoRA 显存占用 | 精度变化 |
| 7B | ~24 GB | ~12 GB | 下降 <0.5% |
| 13B | ~45 GB | ~22 GB | 下降 <1.0% |
| 65B | 无法训练 | ~46 GB | 下降 <1.5% |
QLoRA 在多项任务上(SQuAD、MT-Bench等)表现与全精度微调接近,远优于 Prompt Tuning 等方式。
第四部分:PEFT 框架全家桶解析
随着 LoRA 和 QLoRA 等方法在大模型微调中的流行,如何高效管理这些参数高效微调策略、统一调用接口、提高工程复用性,成为了另一个重要问题。为此,HuggingFace 推出了 PEFT(Parameter-Efficient Fine-Tuning)库,作为轻量微调方法的集成平台。
PEFT 让用户可以使用统一接口快速切换不同微调技术(如 LoRA、Prefix Tuning、Prompt Tuning、IA3、AdaLoRA 等),极大提升了实验效率和工程可维护性。
1. PEFT 支持的微调方法一览
| 微调方法 | 简介 | 适用场景 |
|---|---|---|
| LoRA | 插入低秩矩阵,冻结原始权重 | 通用,推荐默认首选 |
| QLoRA | 结合LoRA+量化,节省显存 | 资源受限场景 |
| Prefix Tuning | 学习一段固定前缀 | 小样本、指令类任务 |
| Prompt Tuning | 学习提示词向量(embedding) | GPT类任务、嵌入控制 |
| IA3 | 对激活层缩放调节 | 精度保留较好 |
| AdaLoRA | 动态调整秩r,提升训练效率 | 精调期/实验期使用 |
2. PEFT 架构与核心概念
PEFT 底层结构主要由以下几个模块组成:
-
PeftModel: 封装了带 Adapter 的模型; -
PeftConfig: 存储 LoRA/Prefix 等参数配置; -
get_peft_model(): 用于将预训练模型转换为可微调结构; -
prepare_model_for_kbit_training(): 结合QLoRA时使用,用于冻结层设置和准备量化训练。
3. 使用 PEFT 快速实现多种微调
以 LoRA 为例,代码如下(适用于任意 HuggingFace 支持的模型结构):
from peft import get_peft_model, LoraConfig, TaskTypelora_config = LoraConfig(r=8,lora_alpha=32,lora_dropout=0.1,bias="none",task_type=TaskType.CAUSAL_LM,target_modules=["q_proj", "v_proj"]
)
model = get_peft_model(model, lora_config)若要切换为 Prefix Tuning,只需更换 Config 类型:
from peft import PrefixTuningConfigprefix_config = PrefixTuningConfig(num_virtual_tokens=20,task_type=TaskType.SEQ_2_SEQ_LM
)
model = get_peft_model(model, prefix_config)这就是 PEFT 的最大优势:统一接口 + 模块复用 + 插拔灵活。
4. PEFT 与 Checkpoint 存储机制
PEFT 默认支持保存/加载的模型包括:
-
Adapter 权重(极小,仅几MB)
-
配置文件(yaml/json)
-
可与原始模型动态合并推理
示例:保存 Adapter
model.save_pretrained("./adapter")加载时:
from peft import PeftModel
model = PeftModel.from_pretrained(base_model, "./adapter")如果需要部署完整模型,也支持使用 merge_and_unload() 合并参数:
model = model.merge_and_unload()
model.save_pretrained("./full")第五部分:实战案例:微调大模型对话助手
本节将以一个典型应用场景为例,走完整个大模型微调流程:从模型选择、数据准备,到训练配置、效果验证,并提供全套代码与提示,助力快速落地。
1. 项目目标与模型选择
目标:基于开源 LLaMA 或 ChatGLM 模型,构建一个中文对话助手,支持通用问答、情绪对话、命令执行等能力。
推荐模型:
-
meta-llama/Llama-2-7b-hf(英文、指令微调强) -
THUDM/chatglm2-6b(中文原生支持,部署友好)
依照资源选择:
-
单A100:推荐 QLoRA + ChatGLM
-
多卡:可考虑 LLaMA2 + LoRA + Flash Attention 加速
2. 数据集准备
选用数据集:
-
Belle Group: 中文对话数据(含多轮、命令类) -
ShareGPT: 结构化英文对话数据(需清洗) -
OpenOrca,UltraChat: 高质量指令问答对话数据
若需自定义数据结构,可转为如下格式:
{"instruction": "请帮我写一段祝福语","input": "场景:公司年会","output": "祝公司年会圆满成功,大家阖家欢乐!"
}格式要求:instruction-based 格式适配 SFT(Supervised Fine-Tuning)流程。
3. 配置训练流程(以 QLoRA + PEFT 为例)
from peft import LoraConfig, get_peft_model, TaskType
from transformers import AutoModelForCausalLMmodel = AutoModelForCausalLM.from_pretrained("THUDM/chatglm2-6b",device_map="auto",load_in_4bit=True,trust_remote_code=True
)lora_config = LoraConfig(r=8,lora_alpha=32,lora_dropout=0.05,task_type=TaskType.CAUSAL_LM,bias="none"
)
model = get_peft_model(model, lora_config)使用 SFTTrainer 配合训练配置:
from trl import SFTTrainertraining_args = TrainingArguments(output_dir="qlora-chatglm2",per_device_train_batch_size=4,gradient_accumulation_steps=4,learning_rate=2e-4,num_train_epochs=3,save_strategy="epoch",fp16=True,
)trainer = SFTTrainer(model=model,args=training_args,train_dataset=train_dataset,dataset_text_field="text",
)
trainer.train()4. 微调效果验证与评估
可使用以下方式评估微调效果:
-
自定义 Prompt 测试
-
BLEU / ROUGE 指标评估生成质量
-
引入 MT-Bench 中文版进行结构化问答打分
示例 Prompt:
### Instruction:
请推荐三种适合情侣周末出游的地方### Response:
1. 鼓浪屿:文艺、浪漫,适合拍照;2. 千岛湖:自然风光宜人;3. 乌镇:古镇风情浓郁。微调后模型应表现出明显风格变化、指令理解增强、情感表达更自然。
通过轻量化微调,可以用极低的成本,让大模型真正适配特定任务与场景,不再止步于调用,而是深入参与模型能力构建。希望本文内容能为大家的后续深入研究与落地实践提供参考与助力,也欢迎大家在实践中不断优化微调流程,推动大模型技术真正走进业务一线。





)


)


C++版——day8)




)


