如果您是一名开发者,正在寻找一种高效、灵活且易于使用的端侧AI开发框架,那么HarmonyOS SDKHiAI Foundation服务(HiAI Foundation Kit)就是您的理想选择。
作为一款AI开发框架,HiAI Foundation不仅提供强大的NPU计算能力和丰富的开发工具,还提供完善的技术支持和社区资源,帮助您快速构建高质量的AI应用程序。以图像分类这种常见的AI应用为例,使用HiAI Foundation可以帮助开发者们快速实现高效的图像分类应用。HiAI Foundation面向自定义AI算法的开发者们,可以灵活地支持自有的算法,给应用带来更好的性能功耗收益。
功能演示
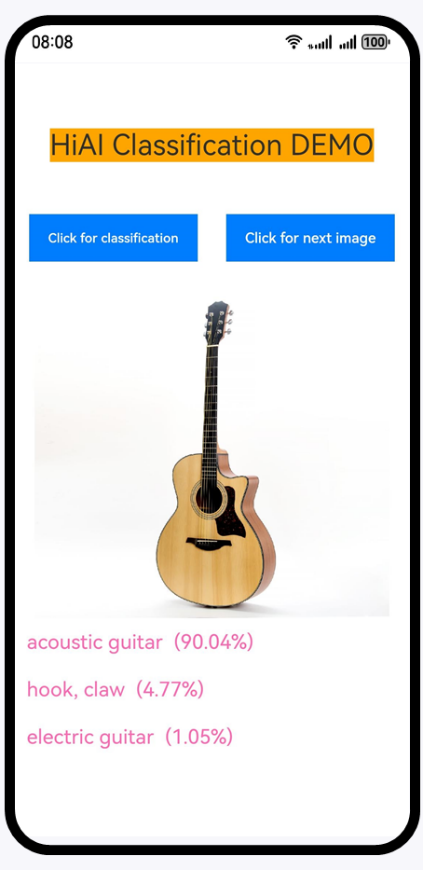
如果开发者对实现方式感兴趣,可以下载Demo体验,基于具体的应用场景优化。Demo支持加载离线模型,对图片中的物体进行分类。
图像分类开发步骤
1.创建项目
本章以Caffe SqueezeNet模型集成为例,说明App集成操作过程。
2.配置项目NAPI
编译HAP时,NAPI层的so需要编译依赖NDK中的libneural_network_core.so和libhiai_foundation.so。
3.头文件引用
按需引用头文件。
#include "neural_network_runtime/neural_network_core.h"
#include "hiai_foundation/hiai_options.h"
4.编写CMakeLists.txt
CMakeLists.txt中的关键代码如下:
include_directories(${HMOS_SDK_NATIVE}/sysroot/usr/lib)
FIND_LIBRARY(hiai_foundation-lib hiai_foundation)
add_library(entry SHARED Classification.cpp HIAIModelManager.cpp)
target_link_libraries(entry PUBLIC libace_napi.z.solibhilog_ndk.z.solibrawfile.z.so${hiai_foundation-lib}libneural_network_core.so)
5.集成模型
模型的加载、编译和推理主要是在native层实现,应用层主要作为数据传递和展示作用。
模型推理之前需要对输入数据进行预处理以匹配模型的输入,同样对于模型的输出也需要做处理获取自己期望的结果。另外SDK中提供了设置模型编译和运行时的配置接口,开发者可根据实际需求选择使用接口。
本节阐述同步模式下单模型的使用,从流程上分别阐述每个步骤在应用层和Native层的实现和调用,接口请参见API参考。
6.预置模型
为了让App运行时能够读取到模型文件和处理推理结果,需要先把离线模型和模型对应的结果标签文件预置到工程的"entry/src/main/resources/rawfile"目录中。
本示例所使用的离线模型转换和生成可参考Caffe模型转换,当前支持Caffe 1.0版本。
命令行中的参数说明请参见OMG参数,转换命令:
./omg --model xxx.prototxt --weight yyy.caffemodel --framework 0 --
output ./modelname
转换示例:
./omg --model deploy.prototxt --weight squeezenet_v1.1.caffemodel --framework
0 --output ./squeezenet
当看到OMG generate offline model success时,则说明转换成功,会在当前目录下生成squeezenet.om。
7.加载离线模型
在App应用创建时加载模型和读取结果标签文件。
1)调用NAPI层的"LoadModel"函数,读取模型的buffer。
2)把模型buffer传递给HIAIModelManager类的"HIAIModelManager::LoadModelFromBuffer"接口,该接口调用
OH_NNCompilation_ConstructWithOfflineModelBuffer创建模型的编译实例。
3)获取并设置模型的deviceID。
size_t deviceID = 0;
const size_t *allDevicesID = nullptr;
uint32_t deviceCount = 0;
OH_NN_ReturnCode ret = OH_NNDevice_GetAllDevicesID(&allDevicesID, &deviceCount);
if (ret != OH_NN_SUCCESS || allDevicesID == nullptr) {OH_LOG_ERROR(LOG_APP, "OH_NNDevice_GetAllDevicesID failed");return OH_NN_FAILED;
}
for (uint32_t i = 0; i < deviceCount; i++) {const char *name = nullptr;ret = OH_NNDevice_GetName(allDevicesID[i], &name);if (ret != OH_NN_SUCCESS || name == nullptr) {OH_LOG_ERROR(LOG_APP, "OH_NNDevice_GetName failed");return OH_NN_FAILED;}if (std::string(name) == "HIAI_F") {deviceID = allDevicesID[i];break;}
}
// modelData和modelSize为模型的内存地址和大小
OH_NNCompilation *compilation = OH_NNCompilation_ConstructWithOfflineModelBuffer(modelData, modelSize);
ret = OH_NNCompilation_SetDevice(compilation, deviceID);
if (ret != OH_NN_SUCCESS) {OH_LOG_ERROR(LOG_APP, "OH_NNCompilation_SetDevice failed");return OH_NN_FAILED;
}
4)调用OH_NNCompilation_Build,执行模型编译。
5)调用OH_NNExecutor_Construct,创建模型执行器。
6)调用OH_NNCompilation_Destroy,释放模型编译实例。
上述流程可参见Demo中"entry/src/main/cpp/Classification.cpp"文件中的"LoadModel"函数和"entry/src/main/cpp/HiAiModelManager.cpp"中的"HIAIModelManager::LoadModelFromBuffer"函数。
8.准备输入输出
1)准备输入输出
2)处理模型的输入,例如示例中模型的输入为13227*227格式Float类型的数据,需要把输入的图片转成该格式后传递到NAPI层。
3)创建模型的输入和输出Tensor,并把应用层传递的数据填充到输入的Tensor中。
// 创建输入数据
size_t inputCount = 0;
std::vector<NN_Tensor*> inputTensors;
OH_NN_ReturnCode ret = OH_NNExecutor_GetInputCount(executor, &inputCount);
if (ret != OH_NN_SUCCESS || inputCount != inputData.size()) { // inputData为开发者构造的输入数据OH_LOG_ERROR(LOG_APP, "OH_NNExecutor_GetInputCount failed, size mismatch");return OH_NN_FAILED;
}
for (size_t i = 0; i < inputCount; ++i) {NN_TensorDesc *tensorDesc = OH_NNExecutor_CreateInputTensorDesc(executor, i); NN_Tensor *tensor = OH_NNTensor_Create(deviceID, tensorDesc); // deviceID的获取方式可参考"加载离线模型"的步骤3if (tensor != nullptr) {inputTensors.push_back(tensor);}OH_NNTensorDesc_Destroy(&tensorDesc);
}
if (inputTensors.size() != inputCount) {OH_LOG_ERROR(LOG_APP, "input size mismatch");DestroyTensors(inputTensors); // DestroyTensors为释放tensor内存操作函数return OH_NN_FAILED;
}
// 初始化输入数据
for (size_t i = 0; i < inputTensors.size(); ++i) {void *data = OH_NNTensor_GetDataBuffer(inputTensors[i]);size_t dataSize = 0;OH_NNTensor_GetSize(inputTensors[i], &dataSize);if (data == nullptr || dataSize != inputData[i].size()) { // inputData为模型的输入数据OH_LOG_ERROR(LOG_APP, "invalid data or dataSize");return OH_NN_FAILED;}memcpy(data, inputData[i].data(), inputData[i].size()); // inputData为模型的输入数据
}
// 创建输出数据,与输入数据的创建方式类似
size_t outputCount = 0;
std::vector<NN_Tensor*> outputTensors;
ret = OH_NNExecutor_GetOutputCount(executor, &outputCount);
if (ret != OH_NN_SUCCESS) {OH_LOG_ERROR(LOG_APP, "OH_NNExecutor_GetOutputCount failed");DestroyTensors(inputTensors); // DestroyTensors为释放tensor内存操作函数return OH_NN_FAILED;
}
for (size_t i = 0; i < outputCount; i++) {NN_TensorDesc *tensorDesc = OH_NNExecutor_CreateOutputTensorDesc(executor, i); NN_Tensor *tensor = OH_NNTensor_Create(deviceID, tensorDesc); // deviceID的获取方式可参考"加载离线模型"的步骤3if (tensor != nullptr) {outputTensors.push_back(tensor);}OH_NNTensorDesc_Destroy(&tensorDesc);
}
if (outputTensors.size() != outputCount) {DestroyTensors(inputTensors); // DestroyTensors为释放tensor内存操作函数DestroyTensors(outputTensors); // DestroyTensors为释放tensor内存操作函数OH_LOG_ERROR(LOG_APP, "output size mismatch");return OH_NN_FAILED;
}
上述流程可参见Demo中"entry/src/main/cpp/Classification.cpp"文件中的"InitIOTensors"函数和"entry/src/main/cpp/HiAiModelManager.cpp"中的"HIAIModelManager::InitIOTensors"函数。
9.同步推理离线模型
调用OH_NNExecutor_RunSync,完成模型的同步推理。
可参见Demo中"entry/src/main/cpp/Classification.cpp"文件中的"RunModel"函数和"entry/src/main/cpp/HiAiModelManager.cpp"中的"HIAIModelManager::RunModel"函数。
说明:如果不更换模型,则首次编译加载完成后可多次推理,即一次编译加载,多次推理。
10.模型输出后处理
1)调用OH_NNTensor_GetDataBuffer,获取输出的Tensor,在输出Tensor中会得到模型的输出数据。
2)对输出数据进行相应的处理可得到期望的结果。
3)例如本示例demo中模型的输出是1000个label的概率,期望得到这1000个结果中概率最大的三个标签。
4)销毁实例。
调用OH_NNExecutor_Destroy,销毁创建的模型执行器实例。
调用OH_NNTensor_Destroy,销毁创建的输入输出Tensor。
上述流程可参见Demo中"entry/src/main/cpp/Classification.cpp"文件中的"GetResult"、“UnloadModel"函数和"entry/src/main/cpp/HiAiModelManager.cpp"中的"HIAIModelManager::GetResult”、"HIAIModelManager::UnloadModel"函数。
了解更多详情>>
访问HiAI Foundation服务联盟官网
获取HiAI Foundation服务开发指导文档


)



--- 变量和简单数据类型)







放大电路的图解分析方法和微变等效电路分析方法;)




