原文链接:https://jack-vanlightly.com/blog/2024/6/10/a-cost-analysis-of-replication-vs-s3-express-one-zone-in-transactional-data-systems
作者|Jack Vanlightly
AutoMQ 导读
随着 S3 在构建现代化数据基础设施的流行,广大 data infra 领域的开发者都非常关注 AWS S3 的一举一动。像 WarpStream[2] 以及 Confluent Freight Cluster[3] 一样完全将存储层构建于 S3 上的最大缺点在于其无法满足低延迟的流系统应用场景。S3 Express One Zone (S3E1Z)的出现为各个数据基础设施厂商基于对象存储构建云原生服务提供了一种新的选择。和S3相似的使用方式,更低的延迟,但代价是更高的成本。本篇内容,Jack 通过一系列实验详细阐释了基于 WAL 和 S3 的模型中,采用复制以及采用多写 S3E1Z在成本模型上的差异。不过可惜的是,其对于预写WAL的几种模型中没有涉及 AutoMQ 独创的 EBS WAL 模式。值得一提的是,AutoMQ 也支持了基于 S3E1Z 的 S3 Express WAL[4],有兴趣的读者可以自行拓展阅读。
直接在 S3 Express One Zone 上构建容错事务数据系统,而不是使用复制,是否经济实惠?请继续阅读分析。云对象存储正在成为大量云数据系统的通用存储层。一些系统使用对象存储作为唯一的存储层,接受对象存储的更高延迟,这些系统往往是可以接受数秒延迟的分析系统。事务系统需要个位数毫秒级的延迟或几十毫秒级的延迟,因此不会直接写入对象存储。相反,它们将数据放在快速复制的预写日志 (WAL) 上,并将数据卸载到对象存储中,以实现读取优化的长期经济存储。Neon就是这种架构的一个很好的例子。写入命中基于 Multi-Paxos 的低延迟复制预写日志,数据最终写入对象存储。
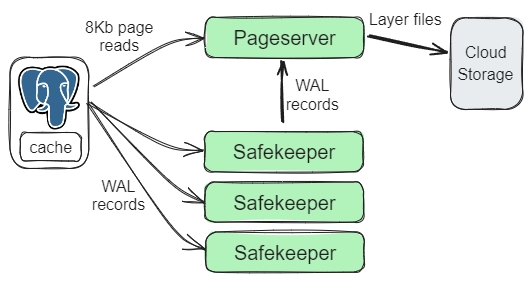
图 1. Neon 架构中的容错预写日志
Kafka 和 Confluent 的 Kora也都使用了这种架构,在流媒体中通常被称为分层存储。本质上,Kafka/Kora 代理是一个复制的写入缓存和服务层,数据被压缩成更大的对象并异步卸载到更经济的云存储中。
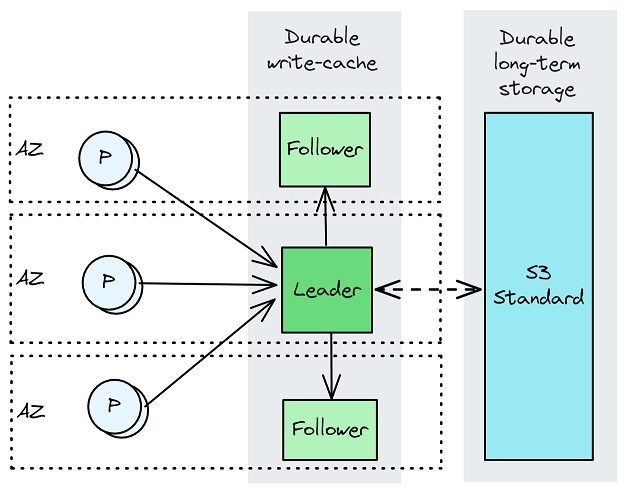
图 2. 数据到达领导节点并同步复制到跟随节点。数据异步卸载到长期存储(Kora/Kafka)
我们称之为预写日志或持久写缓存,其理念是数据在被卸载到对象存储之前,会落在有状态的复制日志层上。对于需要低延迟的事务系统,这是必需的架构。S3 Express One Zone 的出现引发了一个问题:这种快速复制的预写日志层是否可以被 Express One Zone 取代,从而不再需要有状态的复制层。S3 Express One Zone 是 S3 的一个低延迟层,虽然只在单个可用区域内分发数据,但提供个位数的延迟。鉴于 Express One Zone 存储成本比标准存储高出 7 倍,它不适合长期存储。但它可以适用于持久的预写日志/写缓存,就像 Kafka/Kora/Neon 今天使用复制一样。
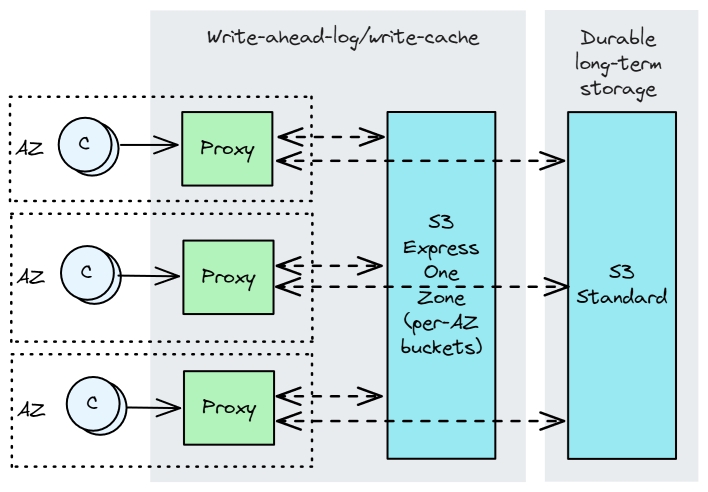
图 3. 客户端与区域本地代理交互,而后者又同步写入 S3 Express One Zone。不会发生跨可用区的数据传输,从而避免了这一巨大的云成本来源。数据被压缩为更大的对象,并异步卸载到 S3 Standard 中的长期存储中
复制和 S3 Express One Zone 具有不同的经济成本模型,并且基于复制或 S3 Express One Zone 提供具有成本竞争力的服务取决于许多因素。这是本篇博文的重点。
01
五个持久预写日志 (WAL) 选项
我在 Confluent 工作,Confluent Cloud 中绝大多数生产专用集群都是多可用区。大多数单可用区集群用于开发和 QA 集群。大多数组织都希望实现高可用性,以便在单个区域降级或离线的情况下,系统能够继续运行。虽然区域中断不会每天都发生,但确实会发生,而且只需一次中断就会直接给所有受影响的组织造成大量损失,并造成声誉损害。只需一次长时间中断就会对企业造成重大损害 - 因此组织不愿把所有精力都放在一个区域。也就是说,我们将比较单可用区和多可用区的预写日志选项。
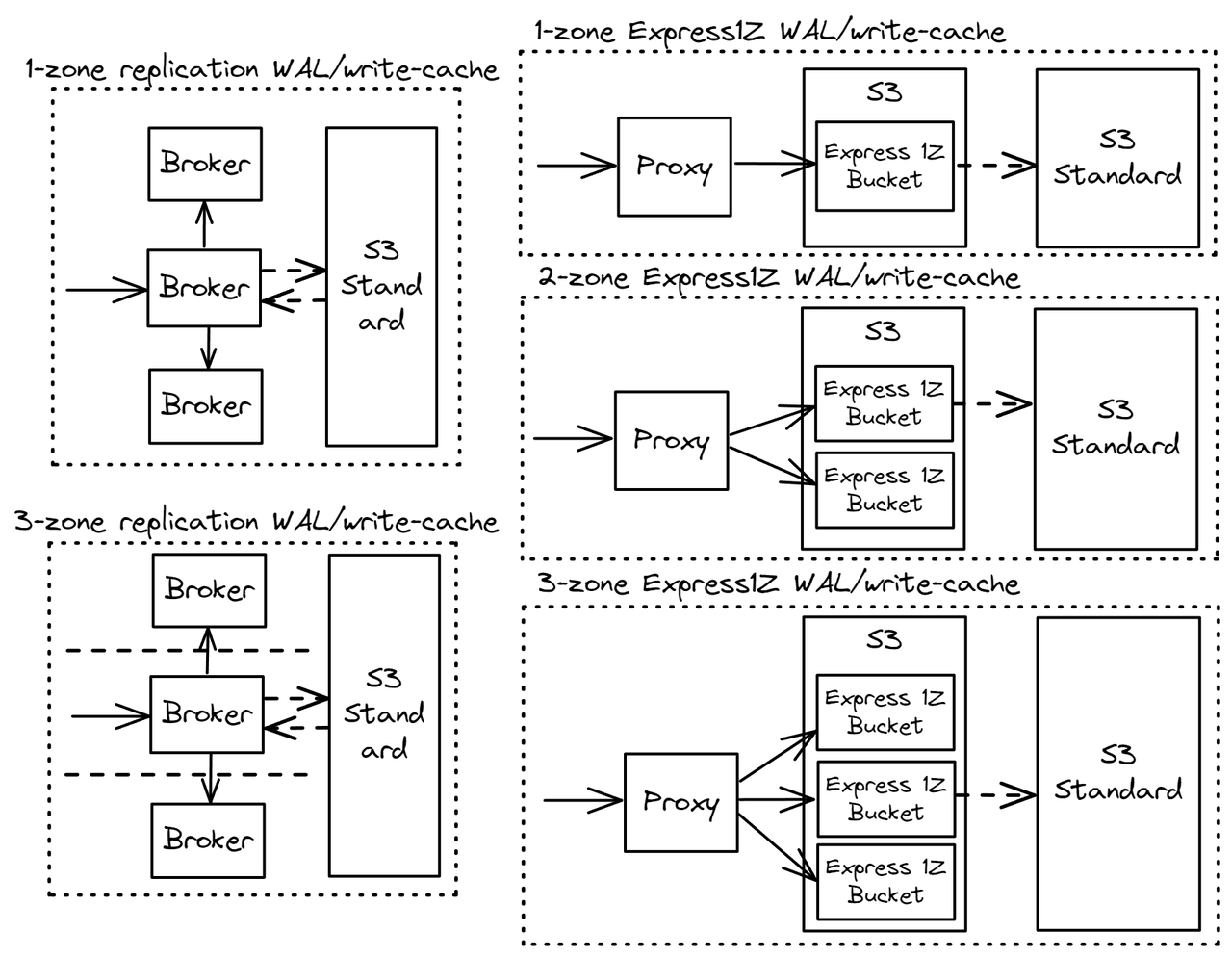
图 4. 单区域复制部署没有跨可用区流量。但是,多区域部署对于生产者和复制流量都有跨可用区流量。代理对象存储架构通过确保客户端与区域本地代理交互来避免所有跨可用区流量。多可用区是通过写入多个存储桶来实现的,每个存储桶位于不同的区域中。写入不同可用区的存储桶没有任何成本
WAL 成本模型
对于这项成本研究,我们假设 WAL 保留最后 6 小时的数据。卸载可能会更早发生,但我们将按 6 小时的本地保留定价。我们还将关注写入路径,因为这是复制和 S3 Express One Zone 的主要成本驱动因素。复制可以使用诸如 fetch-from-follower 之类的技巧来避免在使用时跨可用区数据传输,并且 S3 Express One Zone 的 GET 成本不到 PUT 成本的十分之一。
1.1 复制成本模型
有状态复制层有三个成本:
计算:计算实例(服务器)。
存储:存储驱动器(例如 EBS)。
网络:跨可用区数据传输成本。单区域集群的成本为 0 美元,Microsoft Azure 最近宣布他们正式不再收取跨可用区数据传输费用。因此,在某些部署中,网络成本可能为零。
此分析忽略了计算实例成本,因为对 CPU 和内存的要求完全取决于服务及其实现。我们将重点关注所需的基本存储和网络资源。计算存储需求:
总存储吞吐量(MB/s) = 复制因子 * 总入口吞吐量(MB/s)。
总存储大小= 总存储吞吐量 * 6 小时 * 60 分钟 * 60 秒。
每节点存储吞吐量=总存储吞吐量/节点数。
每个节点的存储大小= 总存储大小/节点数。
计算跨可用区的数据传输:
生产者跨可用区吞吐量(MB/s) = ⅔ * 聚合入口吞吐量 MB/s(平均而言,3 个字节中有 2 个将跨越可用区)。
跨可用区复制= 2 * 总入口吞吐量 MB/s(到达领导者的每个字节将被复制到两个跟随者)。
跨可用区总量= 2.66 * 总入口吞吐量 (MB/s)。
例如,假设有 3 个节点、复制因子为 3 且聚合入口为 100 MB/s,我们得到:
总存储吞吐量= 300 MB/s,每个节点 100 MB/s。
总存储大小= 6.5 TB,每个节点 2.16 TB。
跨可用区= 2.66 * 100 MB/s = 266 MB/s。
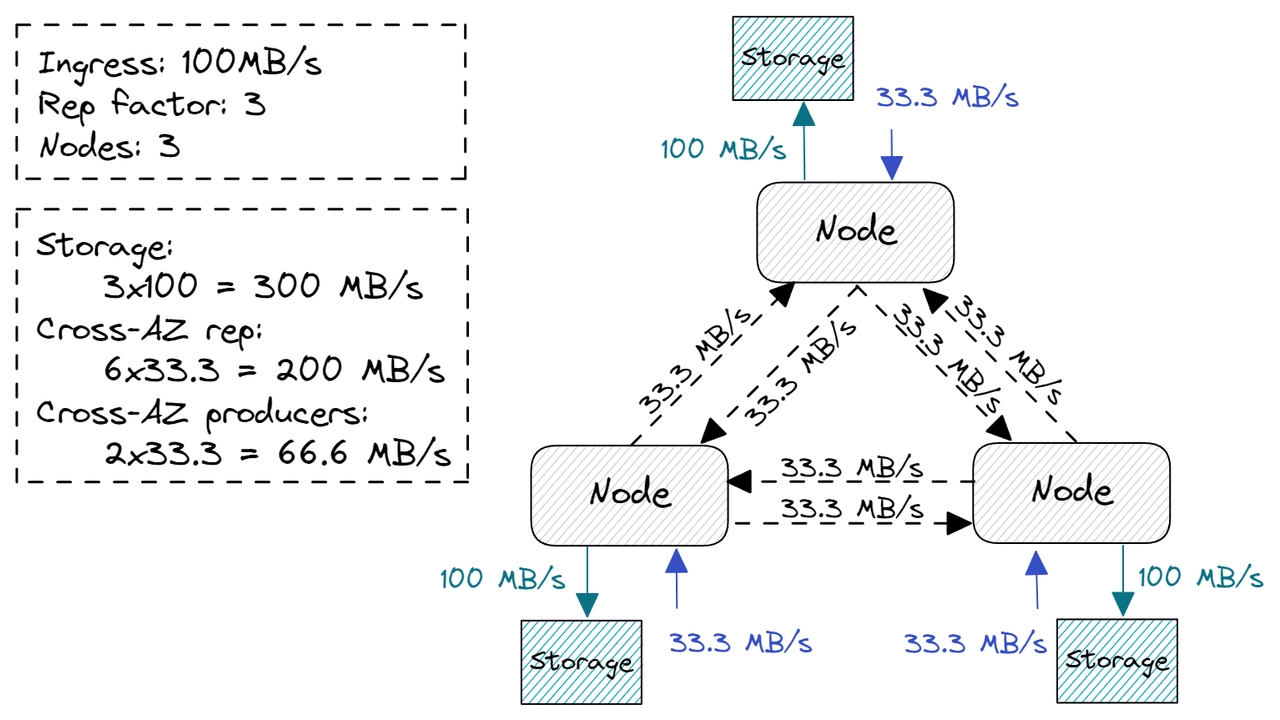
图 5.复制的存储和网络故障
我们来计算一些例子: 1 MB/s,3 个节点
存储:3x gp3、125 MB/s、3000 IOPs、10 GB = 每月 2 美元。
跨可用区:0.02 * 0.00266GB/s * 30 * 24 * 60 * 60 = 每月 135 美元。
2. 100 MB/s,3 个节点
存储:3x gp3、125 MB/s、3000 IOPs、2.5TB = 每月 600 美元。
跨可用区:0.020.266GB/s30*246060 = 每月 13800 美元。
3. 1000 MB/s,9 个节点
存储:18x gp3、350 MB/s、5000 IOPs、7.5TB = 每月 1850 美元。
跨可用区:0.022.66GB/s302460*60 = 每月 138,000 美元。
复制模型以跨可用区数据传输成本为主,约占存储 + 网络总成本的 90-95%,本地保留时间为 6 小时。也许因为跨可用区成本可能非常高,CSP 往往会提供相当大的跨可用区折扣,而Azure 根本不收取跨可用区费用。总数据传输量越大,组织通常可以获得的折扣越大。我见过云占用空间大的组织享受到 85% 以上的折扣。

图6.吞吐量与数据传输成本的关系,以及折扣的影响
因此,基于多可用区复制的系统的主要成本因素是吞吐量与跨可用区数据传输折扣的结合。值得记住的是,在 Azure 上,根本没有跨可用区成本。
1.2 Express 单区成本模型
在多可用区部署中,复制主要由跨可用区的字节数决定,而 Express One Zone 的主要成本驱动因素是请求率,并对请求大小有一个附加条件。S3 Express 单区定价:● 存储:每月每 GB 0.16 美元。● PUT 请求:
每 1000 个 PUT 请求 0.0025 美元。
PUT 请求中超过 512KB 的所有字节为 0.008 美元/GB。
● S3% 折扣。至于折扣,我认为大客户不会为任何东西支付标价。但是,S3 折扣通常比跨可用区数据传输折扣低很多,而 Azure 的数据传输折扣实际上为 100%。我个人从未见过 S3 的折扣超过 25-30%,这些折扣适用于真正巨大的云足迹,但这是我自己的经验。S3 Express 单区写入缓存可由一个、两个或三个可用区组成。通过将每个对象写入多个存储桶(每个存储桶位于不同的区域),可实现多区。对于 3 区配置,它可以使用多数仲裁方法,这样一旦 3 个写入中有 2 个得到确认(以避免延迟峰值),写入即被视为成功,但最终会写入所有 3 个。Express One Zone 成本的关键在于请求率(和请求大小)与可容忍的缓冲延迟之间的矛盾。复制成本不受节点之间交换的实际请求数量的影响,而 S3 Express One Zone 则完全取决于请求数量。鉴于 Express One Zone 是一个能够进行个位数延迟写入的低延迟层,在写入请求之前长时间缓冲数据是没有意义的。对于事务数据系统,缓冲时间必须保持较短。正如我们将在本分析中看到的那样,这对于高吞吐量工作负载来说可能没问题,但对于低吞吐量工作负载来说却是一个真正的问题。关于请求率、请求大小、期望延迟和吞吐量存在以下关系:
对于固定的吞吐量,请求大小和代理上的缓冲时间量之间存在线性关系。
对于固定吞吐量,请求大小和请求速率之间存在反比线性关系。
对于固定的缓冲时间,请求率和代理数量之间存在线性关系。
这些关系会影响成本。下图显示了 9 个代理上 1 GB/s 吞吐量的缓冲时间和放置速率关系。对于固定的吞吐量和代理数量,缓冲时间越长,请求大小越大,放置速率越低。
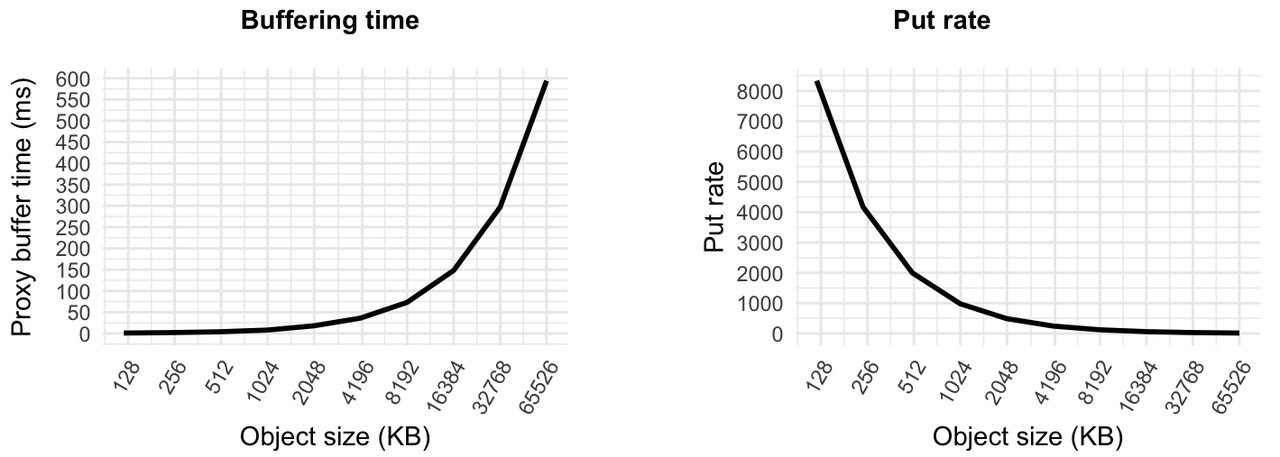
图 7.缓冲时间、放入速率和对象/请求大小之间的关系
总投入率和超过 512 KB 投入大小的总字节数是主要的成本驱动因素。在下面的月度成本图表中,我们可以看到 Express One Zone(1 区)对于 512KB 以下的请求的成本是 Standard 的一半,这反映了两个层级的定价:Express One Zone 每 1000 个请求 0.0025 美元,Standard 每 1000 个请求 0.005 美元。
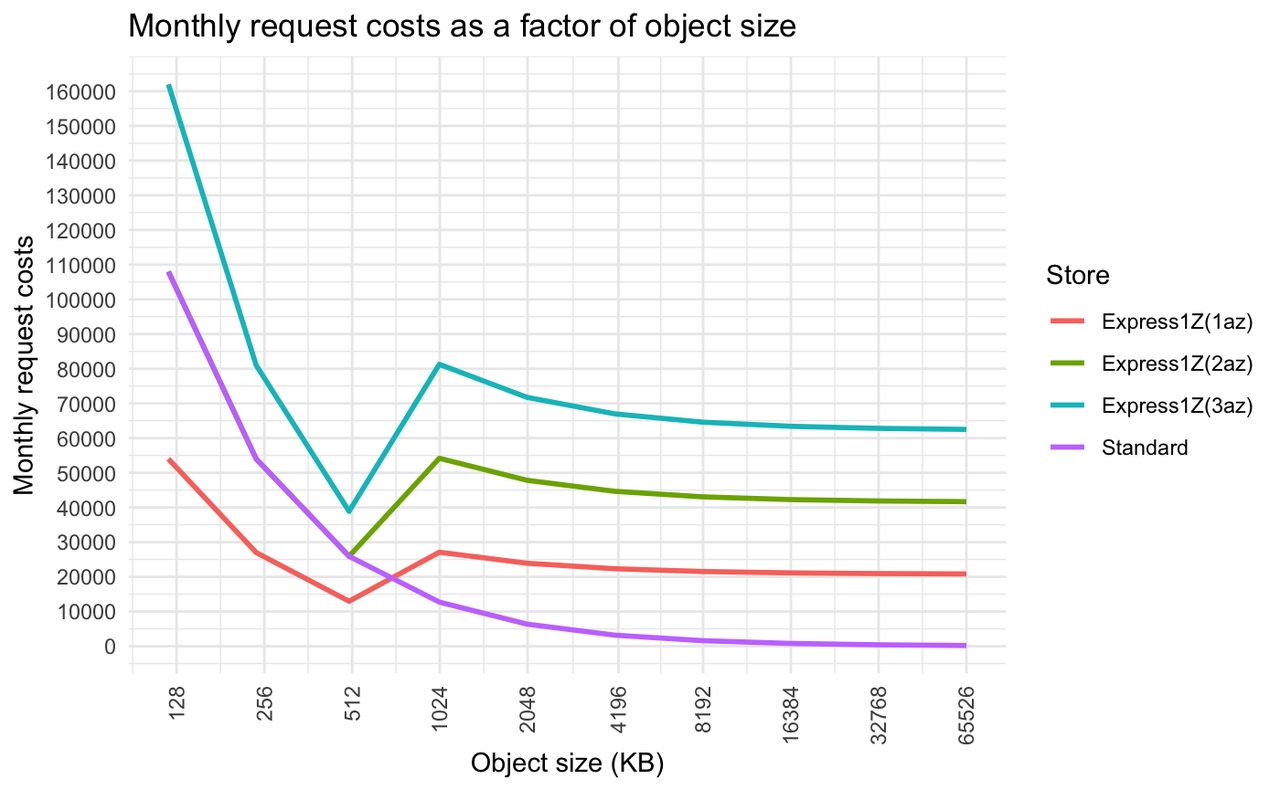
图 8.请求/对象大小如何影响 1 GB/s 工作负载的 Express One Zone 请求成本
由于 Express One Zone 对超过 512KB 的请求收取额外费用,因此一旦请求大小超过 512KB,成本就会再次上升,然后开始略有下降。标准版受益于越来越大且频率更低的请求,而将请求大小增加到 512 KB 以上对 Express One Zone 没有任何好处。每个请求的最佳成本如下:
标准:每月 200 美元,或每 GB 0.000072 美元(64MB 请求大小)
Express One Zone (1az):每月 13,000 美元,或每 GB 0.005 美元(512KB 请求大小)
Express One Zone(2az):每月 26,000 美元,或每 GB 0.01 美元(512KB 请求大小)
Express One Zone(3az):每月 39,000 美元,或每 GB 0.015 美元(512KB 请求大小)
对于 9 个代理的 1 GB/s 工作负载来说,好消息是只需 5 毫秒的缓冲时间即可达到 512 KB 请求。但是,对于较低的吞吐量,请求速率会根据可容忍的最大缓冲时间而存在下限。例如,10 毫秒的缓冲时间将导致每个代理每秒的最低请求速率为 100 个。
让我们检查一下,在固定数量的 Broker(在本例中为 6 个)以及 1 区域和 3 区域配置的情况下,放置速率、放置大小和放置成本如何根据吞吐量而变化。
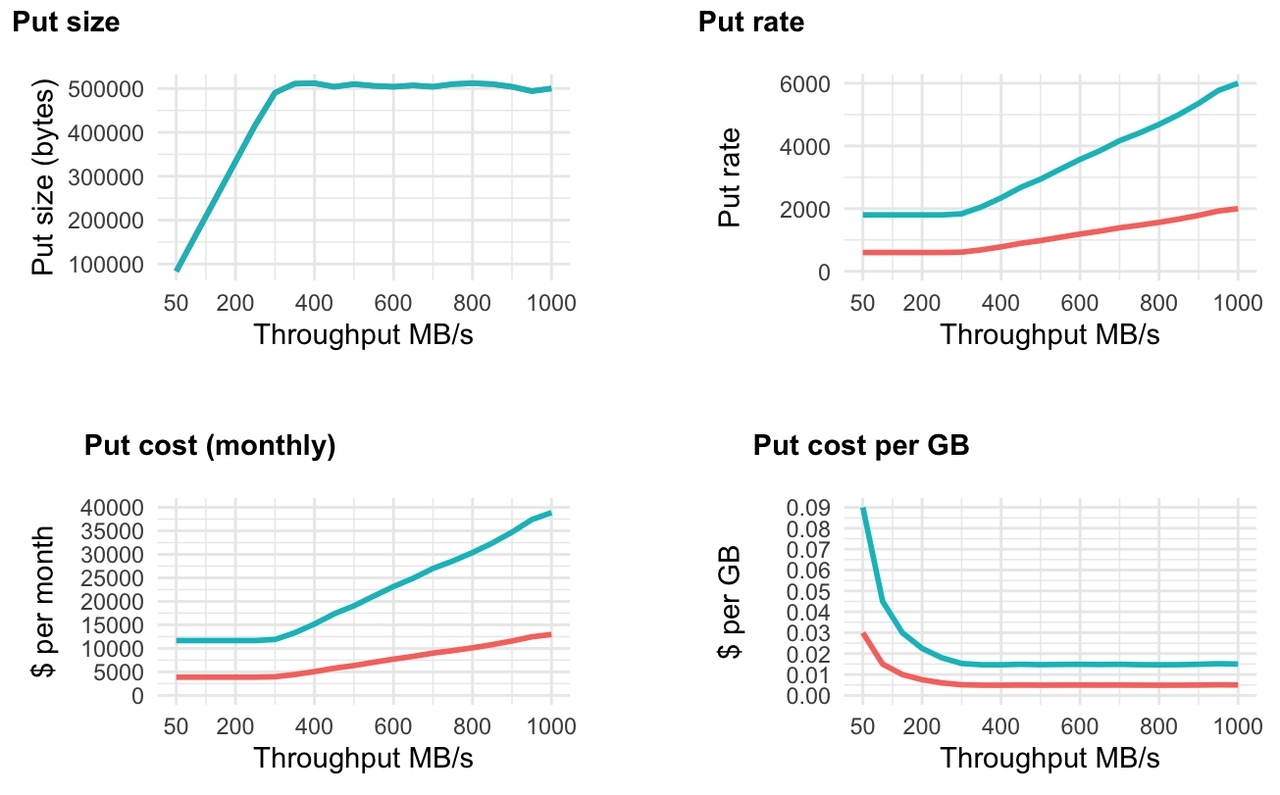
图 9. 可变吞吐量,具有固定代理数量、最大缓冲时间为 10 毫秒且最大请求为 512 KB
我们看到,使用 6 个代理时,基准成本为每月 3888 美元(1 个区域)和每月 11664 美元(3 个区域)。此基准影响较低的吞吐量端,这意味着无论工作负载是 1 MB/s 还是 250 MB/s,请求成本都是相同的。正如我之前所说,代理数量会影响请求成本,因为对于固定的缓冲时间,代理数量和放置速率之间存在线性关系(直到达到 512 KB 的请求大小),因此请求成本也存在线性关系。因此,最好实现自动扩展,其中代理数量以 3 为增量增加和减少(假设有 3 个可用区)。假设每个代理应处理 100 MB/s 的总入口吞吐量,那么成本将如下图所示。
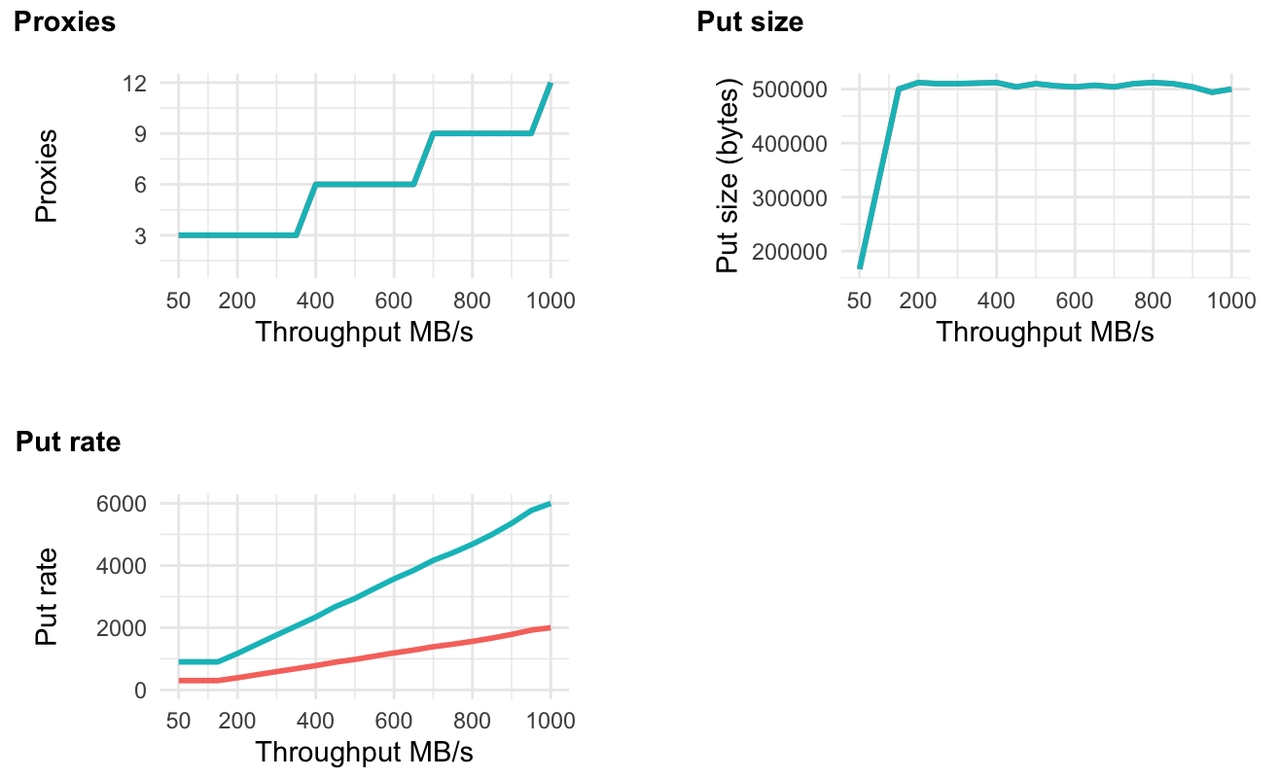
图 10. 自动缩减至 3 个代理可改善较低吞吐量的情况。通过 150 MB/s,我们达到了 3 区 S3 Express One Zone 的理论最佳成本 0.015 美元/GB。将代理数量降低到 3 个,一直到 1 GB/s,对请求成本没有影响(最大缓冲时间为 10ms)
当我们允许代理数量降至最低 3 个时,基准 put 速率从 600/s(1 区)和 1800/s(3 区)变为 300/s(1 区)和 900/s(3 区)。这使得基准成本从每月 3888 美元降至 1944 美元(1 区),从每月 11664 美元降至 5832 美元(3 区)。当我们使用固定的 6 个代理配置时,基准现在也仅适用于从 250 MB/s 到 150 MB/s 的速度。然而,虽然成本概况随着自动扩展而有所改善,但我们仍然需要为 1 MB/s 和 100 MB/s 的工作负载(最大缓冲时间为 10 毫秒,最大请求大小为 512KB)支付每月 5832 美元的固定请求成本。鉴于写入时间应为个位数毫秒,我认为 10 毫秒的缓冲已经增加了很大的开销(并且已经大于复制的平均端到端延迟)。因为我们必须修复最大缓冲延迟才能支持低延迟工作负载,所以代理必须至少发送 100 个(微小)请求/秒,即使吞吐量较低。让我们看看 1-20 MB/秒范围内的相同图表。
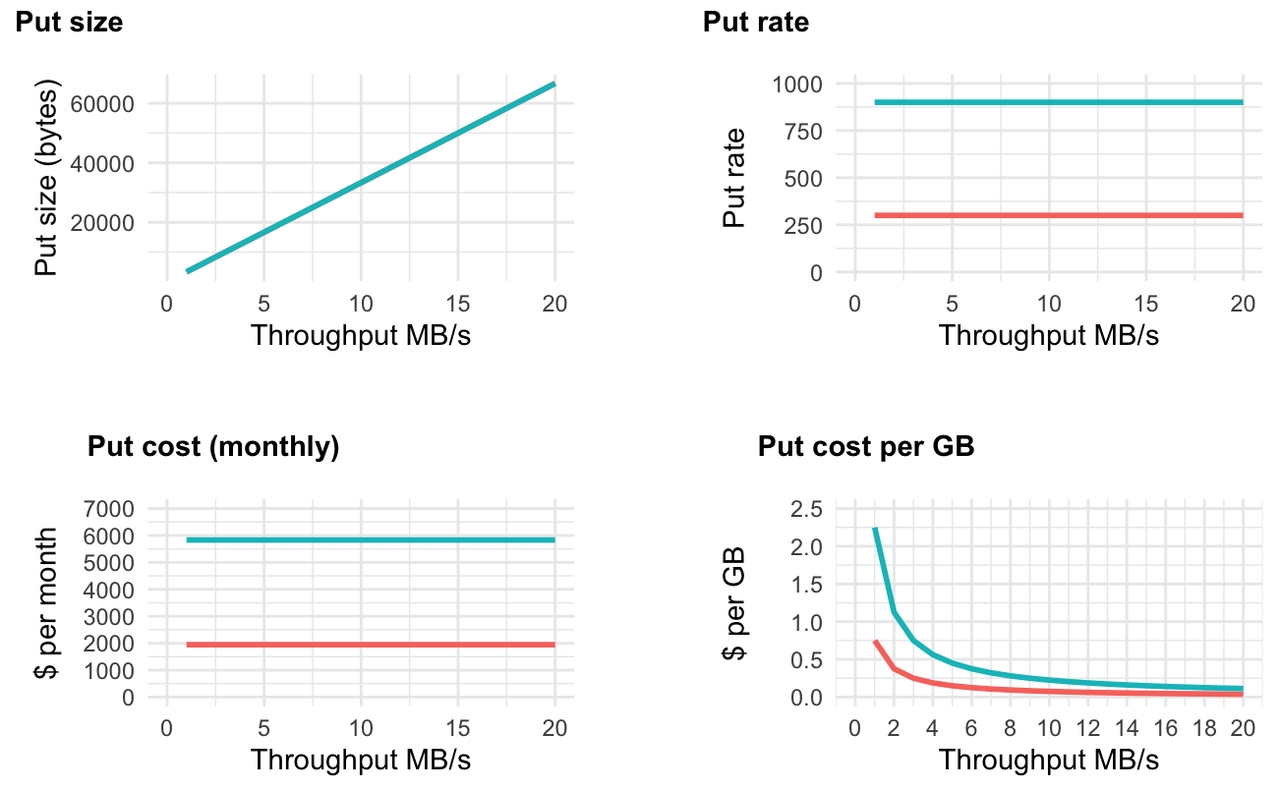
对于 3 区配置,1 MB/s(每月 2.5 TB)的每 GB 成本上升至 2.25 美元。这与高吞吐量 3 区配置的最佳情况(0.015 美元/GB)相差甚远。请注意,请求大小如何达到 3kb 以满足 3 个代理上 1 MB/s 的 10ms 缓冲延迟。总而言之,基于 S3 Express One 的容错 WAL 的成本模型比复制的成本模型更复杂。这完全取决于以下因素的组合:
吞吐量
代理数量
最大缓冲延迟
最大请求大小(从经济角度来看,512KB 是应该使用的最大大小,只有当更大的请求尽管成本较高但能为系统带来其他好处时,才会使用更高的大小)。
还值得注意的是,基于对象存储的日志需要低延迟寻址和排序组件,该组件强制执行排序并包含逻辑到物理的数据映射。这很可能通过状态机复制 (SMR) 服务(例如 Raft)完成。这会将数据平面拆分为 S3 数据对象的平面地址空间以及对象元数据的有序复制日志。此分析中省略了此组件的成本。
1.3 碎片化和小请求大小
此成本模型假设多个集合(表、主题分区等)的数据在共享对象中共置。不这样做根本不划算,因为这会大幅提高每 GB 的成本。S3 Express One Zone 的对象大小应小于等于 512 KB,而 S3 Standard 对象通常会大得多(因为我们不会因大对象而受到惩罚,并且我们不会尝试进行低延迟写入,这意味着我们可以缓冲更长时间)。这种小对象大小的数据混合会增加大量数据碎片。写入对象时,我们会按集合(例如表或主题分区)对每个对象的数据进行排序,这意味着每个对象都有多个连续的数据块。对于大对象,我们会得到更少、更大的连续块,而对于 512KB 对象,我们会得到更多、更小的连续块。这的影响取决于读取请求是否由 WAL 提供。对于像 Neon 这样的架构,根本没有读取指向 WAL。但是,对于 Kafka API 工作负载,如果请求的数据不再本地缓存,则可能需要从 WAL 对象中为追赶消费者提供服务。这样的追赶消费者会增加 GET 请求数量占读取字节数的比例(即它必须读取大量文件的一小部分)。
1.4 将复制与 S3 Express 单区进行比较
可供比较的组合是无限的,因此我只会选择吞吐量,并限制折扣的选择。
● 1 MB/秒 ° S3 Express 单区:
3 个代理,最大缓冲 10ms,最大请求 512 KB
3 个代理,固定 100ms 缓冲,请求大小不受限制
° 复制:3 个节点
● 50 MB/秒 ° S3 Express 单区:
3 个代理,最大缓冲 10ms,最大请求 512 KB
3 个代理,固定 100ms 缓冲,请求大小不受限制
° 复制:3 个节点
● 500MB/秒 ° S3 Express 单区:6 个代理,最大缓冲 10ms,最大请求 512 KB
6 个代理,固定 100ms 缓冲,请求大小不受限制
° 复制:9 个节点
● 1000MB/秒 ° S3 Express 单区:
12 个代理,最大缓冲 10ms,最大请求 512 KB
12 个代理,固定 100ms 缓冲,请求大小不受限制
° 复制:9 个节点
存储
对于复制,EBS 驱动器的大小取决于节点数和一些额外余量。例如,对于 1 MB/s 的吞吐量,我们只需要三个节点,每个节点将托管 6 小时的副本。这相当于大约 3 个节点,每个节点需要 21 GB 的存储空间,但我将其定价为 3x30GB gp3 卷。
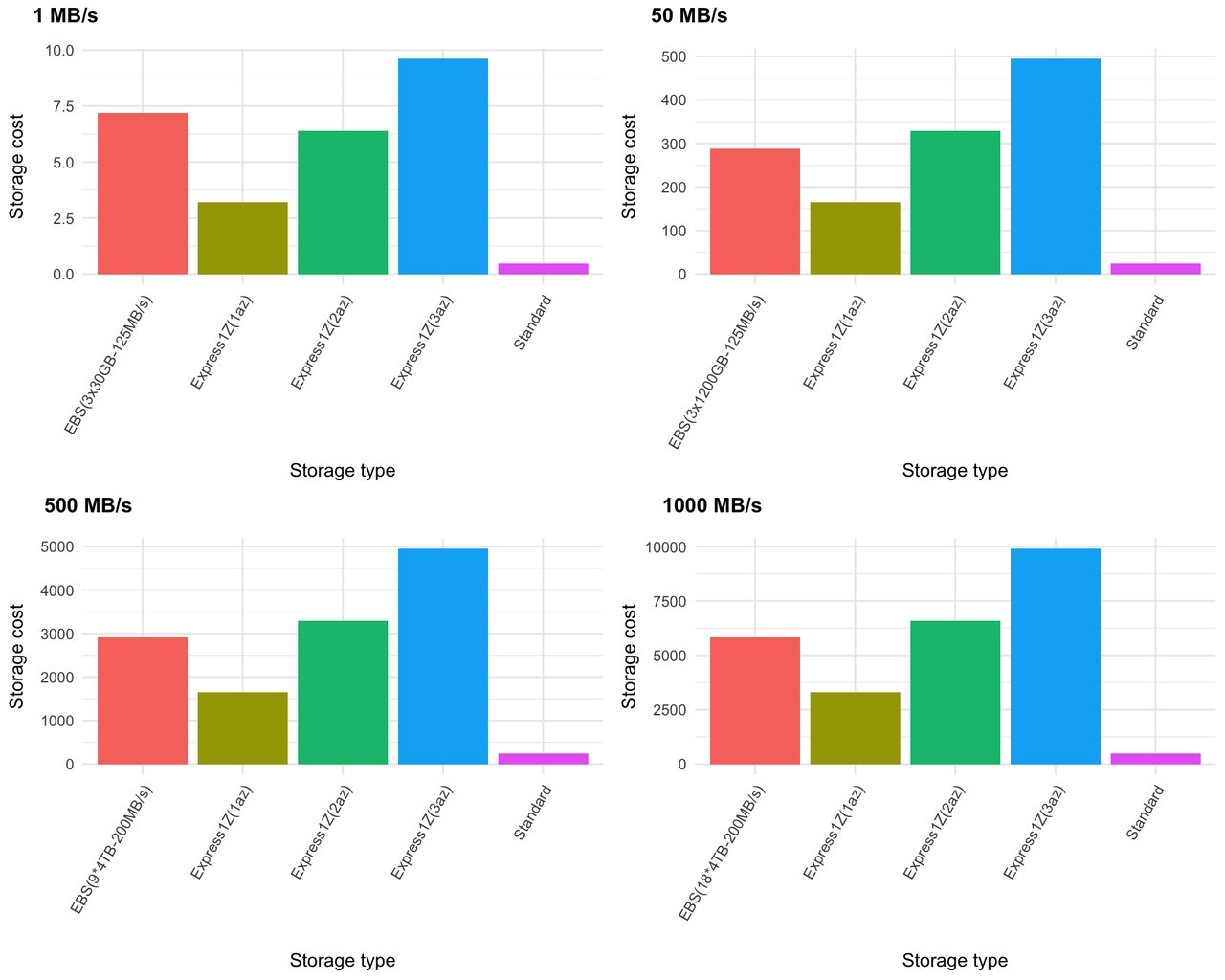
图 12. 存储成本
如您所见,EBS 成本略低于 2-AZ Express One Zone 配置。当然,S3 Standard 每 GB 比 EBS 或 Express One Zone 便宜得多。
网络成本与请求成本(+存储)
我比较了 3 区域复制与 3 区域 Express One Zone。此外,我还比较了以下折扣:
复制:跨可用区数据传输折扣分别为 0%、50%、80%、90%。
S3:一般 S3 折扣为 0%、25%。
如果您想知道为什么数据传输折扣更大,那是因为这反映了现实世界,正如我在文章前面提到的那样。数据传输折扣之所以如此之大,是因为数据传输量大的成本巨大,而 CSP 的网络基础设施成本相对较低。S3 可能在折扣方面没有太大的回旋余地,同时仍能保持盈利。
单可用区配置 请注意,复制折扣为 0%,因为它与单可用区配置(或 Azure 中部署的多可用区集群)无关。
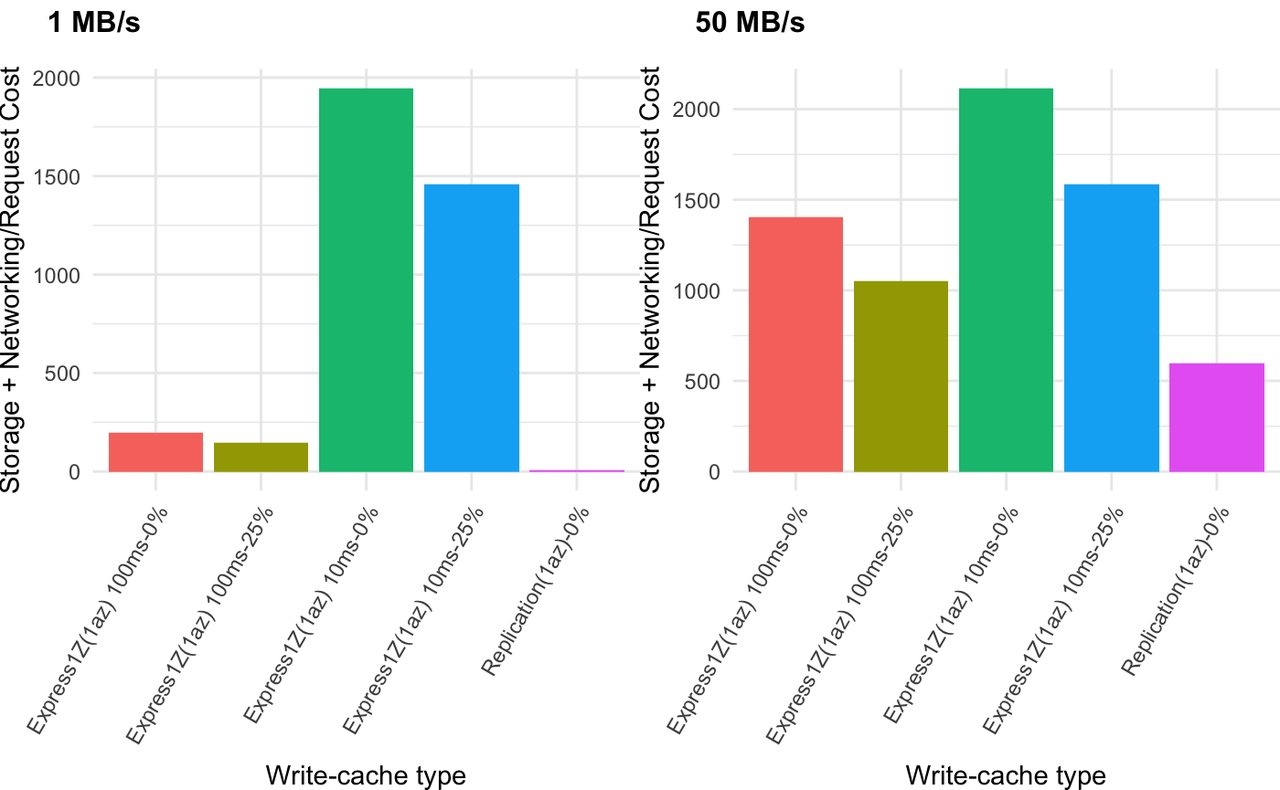
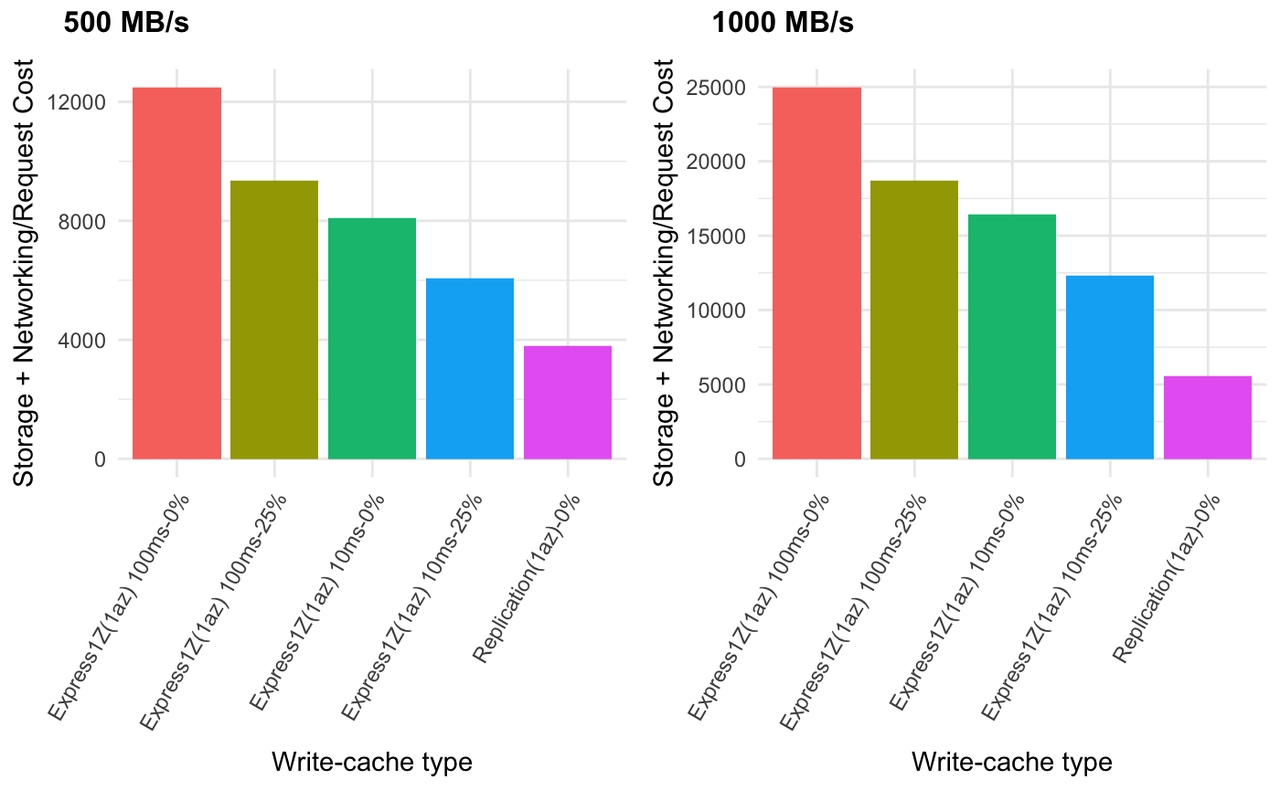
图 13.单可用区总成本
我们在这里看到的复制仅仅是存储成本,而 S3 Express One Zone 的存储 + 请求成本则更高。毫不奇怪,复制更便宜。
有趣的是缓冲时间和请求大小对 S3 Express One Zone 的影响。在 1 MB/s 时,缓冲 100ms 显然更经济,这是因为这会降低请求速率,同时仍保持请求大小 <= 512 KB。然而,在某些时候,缓冲 100ms 会使经济性变得更差。我们在 500MB/s 和 1 GB/s 的工作负载中看到了这一点,其中长缓冲会产生 10 MB 的请求大小。
多可用区配置
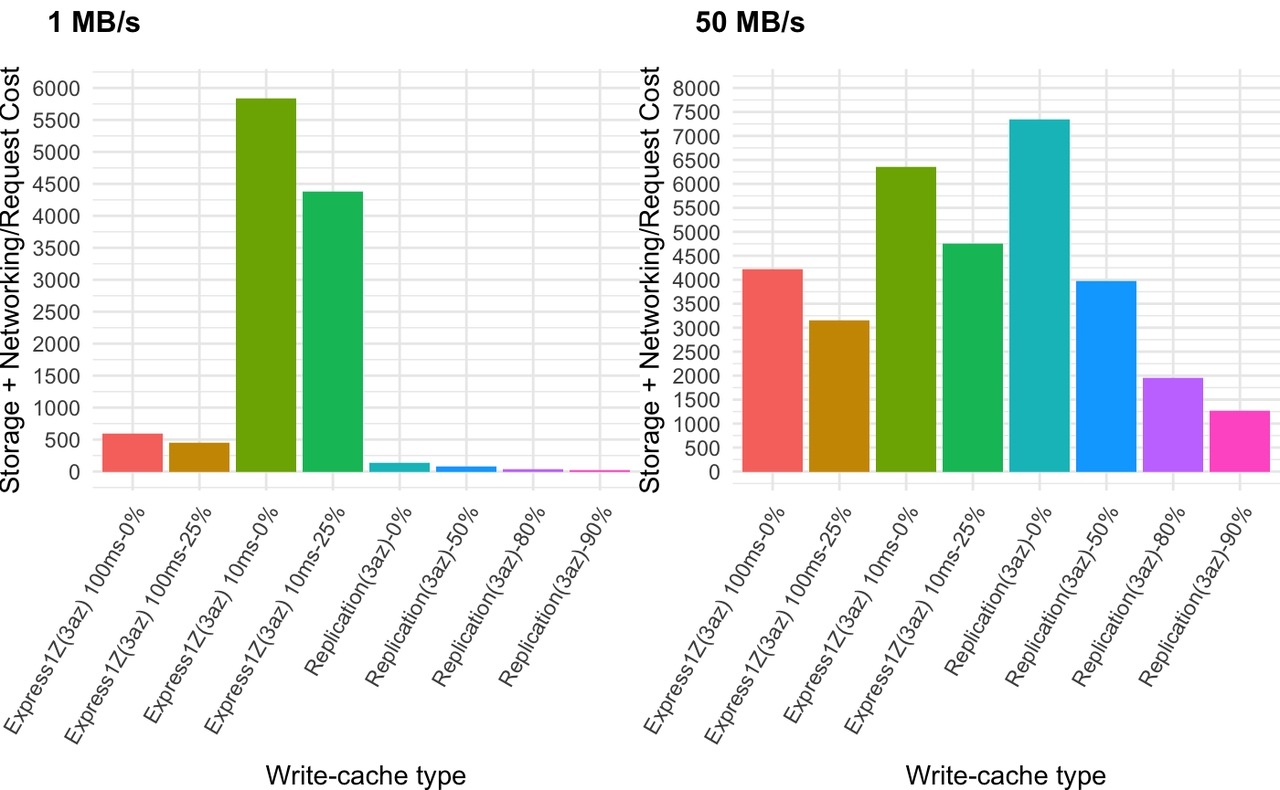

图 14.多可用区总成本
再次,我们发现,对于 S3 Express One Zone 来说,在较低吞吐量下缓冲更长时间更便宜。但是到了 500 MB/s,由于请求大小超过 512 KB,它实际上变得更昂贵。我们清楚地看到,吞吐量越低,复制在成本竞争力方面就越好。对于 500 MB/s 和 1000 MB/s 的工作负载,一切都取决于网络数据传输折扣的大小。对于具有最佳数据传输折扣的组织,复制仍然是最便宜的,对于较低的折扣,S3 Express One Zone 最终可能会更便宜,特别是如果它坚持 512 KB 请求大小。我们还应该考虑到复制将提供最低的生产延迟和端到端延迟。由于代理必须在此模型中缓冲 5-10 毫秒的写入,S3 Express One Zone WAL 已经输掉了延迟之战。此外,如果 WAL 需要数兆字节的请求大小,那么延迟将比复制差几个数量级。
1.5 将 S3 Express One Zone 与缓冲时间更长的 S3 Standard 进行比较
到目前为止,我一直专注于低延迟工作负载,因为这是针对低延迟容错 WAL 的成本分析。如果我们放宽 WAL 的延迟要求会怎么样?如果我们使用更长的缓冲时间,比如 100-250 毫秒,那么我们将处于也可以使用 S3 Standard 的区域(尽管端到端延迟可能会翻倍)。那么对于 1 GB/s 的工作负载(使用 9 个代理),Express One Zone 与 S3 Standard 相比,在更长的缓冲时间方面表现如何。
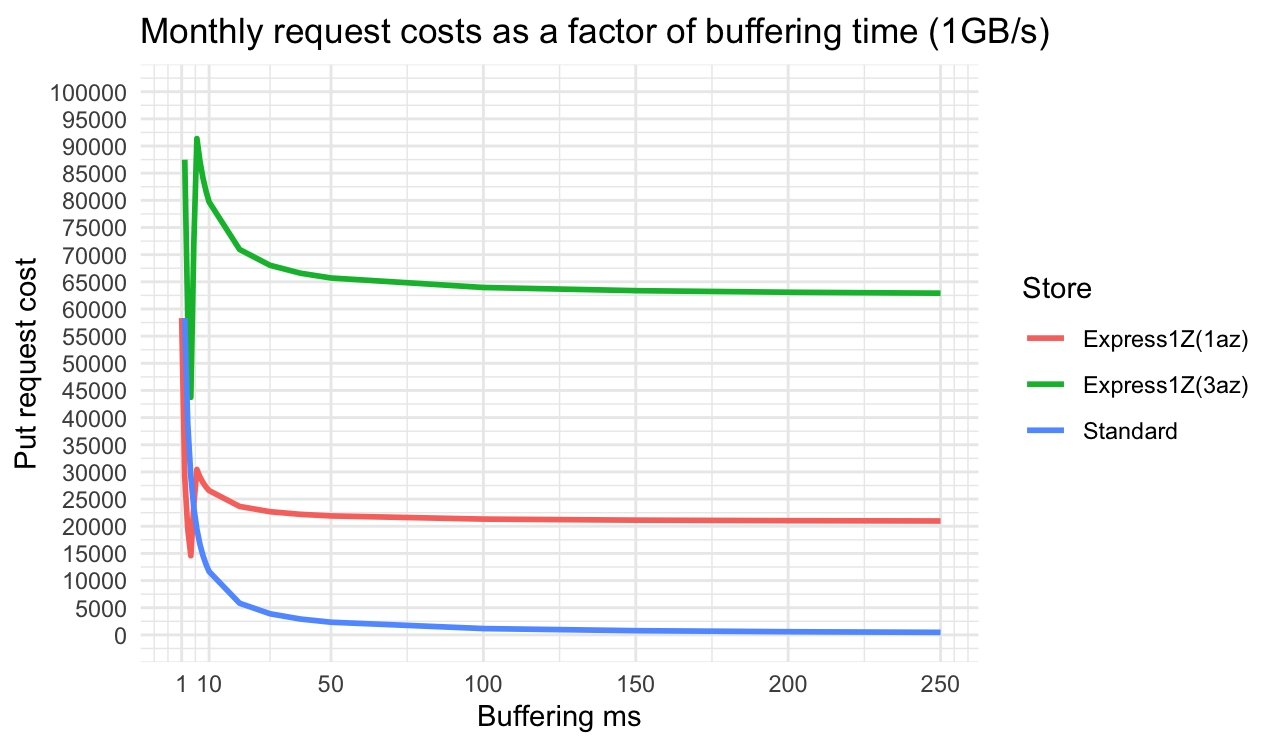
图 15.缓冲时间对 Express One Zone 与 Standard 成本的影响
我们可以看到,对于 Express One Zone,成本最佳点是代理上的缓冲时间为 5 毫秒。超过该时间的所有缓冲时间实际上都会花费更多钱,因为请求大小超过 512 KB。S3 Standard 不会对较大的请求进行惩罚,因此随着缓冲时间的增加,成本只会不断下降。因此,我们看到,如果我们要缓冲更长时间,我们不妨只使用 S3 Standard。使用具有较长缓冲时间的 Express One Zone 会产生一种奇怪的系统。端到端延迟可能只有标准系统的一半,但成本却低得多。因此,我看不出具有较长缓冲时间的 Express One Zone 有什么明显用途,除非是通过降低请求率来使低吞吐量工作负载更经济。对于高吞吐量工作负载,这样的缓冲时间成本要高得多,而且加起来就是两全其美。
02
我如何生成数据
去年我编写了一个 Java 程序,用于模拟状态机复制 (SMR) 工作负载的硬件资源需求(和成本)。为了进行此分析,我为 S3 Express One Zone 日志编写了一个新程序。它们输出 CSV 文件,然后我通过一些 R 笔记本运行这些文件。我可能会花时间清理它们以供一般使用,但这些计算都可以使用电子表格完成,使用 AWS 中提供的定价公式。发布完善的成本模型会很棒,但这需要大量工作,我不想为其他人的成本计算负责。更不用说折扣方案通常会使通用模型变得过于复杂而无法构建。
03
结论
对于低延迟日志,S3 Express One Zone 的主要缺点是低到中等吞吐量下的成本效益。鉴于发送大于 512KB 的请求会产生成本损失,主要的成本驱动因素是请求率。在低吞吐量下,请求率相对于可容忍的最大缓冲时间保持不变。鉴于 S3 Express One Zone 提供个位数的写入延迟,如果您要缓冲 100-400 毫秒以使低吞吐量工作负载经济实惠,那么与标准相比支付大量溢价是没有意义的。出于这个原因,我认为 Express One Zone 仅在高吞吐量工作负载中才可能是预写日志的候选者。这消除了绝大多数单租户工作负载,因此对于常规工作负载,剩下的就是在多租户无服务器架构中使用它。在这样的架构中,您需要将不同租户的数据混合到共享对象中。BYOC 部署将无法使用多租户,因此 BYOC 中 Express One Zone 的使用必须仅限于高吞吐量工作负载。另一方面,复制不会遇到这些问题。它的主要问题是跨可用区的数据传输,但如果对大型工作负载提供适当的折扣,它可以比 S3 Express One Zone 更便宜(并且延迟更低)。目前,有许多玩家参与了“直接写入 S3”游戏。就我而言,我在 Confluent 工作,该公司最近宣布了 Freight Clusters,这是一种基于 Kafka 的对象存储实现。Freight 集群是一个基于标准对象存储层的高延迟系统。我们一直在密切研究 S3 Express One Zone,看看它是否适合作为低延迟写入缓存来取代复制,至少对我们来说,这没有意义。与使用 Express One Zone 相比,我们可以用复制(通过 Kora 代理)获得更好的性能和更低的成本。这可能会改变,也可能不会。AWS 可能会降低请求成本,使其更具竞争力,或者使 S3 Express MultiZone 成为可能,但他们也可能会降低或取消跨可用区的数据传输费用,以便更好地与Azure竞争。如果跨可用区的数据传输变得免费,那么 S3 Express One Zone 就不可能像复制一样便宜。我们只需看看事情会如何发展。
参考资料
[1]WarpStream:https://www.warpstream.com/
[2] Confluent Freight Cluster:https://www.confluent.io/blog/introducing-confluent-cloud-freight-clusters/
[3] AutoMQ EBS WAL: https://docs.automq.com/docs/automq-opensource/HPuDwJ0NdiLJjlkuJb5cOd0unCc#ebs-wal
[4] AutoMQ S3 Express WAL:https://docs.automq.com/docs/automq-opensource/HPuDwJ0NdiLJjlkuJb5cOd0unCc#s3-express-wal
END
关于我们
我们是来自 Apache RocketMQ 和 Linux LVS 项目的核心团队,曾经见证并应对过消息队列基础设施在大型互联网公司和云计算公司的挑战。现在我们基于对象存储优先、存算分离、多云原生等技术理念,重新设计并实现了 Apache Kafka 和 Apache RocketMQ,带来高达 10 倍的成本优势和百倍的弹性效率提升。
🌟 GitHub 地址:https://github.com/AutoMQ/automq
💻 官网:https://www.automq.com

)




)






![[C++] 由C语言过渡到C++的敲门砖](http://pic.xiahunao.cn/[C++] 由C语言过渡到C++的敲门砖)
)




