文章目录
- Go语言学习
- 1. 简介
- 安装
- windows安装
- linux安装
- 编译工具安装-goland
- 2. 入门
- 2.1 Helloworld
- 注释
- 2.2 变量
- 初始化
- 打印内存地址
- 变量交换
- 匿名变量
- 作用域
- 局部变量
- 全局变量
- 2.3 常量
- iota
- 2.4 数据类型
- 布尔
- 整数
- 浮点类型
- 复数
- 字符串
- 定义字符串
- 字符串拼接符`+`
- 定义多行字符串
- map数据类型
- channel管道
- 2.5 运算符
- 1) 数据类型转换
- 2) 算术运算符
- 3) 关系运算符
- 4) 逻辑运算符
- 5) 位运算符
- 6) 赋值运算符
- 2.6 获取键盘输入
- 2.7 流程控制
- 1) 顺序控制
- 2) 条件控制
- if
- if-else 语句
- if else-if else 语法
- 3) 循环控制-for
- 模拟while循环
- 无限循环
- for-range 循环
- 打印九九乘法表
- 4) 分支控制
- switch
- case穿透
- 5) 跳转控制
- goto语句
- break语句
- continue
- 2.8 函数
- 什么是函数?
- 普通函数声明
- 匿名函数
- 闭包
- defer 延迟调用
- 异常处理
- 普通异常
- 自定义异常
- panic 宕机
- 回调函数
- 函数式编程
- 2.9 数组
- 声明
- 初始化
- 总结
- 访问
- 遍历
- 获得数组长度
- 向函数传递数组
- 使用数组指针传参
- 2.10 结构体
- 什么是结构体
- 定义
- 初始化
- 结构体与数组
- 切片
- \*号 和 &号
- 构造函数
- 匿名成员变量
- 方法传值
- 结构体与tag
- 结构体中方法的定义与使用
- 2.11 接口
- 什么是接口?
- 注意事项
- 底层实现
- 3. 高级
- 3.1 IO流使用
- 3.2 泛型
Go语言学习
| 名称 | 链接 | 备注 |
|---|---|---|
| go语言源码 | https://github.com/golang/go | |
| 官方文档-安装 | https://golang.google.cn/dl | |
1. 简介
Go的三个作者分别是:Rob Pike(罗伯.派克),Ken Thompson(肯.汤普森)和Robert Griesemer(罗伯特.格利茨默)
- Rob Pike:曾是贝尔实验室(BellLabs)的Unix团队,和Plan 9操作系统计划的成员。他与Thompson共事多年,并共创出广泛使用的UTF-8字元编码。
- Ken Thompson:主要是B语言、(语言的作者、Unix之父。1983年图灵奖(TuringAward)和1998年美国国家技术奖(National Medal of Technology)得主。他与Dennis Ritchie是Unix的原创者。Thompson也发明了后来衍生出C语言的B程序语言。
- Robert Griesemer:在开发Go之前是Google V8、Chubby和HotSpotJVM的主要贡献者
故事二
lan Lance Taylor 的加入以及第二个编译器(gcc go)的实现 在带来震惊的同时,也伴随着喜悦。
这对 Go 项目来说不仅仅是鼓励,更是一种对可行性的证明。语言的第二次实现对制定语言规范和确定标准库的过程至关重要,同时也有助于保证其高可移植性,这也是 Go 语言承诺的一部分。
自此之后 lan Lance Tavlor 成为了设计和实现 Go 语言及其工具的核心人物。
故事三:http.HandlerFunc、I/0库
Russ Cox在2008年带着他的语言设计天赋和编程技巧加入了刚成立不久的 Go团队。Russ 发现 Go 方法的通用性意味着函数也能拥有自己的方法,这直接促成了 http.HandlerFunc 的实现,让 Go 一下子变得无限可能的特性。
Russ 还提出了更多的泛化性的想法,比如 io.Reader 和 io.Writer 接口,奠定了所有 I/0 库的整体结构。
故事四:cryptographic
安全专家 Adam Langley 帮助 Go 走向 Google 外面的世界。
Adam 为 Go 团队做了许多不为外人知晓的工作,包括创建最初的 http:/lgolang.org 网站以及 build dashboard.
不过他最大的贡献当属创建了 cryptographic 库。
起先,在我们中的部分人看来,这个库无论在规模还是复杂度上都不成气候。但是就是这个库在后期成为了很多重要的网络和安全软件的基础
并且成为了 Go 语言开发历史的关键组成部分。
故事五:Docker、Kubernetes.
一家叫做 Docker 的公司。就是使用 Go进行项目开发,并促进了计算机领域的容器行业,进而出现了像 Kubernetes 这样的项目。现在,我们完全可以说 Go 是容器语言,这是另一个完全出乎意料的结果。
除了大名鼎鼎的Docker,完全用GO实现。业界最为火爆的容器编排管理系统kubernetes完全用GO实现。之后的Docker Swarm,完全用GO实现。
除此之外,还有各种有名的项目,如etcd/consul/fannel,七牛云存储等等 均使用GO实现。有人说,GO语言之所以出名,是赶上了云时代。但为什么不能换种说法?也是GO语言促使了云的发展。
除了云项目外,还有像今日头条、UBER这样的公司,他们也使用GO语言对自己的业务进行了彻底的重构。
小米的云监控open-falcon.org
安装
windows安装
https://golang.google.cn/dl
安装完成后,在设置的安装目录“C:\Program Files\Go”中生成一些目录和文件,如下图1-9所示。
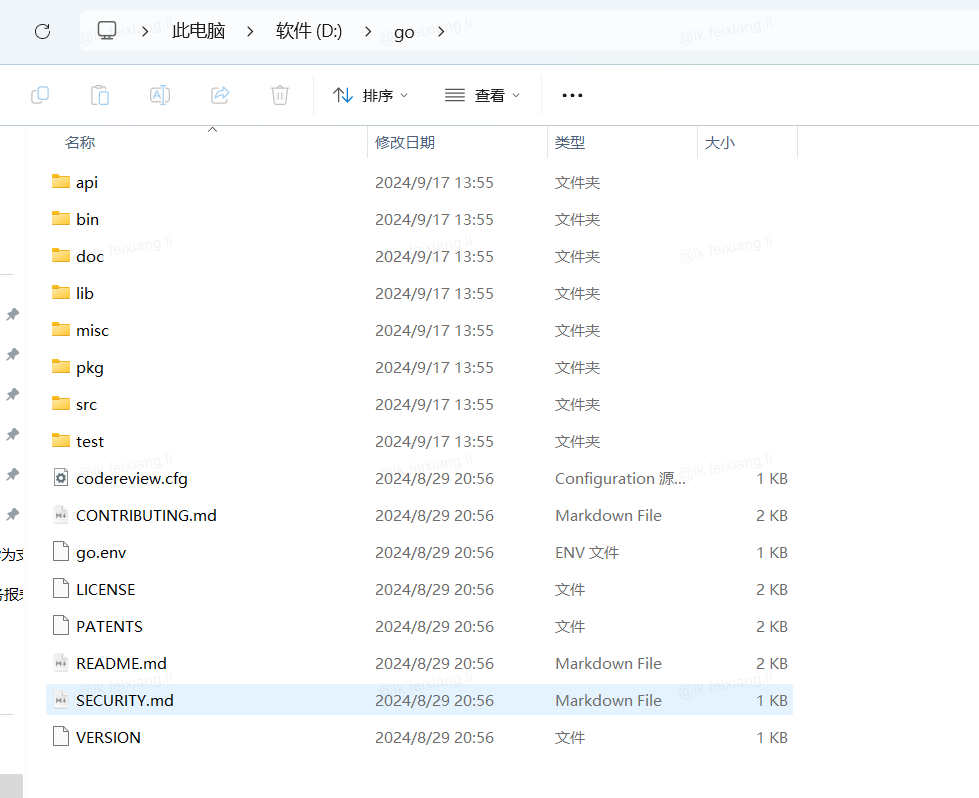
- api:每个版本的 api 变更差异。
- bin:go 源码包编译出的编译器(go)、文档工具(godoc)、格式化工具(gofmt)。
- doc:英文版的 Go 文档。
- lib:引用的一些库文件。
- misc 杂项用途的文件,例如 Android 平台的编译、git 的提交钩子等。
- pkg:Windows 平台编译好的中间文件。
- src:标准库的源码。
- test:测试用例。
在安装完成后,可以通过go env 命令检测是否安装成功。在“命令提示符”界面输入“go env”命令,如果显示如下类似结果则说明安装成功。
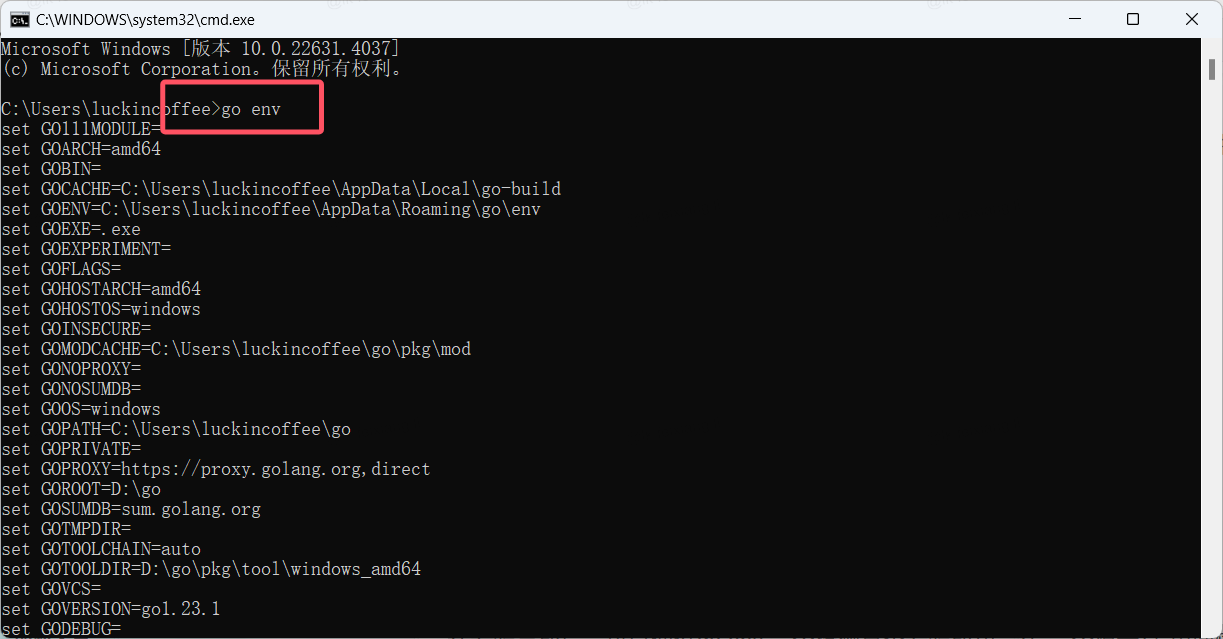
新建一下环境变量
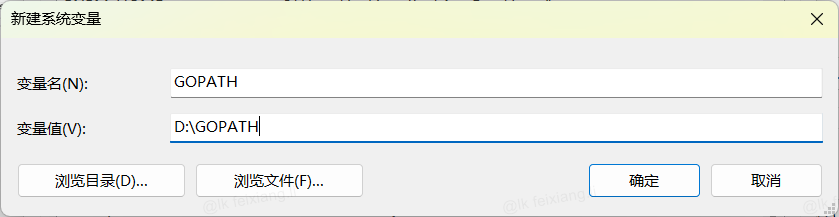
用户环境变量和系统环境变量一起修改一下
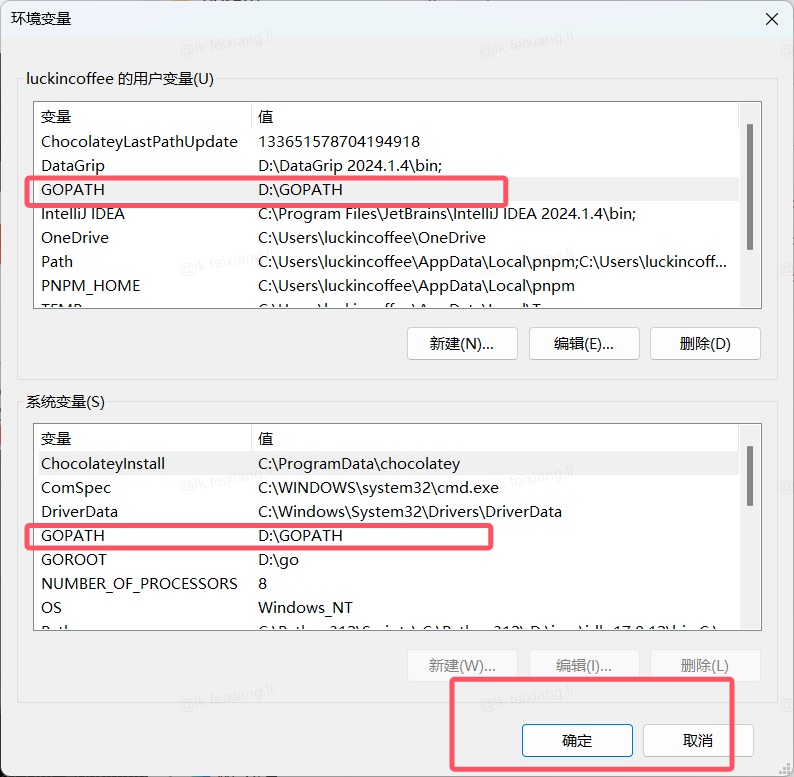
GOROOT 写的就是 安装go的目录位置
linux安装
登录Go语言官网https://golang.google.cn/dl下载Go语言开发包。
安装
cd /usr/local/
wget https://dl.google.com/go/go1.20.1.linux-amd64.tar.gz
tar -C /usr/local -xzf go1.20.3.linux-amd64.tar.gz
bin/go version
在任意目录下使用终端执行 go env 命令,输出如下结果说明Go语言开发包已经安装成功。
go env
编译工具安装-goland
https://www.jetbrains.com/go/
2. 入门
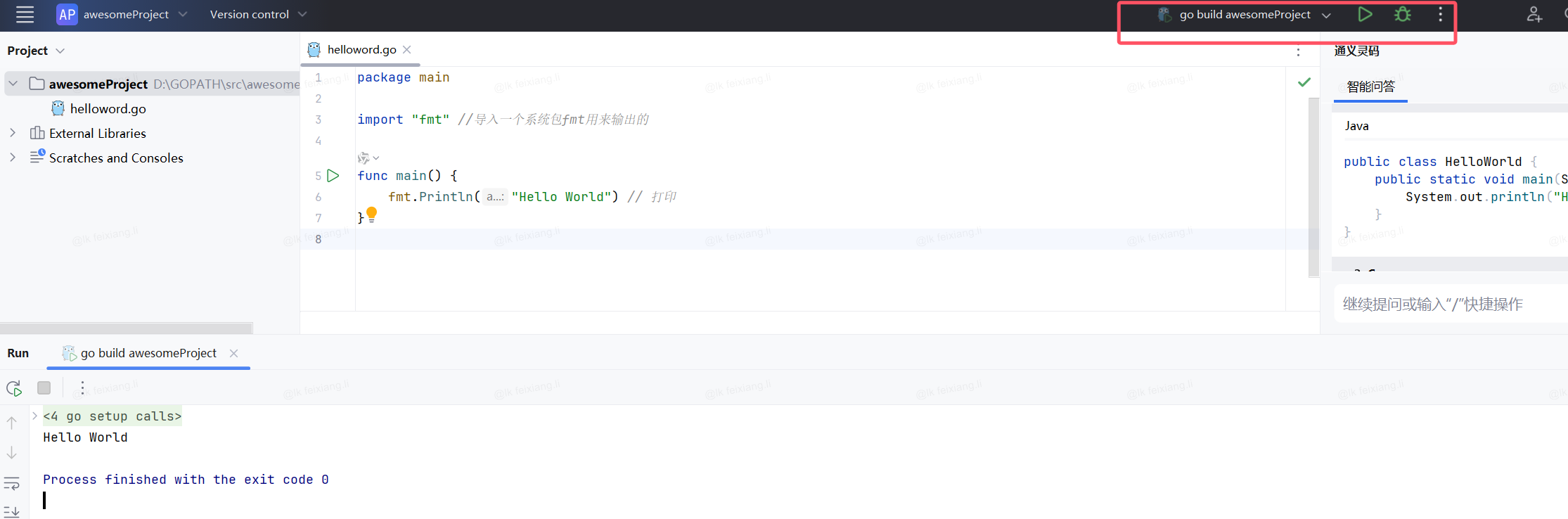
2.1 Helloworld
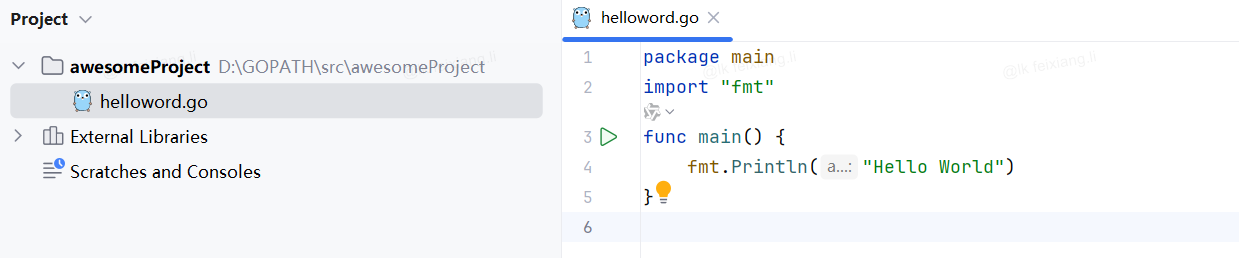
package mainimport "fmt"//导入一个系统包fmt用来输出的func main() {fmt.Println("Hello World") // 打印
}打开文件所在位置
go run helloword.go
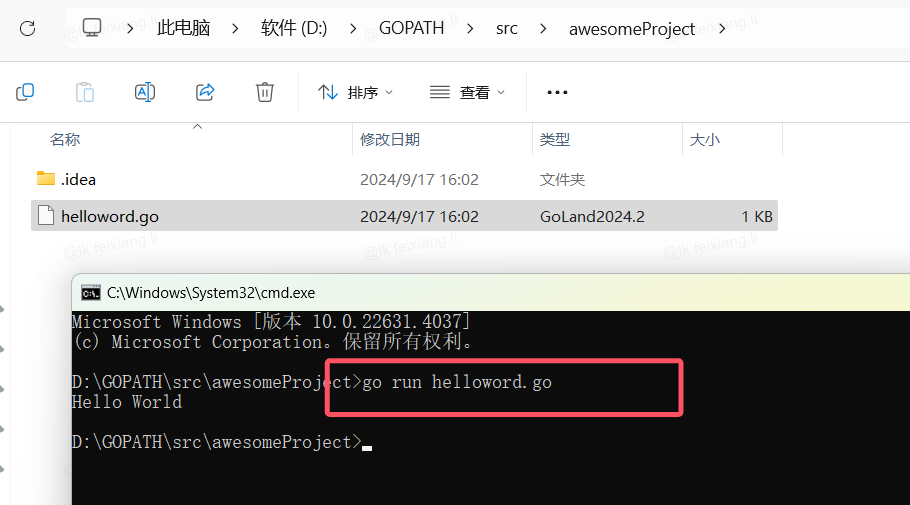
或者使用goland点击右上角的按钮
如果是新版本不需要设置,以下命令,也可以运行
go env -w GO111MODULE=off
注释
注释主要的功能就是为了增强代码的可读性,不参与程序的一切功能,Go语言的注释主要分成两类。
package main//导入一个系统包fmt用来输出的
import "fmt"func main() {// 单行注释fmt.Println("Hello World")/*** 文档注释*/fmt.Println("文档注释")/** 多行注释*/fmt.Println("多行注释")
}2.2 变量
Go语言是静态类型语言,就是所有的类型我们都需要明确的去定义。我们这里先不管其他类型,先了解string,我们用它来表示字符串!
在Go语言中,我们声明一个变量一般是使用 var 关键字:
var name type
- 第一个 var 是声明变量的关键字,是固定的写法,大家记住即可,你要声明一个变量,就需要一个 var。
- 第二个 name,就是我们变量的名字,你可以按照自己的需求给它定一个名字。用来后续使用!
- 第三个 type,就是用来代表变量的类型。
样例
package mainimport "fmt"func main() {// 定义一个字符串的变量var name string = "joker"// 对变量进行修改name = "修改后"// 定义一个数字的变量var age int = 18fmt.Println(name, age)
}如果你学过 Java、C或者其他编程语言,第一次看到这样的操作肯定不舒服。Go语言和许多编程语言不同,它在声明变量时将变量的类型放在变量的名称之后。这样做的好处就是可以避免像C语言中那样含糊不清的声明形式,例如:int*a,b;。其中只有a是指针而b不是。
如果你想要这两个变量都是指针,则需要将它们分开书写。而在 Go 中,则可以和轻松地将它们都声明为指针类型:
var a,b *int
变量的命名规则遵循骆驼命名法,即首个单词小写,每个新单词的首字母大写,例如:userfiles和 systemInfo。
我们有时候会批量定义变量,如果每次都单独定义比较麻烦,Go语言支持批量定义变量
package mainimport "fmt"func main() {// 变量声明var (address string = "中国"phone int = 123456789)fmt.Println(address, phone)
}当一个变量被声明之后,如果没有显示的给他赋值,系统自动赋予它该类型的零值:
- 整型和浮点型变量的默认值为 0和 0.0。
- 字符串变量的默认值为空字符串。
- 布尔型变量默认为 false。
- 切片、函数、指针变量的默认为 nil。
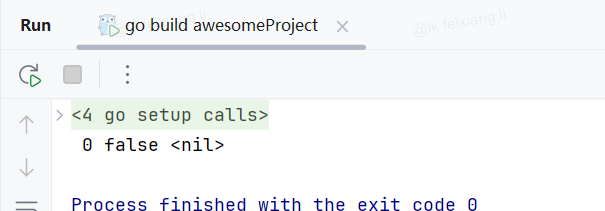
package mainimport "fmt"func main() {// 变量声明var (address stringphone intsex bool// 定义一个指针p *int)fmt.Println(address, phone, sex, p)
}运行出来的结果
初始化
var 变量名 类型=值(表达式)
比如,我想定义小k的一些信息,我可以这么表示
package mainimport "fmt"func main() {// 变量声明var (address string = "中国"phone int = 123456789sex bool = true// 定义一个指针p *int = new(int))fmt.Println(address, phone, sex, p)
}短变量声明并初始化
这是Go语言的推导声明写法,编译器会自动根据右值类型推断出左值的对应类型。
它可以自动的推导出一些类型,但是使用也是有限制的;
- 定义变量,同时显式初始化。
- 不能提供数据类型。
- 只能用在函数内部。不能随便到处定义(关于函数,我们后面会讲解,听一下就好这里)
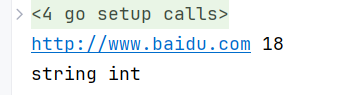
package mainimport "fmt"func main() {// := 自动推到address := "http://www.baidu.com"age := 18fmt.Println(address, age)// %T可以输出变量的类型fmt.Printf("%T %T", address, age)
}输出结果
因为简洁和灵活的特点,简短变量声明被广泛用于大部分的局部变量的声明和初始化。
注意:由于使用了:=,而不是赋值的=,因此推导声明写法的左值变量必须是没有定义过的变量。若定义过,将会发生编译错误。
// 定义变量 name
var name string
//定义变量 name,并赋值为"kuangshen"
name :="kuangshen
打印内存地址
取地址符号 &变量名字
package mainimport "fmt"func main() {var num intnum = 100fmt.Printf("num:%d,内存地址:%p \n", num, &num) // 取地址符 &变量名num = 200fmt.Printf("num:%d,内存地址:%p", num, &num) // 取地址符 &变量名
}点击运行
运行结果如下

变量交换
package mainimport "fmt"func main() {// 实现变量交换var a, b int = 1, 2fmt.Println(a, b)a, b = b, afmt.Println(a, b)}匿名变量
匿名变量的特点是一个下画线"_“,”_"本身就是一个特殊的标识符,被称为空白标识符。它可以像其他标识符那样用于变量的声明或赋值(任何类型都可以赋值给它),但任何赋给这个标识符的值都将被抛弃,因此这些值不能在后续的代码中使用,也不可以使用这个标识符作为变量对其它变量进行赋值或运算。使用匿名变量时,只需要在变量声明的地方使用下画线替换即可。例如:
package mainimport "fmt"/*
定义一个test函数,它会返回两个int类型的值,每次调用将会返回100和200 两个数值。
这里我们先不用管 函数的定义,后面会讲解,
我们用这个函数来理解这个匿名变量。
*/
func test() (int, int) {return 100, 200
}
func main() {// 实现变量交换a, _ := test()_, b := test()fmt.Printf("%d %d\n", a, b)
}在编码过程中,可能会遇到没有名称的变量、类型或方法。虽然这不是必须的,但有时候这样做可以极大地增强代码的灵活性,这些变量被统称为匿名变量。
匿名变量不占用内存空间,不会分配内存。匿名变量与匿名变量之间也不会因为多次声明而无法使用。
作用域
了解变量的作用域对我们学习Go语言来说是比较重要的,因为G0语言会在编译时检查每个变量是否使用过,一旦出现未使用的变量,就会报编译错误。如果不能理解变量的作用域,就有可能会带来一些不明所以的编译错误。
局部变量
package mainimport "fmt"func main() {//声明局部变量a和b并赋值var a int = 3var b int = 4//声明局部变量c 并计算 a和b 的和c := a + bfmt.Printf("a=%d,b=%d,c=%d\n", a, b, c) //a=3,b=4,c=7
}全局变量
在函数体外声明的变量称之为全局变量,全局变量只需要在一个源文件中定义,就可以在所有源文件中使用,当然,不包含这个全局变量的源文件需要使用“import”关键字引入全局变量所在的源文件之后才能使用这个全局变量。
全局变量声明必须以 var 关键字开头,如果想要在外部包中使用全局变量的首字母必须大写。
package mainimport "fmt"// 全局变量
var name intfunc aaa() {fmt.Println(name)
}func main() {//声明局部变量a和b并赋值var a int = 3var b int = 4//声明局部变量c 并计算 a和b 的和name = a + bfmt.Printf("a=%d,b=%d,c=%d\n", a, b, name) //a=3,b=4,c=7aaa()// 局部变量和全局变量 可以一样。但是会覆盖全局变量var name int = 10fmt.Printf("a=%d,b=%d,c=%d\n", a, b, name) //a=3,b=4,c=7
}2.3 常量
常量是一个简单值的标识符,在程序运行时,不会被修改的量,
常量中的数据类型只可以是布尔型、数字型(整数型、浮点型和复数)和字符串型。
const identifier [type]= value
你可以省略类型说明符 [type],因为编译器可以根据变量的值来推断其类型。
- 显式类型定义: const b string = “abc”
- 隐式类型定义: const b = "abc’
多个相同类型的声明可以简写为:
const c_namel,c_name2 =valuel,value2
例如
package mainimport "fmt"const age int = 1
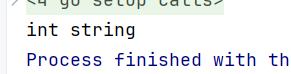
const name = "sss"func main() {fmt.Printf("%T %T", age, name)
}
iota
特殊常量,可以认为是一个可以被编译器修改的常量。iota是go语言的常量计数器
iota 在 const关键字出现时将被重置为 0(const 内部的第一行之前),const 中每新增一行常量声明将使 iota 计数一次(iota 可理解为 const 语句块中的行索引)。
iota 可以被用作枚举值:
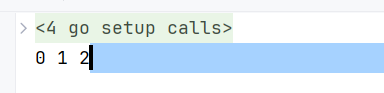
package mainimport "fmt"const (a = iotab = iotac = iota
)func main() {fmt.Printf("%d %d %d\n", a, b, c)
}
第二种情况?
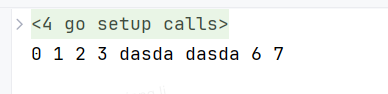
package mainimport "fmt"const (a = iotabcde = "dasda"fg = iotah
)func main() {fmt.Println(a, b, c, d, e, f, g, h)
}
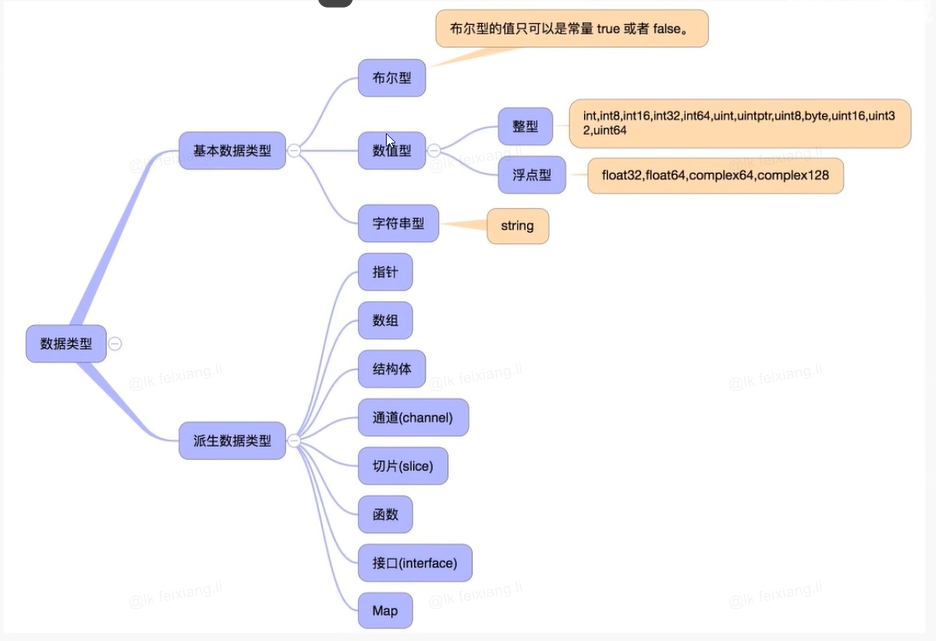
2.4 数据类型
| 类型 | 描述 |
|---|---|
| 布尔型 | 布尔型的值只可以是常量 true 或者 false。一个简单的例子:var b bool = true。 |
| 数字类型 | 整型 int 和浮点型 float,Go 语言支持整型和浮点型数字,并且原生支持复数,其中位的运算采用补码。 |
| 字符串类型 | 字符串就是一串固定长度的字符连接起来的字符序列。Go的字符串是由单个字节连接起来的。Go语言的字符串的字节使用UTF-8编码标识Unicode文本。 |
| 派生类型 | 包括:(a) 指针类型(Pointer) (b) 数组类型 © 结构体类型(struct) (d) 联合体类型 (union) (e) 函数类型 (f) 切片类型 (g) 接口类型(interface) (h) Map 类型 (i) Channel 类型 |
布尔
一个布尔类型的值只有两种:true 或 false。if 和 for 语句的条件部分都是布尔类型的值,并且==和<等比较操作也会产生布尔型的值。
一元操作符!对应逻辑非操作,因此!true的值为 false,更复杂一些的写法是(!true==false) ==true,实际开发中我们应尽量采用比较简洁的布尔表达式,就像用 x 来表示x==true。
package mainimport "fmt"func main() {var num = 10if num == 5 {fmt.Println("num == 5")} else {fmt.Println(num)}if num == 10 {fmt.Println("num == 10")} else {fmt.Println(num)}if num != 5 {fmt.Println("num != 5")} else {fmt.Println(num)}if num != 10 {fmt.Println("num != 10")} else {fmt.Println(num)}
}
// 结果如下
10
num == 10
num != 5
10
布尔值可以和 &&(AND)和 ||(OR)操作符结合,并且有短路行为,如果运算符左边的值已经可以确定整个布尔表达式的值,那么运算符右边的值将不再被求值,因此下面的表达式总是安全的:
短路行为:当有多个表达式(值)时,左边的表达式值可以确定结果时,就不再继续运算右边的表达式的值。
| 操作符 | 短路描述 |
|---|---|
| && | 当左边为True,还需要运算右边,结果由右边决定;当左边为Flase,不需要右边进行运算,结果为Flase |
| || | 当左边为True,不需要运算右边,结果为True;当左边为Flase,需要计算右边,结果由右边决定 |
package mainimport "fmt"func main() {var s1 string = "nihao"// if s1 == "nihao" && s1[0] == 'n' { //s1 符合要求// if s1 == "nihao" && s1[0] == 'x' { //s1 不符合要求// if s1 == "nihao" && s1[0] == "n" { // invalid operation: s1[0] == "n" (mismatched types byte and untyped string)// if s1 != "" && s1[0] == 'x' { // s1 不符合要求// if s1 != "" && s1[0] == 'n' { // s1 符合要求// if s1 == "nihao" || s1[0] == 'n' { //s1 符合要求// if s1 == "nihao" || s1[0] == 'x' { // s1 符合要求// if s1 != "" || s1[0] == 'x' { // s1 符合要求if s1 != "" || s1[0] == 'n' { // s1 符合要求fmt.Println("s1 符合要求")} else {fmt.Println("s1 不符合要求")}
}其中 s[0] 操作如果应用于空字符串将会导致 panic 异常(终端程序的异常)。
因为&&的优先级比||高(&& 对应逻辑乘法,|| 对应逻辑加法,乘法比加法优先级要高),所以下面的布尔表达式可以不加小括号:
if 'a' <= c && c <= 'z' ||'A' <= c && c <= 'Z' ||'0' <= c && c <= '9' {// ...ASCII字母或数字...
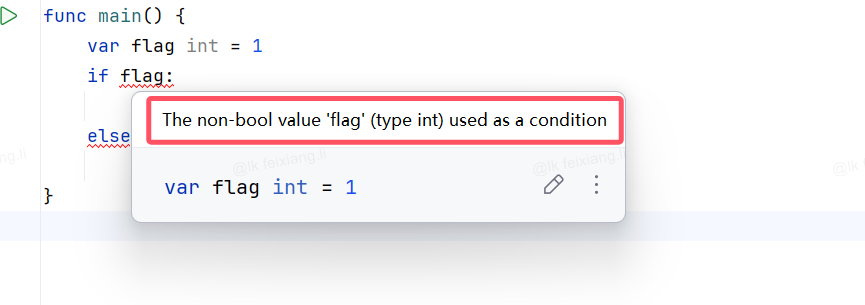
}布尔值并不会隐式转换为数字值 0 或 1,反之亦然,必须使用 if 语句显式的进行转换:
如果需要经常做类似的转换,可以将转换的代码封装成一个函数,如下所示:
// 如果b为真,btoi返回1;如果为假,btoi返回0
func btoi(b bool) int {if b {return 1}return 0
}
数字到布尔型的逆转换非常简单,不过为了保持对称,我们也可以封装一个函数:
// itob报告是否为非零。
func itob(i int) bool { return i != 0 }
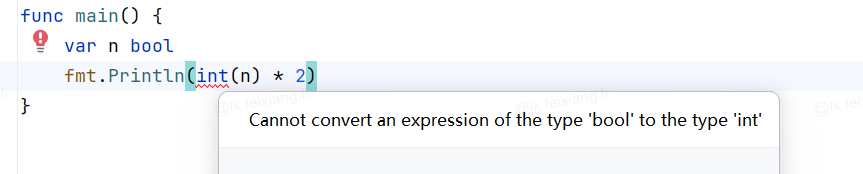
Go语言中不允许将整型强制转换为布尔型,代码如下:
var n bool
fmt.Println(int(n) * 2)
编译错误,输出如下:
Go语言的数值类型分为以下几种:整数、浮点数、复数,其中每一种都包含了不同大小的数值类型,例如有符号整数包含 int8、int16、int32、int64 等,每种数值类型都决定了对应的大小范围和是否支持正负符号。
整数
Go语言同时提供了有符号和无符号的整数类型,其中包括 int8、int16、int32 和 int64 四种大小截然不同的有符号整数类型,分别对应 8、16、32、64 bit(二进制位)大小的有符号整数,与此对应的是 uint8、uint16、uint32 和 uint64 四种无符号整数类型。
| 序号 | 类型和描述 | |
|---|---|---|
| uint8 | 无符号8 位整型 (0 到 255) | |
| uint16 | 无符号 16 位整型 (0 到 65535) | |
| uint32 | 无符号 32 位整型 (0 到 4294967295) | |
| uint64 | 无符号64 位整型(0到18446744073709551615) | |
| int8 | 有符号 8 位整型(-128 到 127) | |
| int16 | 有符号 16 位整型 (-32768 到32767) | |
| int32 | 有符号 32 位整型(-2147483648 到21474836478) | |
| int64 | 有符号64 位整型(-9223372036854775808到9223372036854775807) |
还有其他类型
| 序号 | 类型和描述 | |
|---|---|---|
| 1 | byte 类似 uint8 | |
| 2 | rune 类似 int32 | |
| 3 | uint 32 或 64 位 | |
| 4 | int 与 uint 一样大小 | |
| 5 | uintptr 无符号整型,用于存放一个指针 |
浮点类型
Go语言提供了两种精度的浮点数 float32 和 float64,它们的算术规范由 IEEE754 浮点数国际标准定义,该浮点数规范被所有现代的 CPU 支持。
这些浮点数类型的取值范围可以从很微小到很巨大。浮点数取值范围的极限值可以在 math 包中找到:
- 常量
math.MaxFloat32表示float32能取到的最大数值,大约是3.4e38; - 常量
math.MaxFloat64表示float64能取到的最大数值,大约是1.8e308; float32和float64能表示的最小值分别为1.4e-45和4.9e-324。
一个 float32 类型的浮点数可以提供大约 6 个十进制数的精度,而 float64 则可以提供约 15 个十进制数的精度,通常应该优先使用 float64 类型,因为 float32 类型的累计计算误差很容易扩散,并且 float32 能精确表示的正整数并不是很大。如下:
package mainimport "fmt"func main() {var f float32 = 16777216 // 1 << 24var f1 float64 = 16777216fmt.Println(f) // 1.6777216e+07fmt.Println(f1) // 1.6777216e+07fmt.Println(f +1) // 1.6777216e+07fmt.Println(f == f+1) // truefmt.Println(f1 + 1) // 1.6777217e+07fmt.Println(f1 == f1 + 1) // false
}浮点数在声明的时候可以只写整数部分或者小数部分,像下面这样:
const e = .71828
const f = 1.
fmt.Println(e) // 0.71828
fmt.Println(f) // 1很小或很大的数最好用科学计数法书写,通过 e 或 E 来指定指数部分:
const Avogadro = 6.02214129e23 // 阿伏伽德罗常数
const Planck = 6.62606957e-34 // 普朗克常数
用 Printf 函数打印浮点数时可以使用%f来控制保留几位小数
package mainimport ("fmt""math"
)func main() {fmt.Printf("%f\n", math.Pi) // 3.141593fmt.Printf("%.2f\n", math.Pi) // 3.14
}复数
复数是由两个浮点数表示的,其中一个表示实部(real),一个表示虚部(imag)。
Go语言中复数的类型有两种,分别是 complex128(64 位实数和虚数)和 complex64(32 位实数和虚数),其中 complex128 为复数的默认类型。
复数的值由三部分组成 RE + IMi,其中 RE 是实数部分,IM 是虚数部分,RE 和 IM 均为 float 类型,而最后的 i 是虚数单位。
声明复数的语法格式如下所示:
var name complex128 = complex(x, y)
其中 name 为复数的变量名,complex128 为复数的类型,"="后面的 complex 为Go语言的内置函数用于为复数赋值,x、y 分别表示构成该复数的两个 float64 类型的数值,x 为实部,y 为虚部。
上面的声明语句也可以简写为下面的形式:
name := complex(x, y)
对于一个复数z := complex(x, y),可以通过Go语言的内置函数real(z) 来获得该复数的实部,也就是 x;通过imag(z) 获得该复数的虚部,也就是 y。
使用内置的 complex 函数构建复数,并使用 real 和 imag 函数返回复数的实部和虚部:
var x complex128 = complex(1, 2) // 1+2i
var y complex128 = complex(3, 4) // 3+4i
fmt.Println(x*y) // "(-5+10i)"
fmt.Println(real(x*y)) // "-5"
fmt.Println(imag(x*y)) // "10"
复数也可以用==和!=进行相等比较,只有两个复数的实部和虚部都相等的时候它们才是相等的。
Go语言内置的 math/cmplx 包中提供了很多操作复数的公共方法,实际操作中建议大家使用复数默认的 complex128 类型,因为这些内置的包中都使用 complex128 类型作为参数。
字符串
一个字符串是一个不可改变的字节序列,字符串可以包含任意的数据,但是通常是用来包含可读的文本,字符串是 UTF-8 字符的一个序列(当字符为 ASCII 码表上的字符时则占用 1 个字节,其它字符根据需要占用 2-4 个字节)。
定义字符串
可以使用双引号""来定义字符串,字符串中可以使用转义字符来实现换行、缩进等效果,常用的转义字符包括:
- \n:换行符
- \r:回车符
- \t:tab 键
- \u 或 \U:Unicode 字符
- \:反斜杠自身
package mainimport "fmt"func main() {var s string = "hello Jack!"var s1 string = "hello \nJack!"var s2 string = "hello \rJack!"var s3 string = "hello \tJack!"var s4 string = "hello \\Jack!"fmt.Println(s)fmt.Println(s1)fmt.Println(s2)fmt.Println(s3)fmt.Println(s4)
}// 结果如下:
hello Jack!
hello
Jack!
Jack!
hello Jack!
hello \Jack!
一般的比较运算符(==、!=、<、<=、>=、>)是通过在内存中按字节比较来实现字符串比较的,因此比较的结果是字符串自然编码的顺序。字符串所占的字节长度可以通过函数 len() 来获取,例如 len(str)。
var s string = "hello Jack!"
var s1 string = "hello \nJack!"
fmt.Println(len(s)) // 11
fmt.Println(len(s1)) // 12字符串的内容(纯字节)可以通过标准索引法来获取,在方括号[ ]内写入索引,索引从 0 开始计数:
- 字符串 str 的第 1 个字节:str[0]
- 第 i 个字节:str[i - 1]
- 最后 1 个字节:str[len(str)-1]
需要注意的是,这种转换方案只对纯 ASCII 码的字符串有效。
注意:获取字符串中某个字节的地址属于非法行为,例如 &str[i]。
var s string = "hello Jack!"
fmt.Println(s[3]) //108
fmt.Println(s[4]) //111
字符串拼接符+
两个字符串 s1 和 s2 可以通过 s := s1 + s2 拼接在一起。将 s2 追加到 s1 尾部并生成一个新的字符串 s。
可以通过下面的方式来对代码中多行的字符串进行拼接:
str := "Beginning of the string " +
"second part of the string"
fmt.Println(str01)
// 因为编译器会在行尾自动补全分号,所以拼接字符串用的加号“+”必须放在第一行末尾
也可以使用+=来对字符串进行拼接:
str02 := "hel" + "lo"
fmt.Println(str02)
str02 += " world"
fmt.Println(str02)
定义多行字符串
在Go语言中,使用双引号书写字符串的方式是字符串常见表达方式之一,被称为字符串字面量(string literal),这种双引号字面量不能跨行,如果想要在源码中嵌入一个多行字符串时,就必须使用`反引号,代码如下:
str_more := `first line
second line`
fmt.Println(str_more)first line
second line
map数据类型
map类型是一个K/V键值对存储的数据类型,key通过hash算法生成hash值,hash值的低位取模槽位(可以理解为容量,go的底层存储是hash表,表中有多个表节点,即槽位,一个槽位最多存放8对K/V组合,如果存储满了通过overflow指向下一个槽位),获取value存储的槽位的节点,通过高位查询节点中的数据。
map的初始化
package mainimport "fmt"func main() {var m1 map[string]int // 声明map, 指定key的数据类型是string,value的数据类型是intm2 := make(map[string]int) // 初始化,容量是0m3 := make(map[string]int, 200) // 初始化,容量是200,建议初始化时指定map的容量,减少map扩容m4 := map[string]int{"语文": 2, "数学": 3} // 初始化时赋值fmt.Println(m1, m2, m3, m4)
}map的添加和删除
m := map[string]int{"语文": 2, "数学": 3} // 初始化时赋值m["英语"] = 10 // 向map中添加数据m["英语"] = 20 // 向map中添加数据,如果key之前有值,会覆盖之前的value数据delete(m, "英语") // 从map中删除key对应的键值对数据len(m) // 获取map的长度// map不支持使用cap函数
map的查询
value := m["语文"]
fmt.Println(value)
遍历
m := map[string]int{"语文": 2, "数学": 3}
for key, value := range m {fmt.Printf("key = %s, value = %d\n", key, value)
}
channel管道
管道是一个环形先进先出的队列,send(插入)和recv(取走)从同一个位置沿同一个方向顺序执行。
sendx:表示最后一次插入元素的位置。
recvx:表示最后一次取走元素的位置。
管道的初始化
// ch 定义的管道变量
// chan 管道类型关键字
// int 管道里面存放的数据类型
var ch chan int
管道的初始化
// 管道的环形队列里面可容纳8个int类型的长度
ch = make(chan int, 8)
管道的声明时初始化
var ch = make(chan int, 8)
向管道中插入数据 // 管道写满后再写入会阻塞报错,没有自动扩容的这种机制
// 向管道中插入元素,使用 <- 符号
// 语法: 变量 <- 要插入的数据
ch <- 10
ch <- 20
ch <- 50
从管道中取出数据 // 管道写满后,不可以再写入,有数据被取出后,可以再向管道中写
// 向管道中取出元素
// 语法: 赋值变量 = <-管道变量
var v = <-ch
fmt.Println(v)
v = <-ch
fmt.Println(v)
v = <-ch
fmt.Println(v)
遍历
// 遍历管道,遍历管道中剩余的元素
close(ch) // range方式遍历前必须先关闭管道,禁止再写入元素
for value := range ch {fmt.Println(value)
}
2.5 运算符
1) 数据类型转换
在必要以及可行的情况下,一个类型的值可以被转换成另一种类型的值。由于Go语言不存在隐式类型转换,因此所有的类型转换都必须显式的声明:
valueofTypeB =typeB(valueofTypeA)
例子
package mainimport "fmt"func main() {var a float32 = 10.00b := int(a)fmt.Println(a)fmt.Println(b)fmt.Println("Hello, world!")
}类型转换只能在定义正确的情况下转换成功,例如从一个取值范围较小的类型转换到一个取值范围较大的类型(将int16 转换为 int32)。当从一个取值范围较大的类型转换到取值范围较小的类型时(将 int32 转换为 int16 或将 foat32 转换为int),会发生精度丢失(截断)的情况。
整形是不能转换成bool类型。字符串类型不能强转成int类型
2) 算术运算符
下表列出了所有Go语言的算术运算符。假定 A值为 10,B值为 20。
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 相加 | A+B 输出结果 30 |
| - | 相减 | A-B输出结果 -10 |
| * | 相乘 | A*B输出结果 200 |
| / | 相除 | B/A输出结果2 |
| % | 求余 | B%A输出结果 0 |
| ++ | 自增 | A++ 输出结果 11 |
| – | 自减 | A–输出结果 9 |
例子
package mainimport "fmt"func main() {var a int = 20var b int = 10fmt.Println(a + b)fmt.Println(a - b)fmt.Println(a * b)fmt.Println(a / b)fmt.Println(a % b)a++fmt.Println(a)a=20a--fmt.Println(a)}3) 关系运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| == | 检查两个值是否相等,如果相等返回 True 否则返回 False。 | (A == B)为 False |
| != | 检查两个值是否不相等,如果不相等返回 True 否则返回 False. | (A!= B)为 True |
| > | 检查左边值是否大于右边值,如果是返回 True 否则返回 False。 | (A>B)为 False |
| < | 检查左边值是否小于右边值,如果是返回True 否则返回 False。 | (A<B) 为 True |
| >= | 检查左边值是否大于等于右边值,如果是返回 True 否则返回 False。 | (A >= B)为 False |
| <= | 检查左边值是否小于等于右边值,如果是返回 True 否则返回 False。 | (A<= B)为 True |
例子
package mainimport "fmt"func main() {var A int = 20var B int = 10fmt.Println("A==B:", A == B)fmt.Println("A!=B:", A != B)fmt.Println("A>B:", A > B)fmt.Println("A<B:", A < B)fmt.Println("A>=B:", A >= B)fmt.Println("A<=B:", A <= B)}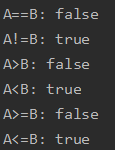
4) 逻辑运算符
| 运算符 | 描述 | 实例(A 为 true,B 为 false。) |
|---|---|---|
| && | 逻辑与运算符。 如果两边的操作数都是 true,则条件 true,否则为 false。 | (A && B) 为 false |
| ! | 逻辑非运算符。 如果条件为 true,则逻辑 NOT 条件 false,否则为 true。 | !(A && B) |
例子
C := trueD := falsefmt.Println("C&&D:",C&&D)fmt.Println("C||D:",C||D)fmt.Println("!(C&&D):",!(C&&D))5) 位运算符
| 运算符 | 描述 | 实例(A为60,B为13) |
|---|---|---|
| & | 按位与运算符"&"是双目运算符。 其功能是参与运算的两数各对应的二进位相与。 | (A & B) 结果为 12, 二进制为 0000 1100 |
| ^ | 按位异或运算符"^"是双目运算符。 其功能是参与运算的两数各对应的二进位相异或,当两对应的二进位相异时,结果为1。 | (A ^ B) 结果为 49, 二进制为 0011 0001 |
| << | 左移运算符"<<“是双目运算符。左移n位就是乘以2的n次方。 其功能把”<<“左边的运算数的各二进位全部左移若干位,由”<<"右边的数指定移动的位数,高位丢弃,低位补0。 | A << 2 结果为 240 ,二进制为 1111 0000 |
| >> | 右移运算符">>“是双目运算符。右移n位就是除以2的n次方。 其功能是把”>>“左边的运算数的各二进位全部右移若干位,”>>"右边的数指定移动的位数,低位丢弃,高位补符号位。 | A >> 2 结果为 15 ,二进制为 0000 1111 |
例子
package mainimport "fmt"func main() {var A, B intA, B = 60, 13fmt.Println("A&B:", A&B)fmt.Println("A|B:", A|B)fmt.Println("A^B:", A^B)fmt.Println("A<<2:", A<<2)fmt.Println("A>>2:", A>>2)}结果如下

6) 赋值运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 简单的赋值运算符,将一个表达式的值赋给一个左值 | C = A + B 将 A + B 表达式结果赋值给 C |
| += | 相加后再赋值 | C += A 等价于 C = C + A |
| -= | 相减后再赋值 | C -= A 等价于 C = C - A |
| *= | 相乘后再赋值 | C *= A 等价于 C = C * A |
| /= | 相除后再赋值 | C /= A 等价于 C = C / A |
| %= | 求余后再赋值 | C %= A 等价于 C = C % A |
| <<= | 左移后赋值 | C <<= 2 等价于 C = C << 2 |
| >>= | 右移后赋值 | C >>= 2 等价于 C = C >> 2 |
| &= | 按位与后赋值 | C &= 2 等价于 C = C & 2 |
| ^= | 按位异或后赋值 | C ^= 2 等价于 C = C ^ 2 |
| |= | 按位或后赋值 |
例子
package mainimport "fmt"func main() {var A int = 20var B int = 10var E intE = A + Bfmt.Println("E:", E)E += Afmt.Println("E += A:", E)E -= Afmt.Println("E -= A:", E)E *= Afmt.Println("E *= A:", E)E /= Afmt.Println("E /= A:", E)E %= Afmt.Println("E %= A:", E)E <<= 2fmt.Println("E <<= 2:", E)E >>= 2fmt.Println("E >>= 2:", E)E &= 2fmt.Println("E &= 2:", E)E ^= 2fmt.Println("E ^= 2:", E)E |= 2fmt.Println("E |= 2:", E)}2.6 获取键盘输入
第一种方式
package mainimport "fmt"func main() {var x intvar y float64fmt.Println("请输入两个数,1.整数,2.浮点数")fmt.Scan(&x, &y)fmt.Printf("整数是%d,浮点数是%f", x, y)
}第二种方式
package mainimport ("bufio""fmt""os""strconv""strings"
)func main() {reader := bufio.NewReader(os.Stdin)fmt.Print("请输入数字,以空格分隔: ")input, err := reader.ReadString('\n')if err != nil {fmt.Fprintln(os.Stderr, "读取输入时发生错误:", err)return}// 移除末尾的换行符input = strings.TrimSuffix(input, "\n")// 分割输入的字符串,以空格为分隔符numbers := strings.Split(input, " ")// 将字符串数组转换为整数数组var intNumbers []intfor _, numStr := range numbers {num, err := strconv.Atoi(numStr)if err != nil {fmt.Fprintln(os.Stderr, "转换数字时发生错误:", err)return}intNumbers = append(intNumbers, num)}// 倒序输出数字for i := len(intNumbers) - 1; i >= 0; i-- {fmt.Println(intNumbers[i])}
}2.7 流程控制
1) 顺序控制
顺序控制是最基本的流程控制,程序按照从上到下的顺序逐行执行。在Go语言中,如果中间没有任何判断和跳转语句,程序就会按照这种默认的顺序执行。
package mainimport "fmt"func main() {var num1 int = 10var num2 int = num1 + 20fmt.Println(num2) // 输出:30
}在这个例子中,程序首先定义了变量num1并赋值为10,然后定义num2并赋值为num1 + 20,最后打印出num2的值。这个过程完全按照代码的顺序执行,没有任何跳转或条件判断。
2) 条件控制
if
条件控制语句用于根据条件表达式的真假来决定是否执行某段代码。Go语言提供了if、if-else、if-else if-else等结构来实现条件控制。
语法格式
if 条件表达式 {// 条件为真时执行的代码
}示例代码:
package mainimport "fmt"func main() {a := 10if a < 20 {fmt.Println("a 小于 20")}fmt.Println("a 的值为:", a)
}
// 输出:a 小于 20
// a 的值为: 10if-else 语句
if-else语句用于在条件表达式为真时执行一段代码,否则执行另一段代码。
语法结构
if 条件表达式 {// 条件为真时执行的代码
} else {// 条件为假时执行的代码
}实例
package mainimport "fmt"func main() {a := 100if a < 20 {fmt.Println("a 小于 20")} else {fmt.Println("a 不小于 20")}fmt.Println("a 的值为:", a)
}
// 输出:a 不小于 20
// a 的值为: 100if else-if else 语法
if-else if-else语句用于处理多个条件分支,当某个条件满足时,执行相应的代码块。
语法
if 条件表达式1 {// 条件表达式1为真时执行的代码
} else if 条件表达式2 {// 条件表达式1为假且条件表达式2为真时执行的代码
} else {// 所有条件都不满足时执行的代码
}示例代码
package mainimport "fmt"func main() {x := 5if x > 10 {fmt.Println("x 大于 10")} else if x < 5 {fmt.Println("x 小于 5")} else {fmt.Println("x 等于 5")}
}
// 输出:x 等于 5实战
package mainimport "fmt"// 命令行程序 go build xxx.go 生成可执行程序。
func main() {// 练习:if的练习// 判断用户密码输入是否正确// 输入框 : 接收用户的输入 (新知识)// 第一次判断// 输入框 :请再次输入密码 接收用户的输入 (新知识)// 第二次判断// 如果两次都是对的,那么则登录成功//var num1 intvar num2 int// 提示用户输入fmt.Printf("请输入密码 : \n")//fmt.Scan() 输入。传入的是指针对象,即是内存地址// 接收用户的输入 (阻塞式等待... 直到用户输入之后才继续运行)最简单的人机交互// Scan() &num1地址,fmt.Scan(&num1) // 等待你的输入,卡住... 如果你输入完毕,回车。输入内容就会赋值给num// 123456 模拟数据,未来是在数据库中查询出来的。根据用户查的if num1 == 123456 {fmt.Println("请再次输入密码: ")fmt.Scan(&num2)if num2 == 123456 {fmt.Println("登录成功")} else {fmt.Println("登录失败")}} else {fmt.Println("登录失败")}}3) 循环控制-for
Go语言中的for循环是唯一的循环结构,但它足够灵活,可以模拟传统的while和do-while循环。
for 初始化语句; 条件表达式; 迭代语句 {// 循环体
}示例代码
package mainimport "fmt"func main() {for i := 0; i < 5; i++ {fmt.Println(i)}
}
// 输出:0
// 1
// 2
// 3
// 4模拟while循环
package mainimport "fmt"func main() {x := 5for x > 0 {fmt.Println(x)x--}
}
// 输出:5
// 4
// 3
// 2
// 1无限循环
package mainimport ("fmt""time"
)func main() {for {fmt.Println("This will run indefinitely!")//每隔一秒执行一次time.Sleep(1 * time.Second)// 通常这里会加入某种条件来跳出循环// 例如通过break语句}
}for-range 循环
for-range循环是Go语言中处理集合(如数组、切片、字符串、映射)的便捷方式。它会自动迭代集合中的每个元素,并返回元素的索引和值(对于映射,则返回键和值)。
for 索引, 值 := range 集合 {// 循环体
}实例代码
package mainimport "fmt"func main() {nums := []int{1, 2, 3, 4, 5}for idx, num := range nums {fmt.Printf("Index: %d, Value: %d\n", idx, num)}
}
// 输出:Index: 0, Value: 1
// Index: 1, Value: 2
// Index: 2, Value: 3
// Index: 3, Value: 4
// Index: 4, Value: 5打印九九乘法表
package mainimport "fmt"func main() {for i := 1; i < 10; i++ {for j := 1; j <= i; j++ {fmt.Printf("%d * %d = %d\t", j, i, i*j)}fmt.Println()}
}4) 分支控制
分支控制语句用于根据不同的条件执行不同的代码块。Go语言提供了switch语句来实现分支控制,并允许在switch语句中进行类型匹配(type switch)。
switch
switch语句基于不同的条件执行不同的代码块,与if-else系列语句相比,它在处理多个条件时更为清晰和简洁。
switch 表达式 {
case 值1:// 表达式等于值1时执行的代码
case 值2, 值3:// 表达式等于值2或值3时执行的代码
default:// 表达式与所有case都不匹配时执行的代码
}示例代码
package mainimport "fmt"func main() {grade := "B"switch grade {case "A":fmt.Println("优秀")case "B", "C":fmt.Println("良好")case "D":fmt.Println("及格")default:fmt.Println("不及格")}
}
// 输出:良好case穿透
特殊的情况:需要多个条件结果的输出,case穿透 。fallthrough
在case中 一旦使用了 fallthrough,则会强制执行下一个case语句,不会去判断条件的。
package mainimport "fmt"func main() {grade := "B"switch grade {case "A":fmt.Println("优秀")case "B", "C":fmt.Println("良好")//在case中 一旦使用了 fallthrough,则会强制执行下一个case语句,不会去判断条件的fallthroughcase "D":fmt.Println("及格")default:fmt.Println("不及格")}
}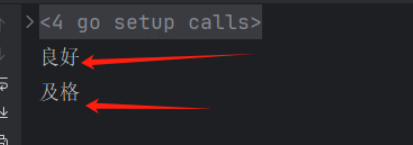
可以看到,grade满足case “B”, “C”,走了这个分支后,又走了下面一个分支case “D”
fallthrough实现了case穿透
5) 跳转控制
跳转控制语句用于改变程序的正常执行流程,Go 语言提供了 goto、break 和 continue 语句来实现跳转控制。
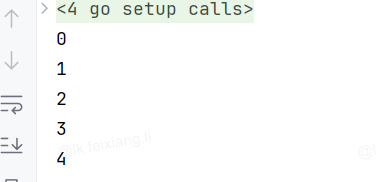
goto语句
goto 标签名
...
标签名:
// 代码块示例代码(尽管不推荐,但展示其用法):
package mainimport "fmt"func main() {i := 0
HERE:fmt.Println(i)i++if i < 5 {goto HERE}
}// 输出:从0到4的连续数字结果
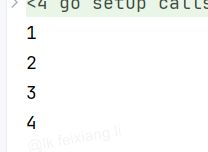
break语句
break : 结束整个循环,立即停止
continue :结束当前这次循环,继续进行下一次循环
package mainimport "fmt"func main() {for i := 1; i <= 10; i++ {if i == 5 {break}fmt.Println(i)}}i=5的时候退出循环
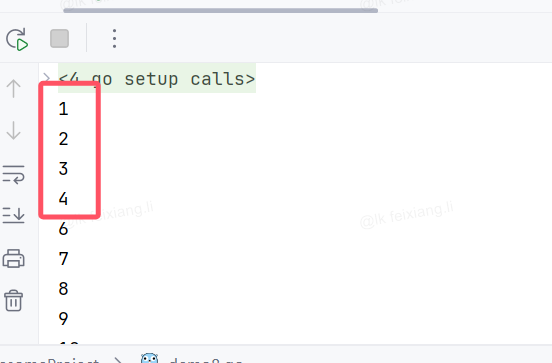
continue
continue语句用于跳过当前循环的剩余部分,直接进入下一次迭代。同样,continue仅影响最近的一层循环。
package mainimport "fmt"func main() {for i := 1; i <= 10; i++ {if i == 5 {continue // 到这里就结束了当次循环,不会向下了,继续从头开始}fmt.Println(i)}}结果如下,缺少5
2.8 函数
什么是函数?
- 函数是基本的代码块,用于执行一个任务,
- Go 语言最少有个 main() 函数。
- 你可以通过函数来划分不同功能,逻辑上每个函数执行的是指定的任务。
- 函数声明告诉了编译器函数的名称,返回类型,和参数。
普通函数声明
函数声明包括函数名、形式参数列表(可省略)、返回值列表(可省略)以及函数体。
注:函数声明时传入的参数叫形参,函数被调用时传入的实际参数叫实参,参数的传递会发生值拷贝(深拷贝),如果形参定义的是指针类型,那就是浅拷贝。
func function_name([parameter list]) [return_types]
{}
- 无参无返回值函数
- 有一个参数的函数
- 有两个参数的函数
- 有一个返回值的函数
- 有多个返回值的函数
例子
// 定义无参,无返回值
func hello() {fmt.Println("Hello GoLang")
}// 调用
hello()
案例
package mainimport "fmt"// 定义有一个参数的函数
func printArr(arr *[5]int) {for i := 0; i < len(arr); i++ {arr[i] = i}
}// 定义两个参数的函数, 返回一个int
func add2(a, b int) int {return a + b
}func main() {// 定义了var arr1 [5]intprintArr(&arr1)fmt.Println(arr1)fmt.Println(add2(1, 2))
}匿名函数
Go语言支持匿名函数,即在需要使用函数时再定义函数,匿名函数没有函数名只有函数体,函数可以作为一种类型被赋值给函数类型的变量,匿名函数也往往以变量方式传递,这与C语言的回调函数比较类似,不同的是,Go语言支持随时在代码里定义匿名函数。
语法
func(参数列表)(返回参数列表){函数体
}
实例
// 定义匿名函数后,把函数赋值给变量
func main() {f := func(data int) {fmt.Println("hello", data)}// 使用f()调用,相当于 f 就是函数名f(100)
}
实例2
func main() {// 定义匿名函数,后面的 (100) 表示定义后直接调用func(data int) {fmt.Println("hello", data)}(100)
}
闭包
Go语言中闭包是引用了自由变量的函数,被引用的自由变量和函数一同存在,即使已经离开了自由变量的环境也不会被释放或者删除,在闭包中可以继续使用这个自由变量,因此,简单的说:函数 + 引用环境 = 闭包.
语法
func 函数名(形式参数列表) 返回值是匿名函数 {return 匿名函数
}
实例
被捕获到闭包中的变量让闭包本身拥有了记忆效应,闭包中的逻辑可以修改闭包捕获的变量,变量会跟随闭包生命期一直存在,闭包本身就如同变量一样拥有了记忆效应。
func Accumulate(value int) func() int {// 返回一个闭包return func() int {// 累加value++// 返回一个累加值return value}
}
func main() {// 创建一个累加器, 初始值为1accumulator := Accumulate(1)// 第一次调用 值累加fmt.Println(accumulator()) // 2// 第二次调用,值在上一次累加的基础上再累加,并不是重新计算,所以叫有记忆fmt.Println(accumulator()) // 3
}
defer 延迟调用
Go语言的 defer 语句会将其后面跟随的语句进行延迟处理,在 defer 归属的函数即将返回时,将延迟处理的语句按 defer 的逆序进行执行,也就是说,先被 defer 的语句最后被执行,最后被 defer 的语句,最先被执行。
关键字 defer 的用法类似于面向对象编程语言 Java 和 C# 的 finally 语句块,它一般用于释放某些已分配的资源,典型的例子就是对一个互斥解锁,或者关闭一个文件。
注意点
- defer一般用于释放某些已分配的资源,典型的例子就是对一个互斥解锁,或者关闭一个文件。类似面向对象编程的语言 Java 和 C# 的 finally 语句块。
- 如果同一个函数里有多个defer,则后注册的先执行(写在后面的先执行)。
- defer后可以跟一个func,func内部如果发生panic,会把panic暂时搁置,当把其他defer执行完成后再执行panic。
- defer后跟一条执行语句,则相关变量在注册defer时被拷贝或计算。
实例
func main() {// 执行顺序 A B C D Efmt.Println("A")defer fmt.Println("E")fmt.Println("B")defer fmt.Println("D")fmt.Println("C")
}
实例2
/*
执行顺序 A B C D
代码解释:
*** 先执行A return 10,表示 返回值变量 a 的值已经从5 变为10了
//
*** 再执行B ,为什么结果会打印5,而不是10呢?上面不是所把5赋值成10了吗? 这里要说的就是相关变量在注册时(编译)就计算好了a的值
*** 编译时 第一行 a = 5, 那B的地方拿到a的值就是5已经计算好了,后面变成10,是在运行时return成为的10
//
*** 再执行C,打印5,原理和B的一样,在编译的时候,已经把a=5把5传给b了已经计算好了,那么我b的值就是5
//
*** 再执行D,打印10,因为return 10是先执行的,这个方法也没有传参赋值的操作,那么这个时候
*** 执行顺序就是 return 10,接着 fmt.Print(a),那么打印的结果就是10
//
总结:可以理解(个人理解)为加了defer的代码,是在本函数执行完后执行的,有传值的函数或者执行语句 那么值就是在当前函数执行前的值,没有传值的函数,就是调用函数执行完后的结果,伪代码如下func test() (a int) {a = 5return 10}func main() {var b = test()fmt.Printf("a1 = %d \n", a) // 打印 5 // 有执行语句,值是函数执行前的值func(b int) {fmt.Printf("b1=%d \n", b) // 打印 5 // 有传参的函数,值是函数执行前的值}(a)func() {fmt.Printf("a2=%d \n", b) // 打印 10 // 没有传值的函数,值是 函数执行往后的值}()}
*/
func testDefer() (a int) {a = 5// 执行顺序 Ddefer func() {fmt.Printf("a2=%d \n", a) // 打印 10}()// 执行顺序 Cdefer func(b int) {fmt.Printf("b1=%d \n", b) // 打印 5}(a)// 执行顺序 Bdefer fmt.Printf("a1 = %d \n", a) // 打印 5// 执行顺序 Areturn 10 // 表示 a = 10
}func main() {testDefer()
}
运行结果
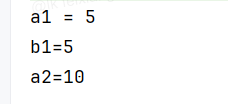
异常处理
普通异常
Go语言没有类似 Java 或 .NET 中的异常处理机制(try catch),虽然可以使用 defer、panic、recover 模拟,但官方并不主张这样做,Go语言的设计者认为其他语言的异常机制已被过度使用,上层逻辑需要为函数发生的异常付出太多的资源,同时,如果函数使用者觉得错误处理很麻烦而忽略错误,那么程序将在不可预知的时刻崩溃。
Go语言希望开发者将错误处理视为正常开发必须实现的环节,正确地处理每一个可能发生错误的函数,同时,Go语言使用返回值返回错误的机制,也能大幅降低编译器、运行时处理错误的复杂度,让开发者真正地掌握错误的处理。
Go语言的错误处理思想及设计包含以下特征:
-
一个可能造成错误的函数,需要返回值中返回一个错误接口(error),如果调用是成功的,错误接口将返回 nil,否则返回错误。
-
在函数调用后需要检查错误,如果发生错误,则进行必要的错误处理。
案例
package mainimport ("errors""fmt"
)// 接收两个int类型,返回它们相除的结果
func testErr(a int, b int) (result int, err error) {if a == 0 || b == 0 {// 这个是0,和一个错误信息return 0, errors.New("除0异常")}// 返回一个正确结果,和一个空return a / b, nil
}func main() {result, err := testErr(12, 0)if err != nil {fmt.Println(err.Error())return}fmt.Println(result)
}自定义异常
// User 定义一个结构体
type User struct {Id stringName stringAge int
}// UserError 自定义一个用户异常
type UserError struct {userId string // 出异常的用户iderrTime string // 出异常的时间msg string // 异常消息
}// NewUserError 自定义用户异常消息
func NewUserError(userId, msg string) *UserError {return &UserError{userId: userId,errTime: time.Now().Format("2006-01-02"),msg: msg,}
}// 自定义异常必须重写Error()方法
func (e *UserError) Error() string {return "异常时间:" + e.errTime + ",异常用户ID:" + e.userId + ",异常信息:" + e.msg
}// service层 使用 自定义异常
func selectUser() (*User, error) {var user = new(User) // 比如所这个user是从数据库中查询出来的if nil == user {return nil, NewUserError("1", "用户不存在")}return user, nil
}// 使用自定义异常
func main() {user, err := selectUser()if err != nil {fmt.Println(err.Error())return}fmt.Println(*user)
}
panic 宕机
Go语言的类型系统会在编译时捕获很多错误,但有些错误只能在运行时检查,如数组访问越界、空指针引用等,这些运行时错误会引起宕机。
宕机不是一件很好的事情,可能造成体验停止、服务中断,就像没有人希望在取钱时遇到 ATM 机蓝屏一样,但是,如果在损失发生时,程序没有因为宕机而停止,那么用户将会付出更大的代价,这种代价可以是金钱、时间甚至生命,因此,宕机有时也是一种合理的止损方法。
panic 就是在程序可能发生严重异常的地方,主动执行 panic 让程序主动宕机,这样开发者可以及时地发现错误,减少可能造成的损失。
案例
package mainfunc main() {panic("手动宕机") //panic() 的参数可以是任意类型的。
}panic会执行哪些操作
1:执行当前 goroutine(可以先理解成线程)的 defer 链。
2:随后,程序崩溃并输出日志信息,日志信息包括 panic value 和函数调用的堆栈跟踪信息。
3:调用 exit(2) 结束整个进程。
在宕机时触发延迟执行语句
当 panic() 触发的宕机发生时,panic() 后面的代码将不会被运行,但是在 panic() 函数前面已经运行过的 defer 语句依然会在宕机发生时发生作用。
案例
func main() {defer fmt.Println("宕机后要做的事情2")defer fmt.Println("宕机后要做的事情1")panic("宕机")
}
捕获 panic
func main() {// 使用 recover() 函数可以捕获 panicdefer func() {if err := recover(); err != nil {fmt.Printf("函数中发生了 panic,%s\n", err)}}()panic("宕机")
}
回调函数
在Go语言中,函数回调是一种非常常见且强大的编程技术。函数回调允许我们将一个函数作为参数传递给另一个函数,并在适当的时机由那个函数来调用它。这种机制允许我们编写更加模块化和可复用的代码。
首先,我们需要理解什么是函数回调。简单来说,函数回调就是一个函数在执行过程中调用了另一个函数。被调用的函数称为回调函数。在Go语言中,函数是一等公民,可以作为变量传递,这为实现函数回调提供了便利。
案例
package mainimport "fmt"// 定义一个回调函数类型
type Callback func(int)// 实现一个接受回调函数作为参数的函数
func Process(data int, callback Callback) {// 在这里处理数据...fmt.Println("Processing data:", data)// 调用回调函数callback(data)
}// 定义一个符合回调函数类型的函数
func HandleData(data int) {fmt.Println("Handling data:", data)
}func main() {// 调用Process函数,并传入HandleData作为回调函数Process(10, HandleData)
}运行结果
Processing data: 10
Handling data: 10在这个示例中,我们定义了一个Callback类型,它是一个接受一个int类型参数并返回nil的函数。然后,我们实现了一个Process函数,它接受一个int类型的数据和一个Callback类型的回调函数作为参数。在Process函数的内部,我们处理数据并调用回调函数。
我们还定义了一个HandleData函数,它的签名与Callback类型相匹配。在main函数中,我们调用Process函数,并传入10作为数据和HandleData作为回调函数。当Process函数执行到调用回调函数的代码时,它会调用HandleData函数。
函数式编程
2.9 数组
数组在声明(使用 [长度]类型 进行声明)的时候必须指定长度,可以修改数组元素,但是不可修改数组长度。
Golang Array和以往认知的数组有很大不同:
-
数组:是同一种数据类型的固定长度的序列。
-
数组定义:
var name [len]type,比如:var a [5]int,数组长度必须是常量,且是类型的组成部分。一旦定义,长度不能变。 -
长度是数组类型的一部分,因此,
var a [5]int和var a [10]int是不同的类型。 -
数组可以通过下标进行访问,下标是从0开始,最后一个元素下标是:len-1
for i := 0; i < len(a); i++ { } for index, v := range a { } -
访问越界,如果下标在数组合法范围之外,则触发访问越界,会panic
-
数组是 值类型 ,赋值和传参会复制整个数组,而不是指针。因此改变副本的值,不会改变本身的值。(与 C 数组变量隐式作为指针使用不同,Go 数组是值类型,赋值和函数传参操作都会复制整个数组数据。)
-
支持 “==”、“!=” 操作符,因为内存总是被初始化过的。
-
指针数组
[n]*T,数组指针*[n]T。
声明
Go 声明数组需要指定元素类型及元素个数,语法格式如下:
var name [SIZE]type
以上为一维数组的定义方式。
多维数组的声明:
var name [SIZE1][SIZE2]...[SIZEN]type
初始化
var balance = [5]float32{1000.0, 2.0, 3.4, 7.0, 50.0}
初始化操作
//一维数组的声明
balance := [5]float32{1000.0, 2.0, 3.4, 7.0, 50.0}
//多维数组的声明
a := [3][4]int{ {0, 1, 2, 3} , /* 第一行索引为 0 */{4, 5, 6, 7} , /* 第二行索引为 1 */{8, 9, 10, 11}} /* 第三行索引为 2 */特殊情况的说明:
数组长度不确定
如果数组长度不确定,可以使用 ... 代替数组的长度,编译器会根据元素个数自行推断数组的长度
var balance = [...]float32{1000.0, 2.0, 3.4, 7.0, 50.0}
或
balance := [...]float32{1000.0, 2.0, 3.4, 7.0, 50.0}只初始化个别元素(通过下标)
如果设置了数组的长度,我们还可以通过指定下标来初始化元素:
// 将索引为 1 和 3 的元素初始化
balance := [5]float32{1:2.0,3:7.0}
初始化数组中 {} 中的元素个数不能大于 [] 中的数字。
如果忽略 [] 中的数字不设置数组大小,Go 语言会根据元素的个数来设置数组的大
总结
全局变量:
var arr0 [5]int = [5]int{1, 2, 3}
var arr1 = [5]int{1, 2, 3, 4, 5}
var arr2 = [...]int{1, 2, 3, 4, 5, 6}
var str = [5]string{3: "hello world", 4: "tom"}
局部变量:
a := [3]int{1, 2} // 未初始化元素值为 0。
b := [...]int{1, 2, 3, 4} // 通过初始化值确定数组长度。
c := [5]int{2: 100, 4: 200} // 使用索引号初始化元素。
d := [...]struct {name stringage uint8
}{{"user1", 10}, // 可省略元素类型。{"user2", 20}, // 别忘了最后一行的逗号。
}多维数组方法
全局变量:
var arr0 [5][3]int
var arr1 [2][3]int = [...][3]int{{1, 2, 3}, {7, 8, 9}}
局部变量:
a := [2][3]int{{1, 2, 3}, {4, 5, 6}}
b := [...][2]int{{1, 1}, {2, 2}, {3, 3}} // 第 2 纬度不能用 "..."。访问
var salary float32 = balance[9]
遍历
package mainimport ("fmt"
)func main() {var f [2][3]int = [...][3]int{{1, 2, 3}, {7, 8, 9}}for k1, v1 := range f {for k2, v2 := range v1 {fmt.Printf("(%d,%d)=%d ", k1, k2, v2)}fmt.Println()}
}获得数组长度
内置函数 len 和 cap 都返回数组长度 (元素数量)。
package mainfunc main() {a := [2]int{}println(len(a), cap(a))
}向函数传递数组
如果你想向函数传递 数组参数,你需要在函数定义时,声明形参为数组,我们可以通过以下两种方式来声明:
方式一:形参设定数组大小:
void myFunction(param [10]int)
{
.
.
.
}方式二:形参未设定数组大小:
void myFunction(param []int)
{
.
.
.
}实例:实例:函数接收整型数组参数,另一个参数指定了数组元素的个数,并返回平均值:
package mainimport "fmt"func main() {/* 数组长度为 5 */var balance = [5]int {1000, 2, 3, 17, 50}var avg float32/* 数组作为参数传递给函数 */avg = getAverage( balance, 5 ) ;/* 输出返回的平均值 */fmt.Printf( "平均值为: %f ", avg );
}func getAverage(arr [5]int, size int) float32 {var i,sum intvar avg float32 for i = 0; i < size;i++ {sum += arr[i]}//提升精度avg = float32(sum) / float32(size)return avg;
}使用数组指针传参
package mainimport "fmt"func printArr(arr *[5]int) {arr[0] = 10for i, v := range arr {fmt.Println(i, v)}
}func main() {var arr1 [5]intprintArr(&arr1)fmt.Println(arr1)arr2 := [...]int{2, 4, 6, 8, 10}printArr(&arr2)fmt.Println(arr2)
}总结:想通过函数调用改变数组内容的两种方式
- return + 赋值
- 用 slice,或数组指针来传参(推荐)
2.10 结构体
什么是结构体
- 结构体是一种自定义的数据类型,用于表示一组相关的数据字段。
- 结构体可以包含任意数量和类型的字段,每个字段都有一个名称和一个类型。
- 结构体的定义使用关键字
type和struct。
定义
type 结构体名 struct {字段1 数据类型1字段2 数据类型2...
}举个例子
type Class struct{id intname stringage intcredit int
}初始化
package mainimport ("fmt"
)type Class struct {id intname stringage intcredit int
}func main() {// 第一种:按照顺序初始化var zhangsan Class = Class{1, "zhangsan", 18, 100}// 第二种:部分初始化var lisi Class = Class{name: "lisi", age: 20}// 第三种: 结构体.成员 方式初始化var wangwu Classwangwu.id = 3wangwu.name = "wangwu"wangwu.age = 23// 第四种:自动推导类型初始化maliu := Class{4, "maliu", 18, 90}fmt.Printf("%v\n%v\n%v\n%v\n", zhangsan, lisi, wangwu, maliu)}结构体与数组
package mainimport "fmt"type Class struct {id intname stringage intcredit int
}func main() {var arr [3]Class = [3]Class{{1, "zhangsan", 18, 200},{2, "lisi", 19, 100},{3, "wagnwu", 22, 300},}// 修改结构体成员值arr[0].age = 666// 输出整个数组fmt.Println(arr)// 输出下标0的名称fmt.Println(arr[0].name)// 输出下标0的年龄fmt.Println(arr[0].age)}代码输出内容
[{1 zhangsan 666 200} {2 lisi 19 100} {3 wagnwu 22 300}]
zhangsan
666切片
package mainimport "fmt"type Class struct {id intname stringage intcredit int
}func main() {// 定义切片使用Class类型var s []Class = []Class{{101, "zhangsan", 10, 20},{102, "lisi", 20, 30},{103, "wangwu", 30, 100},}// 修改值s[0].age = 666// 末尾追加元素s = append(s, Class{104, "maliu", 28, 100})// 遍历切片for i := 0; i < len(s); i++ {fmt.Println(s[i])}
}*号 和 &号
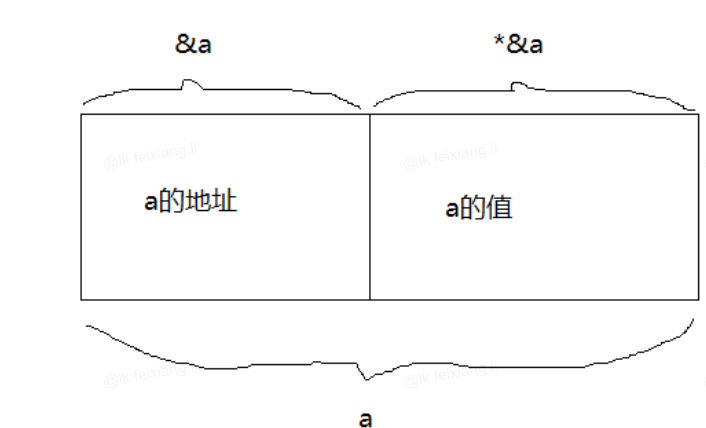
变量是什么?变量是一块内存的别名,即给这块内存起一个名字,这块内存在计算机内存中有具体的地址。
&:取地址符号,表示取出这个变量所在内存的地址。
*:指针符号,表示指向变量的内存地址。指针变量就是指向内存地址的变量
*是指,&是取,可以理解成 &取得的值赋给*,即 *p = &a
一个变量由变量地址和地址上的数据组成,在内存中物理表示的方式如下图
var a = 10
var p *int // 第 2 行
p = &afmt.Printf("%T \n", p) // *intfmt.Println(&a) // 0xc00001e0a8
fmt.Println(p) // 0xc00001e0a8fmt.Println(a) // 10
fmt.Println(*&a) // 10 // &a = p,那么是不是 *&a 和 *p 是一样的
fmt.Println(*p) // 10 // 第 10 行// 注意第2行和第10行*号的区别,第2行表示这是一个指针变量,第10行表示取这个指针地址上的数据
构造函数
Go语言的类型或结构体没有构造函数的功能,可以使用结构体初始化的过程来模拟实现构造函数。
实例
// Cat 定义结构体
type Cat struct {Color stringName string
}// NewCatByName 定义构造函数,只初始化名称
func NewCatByName(name string) *Cat {return &Cat{Name: name,}
}// NewCatByColor 定义构造函数,只初始化颜色
func NewCatByColor(color string) *Cat {return &Cat{Color: color,}
}// 调用构造函数,生成构造实例
var c = NewCatByName("大花")
fmt.Println(c.Name)
匿名成员变量
匿名字段,直接使用类型作为字段名,所以匿名字段中不能出现重复的数据类型。
实例
// 定义
type Student struct {id intstring // 匿名字段float32 // 匿名字段
}// 使用
var stu = Student{id: 1, string: "ZhangSan", float32: 88.3}
fmt.Println(stu.string)
方法传值
- 方法入参是普通的结构体时,在函数里修改入参结构体对象不影响原来的结构体数据。因为传入的是数据的拷贝,不影响原来的数据。(深拷贝)
- 方法入参是指针类型的结构体时,在函数里修改入参结构体对象时,会影响原来的结构体数据,因为传入的是指针,修改会直接修改指针地址上的数据。(浅拷贝)
func hello(u *user) {u.username = "LiSi"
}func (u *user) hello() {u.username = "LiSi"
}
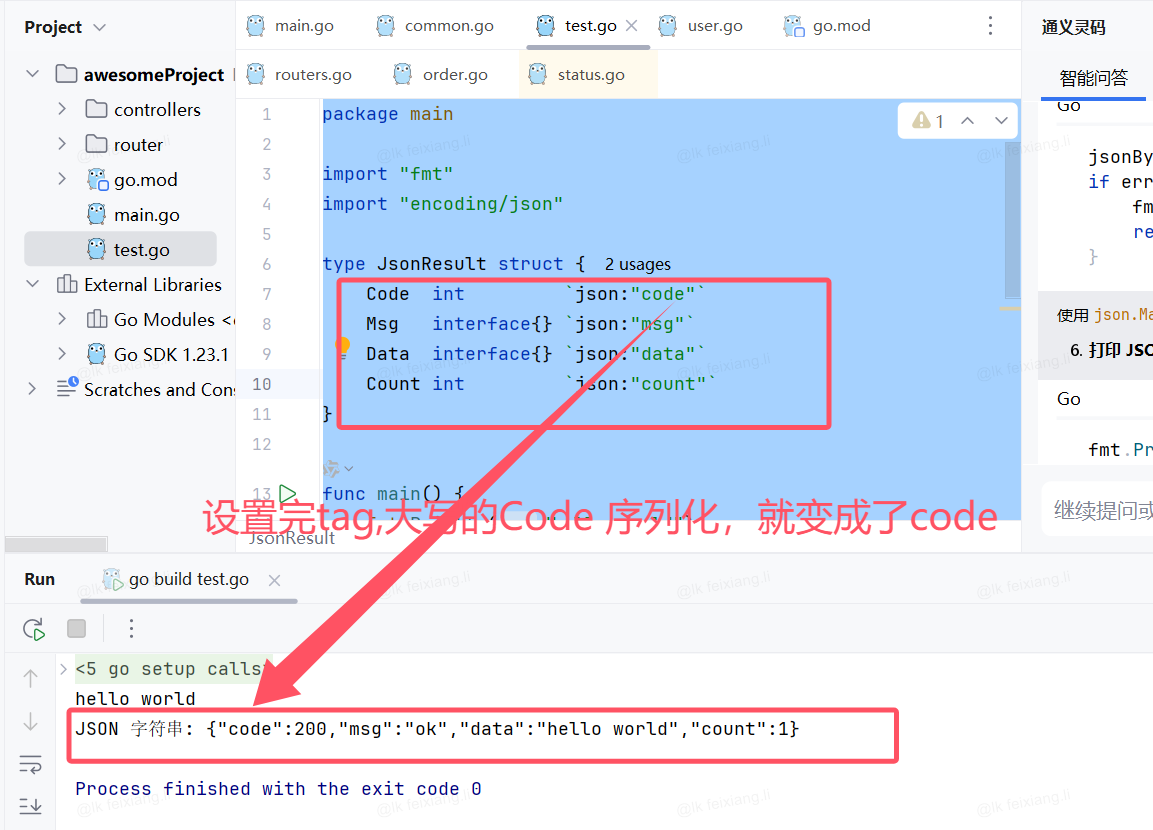
结构体与tag
在定义结构体时,可以给每个字段加上一个tag
type Student struct {Name string "tag-name"Age int "tag-age"
}结构体的tag可以通过反射机制获取,常见用于序列化和反序列化
比如
type JsonResult struct {Code int `json:"code"`Msg interface{} `json:"msg"`Data interface{} `json:"data"`Count int `json:"count"`
}
案例
package mainimport "fmt"
import "encoding/json"type JsonResult struct {Code int `json:"code"`Msg interface{} `json:"msg"`Data interface{} `json:"data"`Count int `json:"count"`
}func main() {fmt.Println("hello world")var a JsonResult = JsonResult{Code: 200,Msg: "ok",Data: "hello world",Count: 1,}jsonBytes, err := json.Marshal(a)if err != nil {fmt.Println("JSON 序列化失败:", err)return}fmt.Println("JSON 字符串:", string(jsonBytes))
}
结构体中方法的定义与使用
- 方法类似于函数,只不过方法可以进行绑定,方法可以绑定到指定的数据类型上,使该数据类型的实例都可以使用这个方法
- 方法不能独自调用,只能通过绑定的数据类型的实例进行调用
- 自定义类型都可以有方法,不仅仅是struct
type A struct {Name string
}func (a A) test() {fmt.Println(a.Name)
}func main() {a := A{Name:"111"}a.test()
}-
接收者必须有一个显式的名字,这个名字必须在方法中被使用
-
如果方法不需要使用接收者的值,可以用 _ 替换它
-
接收者必须有一个显式的名字,这个名字必须在方法中被使用
-
如果方法不需要使用接收者的值,可以用 _ 替换它
func (_ receiver_type) methodName(parameter_list) (return_value_list) { ... }
-
类型和作用在它上面定义的方法必须在同一个包里定义,这就是为什么不能在 int、float 或类似这些的类型上定义方法,可以为当前包中任何类型定义方法,必须是当前包
-
Go中的toString()方法
func (a type) String() string { ... }
2.11 接口
什么是接口?
在Go语言中,接口(interface)是方法的集合,它允许我们定义一组方法但不实现它们,任何类型只要实现了这些方法,就被认为是实现了该接口。
接口更重要的作用在于多态实现,它允许程序以多态的方式处理不同类型的值。接口体现了程序设计的多态和高内聚、低耦合的思想。
package mainimport "fmt"// 定义接口
type Person interface {GetName() stringGetAge() int
}// 定义结构体
type Student struct {Name stringAge int
}// 实现接口
// 实现 GetName 方法
func (s Student) GetName() string {fmt.Println("name:", s.Name)return s.Name
}// 实现 GetAge 方法
func (s Student) GetAge() int {fmt.Println("age:", s.Age)return s.Age
}// 使用接口
func main() {var per Personvar stu Studentstu.Name = "xiaozhang"stu.Age = 24per = stuper.GetName() // name: xiaozhangper.GetAge() // age: 24
}注意事项
-
(1)接口本身不能创建实例,但是可以指向一个实现了该接口的自定义类型的变量(实例)。
-
(2)接口中所有的方法都没有方法体,即都是没有实现的方法。
-
(3)在Go中,一个自定义类型需要将某个接口的所有方法都实现,才能说这个自定义类型实现了该接口。
-
(4)一个自定义类型只有实现了某个接口,才能将该自定义类型的实例(变量)赋给接口类型。
-
(5)只要是自定义数据类型就可以实现接口,不仅仅是结构体类型(structs),还包括类型别名(type aliases)、其他接口、自定义类型、变量等。
-
(6)一个自定义类型可以实现多个接口。
-
(7)interface 接口不能包含任何变量。
-
(8)一个接口可以继承多个别的接口,这时如果要实现这个接口必须实现它继承的所有接口的方法。
在低版本的Go编辑器中,一个接口继承其他多个接口时,不允许继承的接口有相同的方法名。比如A接口继承B、C接口,B、C接口的方法名不能一样。高版本的Go编辑器没有相关问题。
-
(9)interface类型默认是一个指针(引用类型),如果没有对interface初始化就使用,那么会输出nil。
var i interface{} fmt.Println(i == nil) // 输出:true -
(10)在Go中,接口的实现是非侵入式,隐式的,不需要显式声明“我实现了这个接口”。只要一个类型提供了接口中定义的所有方法的具体实现,它就自动成为该接口的一个实现者。
-
(11)空接口interface{}没有任何方法,是一个能装入任意数量、任意数据类型的数据容器,我们可以把任何一个变量赋给空接口类型。任意数据类型都能实现空接口,这就和 “空集能被任意集合包含” 一样,空接口能被任意数据类型实现。
底层实现
Go的interface源码在Golang源码的runtime目录中。Go的interface是由两种类型来实现的:iface和eface。runtime.iface表示非空接口类型,runtime.eface表示空接口类型interface{}。
iface是包含方法的interface,如:
type Person interface {GetName()
}
eface是不包含方法的interface,即空interface,如:
type Person interface {
}
//或者
var person interface{} = xxxx实体
iface的源代码是:
type iface struct {tab *itab // 表示值的具体类型的类型描述符data unsafe.Pointer // 指向值的指针(实际的数据)
}
itab是iface不同于eface的关键数据结构。其包含两部分:一部分是唯一确定包含该interface的具体结构类型,一部分是指向具体方法集的指针。
参考资料
GO语言中的接口(interface)_go 接口-CSDN博客
3. 高级
3.1 IO流使用
3.2 泛型
参考资料
[Go 函数-CSDN博客](https://blog.csdn.net/a1053765496/article/details/129842600


![LeetCode-632. Smallest Range Covering Elements from K Lists [C++][Java]](http://pic.xiahunao.cn/LeetCode-632. Smallest Range Covering Elements from K Lists [C++][Java])

开发中常用的C语言基础语法(二))














