导读:SQL 诞生于 20 世纪 70 年代,至今已有半个世纪。SQL 语言具有语法简单,低学习门槛等特点,诞生之后迅速普及与流行开来。由于 SQL 具有易学易用的特点,使得开发人员容易掌握,企业若能在其计算机软件中支持 SQL,则可顺应当今降本增效的行业发展趋势。Spark 早期的 0.6 版本,主要围绕着 Spark Core 的功能,比如支持用户在 Spark Context 下用 RDD API 去写一些应用程序代码,当时还没有更简单的方式通过 Spark 去操纵数据。2012 年加州大学伯克利分校在 Spark 基础上通过兼容 Hive 语法,推出了 Shark 功能。并于 2014 年 5 月在 Spark1.0 版本正式发布的时候,推出了 Spark 社区自身实现的 Spark SQL。当时的 Spark SQL 在解析层是通过 Scala 模式匹配来进行实现的,不够灵活也没有开源的解析方案强大、稳健。Spark 在 2016 年 7 月改用 Antlr4 重新实现 Parser。2016 年 7 月至今,Spark 社区发展的最为稳健和活跃的功能模块即为 Spark SQL。
本期是 DataFun 深入浅出 Apache Spark 第二期的分享,主要介绍 Apache Spark SQL 原理,包括:
1. Apache Spark SQL 基本概念
2. Apache Spark SQL 核心组件
3. Apache Spark SQL API
一、Apache Spark SQL 基本概念
1.TreeNode & 2. AST(Abstract Syntax Tree) & 3. QueryPlan
SQL 本身有一套理论上比较成熟的架构,比如需要将 SQL 文本转换成抽象语法树(Abstract Syntax Tree)。TreeNode 代表了抽象语法树里面的某个节点,如 Limit 算子或者 Join 算子,通过大量 TreeNode 的不同实现最后组成了一棵抽象语法树(AST)。QueryPlan 是 TreeNode 基础上扩展的一个查询计划,既可以是逻辑的也可以是物理的,里面定义了一些查询计划节点的基本属性包括转换 API,可以对生成的 AST 进行遍历,遍历的方法类比树的深度优先/广度优先遍历,通过这样的方式对其实现访问和转换。

4. LogicalPlan vs 5. Physical Plan
LogicalPlan 是 QueryPlan 的实现,用于表示逻辑计划,在 Spark 中是类的实现。PhysicalPlan 是纯逻辑的概念,表示物理计划,实际的实现是 SparkPlan,用于执行物理算子。

6. Rule 规则& 7. Rule Executor 规则执行器
规则应用于 LogicalPlan 构建的逻辑的抽象语法树,比如把属性绑定到某个表的某个字段;或者通过元数据绑定的分析过程找到某个表是位于 MySQL 数据库还是位于 Hive 中某一个 HDFS 存储目录;也可以是在编译理论里面会有的常量表达式折叠这样的优化。以上这些优化或者分析的工作可以在 Spark 中抽象成规则。每种规则都会对 AST 通过调用 QueryPlan 里面的转换 API 应用一些转换。
Rule 规则类似模板,里面定义了一些逻辑,实际触发规则需要能执行它的 RuleExecutor。在 Spark 中会将规则组织成批,每批 Rule 会有其处理的迭代策略:包括需要执行一次的(Once)和需要执行多次的(FixedPoint)。

如上图,左边是规则 Batches,右边是 LogicalPlan 代表逻辑的抽象语法树(AST),在 RuleExecutor 里结合到一块,执行器帮助 AST 应用规则之后生成一个新的 LogicalPlan。
8. Generic Strategy & 9. QueryPlanner

以上的分析和优化阶段主要针对的是逻辑计划,需要有阶段将逻辑计划翻译成物理计划,来实际执行物理算子。这个阶段主要由 GenericStrategy 和 QueryPlanner 配合完成。其中 GenericStrategy 策略类似 Rule,是一些行为模板,也有多种实现可能。GenericStrategy和QueryPlanner的关系类似Rule和RuleExecutor。GenericStrategy 由 QueryPlanner 去触发执行,把逻辑计划转化成物理计划,如上图所示。当 GenericStrategy 不能应用到 LogicalPlan时,返回空列表。
二、Apache Spark SQL 核心组件
1. SparkSqlParser 解析器
负责将输入的 SQL 文本解析成一个 AST。SparkSqlParser 包含 Astbuilder,VariableSubstitution,SparkSqlAstBuilder。
-
Astbuilder
围绕 Antlr4 进行扩展和实现,将由 Antlr4 解析得到的 ParseTree 进而转化为 Catalyst Expression,LogicalPlan 或者 CatalystIdentifier。举个例子,Catalyst Expression:SQL 文本中的 SUM 函数可以在 Spark 中转化为 Catalyst SQL Expression。LogicalPlan:SQL 里面有 SELECT 可以生成 Project 之类的逻辑计划。CatalystIdentifier:SELECT columns FROM table 中的表名会转化为 Spark SQL CatalystIdentifier,是身份表示的一种抽象。这些总体会形成最初的 AST。
此刻的 AST 只是通过 Antlr4 的帮助解析出来。还没有和数据字典进行绑定,称之为 Parsed Logical Plan。此时尚不知道,SELECT 的某个属性是一个字段还是自定义的表达式,FROM table 的表是一个数据库的表还是某个目录文件。
-
SparkSQLAstBuilder 的主要功能和 Astbuilder 类似并在其基础上进行了一些扩展。
-
VariableSubstitution 兼容了 Hive 中变量声明的方式。

2. Analyzer 分析器
Analyzer 是 RuleExecutor 的具体实现之一,可以帮助 Parsed Logical Plan 进行数据字典的绑定。举个例子,在 SQL 中 SELECT id FROM table,SparkSqlParser 会将 id 转化为 UnresolvedAttribute, 将 table 转化为 UnresolvedRelation。分析器会从数据字典中将元数据信息填充进去。经过分析器处理后,AST 已经和数据字典绑定,成为分析后的逻辑计划(Analyzed Logical Plan)。理论上可以基于其执行物理计划并读取和查询数据,此时的逻辑计划并不是最优的,需要对分析后的逻辑计划进行优化。


3. Optimizer 优化器
Optimizer 在分析器结果之上对分析后的逻辑计划应用优化规则。这些优化规则除了极少数,都是围绕 Spark 的性能优化展开的,应用后生成 Optimized Logical Plan(优化后的逻辑计划)。Optimizer 的应用过程和 Analyzer 类似,都是 RuleExecutor 架构下的成员。
举个例子,SparkSQL 数据库有很多类型,对于类型转化而言,有些类型转换是安全的,有些类型转换会丢失一些精度,有些类型之间不能进行转换。比如用户将 String 类型的变量通过 Cast 表达式转成 Int,如果错误地判断了数据的值,或者随着时间流逝字段发生变化出现了非数字字符,可能会出现一些问题。Spark 在简化 Cast 上做了一些工作,如数据本身是整型转化为长整型,这在很多语言层面是隐式转化是安全的,而 Cast 会在物理执行阶段占用 CPU 资源,对于这种不必要的转换,Spark 会进行 Cast 消除。对于一些有问题的转换可以检测出来,对有些转换进行更进一步的优化。
在 Spark 3.0.0 之前,Optimized Logical Plan 属于逻辑计划的最后使命,之后被转换为 Physical Plan 用于提交 Job 并执行查询或计算。Spark 3.0.0 发布了一个十分重要的优化框架 AQE(Adaptive Query Execution),用于在执行阶段,利用运行期收集到的统计信息对 Logical Plan 进行渐进式的运行时优化,并适时改变物理执行计划。AQE 框架提供了 AQEOptimizer,专门针对 AQE 的场景,对 Logical Plan 进行优化。


4. SparkPlanner
Optimized Logical Plan(优化后的逻辑计划)已经可以转化为物理计划,需要 SparkPlanner 来进行介入。SparkPlan 继承了 QueryPlan,是 PhysicalPlan 的实际实现,代表物理计划。最终可执行的物理计划都继承自 SparkPlan。比如用户在 SQL 里写了 Limit 10 的语法,逻辑计划里有 Limit 节点,在物理计划阶段会转化成不同的物理算子。比如 Limit 的结果 Spark SQL 执行完毕需要把结果收集上来,会生成 CollectLimitExec 物理算子。

5. SparkStrategy
SparkStrategy 是 GenericStrategy 的抽象扩展,将 LogicalPlan 转化为零个或多个 SparkPlan,所有的执行策略实际继承 SparkStrategy 即可。像刚刚提到的 Limit 10 的例子,如果执行 collect 会生成 CollectLimitExec 算子把结果拉取到 Driver 端,但是也有一些别的情况比如 Limit 伴随 Offset,随着 SQL 语法的不同生成的算子是不一样的。


6. SQLConf
用于设置和获取可变的配置参数/提示。可供用户基于自己的使用场景对于参数进行调整和优化。
7. FunctionRegistry 函数的注册表
内建函数及用户自定义函数的数据字典。包括 Spark 兼容 Hive 的函数,ANSI 标准相关的函数,同时 Spark 也支持自定义函数的功能。注册表主要用于分析器(Analyzer)使用,比如将 SparkSqlParser 解析后 unresolved 的 SUM 函数与注册表比对确定其含义和所需参数等。
8. DataSourceManager 数据源管理器
用户定义数据源的管理器。它用于按数据源的短名称或完全限定名称注册和查找数据源。目前主要是迎合 Python 用户的需要,用 Python 的方法去注册一些数据源。
9. Spark CatalogPlugin
用于为 Spark 提供 Catalog 实现的接口。它的子接口包括:FunctionCatalog、SupportsNamespaces、TableCatalog、ViewCatalog 等。举个例子,最早的时候接入数据源需要 Provider 和 Connector,以 MySQL 为例,需要有 MySQL 驱动程序的 jar 包,还需要有 MySQL 对应的 Connector 的实现,当时用户必须使用编程的方式,实现和维护成本较高。Spark3.0 推出了 Spark DataSource V2 API,用户可以借助这样的一个 Catalog Plugin 把数据源注册在 Spark 里面,之后可反复使用,极大提高了生产效率。
10. CatalogManager
跟踪所有通过 Catalog Plugin 注册的 Catalog。

11. SessionCatalog
SparkSession 使用的内部数据字典。该字典充当底层元存储(例如 Hive 元存储)的代理,还管理其所属 SparkSession 的临时视图和功能。早期围绕 Hive 实现,代理了 Hive 元数据。SessionCatalog 可将核心组件串在一起来解析 SQL。

如上图,用户输入 SQL 文本,首先经过 Spark Parser 形成解析后的 AST, 之后分析器利用一些函数注册表和 SessionCatalog 提供的 Hive 相关信息或者第三方的 Catalog 元数据信息,对元数据信息进行绑定,生成分析后的 LogicalPlan,经过优化器生成优化后的 LogicalPlan,再经过物理计划的 planner 转化成物理计划,这个物理计划被提交到 Spark 计算节点。

以一条 SQL 为例来展示 Spark SQL 的执行流程。用户输入 SQL 文本 SELECT sum(distinct val) FROM cyber;首先解析为 Parsed Logical Plan,其中 Sum(distinct val)解析为 UnresolvedAlias(sum(distinct val)),cyber 解析为 UnresolvedRelation(cyber);之后经过分析器转化为分析后知道元数据信息的 AST;之后经过优化器进行优化,比如此处优化器通过增加 Project 避免 scan cyber 整表;最后在规划器中生成真正的物理计划。如上图 Sum 在 Spark 中需要 Shuffle 过程,在物理计划中会伴随 Exchange 算子,Exchange 算子代表 shuffle。Spark 本身支持 DISTINCT 语法,可以额外增加一次聚合,所以在物理计划里面有两次 Shuffle 过程。例子里面还有一个 ColumnarToRow 运算,是因为 Parquet 是列式存储但是 Select 在输出时是按照行来输出的,所以会有一个列转行的运算。
三、Apache Spark SQL API
1. Spark Session
Spark Session 方便接入数据源,执行转换,添加算子。通过 SparkSession 会生成 Dataset,可以在 Dataset 基础上进一步进行 API 调用。Spark Session 内部封装了 SparkContext 来调用 Spark Core 的一些能力,结合 SparkSQLParser,Analyser,Optimizer,SparkPlanner 等组件,完成对执行计划的转换;通过间接持有 SQLConf, FunctionRegistry,DataSourceManager, CatalogManager,SessionCatalog 等组件,完成对元数据或者数据的访问。

2. Dataset&DataFrame
Dataset 是特定对象的强类型集合,可以使用函数或关系操作并行转换,每个 Dataset 还有一个称为 DataFrame 的非类型化视图,它是 row 的数据集。
3. DataFrameReader
用于从外部存储系统(如文件系统、键值存储等)加载 Dataset 的 API。SparkSession的read 方法可以获得对 DataFrameReader 的访问。在 SparkSession 里面需要读取 Parquet 文件会生成临时的 DataFrameReader,进一步对文件进行访问操作。

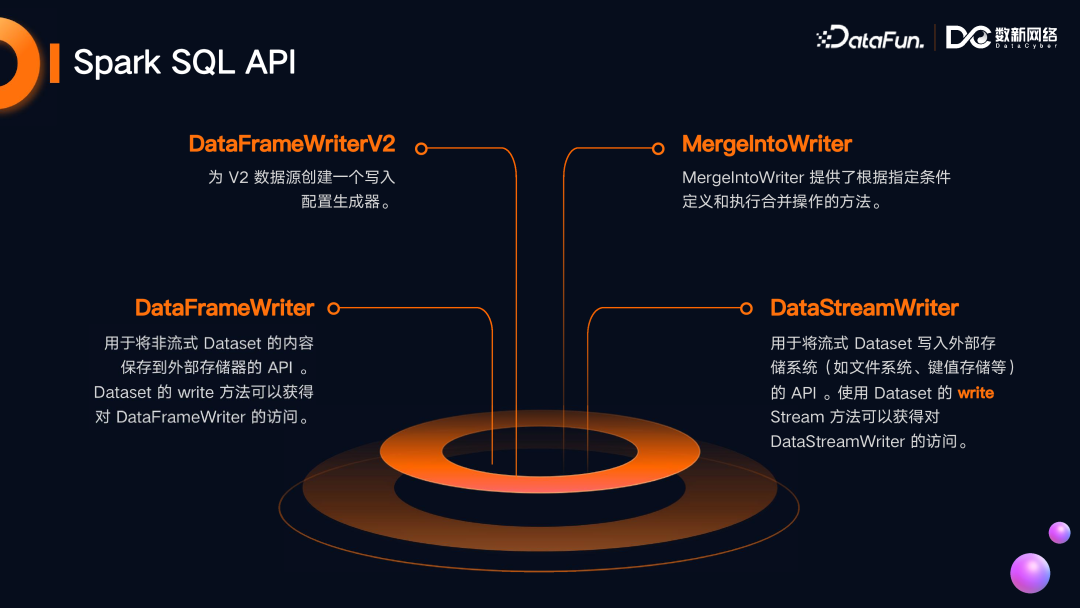
4. Writer 写的 API
-
DataFrameWriter
用于将非流式 Dataset 的内容保存到外部存储器的 API,Dataset 的 write 方法可以获得对 DataFrameWriter 的访问。
-
DataFrameWriterV2
为 V2 数据源创建一个写入配置生成器。
-
MergeIntoWriter
提供了根据指定条件定义和执行合并操作的方法。
-
DataStreamWriter
用于将流式 Dataset 写入外部存储系统(如文件系统,键值存储等)的 API。使用 Dataset 的 write Stream 方法可以获得对 DataStreamWriter 的访问。



)







![题解:P11248 [GESP202409 七级] 矩阵移动](http://pic.xiahunao.cn/题解:P11248 [GESP202409 七级] 矩阵移动)

![[ DOS 命令基础 4 ] DOS 命令命令详解-端口进程相关命令](http://pic.xiahunao.cn/[ DOS 命令基础 4 ] DOS 命令命令详解-端口进程相关命令)





