前言
本文隶属于专栏《机器学习的一百个概念》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和参考文献请见[《机器学习的一百个概念》
ima 知识库
知识库广场搜索:
| 知识库 | 创建人 |
|---|---|
| 机器学习 | @Shockang |
| 机器学习数学基础 | @Shockang |
| 深度学习 | @Shockang |
正文
引言 🌟
在机器学习的数据预处理阶段,我们经常会遇到分类变量(categorical variables)的处理问题。这些变量可能是性别、职业、教育程度等非数值型数据。由于大多数机器学习算法只能处理数值型数据,如何有效地将这些分类变量转换为数值型特征就成为了一个关键问题。独热编码(One-Hot Encoding)作为最常用的解决方案之一,在这个过程中扮演着重要角色。
核心原理 🔍
基本概念
独热编码的核心思想是将每个类别值转换为一个包含0和1的向量,向量的长度等于类别的总数。在这个向量中,只有一个位置的值为1(表示当前类别),其余位置都为0。
编码流程

数学表示
对于具有 k k k 个不同类别的特征,独热编码会创建一个 k k k 维向量空间,每个类别映射到这个空间中的一个标准基向量。形式化表示如下:
设类别集合 C = { c 1 , c 2 , . . . , c k } C = \{c_1, c_2, ..., c_k\} C={c1,c2,...,ck}
对于类别 c i c_i ci, 其独热编码为:
e i = [ 0 , 0 , . . . , 1 , . . . , 0 ] e_i = [0,0,...,1,...,0] ei=[0,0,...,1,...,0]
其中第 i i i 个位置为1,其余位置为0
示例说明
考虑一个包含颜色特征的数据集:
原始数据: ['红', '蓝', '绿', '红', '绿']独热编码后:
红: [1, 0, 0]
蓝: [0, 1, 0]
绿: [0, 0, 1]
红: [1, 0, 0]
绿: [0, 0, 1]
深入理解独热编码 🧠
几何解释
从几何角度看,独热编码将类别映射到多维空间中的正交向量。这种表示方法确保了:
- 所有类别之间的欧氏距离相等
- 没有引入人为的顺序关系
- 在向量空间中形成了线性可分的表示
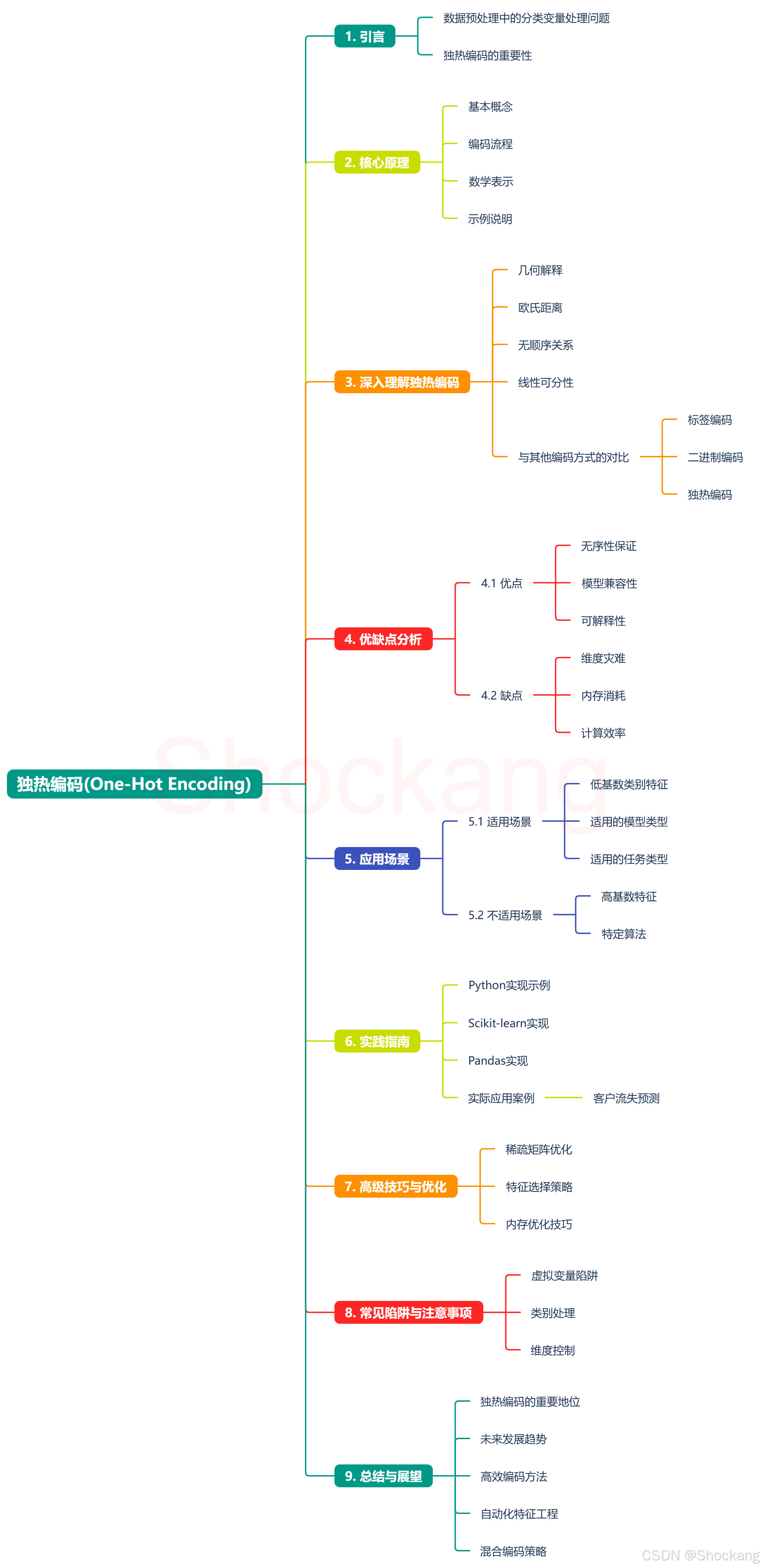
与其他编码方式的对比
-
标签编码(Label Encoding)
- 直接将类别映射为整数
- 可能引入顺序关系
- 计算效率高
- 适用于有序类别
-
二进制编码(Binary Encoding)
- 使用二进制表示
- 维度增长为log2(n)
- 计算效率较高
- 可能失去可解释性
-
独热编码(One-Hot Encoding)
- 使用独立维度表示每个类别
- 不引入顺序关系
- 维度增长线性
- 保持可解释性
优缺点分析 ⚖️
优点 👍
-
无序性保证
- 消除了类别之间的人为顺序关系
- 保持了特征的独立性
- 适合无序类别变量
-
模型兼容性
- 与大多数机器学习算法兼容
- 特别适合线性模型和神经网络
- 便于特征选择和权重分析
-
可解释性
- 结果直观易懂
- 便于追踪特征重要性
- 方便进行特征工程
缺点 👎
-
维度灾难
- 类别数量大时维度剧增
- 产生稀疏矩阵
- 增加计算复杂度
-
内存消耗
- 需要更多存储空间
- 可能导致内存溢出
- 处理大规模数据集困难
-
计算效率
- 训练时间增加
- 预测速度降低
- 模型复杂度提升
应用场景 🎯
适用场景
-
低基数类别特征
- 性别(男/女)
- 教育程度(小学/中学/大学)
- 职业类别(少量分类)
-
模型类型
- 线性回归
- 逻辑回归
- 神经网络
- 支持向量机
-
任务类型
- 分类问题
- 回归问题
- 推荐系统
不适用场景
-
高基数特征
- 用户ID
- 产品SKU
- 详细地址
-
特定算法
- 决策树
- 随机森林
- XGBoost
实践指南 💻
Python实现示例
- 使用Scikit-learn
from sklearn.preprocessing import OneHotEncoder
import numpy as np# 示例数据
data = np.array([['男'], ['女'], ['男'], ['女']])# 创建编码器
encoder = OneHotEncoder(sparse=False)# 训练并转换数据
encoded_data = encoder.fit_transform(data)# 获取特征名称
feature_names = encoder.get_feature_names_out(['gender'])print("编码结果:\n", encoded_data)
print("特征名称:", feature_names)
- 使用Pandas
import pandas as pd# 创建示例数据框
df = pd.DataFrame({'color': ['红', '蓝', '绿', '红'],'size': ['大', '中', '小', '中']
})# 对指定列进行独热编码
df_encoded = pd.get_dummies(df, columns=['color', 'size'])print("编码后的数据框:\n", df_encoded)
实际应用案例
- 客户流失预测
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression# 假设数据准备
data = pd.DataFrame({'age': [25, 35, 45, 55],'gender': ['男', '女', '男', '女'],'occupation': ['工程师', '教师', '医生', '工程师'],'churn': [0, 1, 1, 0]
})# 定义分类特征和数值特征
categorical_features = ['gender', 'occupation']
numeric_features = ['age']# 创建预处理流水线
preprocessor = ColumnTransformer(transformers=[('num', 'passthrough', numeric_features),('cat', OneHotEncoder(drop='first'), categorical_features)])# 创建完整流水线
pipeline = Pipeline([('preprocessor', preprocessor),('classifier', LogisticRegression())
])# 分割数据
X = data.drop('churn', axis=1)
y = data['churn']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)# 训练模型
pipeline.fit(X_train, y_train)
高级技巧与优化 🚀
1. 稀疏矩阵优化
from scipy.sparse import csr_matrix# 使用稀疏矩阵存储
encoder = OneHotEncoder(sparse=True)
sparse_encoded = encoder.fit_transform(data)# 转换为CSR格式
csr_matrix = sparse_encoded.tocsr()
2. 特征选择策略
3. 内存优化技巧
# 使用类别数据类型
df['category'] = df['category'].astype('category')# 指定dtypes减少内存使用
encoded_df = pd.get_dummies(df, columns=['category'], dtype=np.int8)
常见陷阱与注意事项 ⚠️
-
虚拟变量陷阱
- 问题:完全共线性
- 解决:删除一个类别或使用drop_first=True
-
类别处理
- 训练集和测试集类别不一致
- 新类别出现的处理
- 缺失值的处理
-
维度控制
- 设置最大类别数量
- 合并低频类别
- 使用降维技术
总结与展望 🎓
独热编码作为处理分类变量的基础方法,在机器学习中占据重要地位。它的简单直观和良好的可解释性使其成为数据预处理的首选方法之一。然而,在实际应用中需要注意维度灾难和计算效率等问题,并根据具体场景选择合适的优化策略。
未来发展趋势
-
高效编码方法
- 哈希编码
- 实体嵌入
- 目标编码
-
自动化特征工程
- AutoML集成
- 智能编码选择
- 动态特征生成
-
混合编码策略
- 多种编码方法组合
- 上下文感知编码
- 自适应编码机制
通过深入理解和灵活运用独热编码,我们可以更好地处理分类数据,为后续的机器学习模型训练打下坚实基础。在实践中,需要根据具体问题和场景,选择合适的编码策略,并注意平衡表达能力和计算效率。


-audiopolicyservice介绍)
)

:ReentrantLock 源码分析)




中,在LCD中显示两位数字问题)

)

)



)
)