目录
- 前言
- 一、智能体
- 1-1、Agent概述
- 1-2、Agent与ChatGPT的区别
- 二、多智能体框架MetaGPT
- 2-1、安装&配置
- 2-2、使用已有的Agent(ProductManager)
- 2-3、多智能体系统介绍
- 2-4、多智能体案例分析
- 2-4-1、构建智能体团队
- 2-4-2、动作/行为 定义
- 2-4-3、角色/智能体 定义
- 2-4-4、创建队伍,添加角色
- 2-4-5、内部机制介绍
- 2-4-6、人工介入
- 2-4-7、记忆/内存
- 附录
- 1、react_mode(智能体的思维范式介绍)
- 1-1、ReAct
- 1-2、By order
- 1-3、Plan and act
- 总结
前言
用公式来讲,智能体=大语言模型LLM+观察+思考+行动+记忆一、智能体
1-1、Agent概述
Agent(智能体): 具有一定自主性和目标导向性,可以在没有持续人类干预的情况下执行任务和作出决策。以下为Agent的一些特性:
(1)自主性和目标导向性
- 自主性:Agent具备自主执行任务的能力,不需要外部指令即可根据设定的目标进行操作。
- 目标导向性:Agent设置并追求特定的目标或任务,这些目标指导其决策过程和行为模式。
(2)复杂的工作流程
- 任务规划与执行:Agent能够规划如何达到其目标,包括任务分解、优先级排序以及实际执行。
- 自我对话和内部决策:在处理问题时,Agent可以进行内部对话,以自我推理和修正其行动路径,而无需外部输入。
(3)学习和适应能力
- 反思和完善:Agent能从自身的经验中学习,评估过去的行为,从错误中吸取教训,并改进未来的策略。
- 环境适应性:在遇到变化的环境或不同的挑战时,Agent能够适应并调整其行为以最大化目标达成。
(4)记忆机制
- 短期记忆:使用上下文信息来做出即时决策。
- 长期记忆:保留关键信息,供未来决策使用,通常通过外部数据库或持久存储实现。(例如使用向量数据库)
(5)工具使用与集成
- API调用和外部数据访问:Agent可以利用外部资源(如API、数据库)来获取信息,填补其知识空白,或执行无法直接通过模型内部处理的任务。
- 技术整合:Agent能整合多种技术和服务,如代码执行能力和专业数据库访问,以丰富其功能和提高效率。
LLM 驱动的自主Agents系统概述如下图所示:(包含工具调用、记忆、计划、执行模块)
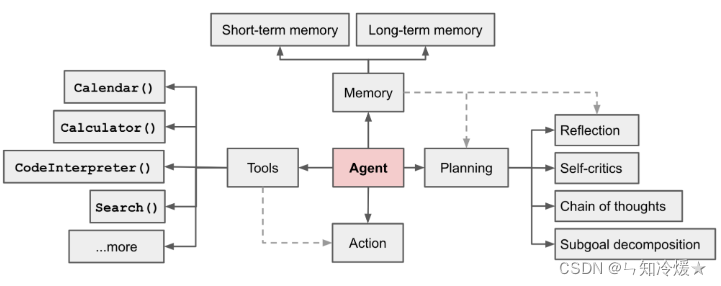
1-2、Agent与ChatGPT的区别
Agent与ChatGPT的区别: Agent与ChatGPT在设计、功能和目标上有一些关键区别。虽然它们都是基于人工智能技术,但应用方式和交互性质大不相同。下面是这两者的主要区别:
(1)目标和自主性
- ChatGPT:主要是一个响应型模型,专注于对用户的特定输入生成一次性、相关且连贯的回答。它的主要目的是解答问题、提供信息或进行对话模拟。
- AI Agent:更强调在持续的任务中表现出自主性。它能够设定和追求长期目标,通过复杂的工作流程自主地完成任务,比如从错误中自我修正、连续地追踪任务进展等。
(2) 交互方式
- ChatGPT:用户与ChatGPT的交互通常是线性的和短暂的,即用户提问,ChatGPT回答。它不保留交互的历史记忆,每次交互都是独立的。
- AI Agent:可以维持跨会话的状态和记忆,具有维持长期对话的能力,能够自动执行任务并处理一系列相关活动,例如调用API、追踪和更新状态等。
(3)任务执行和规划能力
- ChatGPT:通常只处理单个请求或任务,依赖用户输入来驱动对话。它不具备自我规划或执行连续任务的能力。
- AI Agent:具备规划能力,可以自行决定执行哪些步骤以完成复杂任务。它可以处理任务序列,自动化决策和执行过程。
(4)技术整合与应用
- ChatGPT:主要是文本生成工具,虽然能够通过插件访问外部信息,但核心依然是文本处理和生成。
- AI Agent:可能整合多种技术和工具,如API调用、数据库访问、代码执行等,这些都是为了实现其目标和改善任务执行的效率。
(5)学习和适应
- ChatGPT:它的训练是在离线进行,通过分析大量数据来改进。
- AI Agent:除了离线学习,更复杂的AI Agent可能具备实时学习能力,能够从新的经验中迅速适应和改进,这通常需要一定的记忆和自我反思机制。
二、多智能体框架MetaGPT

2-1、安装&配置
安装: 必须要python版本在3.9以上 ,这里使用conda,尝鲜安装。
conda create -n metagpt python=3.9 && conda activate metagpt
开发模式下安装: 为开发人员推荐。实现新想法和定制化功能。
git clone https://github.com/geekan/MetaGPT.git
cd ./MetaGPT
pip install -e .
模型配置: 在文件 ~/.metagpt/config2.yaml下,有关于各大厂商模型的配置详细列表参考:LLM API Configuration
llm:api_type: "openai" # or azure / ollama / groq etc. Check LLMType for more optionsmodel: "gpt-4-turbo" # or gpt-3.5-turbobase_url: "https://api.openai.com/v1" # or forward url / other llm urlapi_key: "YOUR_API_KEY"
2-2、使用已有的Agent(ProductManager)
概述: 调用ProductManager Agent,注意,会话上下文是需要独立创建的
import asynciofrom metagpt.context import Context
from metagpt.roles.product_manager import ProductManager
from metagpt.logs import loggerasync def main():msg = "Write a PRD for a snake game"context = Context() # The session Context object is explicitly created, and the Role object implicitly shares it automatically with its own Action objectrole = ProductManager(context=context)while msg:msg = await role.run(msg)logger.info(str(msg))if __name__ == '__main__':asyncio.run(main())
输出结果:

2-3、多智能体系统介绍
多智能体系统: 即智能体社会,用公式表示为:
MultiAgent = 智能体 + 环境 + 标准化的操作程序(SOP)+ 通信 +经济
各个部分的详细介绍:
- Agent:每个智能体都可能有独特的LLM、观察、思想、行动和记忆,在多智能体系统中,各个智能体协同工作,就像人类社会一样。
- 环境: 环境是各个Agent交互的共同空间,Agent从环境中观察与自身有关的重要信息,并执行相应的操作。
- 标准化操作程序(Standardized operating procedure): 即设置好的程序,用来管理智能体的行为以及智能体间的交互,确保系统的有序、高效进行。
- 通讯:通讯,即Agent之间的信息交换。
- 经济:指的是多智能体环境中的价值交换系统,决定了资源如何分配和任务的优先级。
简单示例:

具体介绍如下:
- 在该环境下,三个智能体Alice、Bob、Charlie彼此交互。
- 每个智能体都可以把信息或者是行为结果输出到环境中。
- 以Agent——Charlie的内部进程为例(其他Agent类似),基于LLM,即决策🧠,并且拥有观察、思考、行动能力。思想和其进一步的行动主要是由LLM决策的,并且同时拥有使用工具的能力。
- 智能体Charlie通过观察Alice智能体的相关文档以及Bob智能体的代码需求,参考上下文记忆,思考如何编写代码并采取行动,最终行动输出代码文件。
- 智能体Charlie的输出结果刚好是智能体Bob观察的对象,智能体Bob在环境中得到了Charlie的输出结果,并且做出了进一步的响应。
2-4、多智能体案例分析
概述: 虽然单智能体可以解决很多任务,但是复杂的任务还是需要多智能体之间的协作。
2-4-1、构建智能体团队
构建智能体团队的步骤如下:
- 定义每个能执行特定动作的角色
- 标准化操作程序,即SOP的构建,确保每个角色遵守程序。实现过程:让每个角色观察自己的上游输出,根据上游输出做出相应的响应,并且输出内容到下游。
- 初始化所有智能体,创建一个带有环境的队伍,让他们能够互相交互。(主要是根据上游角色发布到环境中的消息来做出响应。)
具体的智能体以及对应的行为定义如下:
- 角色:SimpleCoder, 动作:SimpleWriteCode,接收用户指令并且写出主要代码
- 角色:SimpleTester , 动作:SimpleWriteTest,从动作/行为SimpleWriteCode的输出中获取主要的代码并且提供测试用例。
- 角色:SimpleReviewer , 动作:SimpleWriteReview,从动作/行为SimpleWriteTest 的输出中获取测试用例,检查测试用例的覆盖程度以及质量,输出报告。
2-4-2、动作/行为 定义
写代码行为如下:
from metagpt.actions import Actionclass SimpleWriteCode(Action):PROMPT_TEMPLATE: str = """Write a python function that can {instruction}.Return ```python your_code_here ```with NO other texts,your code:"""name: str = "SimpleWriteCode"async def run(self, instruction: str):prompt = self.PROMPT_TEMPLATE.format(instruction=instruction)rsp = await self._aask(prompt)code_text = parse_code(rsp)return code_text
测试用例代码书写行为如下:
class SimpleWriteTest(Action):PROMPT_TEMPLATE: str = """Context: {context}Write {k} unit tests using pytest for the given function, assuming you have imported it.Return ```python your_code_here ```with NO other texts,your code:"""name: str = "SimpleWriteTest"async def run(self, context: str, k: int = 3):prompt = self.PROMPT_TEMPLATE.format(context=context, k=k)rsp = await self._aask(prompt)code_text = parse_code(rsp)return code_text
测试用例评审行为如下:
class SimpleWriteReview(Action):PROMPT_TEMPLATE: str = """Context: {context}Review the test cases and provide one critical comments:"""name: str = "SimpleWriteReview"async def run(self, context: str):prompt = self.PROMPT_TEMPLATE.format(context=context)rsp = await self._aask(prompt)return rsp
2-4-3、角色/智能体 定义
写代码角色定义:
- 使用set_actions函数,为角色装配行为。
- 使用_watch函数,观察上游重要信息(来自于用户或者是其他智能体),这里UserRequirement代表的是用户输入
class SimpleCoder(Role):name: str = "Alice"profile: str = "SimpleCoder"def __init__(self, **kwargs):super().__init__(**kwargs)self._watch([UserRequirement])self.set_actions([SimpleWriteCode])
代码测试角色定义:
- 同样的, 使用set_actions函数,为角色装配行为。
- 同理,使用_watch函数,观察上游重要信息(来自于用户或者是其他智能体),这里主要的观察来源是SimpleWriteCode。
- 这里,重写act函数,使用所有对话内容作为测试行为的上下文,写出更加精准的测试用例。
class SimpleTester(Role):name: str = "Bob"profile: str = "SimpleTester"def __init__(self, **kwargs):super().__init__(**kwargs)self.set_actions([SimpleWriteTest])self._watch([SimpleWriteCode])# 既观察SimpleWriteCode,也观察SimpleWriteReview,这样可以做到一个循环的自我修正。# self._watch([SimpleWriteCode, SimpleWriteReview]) # feel free to try this tooasync def _act(self) -> Message:logger.info(f"{self._setting}: to do {self.rc.todo}({self.rc.todo.name})")todo = self.rc.todo# context = self.get_memories(k=1)[0].content # use the most recent memory as contextcontext = self.get_memories() # use all memories as contextcode_text = await todo.run(context, k=5) # specify argumentsmsg = Message(content=code_text, role=self.profile, cause_by=type(todo))return msg
测试用例评审角色定义: 同上。
class SimpleReviewer(Role):name: str = "Charlie"profile: str = "SimpleReviewer"def __init__(self, **kwargs):super().__init__(**kwargs)self.set_actions([SimpleWriteReview])self._watch([SimpleWriteTest])
2-4-4、创建队伍,添加角色
概述: 使用Team来雇佣三位角色
- idea: 即复杂任务描述,代表用户输入
- investment: 投资人工智能公司的金额,暂时不清楚有什么用
- n_round: 模拟的回合数,大部分情况,该数字越大越好,但是也并不是绝对的,简单任务,回合少点就ok,复杂任务需要调试一个相对均衡的回合。多了有可能复读机或者性能下降。
import asyncio
import typer
from metagpt.logs import logger
from metagpt.team import Team
app = typer.Typer()@app.command()
def main(idea: str = typer.Argument(..., help="write a function that calculates the product of a list"),investment: float = typer.Option(default=3.0, help="Dollar amount to invest in the AI company."),n_round: int = typer.Option(default=5, help="Number of rounds for the simulation."),
):logger.info(idea)team = Team()team.hire([SimpleCoder(),SimpleTester(),SimpleReviewer(),])team.invest(investment=investment)team.run_project(idea)asyncio.run(team.run(n_round=n_round))if __name__ == '__main__':app()
输出:

2-4-5、内部机制介绍
概述: 详细介绍整个多智能体系统的运行机制。
- 如右图所示,Role(智能体)将观察来自于环境的输出信息。(只观察特定Action,这要看参数设置)
- 如果一个特定的行为输出了信息到环境,并且恰好是Role要观察的行为,那么Role将做出反馈。
- 首先,Role将会思考并选择一种行为作为接下来要执行的,之后会执行该行为并且得到输出,输出后续将会被投入到环境中去。

2-4-6、人工介入
概述: 在真实场景下,我们往往需要人类介入来修正多智能体团队协作中的一些错误。
在2-4-4中,我们设置SimpleReviewer的is_human参数为True即可。这样我们可以控制协作流程,代替测试用例评审角色,作为测试用例评审角色来参与到整个流程中。每次轮到我们响应时(测试用例评审角色),正在运行的进程都会暂停等待我们的输入。我们可以根据其他Agent的输出,提出合理要求以参与到整个交互中。
team.hire([SimpleCoder(),SimpleTester(),# SimpleReviewer(), # the original lineSimpleReviewer(is_human=True), # change to this line]
)
2-4-7、记忆/内存
概述: 记忆是Agent的核心,Agent需要依靠记忆来做决策。类Memory是Agent记忆的抽象表示,当角色初始化时,以self.rc.memory初始化记忆,它将把它随后观察到的每条消息存储在一个列表中,以便将来检索。当记录的记忆被需要时,你可以使用self.get_memories来获取记忆。
def get_memories(self, k=0) -> list[Message]:"""A wrapper to return the most recent k memories of this role, return all when k=0"""return self.rc.memory.get(k=k)
例如在2-4-3中: 我们调用整个函数是为了向测试智能体提供完整的历史记录。
async def _act(self) -> Message:logger.info(f"{self._setting}: ready to {self.rc.todo}")todo = self.rc.todo# context = self.get_memories(k=1)[0].content # use the most recent memory as contextcontext = self.get_memories() # use all memories as contextcode_text = await todo.run(context, k=5) # specify argumentsmsg = Message(content=code_text, role=self.profile, cause_by=todo)return msg
添加记忆: 使用self.rc.memory.add(msg)添加记忆,并且msg必须是Message对象。
Notice: 角色通常需要记住它之前说过或做过什么,以便采取下一步行动。所以建议在复写act函数的逻辑时,建议将动作输出的消息添加到角色的内存中。
附录
1、react_mode(智能体的思维范式介绍)
概述: 接收到对环境的观察后,智能体会进行思考以及做出一些行为来应对,MetaGPT目前提供两种方式,即ReAct和By Order。
1-1、ReAct
ReAct: 先思考,后行动,直到Agent决定停止循环。每次思考(_think)时,角色会选择一种行为来回应观察,并且执行选择的行为在_act函数,而行为的输出结果将会是下一次思考的观察对象,LLM作为大脑,动态的选择行为去执行。
REACT: SYNERGIZING REASONING AND ACTING IN LANGUAGE MODELS: ReAct详细介绍可以参考我的另一篇文章:REACT: SYNERGIZING REASONING AND ACTING IN LANGUAGE MODELS【大模型的协同推理】

Notice: 如果你想要角色执行更多次思考-行动循环,那么你可以设置参数max_react_loop。实验证明,设置该参数非常有必要,在react的过程中,如果思考-行动循环少,往往会做出错误的决策,即少执行或者错误执行行为
self._set_react_mode(react_mode="react", max_react_loop=6)
1-2、By order
By order: 按照set_actions中设定的行为去依次执行。该情况适用于我们清楚Agent该依次执行哪些行为。

例如在目录2-4-2的案例中,我们就是顺序执行行为,先写代码,后执行代码。
class RunnableCoder(Role):name: str = "Alice"profile: str = "RunnableCoder"def __init__(self, **kwargs):super().__init__(**kwargs)self.set_actions([SimpleWriteCode, SimpleRunCode])self._set_react_mode(react_mode="by_order")async def _act(self) -> Message:...
1-3、Plan and act
先拟定计划,之后使用计划去执行一系列动作:

参考文章:
《MetaGPT智能体开发入门》教程
Datawhale教程.
MetaGPT—GitHub官网
openAI研究主管文章
awesome-ai-agents——AI agent汇总
MetaGPT智能体入门——官方文档
LLM图形化界面:
川虎 Chat 🐯 Chuanhu Chat
chatgpt-KnowledgeBot
总结
好困好困😩

)


)
)













