
目录
编辑一、延迟队列概念
二、延迟队列使用场景
三、整合 SpringBoot
1、创建项目
2、添加依赖
3、修改配置文件
4、添加 Swagger 配置类
四、队列 TTL
1、代码架构图
2、配置文件代码类
3、生产者
4、消费者
5、结果展示
五、延时队列优化
1、代码架构图
2、配置文件
3、生产者编辑
4、结果展示
六、RabbitMQ 插件实现延迟队列
1、安装延时队列插件
2、代码架构图
3、配置文件类代码
4、生产者
5、消费者
6、结果展示
一、延迟队列概念
二、延迟队列使用场景
1.订单在十分钟之内未支付则自动取消
2.新创建的店铺,如果在十天内都没有上传过商品,则自动发送消息提醒。
3.用户注册成功后,如果三天内没有登陆则进行短信提醒。
4.用户发起退款,如果三天内没有得到处理则通知相关运营人员。
5.预定会议后,需要在预定的时间点前十分钟通知各个与会人员参加会议
这些场景都有一个特点,需要在某个事件发生之后或者之前的指定时间点完成某一项任务,如:
发生订单生成事件,在十分钟之后检查该订单支付状态,然后将未支付的订单进行关闭;看起来似乎使用定时任务,一直轮询数据,每秒查一次,取出需要被处理的数据,然后处理不就完事了吗?
如果数据量比较少,确实可以这样做,比如:对于“如果账单一周内未支付则进行自动结算”这样的需求,如果对于时间不是严格限制,而是宽松意义上的一周,那么每天晚上跑个定时任务检查一下所有未支付的账单,确实也是一个可行的方案。
但对于数据量比较大,并且时效性较强的场景,如:“订单十分钟内未支付则关闭“,短期内未支付的订单数据可能会有很多,活动期间甚至会达到百万甚至千万级别,对这么庞大的数据量仍旧使用轮询的方式显然是不可取的,很可能在一秒内无法完成所有订单的检查,同时会给数据库带来很大压力,无法满足业务要求而且性能低下。
三、整合 SpringBoot
1、创建项目
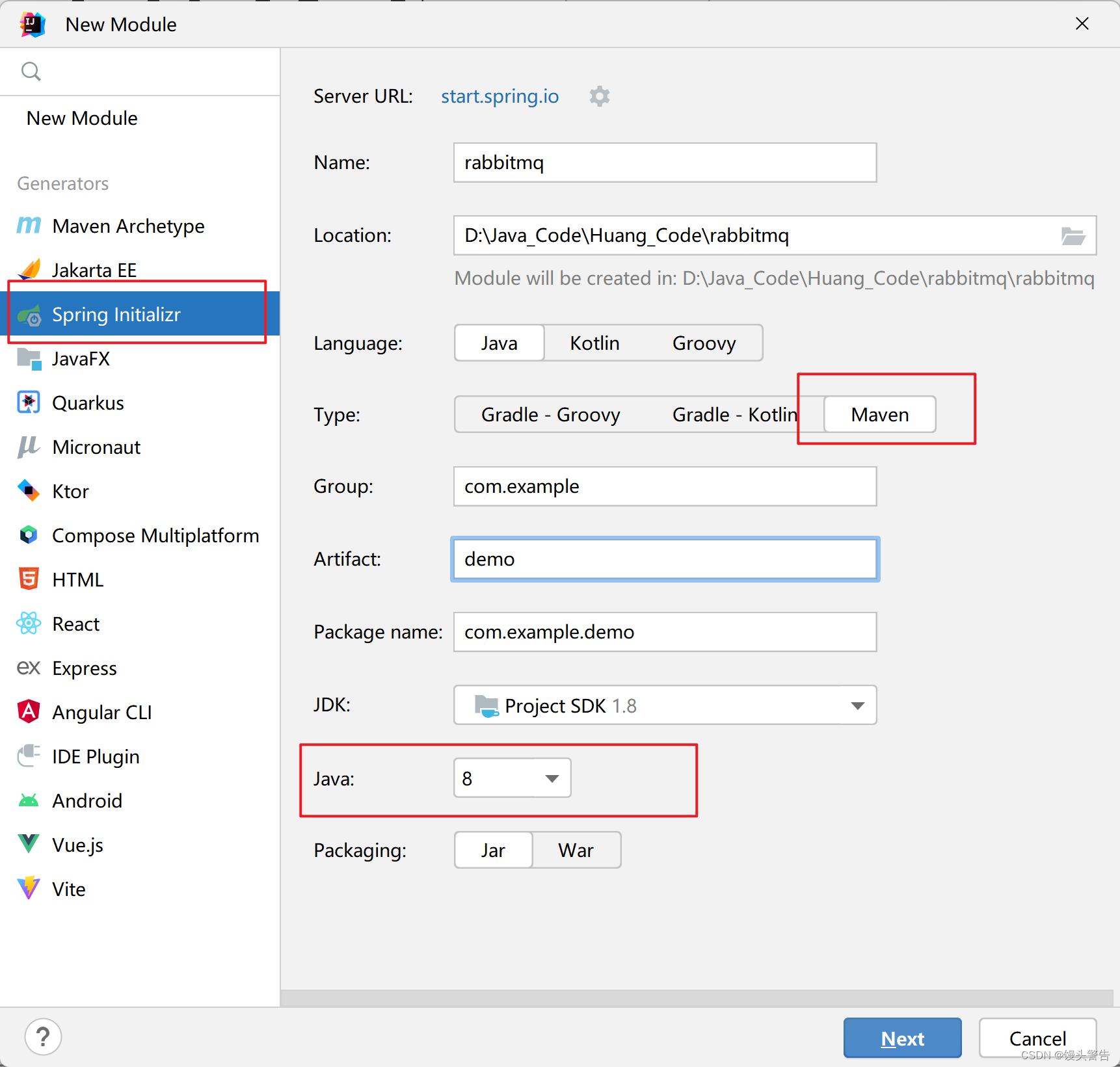
2、添加依赖
<dependencies><!--RabbitMQ 依赖--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-amqp</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.47</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency><!--swagger--><dependency><groupId>io.springfox</groupId><artifactId>springfox-swagger2</artifactId><version>2.9.2</version></dependency><dependency><groupId>io.springfox</groupId><artifactId>springfox-swagger-ui</artifactId><version>2.9.2</version></dependency><!--RabbitMQ 测试依赖--><dependency><groupId>org.springframework.amqp</groupId><artifactId>spring-rabbit-test</artifactId><scope>test</scope></dependency>
</dependencies>3、修改配置文件
spring.rabbitmq.host=111.229.153.16
spring.rabbitmq.port=5672
spring.rabbitmq.username=admin
spring.rabbitmq.password=123
spring.mvc.pathmatch.matching-strategy=ant_path_matcher
4、添加 Swagger 配置类
@Configuration
@EnableSwagger2
public class SwaggerConfig {@Beanpublic Docket webApiConfig(){return new Docket(DocumentationType.SWAGGER_2).groupName("webApi").apiInfo(webApiInfo()).select().build();}private ApiInfo webApiInfo(){return new ApiInfoBuilder().title("rabbitmq 接口文档").description("本文档描述了 rabbitmq 微服务接口定义").version("1.0").contact(new Contact("馒头警告", "www.baidu.com","2714858327@qq.com")).build();}
}四、队列 TTL
1、代码架构图
创建两个队列 QA 和 QB,两者队列 TTL 分别设置为 10S 和 40S,然后在创建一个交换机 X 和死信交换机 Y,它们的类型都是 direct,创建一个死信队列 QD,它们的绑定关系如下:

2、配置文件代码类
// TTL 队列,配置文件类代码
@Configuration
public class TTLQueueConfig {// 普通交换机的名称public static final String X_EXCHANGE = "X";// 死信交换机名称public static final String Y_DEAD_LETTER_EXCHANGE = "Y";// 普通队列名称public static final String QUEUE_A = "QA";public static final String QUEUE_B = "QB";// 死信队列名称public static final String DEAD_LETTER_QUEUE_D = "QD";// 声明 X 交换机@Bean(value = "xExchange") // 相当于别名public DirectExchange xExchange(){return new DirectExchange(X_EXCHANGE);}// 声明 Y 交换机@Bean(value = "yExchange") // 相当于别名public DirectExchange yExchange(){return new DirectExchange(Y_DEAD_LETTER_EXCHANGE);}// 声明普通队列 TTL 为 10s@Bean(value = "queueA") // 相当于别名public Queue queueA(){Map<String, Object> arguments = new HashMap<>(3);// 设置死信交换机arguments.put("x-dead-letter-exchange",Y_DEAD_LETTER_EXCHANGE);// 设置死信 RoutingKeyarguments.put("x-dead-letter-routing-key","YD");// 设置 TTLarguments.put("x-message-ttl",10000);return QueueBuilder.durable(QUEUE_A).withArguments(arguments).build();}// 声明普通队列 TTL 为 10s@Bean(value = "queueB") // 相当于别名public Queue queueB(){Map<String, Object> arguments = new HashMap<>(3);// 设置死信交换机arguments.put("x-dead-letter-exchange",Y_DEAD_LETTER_EXCHANGE);// 设置死信 RoutingKeyarguments.put("x-dead-letter-routing-key","YD");// 设置 TTLarguments.put("x-message-ttl",40000);return QueueBuilder.durable(QUEUE_B).withArguments(arguments).build();}// 声明死信队列@Bean(value = "queueD")public Queue queueD(){return QueueBuilder.durable(DEAD_LETTER_QUEUE_D).build();}// 绑定@Beanpublic Binding queueABindingX(@Qualifier("queueA") Queue queueA ,@Qualifier("xExchange") DirectExchange xExchange){return BindingBuilder.bind(queueA).to(xExchange).with("XA");}// 绑定@Beanpublic Binding queueBBindingX(@Qualifier("queueB") Queue queueB ,@Qualifier("xExchange") DirectExchange xExchange) {return BindingBuilder.bind(queueB).to(xExchange).with("XB");}// 绑定@Beanpublic Binding queueDBindingY(@Qualifier("queueD") Queue queueD ,@Qualifier("yExchange") DirectExchange yExchange){return BindingBuilder.bind(queueD).to(yExchange).with("YD");}}
3、生产者
// 发送延迟消息
@Slf4j
@Configuration
@RequestMapping("/ttl")
public class SendMessageController {@Autowiredprivate RabbitTemplate rabbitTemplate;// 开始发消息@GetMapping("/sendmsg/{message}")public void sendMsg(@PathVariable String message){log.info("当前时间:{},发送一条信息给两个 TTL 队列:{}", new Date().toString(),message);rabbitTemplate.convertAndSend("X","XA","消息来自 TTL 为 10s 的队列" + message);rabbitTemplate.convertAndSend("X","XB","消息来自 TTL 为 40s 的队列" + message);}
}4、消费者
// 队列 TTL
@Slf4j
@Component
public class DeadLetterQueueConsumer {// 接收消息@RabbitListener(queues = "QD")public void receiveD(Message message, Channel channel){String msg = new String(message.getBody());log.info("当前时间:{},收到死信队列的消息:{}",new Date().toString(),msg);}
}5、结果展示

五、延时队列优化
第一条消息在 10S 后变成了死信消息,然后被消费者消费掉,第二条消息在 40S 之后变成了死信消息,然后被消费掉,这样一个延时队列就打造完成了。
不过,如果这样使用的话,岂不是每增加一个新的时间需求,就要新增一个队列,这里只有 10S 和 40S两个时间选项,如果需要一个小时后处理,那么就需要增加 TTL 为一个小时的队列,如果是预定会议室然后提前通知这样的场景,岂不是要增加无数个队列才能满足需求?
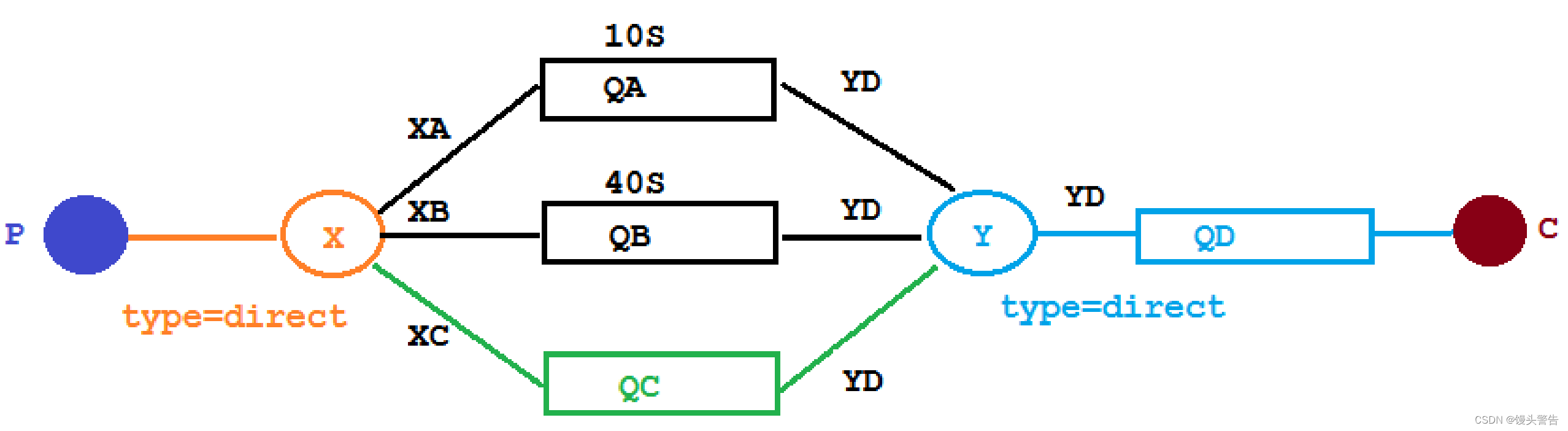
1、代码架构图
在这里新增了一个队列 QC,绑定关系如下,该队列不设置 TTL 时间
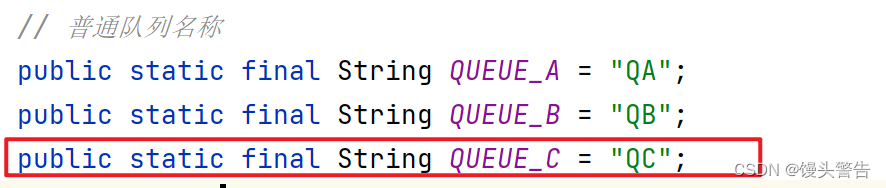
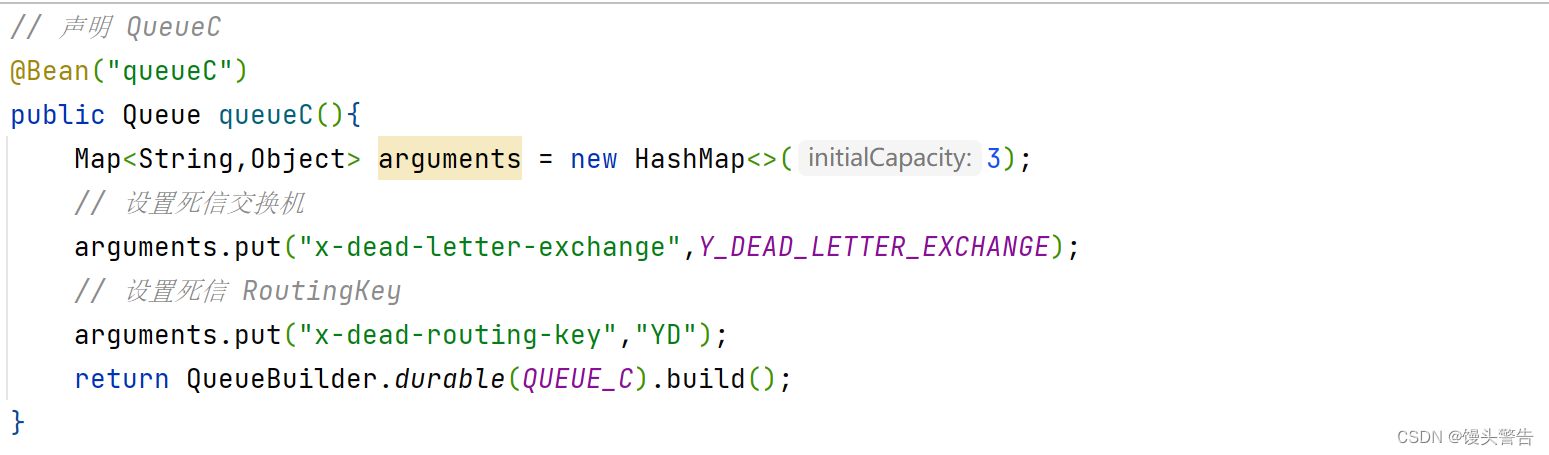
2、配置文件

3、生产者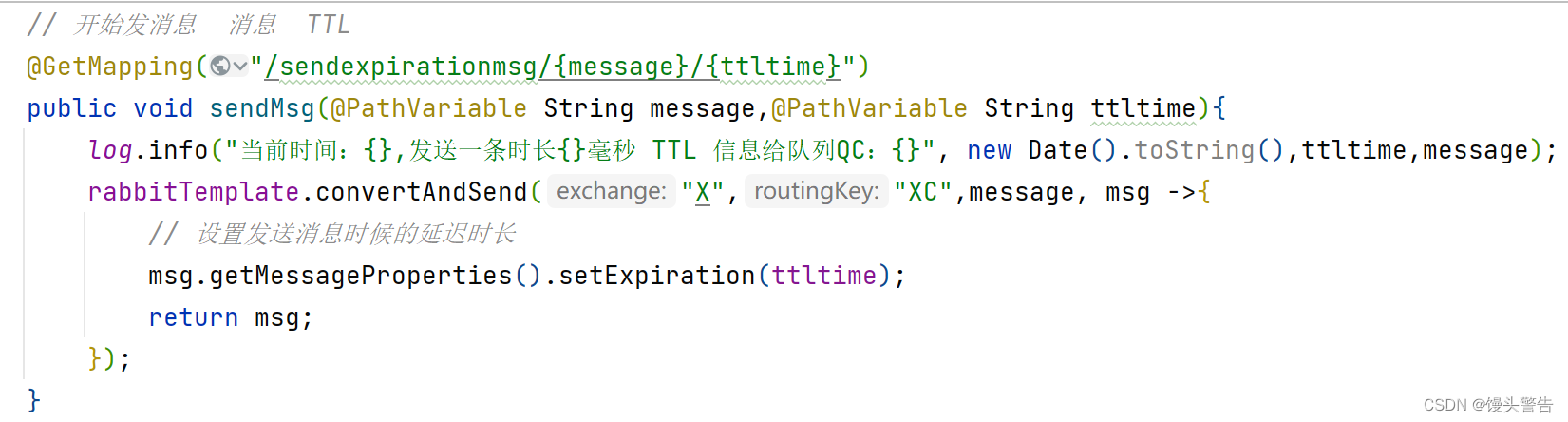
4、结果展示

看起来似乎没什么问题,但是在最开始的时候,就介绍过如果使用在消息属性上设置 TTL 的方式,消息可能并不会按时“死亡“
因为 RabbitMQ 只会检查第一个消息是否过期,如果过期则丢到死信队列,如果第一个消息的延时时长很长,而第二个消息的延时时长很短,第二个消息并不会优先得到执行。
六、RabbitMQ 插件实现延迟队列
1、安装延时队列插件
大家可以参考网上的教程自行去下载安装,这里就不再进行描述了
如果安装好了,就会有一个叫做 x-delayed-message 的类型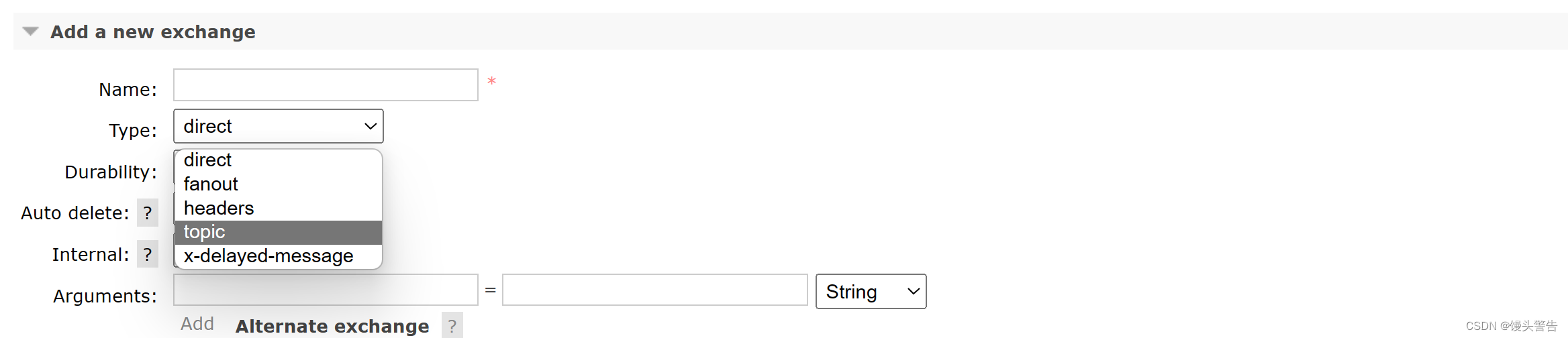
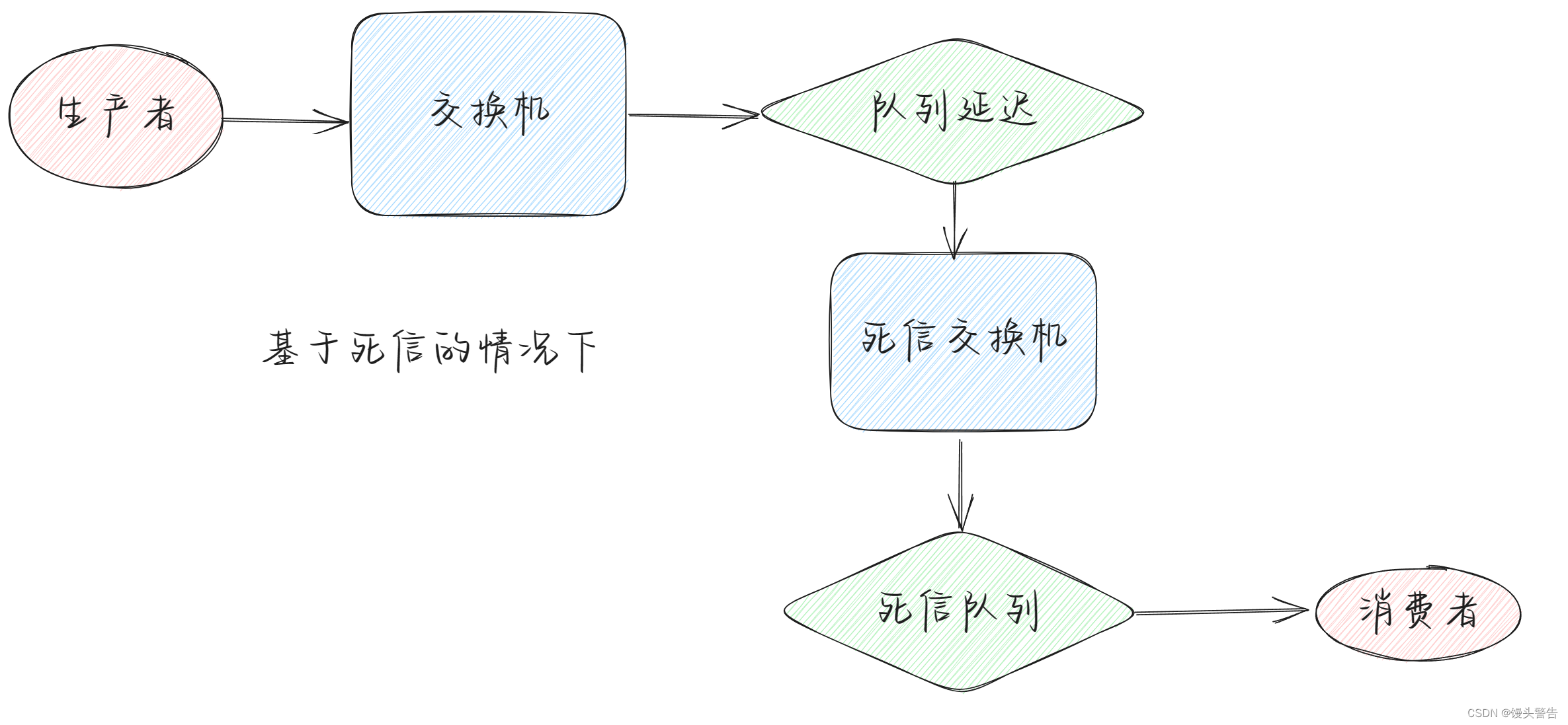
一旦装完插件之后,消息延迟的位置就换到交换机了,相当于生产者发消息,这个消息停留在交换机这个位置,再将消息发给队列

2、代码架构图
在这里新增了一个队列 delayed.queue,一个自定义交换机 delayed.exchange,绑定关系如下:

一个生产者,要走延迟的交换机,延迟的交换机根据 RoutingKey ,路由到延迟的队列,而延迟的位置是在交换机的位置,队列被消费者所消费
3、配置文件类代码
在我们自定义的交换机中,这是一种新的交换类型,该类型消息支持延迟投递机制 消息传递后并
不会立即投递到目标队列中,而是存储在 mnesia(一个分布式数据系统)表中,当达到投递时间时,才投递到目标队列中。
@Configuration
public class DelayedQueueConfig {// 交换机public static final String DELAYED_EXCHANGE_NAME = "delayed.exchange";// 队列public static final String DELAYED_QUEUE_NAME = "delayed.queue";// RoutingKeypublic static final String DELAYED_ROUTING_KEY = "delayed.routingkey";// 声明交换机 基于插件的@Beanpublic CustomExchange delayedExchange(){Map<String, Object> arguments = new HashMap<>();arguments.put("x-delayed-type","direct");return new CustomExchange(DELAYED_EXCHANGE_NAME,"x-delayed-message",true,false,arguments);}// 声明队列@Beanpublic Queue delayedQueue(){return new Queue(DELAYED_QUEUE_NAME);}// 绑定@Beanpublic Binding delayedQueueBindingDelayedExchange(@Qualifier("delayedQueue") Queue delayedQueue,@Qualifier("delayedExchange")CustomExchange delayedExchange){return BindingBuilder.bind(delayedQueue).to(delayedExchange).with(DELAYED_ROUTING_KEY).noargs();}
}4、生产者
// 开始发消息 基于插件的 消息及延迟的时间@GetMapping("/senddelaymsg/{message}/{delaytime}")public void sendMsg(@PathVariable String message,@PathVariable Integer delaytime){log.info("当前时间:{},发送一条时长{}毫秒信息给延迟队列delayed.queue:{}",new Date().toString(),delaytime,message);rabbitTemplate.convertAndSend("delayed.exchange","delayed.routingkey",message, msg ->{// 设置发送消息时候的延迟时长msg.getMessageProperties().setDelay(delaytime);return msg;});}5、消费者
// 消费者 基于插件的延迟消息
@Slf4j
@Component
public class DelayQueueConsumer {// 监听消息@RabbitListener(queues = DelayedQueueConfig.DELAYED_QUEUE_NAME)public void receiverDelayQueue(Message message){String msg = new String(message.getBody());log.info("当前时间:{},收到延迟队列的消息:{}",new Date().toString(),msg);}
}6、结果展示





拓扑球与拓扑环面与同胚)
:JVM虚拟机工具之可视化故障处理工具)




)






)

