文章目录
- 基础概念
- 自动驾驶级别
- 再稍提一下ODD是什么?
- 自动驾驶仿真分类
- 软件在环仿真
- 硬件仿真
- 仿真究竟难在哪?
- 关于lidar和radar区别
- 一些名词解释
最近也是学习自动驾驶仿真相关知识,习惯去总结一下,方便自己回顾和总结,主要包括了自动驾驶框架和一些关于仿真方面的简单介绍,给想了解车企自动驾驶岗位的同学做一个初步普及,有写的不对的地方欢迎大佬前来指点orz
总的来说,仿真是自动驾驶方案的重点部分,无论是仿真开发还是仿真测试,都是为了实车相关部分的验证与落地。仿真开发的工作是为了去开发一套用于仿真测试的工具和算法。
QA仿真测试团队的使命是加速AD技术开发、测试验证与落地。在自动驾驶(AD)系统的开发流程中,仿真测试、模块测试与实车测试通过实施分层测试策略紧密协作,共同确保产品发布的质量和效率得以显著提升。为了实现这一目标,需要设计并构建了一套全面的仿真测试方案,包括丰富的测试场景集、科学的评价体系以及高效的自动化测试工具。
基础概念
自动驾驶级别
SAE是分为了L0~L5,根据不同程度,从零到完全自动化,共分为六个等级。
- L0级自动驾驶:
无自动,油门、刹车、方向盘全程皆由驾驶者掌控。 - L1级自动驾驶
主要还是由驾驶者操控车辆,但在特定的时候系统会介入,如ESP电子车身稳定系统或ABS防锁死刹车系统 - L2(部分自动驾驶)
部分自动化,驾驶者仍需专心于路况。第二级自动驾驶可说是目前各大车厂的主流,车辆的速度和转向可以在一定的条件下控制,但驾驶者仍需保持对路况的专注。 - L3(有条件自动驾驶)
相较于第二级,第三级自动驾驶可以在一定条件下驱动车辆,而不需要驾驶者专注于路况,双手甚至可以离开方向盘。但驾驶者仍需随时准备接管车辆。 - L4(高度自动驾驶)
高度自动化,车辆在启动自动驾驶后,计算机将在目的地设置后按自己的路线行驶,无需干预全面驾驶,但可能需要在特定区域(如高速公路或市区)进行干预。这一级别的自动驾驶技术仍处于研发阶段,市场上尚未有成熟的车型。 - L5(完全自动驾驶)
全自动化,第五级自动驾驶车辆将完全自动化,车上甚至不需要方向盘等驾驶机构,完全通过电脑感知与运算来驾驶车辆。不论任何环境、路况,都不需要人类驾驶介入操控。
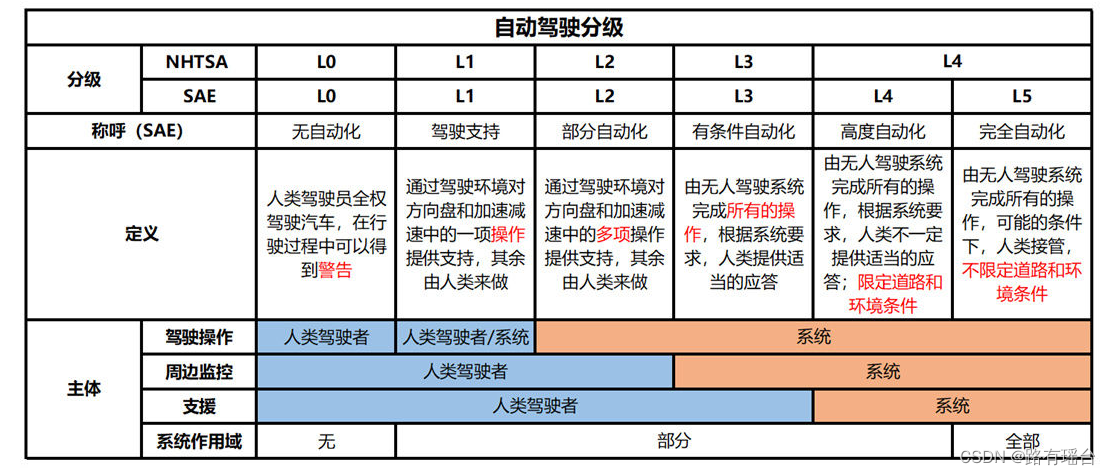
如上述,自动驾驶一直有两条路线,一条是L2->L4的渐进式路线,典型公司是特斯拉和多数车企,一条是直接L4路线,典型公司是谷歌旗下的Waymo以及国内的百度、小马等公司。
渐进式路线的思路是,做事要一步步来,每一步都要实现商业价值,支撑着技术的演进,否则很容易路子太长,走不到最后。而直接L4路线的公司则认为,渐进式路线为了提前商业化,需要做太多的“无用功”,绕太多的弯路,他们认为自动驾驶的成败不在于前边谁抢占了乘用车市场,而在于谁先能真正做到完全不需要人来开车,如果做到了这一点,就可以通过运营无人驾驶出租车的方式,靠低人力成本先抢占出租车市场,再进一步的,无人出租便宜又方便之后,它甚至可以挤压掉私家车的市场份额。
再稍提一下ODD是什么?
ODD的概念来自于SAE J3016中的定义,它将ODD定义为“特定驾驶自动化系统或其功能专门设计的运行条件。任何一台自动驾驶车辆,都必须有一定限定的工况。
ODD运行设计域(Operational Design Domain),代表了自动驾驶汽车的预期操作范围,包括交通状况、道路类型、天气等因素。定义涵盖了自动驾驶系统在设计时所确定的本车状态和外部环境,这些环境因素包括速度、道路、交通、天气、光照等。
简单来说,ODD就是要定义好在哪些工况下是能够自动驾驶的,脱离了这些工况,自动驾驶就不能保证工作。任何一台自动驾驶车辆,都必须有一定限定的工况。
ODD的范围越广,自动驾驶系统的适用性就越高,但在确定ODD时需要考虑各种复杂的因素,如不同的道路类型、交通情况、天气状况等,这些都会影响自动驾驶系统的表现。ODD是自动驾驶技术的重要组成部分,因为它决定了自动驾驶汽车在何种情况下可以安全地运行。在实际应用中,ODD的确定是非常困难的,因为自动驾驶系统需要在各种复杂环境中运行,确定ODD需要考虑各种可能情况。
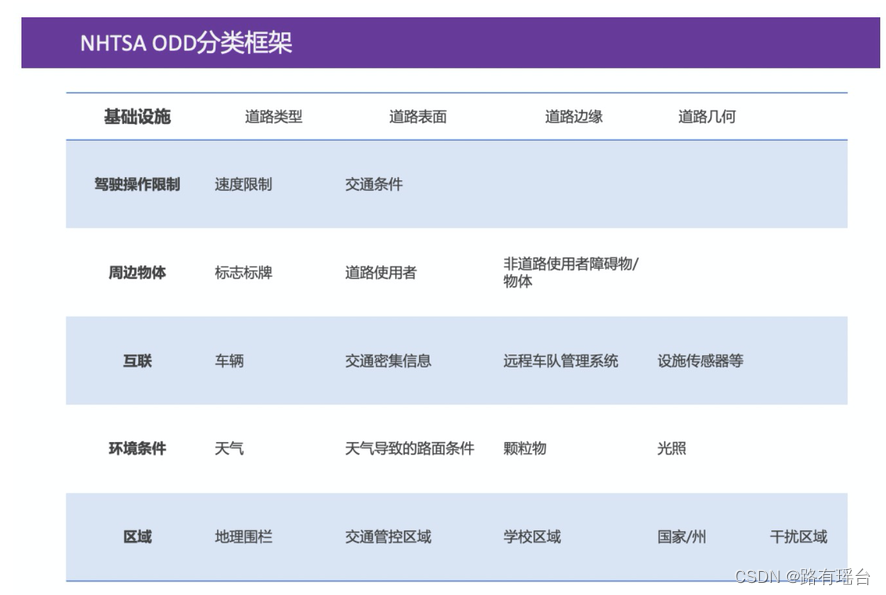
通过对于这六大要素的划分,可以较为清晰地定义出自动驾驶系统可以运行的工况及范围。
可以说,ODD的场景分类给予非L5级别的自动驾驶非常明确的场景定义以及测试标准,可以极大程度上保障驾驶员在使用这些自动驾驶功能时的安全性。根据不同场景的业务需求进行合理地ODD设计以及测试已经成为了所有自动驾驶企业们着重关注的目标。
ODD的划分标准与框架都有相关的标准可以清晰定义,那么在对ODD场景进行分类之后,如何去测试这些ODD的边界来判断现有的自动驾驶系统是否合格达标呢?
我们知道,自动驾驶汽车的开发满足V字开发模型,在V字开发模型中,涉及的测试方法主要包括软件在环(SIL,即software-in-loop)、硬件在环(HIL,即hardware-in-loop)、车辆在环(VIL,即vehicle-in-loop),再到最后的整车场地、道路测试等方法,涵盖了从零部件到系统再到整车的全链条验证。在测试内容方面,主要包括传感器、执行器、算法、人机界面测试以及整车功能等内容。
在环测试,借助虚拟现实数据生成、传输与交互技术,模拟自动驾驶汽车在真实道路环境行驶,并通过概率分布的危险场景强化模拟方法,进行的自适应加速测试。通过在环测试,可以在大幅节约测试时间和成本的同时,给虚拟测试提供了验证结果,并为实际道路测试提供了较为真实的参考数据。
传统来说自动驾驶几大核心团队,感知、PnC(规控)、地图、定位、仿真、系统。我主要在仿真团队,所以以下就以仿真展开了~
自动驾驶仿真分类
软件在环仿真
软件仿真有两种方法:WorldSim、LogSim.
场景完全虚拟(算法生成)的叫 WorldSim,将真实数据回放给算法看的叫LogSim,“但WorldSim中的路网也是在对来自真实道路的数据做自动标准的基础上生成的,因此,WorldSim与LogSim的界限越来越模糊”。
WorldSim:
- 完全虚拟与算法生成:WorldSim利用算法生成完全虚拟的测试场景,包括道路、交通参与者、天气条件等。这些场景可以根据需要进行定制,以覆盖各种极端和复杂的驾驶情况。
- 基于真实数据的路网:虽然场景本身是虚拟的,但WorldSim中的路网结构、交通规则等往往是在对真实道路数据进行自动化处理和标准化后生成的。这确保了仿真环境的真实性和有效性。
- 合成数据的优势:使用虚拟数据(合成数据)可以避免真实数据采集中的限制,如数据片段的有限性、危险事件发生的不可预测性等。合成数据可以按需生成,以覆盖各种可能的驾驶场景。
LogSim:
- 真实数据回放:LogSim利用从真实道路测试中收集的数据进行回放,这些数据包括传感器数据、车辆状态信息等。通过这种方式,测试工程师可以模拟真实道路条件下的驾驶场景,以验证自动驾驶系统的性能和可靠性。
- 数据片段的局限性:使用真实道路数据做回放时,能采集的片段是有限的。此外,由于数据采集的延迟和不确定性,可能无法完整记录某些危险事件的发生过程。
- 结合真实与虚拟:尽管LogSim主要依赖于真实数据,但它也可以与虚拟数据相结合,以补充或扩展测试场景。例如,在真实数据的基础上添加虚拟的交通参与者或变化的环境条件。
硬件仿真
硬件仿真也主要分为两种:HIL replay、HIL sim.
HIL Replay:
HIL Replay(也称为回放测试)是一种利用实际道路测试或模拟环境中收集的数据来模拟传感器输入的方法。这些数据通常包括来自各种传感器的原始信号,如摄像头、雷达、激光雷达(LiDAR)等。
在HIL Replay中,这些数据被记录下来,并按照传感器信号格式进行格式化,以便在HIL测试环境中重放。这种方式允许测试工程师在实验室环境中复现实际道路场景,而无需实际车辆和驾驶员的参与。
HIL Replay的优势在于能够精确地模拟实际道路条件,包括复杂的交通状况、天气变化等,从而帮助开发者发现和解决在实际道路测试中可能遇到的问题。
HIL Sim:
HIL Sim(硬件在环仿真)则更多地侧重于使用模拟软件或模型来与硬件进行交互。这些模拟软件或模型可以是基于物理的、基于数据的或混合的,用于模拟车辆的动力学、环境感知、决策制定等各个方面。
在HIL Sim中,测试工程师可以构建复杂的仿真场景,包括道路、交通参与者、障碍物等,并通过模拟软件生成相应的传感器数据和车辆状态信息。这些数据随后被发送到被测硬件(如控制器)进行处理,并产生相应的控制指令。
HIL Sim的优势在于其灵活性和可扩展性。测试工程师可以根据需要调整仿真场景和参数,以覆盖各种可能的测试情况。此外,HIL Sim还可以与其他仿真工具(如软件在环仿真、驾驶员在环仿真等)相结合,形成更全面的测试体系。
那么硬件和软件仿真最大的区别就是会不会涉及硬件的参与,即会不会与真实的物理设备产生交互。可以简单理解硬件和软件仿真都是分成两种,两者的区别就是一个是用真实数据回灌,一个是使用虚拟数据模拟出来的数据。
用真实交通流数据做仿真,称为“回灌”,
回灌又可分两种,直接回灌和模型回灌。大部分都是直接回灌。但是要注意的是即使是用真实数据做回灌还是会出现很多误差的,原因有很多,比如传感器信号的模拟、传输过程中的损耗和噪声以及延迟。
- 所谓“直接回灌”,是指对传感器数据不做处理直接喂给算法,在这种模式下,车辆及场景的参数是不可调整的,用某款车型采的数据,就只能用于同款车型的仿真测试;
- “模型回灌”,则是指先将场景数据抽象化、模型化,用一组数学公式将其表达出来,在这个数学公式里面,车辆及场景的参数都是可调的。
直接回灌是无需用到数学模型的,“比较简单,基本上,只要有大数据能力都能做到”,但在模型回灌方案中,不管是传感器模型还是车辆的行驶轨迹、车速,都是要通过数学公式来完成的。
模型回灌的技术门槛很高,成本也不低, 要把传感器录制的数据转换成仿真数据,数据解析的过程非常难。因此当前这一技术主要停留在PR层面上。在实践中,各家的仿真测试都是以算法生成的场景为主,以采自真实道路集的场景为补充。
模型回灌存在的最大挑战是:在场景比较复杂的情况下,要将场景用公式表达的难度极高,这个过程是可以通过自动化的方式来实现的,但最终做出来的场景能不能用也是个问题。
Waymo在2020年公布了的“通过将传感器收集到的数据直接生成逼真的图像信息来做仿真”的ChauffeurNet,其实就是在云端用神经网络将原始道路数据转换成数学模型,然后做模型回灌。但一位在硅谷多年的仿真专家说,这个还停留在试验阶段,距离成为真正的产品还有一段时间。
比回灌更有意义的是引入机器学习或强化学习。具体地说,仿真系统在充分学习各类交通参与者行为习惯的基础上训练出一些自己的逻辑,并将这些逻辑公式化,然后,在这些公式中调参。
而一个车企是否具备做模型回灌的能力,这主要取决于他们所使用的工具及场景管理能力。多数公司基于真实交通流的数据之所以不能调参,是因为他们没有做好场景管理。
“用算法直接生成场景,这在开发的早期当然是没问题的,但局限性也很明显——那些工程师们‘想不到’的场景怎么办?真实的交通状况千变万化,你的想象力不可能穷举所有。
“更关键的是,在工程师想象出的场景中,目标物之间的交互关系往往是不自然的。比如前方有车辆插入,它是以多大的角度插入?在距离你10米时还是5米时插入?在用算法生成场景的实践中,场景参数的制定往往带有非常的大主观性、随意性,工程师拍脑袋想出了一组参数注入模型,但这组参数是否具有代表性呢?”
某车载仿真负责人认为,自然驾驶数据做泛化目前还比较前瞻,但未来肯定会成为很重要的方向。可能未来用真实道路数据做仿真和用算法生成的数据做仿真这两种路线会相互渗透。
一方面,用算法生成场景,也依赖于工程师对真实道路场景的理解,对真实场景的理解越透彻,建模就越能接近真实。另一方面,用真实道路数据做场景,也需要对数据做切片、提取(将有效部分筛选出来),再设定参数、触发规则,再做精细化的分类,然后可以将它们逻辑化、公式化。
某仿真专家说:“真实场景数据转化为标准格式化数据后,可通过规则去进行赴泛化,从而产生更有价值的仿真场景。”
总结:两种路线相互渗透,界限越来越模糊
仿真究竟难在哪?
在跟很多仿真公司的专家及其下游用户交流的过程中,我们了解到当下自动驾驶的仿真,最难的环节之一是传感器的建模。
传感器建模可分为功能信息级建模、现象信息级/统计信息级建模及全物理级建模几个级别。
这几个概念的区别如下——
- 功能信息级建模,简单地描述摄像头输出图像、毫米波雷达在某个范围内探测目标这些具体功能,主要目的在于测试验证感知算法,但对传感器本身的性能并不关注;
- 现象信息和统计信息级建模是混合的、中间层级的建模,它包括一部分功能信息级建模,也包括一部分物理级建模;
- 全物理级建模,指对传感器工作的整个物理链路做仿真,其目标在于测试传感器本身的物理性能,比如,毫米波雷达的滤波能力如何。
狭义上的的传感器建模拟特指全物理级的建模。这种建模,很少有公司能做好,具体原因如下:
1.图像渲染的效率不够
从计算机图形成像原理看,传感器模拟包括光线(输入、输出模拟)、几何形状、材质模拟、图像渲染等模拟,而渲染能力和效率的差别则会影响到仿真的真实性。
2.传感器的类型太多&模型精度、效率和通用性的“不可能三角”
仅有单个传感器的精度高还不够,你还需要所有的传感器都能同时达到一个理想的状态,这就要求建模有很广的覆盖度,但在成本压力下,仿真团队显然不可能对激光雷达做10个、20个版本的建模吧? 另一方面,又很难用一个通用的模型去将各种不同款式的传感器表达出来。
模型的精度、效率和通用性是一个“不可能三角”的关系,你可以去提升其中的一面或者两个角两面,但你很难去持续性地把三个维度同时提升。当效率足够高的时候,模型精度一定是下降的。
“再复杂的数学模型也可能只能以99%的相似度模拟真实传感器,而这剩下的1%可能就是会带来致命问题的因素。”
3.传感器建模受制于目标物的参数
传感器仿真需要外部的数据,即外部环境数据跟传感器有强耦合,然而外部环境的建模其实也挺复杂的,并且成本也不低。
- 数量多:城市场景下建筑物的数量太多,这会严重消耗用来做图像渲染的计算资源。
- 遮挡物:有的建筑物会遮挡路上的车流、行人及其他目标物体,而有遮挡没遮挡,计算量是完全不一样的。
- 反射率和材质:目标物的反射率、材质,很难通过传感器建模搞清楚。比如,可以说一个目标是个桶状的,但它究竟是铁桶还是塑料桶,这个很难通过建模来表达清楚;即使能表达清楚,要在仿真模型中把这些参数调好,又是一个超级大的工程。
而目标物的材质等物理信息不清楚的话,仿真的模拟器就难以选择。
4.传感器的噪声加多少很难确定
仿真工程师面临的主要挑战在于如何平衡仿真信号的逼真度与泛化能力。一方面,仿真生成的传感器信号需要足够接近真实世界的数据,以便深度学习模型能够准确识别出对应物体;另一方面,又不能过于依赖特定场景的细节,而是要加入适当的噪声和复杂因素,以提升模型在更广泛场景下的识别能力(即泛化能力)。
具体到传感器建模,相机和激光雷达是两种常见的传感器类型,它们的建模过程各具特色。
- 相机建模不仅涉及生成理想的图像模型,还需要进行一系列后处理来模拟真实世界中的相机特性,如模糊化、畸变、暗角、颜色转换和鱼眼效果等。这些处理旨在使仿真图像更加贴近实际拍摄效果。
- 激光雷达的建模则更加复杂,需要构建包括理想点云模型、功率衰减模型和考虑天气噪点的物理模型在内的多层次模型。理想点云模型关注于场景的基本几何信息,而功率衰减模型则深入考虑了激光在传输过程中的各种衰减因素,如反射、散射、大气和光学传输系数等。此外,为了更全面地模拟真实环境,还需要在模型中加入天气噪点等随机因素。
5.资源的限制
- 工程量巨大:我们要对传感器做完全的物理级建模,比如摄像头的光学物理参数等都要清楚,还需要知道目标物(感知对象)的材质、反射率等数据,在有足够人力的情况下,一公里场景的建设周期需要差不多1个月。
- 模型复杂度问题:
- 物理机仿真难度:即使真能建好,模型的复杂度也极高,很难在当前的物理机上跑起来
- 云端仿真难度:未来仿真都是要上云的,虽然云端的算力‘无穷无尽’,但具体分摊到某个单一节点的单一模型上,云端的计算能力可能还不如物理机——并且,在物理机上做仿真时,如果一台机器的计算资源不够,可以上三台,一台负责传感器模型,一台负责动力学,一台负责规控,但在云上跑仿真, 能用在单一场景单一模型上的算力并不是无穷无尽的,那么这个就限制了我们这个模型的复杂度。
6.仿真公司很难拿到传感器的底层数据
-
仿真公司不了解底层机制:传感器内部的感知算法往往被视为黑盒子,仿真公司难以了解其内部机制,这增加了建模的难度。同时,为了进行精确的全物理建模,需要获取传感器元器件的底层参数和物理原理的深入理解,这通常超出了仿真公司的能力范围,因为这些参数和原理往往由传感器厂商掌握且不愿开放。
-
传感器厂商不愿透露:传感器厂商出于技术保护和商业竞争的考虑,通常不愿意向外界提供详细的底层数据,包括材质物理参数等。这使得仿真公司在没有足够数据支持的情况下,难以进行高精度的传感器建模。
-
物理级仿真技术有限:目前能够进行传感器物理级仿真的主要是传感器厂商自身或上游供应商,如TI、恩智浦等,它们具备设计和生产传感器的技术实力和数据支持。对于国内许多传感器厂商来说,由于更多地依赖外采芯片等零部件进行集成,其进行物理级仿真的能力相对有限。
-
传感器的仿真难做也导致了传感器选型过程的复杂性。在实际应用中,为了选择合适的传感器,通常需要传感器公司提供样件并进行实车测试。如果传感器厂商和仿真公司能够合作,提供精准的传感器建模,将有助于降低选型成本并减少工作量。然而,由于各种因素限制,这种合作在实际操作中仍面临诸多挑战。
关于lidar和radar区别
使用技术:
- lidar激光雷达,用激光束,具有高分辨率和精度,更贵
- radar雷达,用电磁波,远距离侦测和距离测量,便宜一点
与什么结合:
- lidar通常与GPS和IMU(惯性测量设备)结合,高准确度定位物体。
- radar虽然也可能与其他技术结合使用,但并非其核心组成部分。
检测方面:
- lidar会存在人工无法标注远处(300m)过于稀疏点的问题
- radar只能拿到检测结果,没有原始点云。
端到端评测和感知评测两者区别:
企业更多还是依靠端到端测试,感知评测占少部分。
个人理解:端到端测试就是明确测试范围和具体界定指标。
感知评测是基于直觉认知和模糊数学计算进行的一种测评方式。
关于仿真数据量大上传出现的问题,解决方案:
主要的耗时不在上传而在压缩,短数据的并行量可以上去。
优化:
非必要不上传(不需要图像信息的时候,只上传时序信息)本地校验
一些名词解释
包括了一些我刚入门的一些问题和别人的回答。
台架是什么?
答:台架是一整套 ,包括服务器、设备(智驾域控制器MAZU)、传感器(IO设备)。单台架的成本是非常高的,以M为级别。
硬件仿真平台和软件仿真平台有什么区别,平台主要是在做什么?
答:硬件仿真具有物理性能,软件具有数学模型,目前主要是通过模拟信号。
自动驾驶仿真的框架和核心是什么?
答:框架:车辆物理模拟 信号模拟 分析计算
核心:渲染引擎 计算引擎
这几种传输给智能辅助驾驶域控制器的数据格式(video、can、eth、mipi)互相之间有什么联系
答:实车是这些,就是模拟实车
video就是接收到的图像,而can主要是包括五大控制域的信息,eth包括的是车载娱乐方面(视频之类)。
车载以太网采用星型或树型拓扑结构,通过网关或交换机连接各个节点。这使得网络扩展和升级相对容易,但也可能增加系统的复杂性和成本。CAN/CAN FD采用总线型拓扑结构,所有节点都连接在同一条总线上。这种结构简单可靠,但扩展性较差。同时,CAN/CAN FD具有良好的兼容性,能够与传统CAN网络无缝集成。
实现闭环和半闭环是什么意思?
答:大白话:闭环指所有都测一遍,从模型 算法 硬件 数据回溯。半闭环值的是但一某一模块的功能。
“所谓的‘没法实现闭环’也是相对的,已经有供应商可以把采集到的场景里面的元素都完成参数化,这样就可以闭环了,但这种设备的价格是非常昂贵的。”
测试的应用场景有什么?
答:集成测试、功能测试、性能测试、故障注入测试
场景库是什么,在仿真平台里起到camera的作用吗 ?
答:别的做的厉害的(比如特斯拉)可以起到camera的作用,场景库就是可以当作一个静态地图,在仿真平台上再加入动态元素(车辆和人)
数据脱敏是指什么?
答:把自动驾驶产生的数据其中的敏感元素进行抹除 替换 比如高精度地图转换,比如摄像头拍摄的车牌号 脸 车控数据要打码或者数据替换
台架上的板卡是干什么的?
答:为了通信的,实现信号采集、转换、处理。
大部分车企没有自己对于自动驾驶的平台方案,平台方案指的就是一个综合性的系统架构,旨在实现车辆的自主驾驶功能。可以大致分为软件、硬件、算法。这些部分协同工作以确保车辆能够安全、高效地行驶。目前,自动驾驶领域存在多种主流平台方案,如特斯拉的Autopilot、华为的ADS、百度的Apollo等。这些平台方案在感知系统、决策与规划系统、控制系统以及车载计算平台等方面各有特色,但都致力于实现车辆的自主驾驶功能。
和reactive())





)

)



+单总线协议)
 + Springboot集成kafka)





:Psutil库实现系统和硬件监控工具)