大模型-微调与对齐-人类对齐背景与标准
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.mzph.cn/news/885125.shtml
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

hive数据查询语法
思维导图 基本查询
基本语法
SELECT [ALL | DISTINCT] 字段名, 字段名, ...
FROM 表名 [inner | left outer | right outer | full outer | left semi JOIN 表名 ON 关联条件 ]
[WHERE 非聚合条件]
[GROUP BY 分组字段名]
[HAVING 聚合条件]
[ORDER BY 排序字段名 asc | desc…
前端小知识:我居然没学会用 split 方法?!
小伙伴们,你们会用 JavaScript 的 split 方法吗?最近我才发现,原来我多年来一直没真正掌握它,结果在解题时被卡住了。所以今天,我决定好好整理一下这个方法的用法。 在讨论问题之前,先来看一下 split 的两种…

VTK知识学习(2)-环境搭建
1、c方案
1.1下载源码编译
官网获取源码。
利用Cmake进行项目构建。 里面要根据实际使用的情况配置相关的模块哟,这个得你自行研究下了。
CMAKEINSTALLPREFIX--这个选项的值表示VTK的安装路径,默认的路径是C:/Program Files/VTK。该选项的值可不作更…

Halcon 从XML中读取配置参数
1、XML示例 以下是一个XML配置文件的示例,该文件包含了AOI(自动光学检测)算法的环境参数和相机逻辑参数:
<AOI><!--AOI算法参数 20241106--><Env><!--环境参数--><Param name="GPUName" value="NVIDIA GeForce RTX 405…

SQL--查询连续三天登录数据详解
问题: 现有用户登录记录表,请查询出用户连续三天登录的所有数据记录
id dt1 2024-04-25
1 2024-04-26
1 2024-04-27
1 2024-04-28
1 2024-04-30
1 2024-05-01
1 2024-05-02
1 2024-05-04
1 2024-05-05
2 20…

结构方程、生物群落、数据统计、绘图分析在生态领域的应用
R语言结构方程模型(SEM)在生态学领域中的实践应用
结构方程模型(Sructural Equation Model)是一种建立、估计和检验研究系统中多变量间因果关系的模型方法,它可以替代多元回归、因子分析、协方差分析等方法࿰…

vue使用canves把数字转成图片验证码
<canvas id"captchaCanvas" width"100" height"40"></canvas>function drawCaptcha(text) {const canvas document.getElementById(captchaCanvas);const ctx canvas.getContext(2d);// 设置背景颜色ctx.fillStyle #f0f0f0;ctx.f…


「Mac畅玩鸿蒙与硬件23」鸿蒙UI组件篇13 - 自定义组件的创建与使用
自定义组件可以帮助开发者实现复用性强、逻辑清晰的界面模块。通过自定义组件,鸿蒙应用能够提高代码的可维护性,并简化复杂布局的构建。本篇将介绍如何创建自定义组件,如何向组件传递数据,以及如何在不同页面间复用这些组件。 关键…
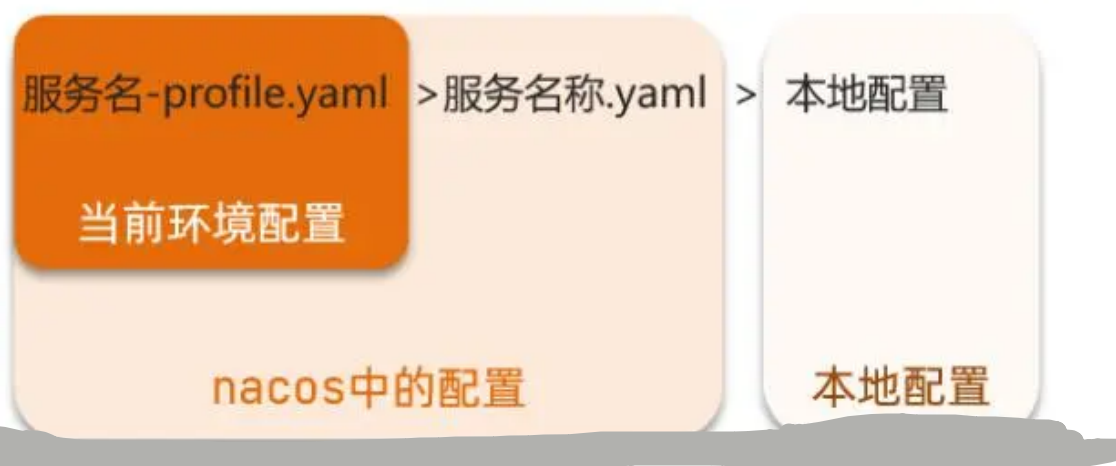
【SpringCloud】Nacos微服务注册中心
微服务的注册中心
注册中心可以说是微服务架构中的"通讯录",它记录了服务和服务地址的映射关系 。在分布式架构中, 服务会注册到这里,当服务需要调⽤其它服务时,就从这里找到服务的地址,进行调用。 注册中心…

【Go语言】| 第1课:Golang安装+环境配置+Goland下载
😎 作者介绍:我是程序员洲洲,一个热爱写作的非著名程序员。CSDN全栈优质领域创作者、华为云博客社区云享专家、阿里云博客社区专家博主。 🤓 同时欢迎大家关注其他专栏,我将分享Web前后端开发、人工智能、机器学习、深…
数据库优化指南:如何将基本功能运用到极致?
一次问题 数据库的归档日志很多,多到那个机器的硬件不足以处理了。查看了一下为什么产生这么多日志。发现其实都是一些不当的使用方式。比如开发人员建立了一个xxxx_temp从这么名字上就应该能猜出来这是要做什么?美其名曰是临时表。 就是导入一批数据&am…

150道MySQL高频面试题,学完吊打面试官--关于索引的五道大厂面试题,跳槽面试很重要
前言
本专栏为150道MySQL大厂高频面试题讲解分析,这些面试题都是通过MySQL8.0官方文档和阿里巴巴官方手册还有一些大厂面试官提供的资料。 MySQL应用广泛,在多个开发语言中都处于重要地位,所以最好都要掌握MySQL的精华面试题,这也…

自攻螺钉的世纪演变:探索关键设计与应用
自攻螺钉作为现代工业和建筑中的不可或缺的标准部件,经过了超过100年的发展和创新。从1914年最早的铁螺钉设计到今天的自钻自攻螺钉,自攻螺钉的设计不断优化,以适应更复杂的应用需求。本文将回顾自攻螺钉的演变历程,分析其设计原理…


快速学习Django框架以开发Web API
简介 Django是一个高级Python Web框架,它鼓励快速开发和简洁实用的设计。由经验丰富的开发者构建,Django可以为你处理大量的Web开发任务,使你能够专注于编写应用的关键组件。Django的模块化设计、可复用性和广泛的社区支持,使其成为开发Web应用和API的理想选择。
在本文中…

论文 | Evaluating the Robustness of Discrete Prompts
论文《Evaluating the Robustness of Discrete Prompts》深入探讨了离散提示(Discrete Prompts)的鲁棒性,即离散提示在自然语言处理任务中面对不同扰动时的表现。研究特别关注离散提示在自然语言推理(NLI)任务中的表现…

2024中国国际数字经济博览会:图为科技携明星产品引领数智化潮流
10月24日,全球数智化领域的目光齐聚于中国石家庄正定,一场关于数字经济未来的盛会—2024中国国际数字经济博览会在此拉开帷幕。 云边端算力底座的领航者,图为科技携其明星产品惊艳亮相,期待与您共赴一场数智化的非凡之旅ÿ…

7.2、实验二:被动接口和单播更新
源文件链接:
7.2、实验二:被动接口和单播更新: https://url02.ctfile.com/d/61945102-63671890-6af6ec?p2707 (访问密码: 2707)
一、被动接口
1.介绍
定义: 在路由协议的配置中,一个被动接口指的是一个接口不发送路由更新包的配置方式&a…

4.3 Linux的中断处理流程
点击查看系列文章 》 Interrupt Pipeline系列文章大纲-CSDN博客
原创不易,需要大家多多鼓励!您的关注、点赞、收藏就是我的创作动力!
4.3 Linux的中断处理流程 先上图,一图胜千言!
图中心的蓝色部分,是L…