看了不少关于MQ的文章,也对MQ的作用做了一些总结。通常来说MQ有三大功能:异步处理、系统解耦和流量削峰。但我觉得这些功能本质上都是围绕着异步这个核心来的,只是针对不同的业务场景做了些调整。
现在市面上常用的MQ中间件,如RabbitMQ、RocketMQ和Kafka,都是大家耳熟能详的。最近,Apache基金会推出的Pulsar也挺火的,口碑不错,只还差一些大项目实战来检验它。
如今,MQ在现在的项目里基本是标配了。这篇文章主要是梳理一下自己所在项目中是怎么用MQ的,复盘一下使用MQ的场景。
这里接上篇,此篇主要梳理的是支付订单的业务场景。
支付订单
1、场景描述
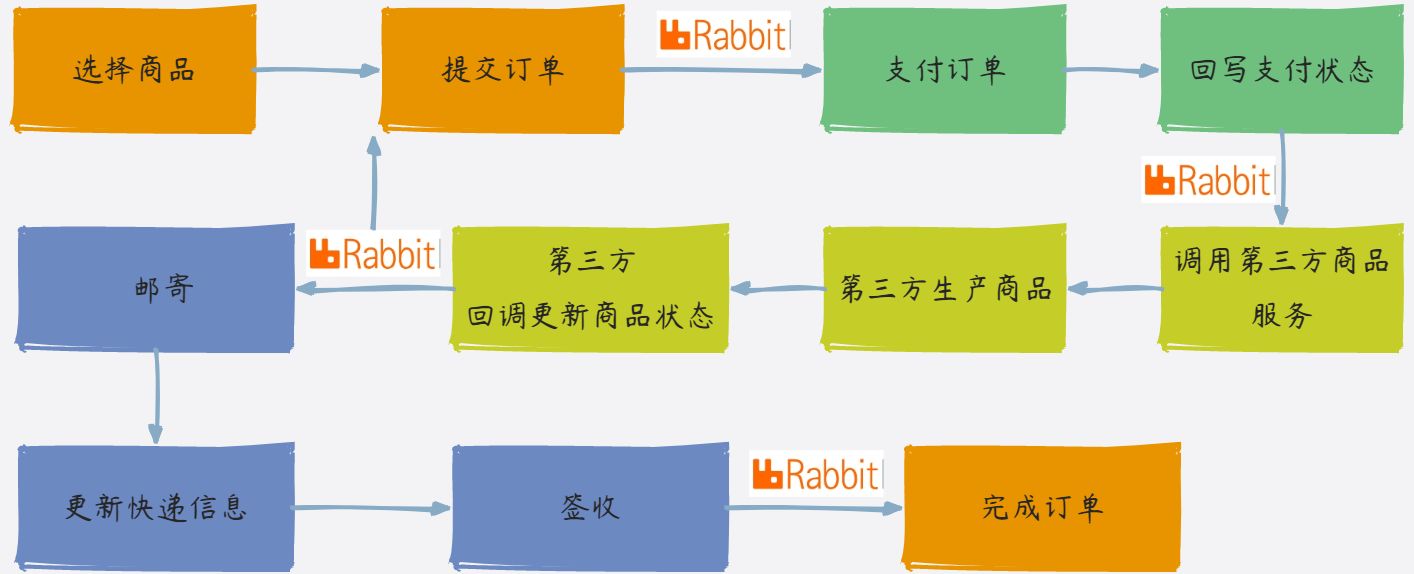
业务流程比较长, 和一般的订单业务有点不太一样的地方就是商品是由第三方系统制作的。
2、实现分解
业务分解
- 用户选择自己需要的商品及年限
- 系统根据用户选择,自动计算出价格及相关的信息展示给用户
- 用户确认后,提交订单,订单服务收到订单后存储在DB同时,给Rabbitmq发送支付任务。如果DB保存成功,MQ失败则重试,重试失败则转人工。
- 支付中心监听到支付消息,向第三方支付平台发起支付请求,第三方支付平台返回支付二维码
- 如果支付未完成或支付失败或不小心关闭支付页面,用户重新进入后可以重新扫码支付
- 用户扫码支付成功后,第三方支付平台异步通知支付结果,一般通知失败有多次重新通知的机制。比如支付宝:
在进行异步通知交互时,如果支付宝收到的应答不是 success,支付宝会认为通知失败,会通过一定的策略定期重新发起通知。重试逻辑为:当未收到success 时立即尝试重发 3 次通知,若 3 次仍不成功,则后续通知的间隔频率为:4m、10m、10m、1h、2h、6h、15h。
当然有可能回调服务异常,调用方也可以去支付平台反查支付结果。
- 支付中心支付完成后,会向rabbitmq发送完成消息
- 商品服务收到消息后会向第三方发起调用商品生产的服务,生产完成后向rabbitmq发送商品制作完成消息
- 物流服务收到消息后调用第三方物流接口发起快递(之前下单用户已经填写物流信息),物流完成后,MQ通知订单服务。
- 订单服务收到后更新订单状态,完成订单。
优势分析
在此业务场景中,使用消息队列(RabbitMQ)具有以下优势和必要性:
- 解耦:RabbitMQ允许系统间的松耦合,例如,如果订单系统需要通知支付和物流服务,通过MQ,订单系统只需将消息发送到队列,而不必直接与其他系统通信。这样,即使业务流程发生变化,也不需要修改订单系统的代码。
- 异步处理:RabbitMQ支持异步通信,允许系统在处理长时间运行的任务时不阻塞用户请求。例如,用户下单后,订单系统可以立即响应,而支付和流程操作可以在后台异步进行。
- 削峰填谷:在高流量时段,RabbitMQ可以作为缓冲,接收突发的大量请求,然后慢慢地处理这些请求,避免直接压力过大导致系统崩溃。
- 可靠性和持久化:RabbitMQ可以保证消息的可靠传递,即使处理系统暂时不可用,消息也可以存储在队列中,待系统恢复后再进行处理。 MQ应答、持久化等机制可以保证整个业务的最终一致性。
3、小结
此业务场景选择RabbitMQ而非继续沿用之前搭建的Kafka,主要是基于对系统需求的深入分析。Kafka作为一款高性能的消息队列系统,其设计初衷是为了处理大规模数据流的高吞吐量场景。尽管Kafka同样具备低延迟和确保消息不丢失的特性,但在当前项目中,我们面临的是消息量相对较小,却对消息处理的实时性有较高要求的场景。
RabbitMQ,以其卓越的灵活性和低延迟特性,在此类场景下表现得更为出色。它能够提供毫秒级的消息传递延迟,并且通过其丰富的路由策略和消息确认机制,确保了消息传递的可靠性和准确性。因此,在综合考虑了系统的实际需求和两款消息队列产品的特性后,我们最终决定采用RabbitMQ来满足项目对低延迟和高可靠性的双重需求。
在下图可以看到低吞吐量的情况下,rabbitmq的延迟是最低的,对于延迟是越低越好。
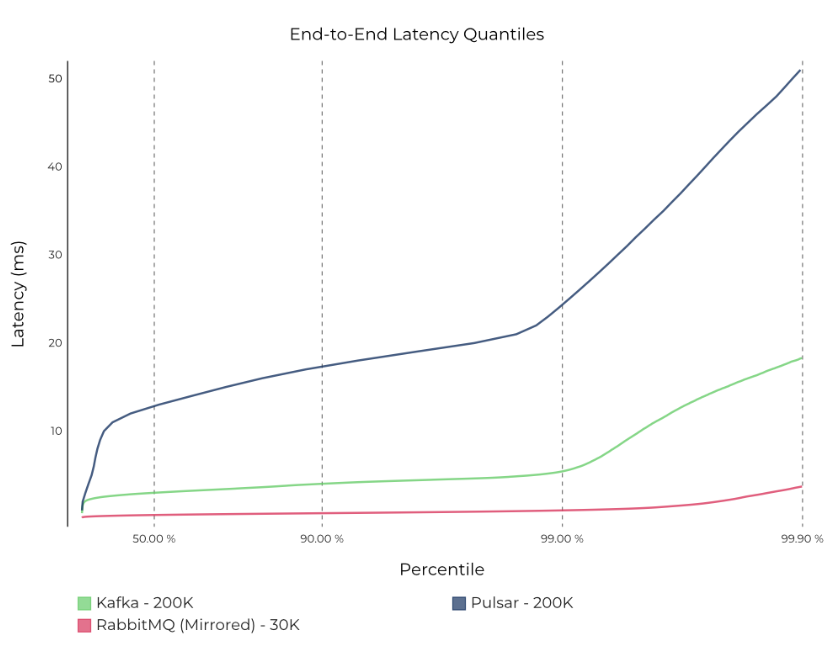
此图来源于confluent.io