背景
LLM Transparency Tool 是一个用于深入分析和理解大型语言模型(LLM)工作原理的工具,旨在增加这些复杂系统的透明度。它提供了一个交互式界面,用户可以通过它观察、分析模型对特定输入(prompts)的反应,以及模型内部的决策过程。
LLM Transparency Tool的主要功能包括:
- 选择模型和提示,并运行推理:用户可以选择一个已经集成的语言模型,并给这个模型提供一个提示(prompt),工具会显示模型是如何处理这个提示的。
- 浏览贡献图:这个功能允许用户社交从模型生成的token开始构建图表,通过调整贡献门槛来过滤信息。
- 选择任何模块后的token表示:用户可以查看每个处理块之后任意token的内部表示。
- 查看输出词汇表的投影:对于选中的表示,工具可以显示它是如何影响模型输出词汇的选择的,包括哪些token被之前的块促进或抑制了。
- 可交互的图形元素:包括连接线(展示了贡献的注意力头信息)、当选中连接线时显示的头部信息、前馈网络块(FFN blocks)、以及选中FFN块时的神经元等。
使用场景
- 模型分析与调优:研究人员或开发者在开发或优化语言模型时,可以使用此工具来观察模型对特定输入的处理过程,找出模型的优点与不足。
- 教育与学习:对深度学习和NLP(自然语言处理)感兴趣的学生或爱好者可以通过这个工具来加深对大型语言模型工作原理的理解。
- 算法透明度与可解释性:在追求算法透明度和可解释AI的推进中,该工具可作为分析工具的一种,帮助解释模型的决策依据
项目说明
- 项目地址:https://github.com/facebookresearch/llm-transparency-tool
- 项目依赖:https://github.com/TransformerLensOrg/TransformerLens
- 论文地址:https://arxiv.org/pdf/2403.00824.pdf
- Transparency Tool是基于TransformerLens开发的,TransformerLens是一个专注于生成语言模型(如GPT-2风格的模型)的可解释性的库。其核心目标是利用训练好的模型,通过分析模型的内部工作机制,来提供对模型行为的深入理解
- 凡是TransformerLens支持的模型,Transparency Tool都能支持。对于TransformerLens不支持的模型,需要实现自己的TransparentLlm类
部署
# download
git clone git@github.com:facebookresearch/llm-transparency-tool.git
cd llm-transparency-tool# install the necessary packages
conda env create --name llmtt -f env.yaml
# install the `llm_transparency_tool` package
pip install -e .# now, we need to build the frontend
# don't worry, even `yarn` comes preinstalled by `env.yaml`
cd llm_transparency_tool/components/frontend
yarn install
yarn build
- 模型配置
{"allow_loading_dataset_files": true,"preloaded_dataset_filename": "sample_input.txt","debug": true,"models": {"": null,"/root/.cache/modelscope/hub/AI-ModelScope/gpt2-medium": null, // 额外添加模型"/root/.cache/Qwen1.5-14B-Chat/": null, // 额外添加模型"gpt2": null,"distilgpt2": null,"facebook/opt-125m": null,"facebook/opt-1.3b": null,"EleutherAI/gpt-neo-125M": null,"Qwen/Qwen-1_8B": null,"Qwen/Qwen1.5-0.5B": null,"Qwen/Qwen1.5-0.5B-Chat": null,"Qwen/Qwen1.5-1.8B": null,"Qwen/Qwen1.5-1.8B-Chat": null,"microsoft/phi-1": null,"microsoft/phi-1_5": null,"microsoft/phi-2": null,"meta-llama/Llama-2-7b-hf": null,"meta-llama/Llama-2-7b-chat-hf": null,"meta-llama/Llama-2-13b-hf": null,"meta-llama/Llama-2-13b-chat-hf": null,"gpt2-medium": null,"gpt2-large": null,"gpt2-xl": null,"mistralai/Mistral-7B-v0.1": null,"mistralai/Mistral-7B-Instruct-v0.1": null,"mistralai/Mistral-7B-Instruct-v0.2": null,"google/gemma-7b": null,"google/gemma-2b": null,"facebook/opt-2.7b": null,"facebook/opt-6.7b": null,"facebook/opt-13b": null,"facebook/opt-30b": null},"default_model": "","demo_mode": false
}- 适配更多模型

- 启动
streamlit run llm_transparency_tool/server/app.py -- config/local.json
- 效果
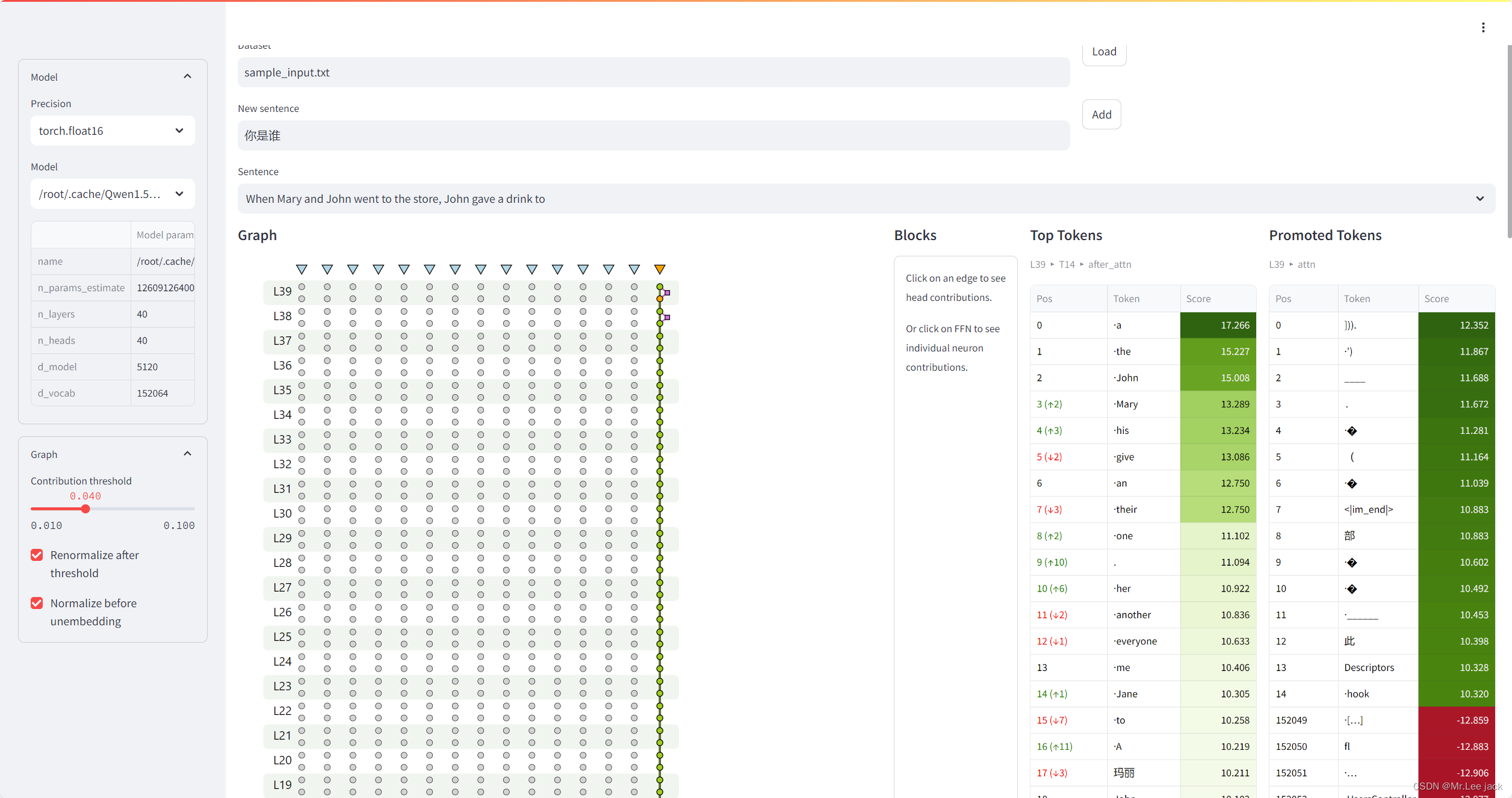
原理
引言
-
Transformer架构:作者首先指出,当前最先进的语言模型(LMs)大多基于Transformer架构,这是一种深度学习模型,广泛应用于自然语言处理任务中。Transformer模型通过自注意力机制(self-attention)和前馈网络(feed-forward networks)处理语言信息。
-
信息流的概念:在Transformer模型中,每个token的表示(representation)会随着网络层的加深而不断演化。这种演化过程可以视为信息流,即信息在模型内部的流动和转换。作者将这种信息流比作一个图,其中节点代表token的表示,边代表模型内部的计算操作。
-
信息流的重要性:尽管在模型的前向传播过程中,所有的计算路径都存在,但对于特定的预测任务,只有一部分计算是重要的。作者强调了识别和提取这些重要信息流路径的重要性,因为这有助于我们更好地理解模型是如何做出特定预测的。
-
现有方法的局限性:论文提到了现有的基于激活补丁(activation patching)的方法,这种方法通过替换模型内部的激活值来研究模型的行为。然而,这种方法存在局限性,包括需要人为设计预测模板、分析仅限于预定义模板、以及在大规模模型中不切实际等。
-
提出的新方法:为了克服现有方法的局限性,作者提出了一种新的方法来自动构建信息流图,并提取对于每个预测最重要的节点和边。这种方法不需要人为设计的模板,可以高效地应用于任何预测任务,并且只需单次前向传播即可完成。
-
实验和结果:在引言的最后,作者简要提到了他们使用Llama 2模型进行的实验,展示了新方法的有效性。他们发现某些注意力头(如处理前一个token的头和子词合并头)在整体上很重要,并且模型在处理相同词性的token时表现出相似的行为模式。
-
贡献总结:作者总结了他们的贡献,包括提出了一种新的解释Transformer LMs预测的方法,与现有方法相比,新方法具有更广泛的适用性、更高的信息量和更快的速度
信息流路径的提取
实现步骤
-
构建信息流图:首先,将模型内部的计算过程表示为一个图,其中节点代表token的表示,边代表模型内部的操作,如注意力头、前馈层等。
-
自顶向下追踪:从预测结果的节点开始,自顶向下地追踪网络中的信息流动。在每一步中,只保留对当前预测结果有重要影响的节点和边。
-
设置重要性阈值:通过设置一个阈值τ,只有当边的重要性高于这个阈值时,才会将其包含在最终的信息流路径图中。
-
利用属性方法:与传统的激活补丁方法不同,作者使用属性(attribution)方法来确定边的重要性。这种方法不需要人为设计对比模板,可以更高效地识别对预测结果有实质性影响的信息流动路径。
-
计算边的重要性:根据ALTI(Aggregation of Layer-Wise Token-to-Token Interactions)方法,计算每个边对于节点(即token表示的总和)的贡献度。贡献度与边向量与节点向量的接近程度成正比。
意义
-
提高透明度:通过提取信息流路径,可以更清晰地看到模型内部是如何进行决策的,提高了模型的透明度。
-
优化模型设计:理解信息流动的模式可以帮助研究者发现模型设计中的不足之处,从而进行优化。
-
解释预测结果:信息流路径提供了一种方式来解释模型的预测结果,有助于理解模型为何做出特定的预测。
-
发现模型组件的专门化:通过分析信息流路径,可以识别出模型中专门针对特定领域或任务的组件。
-
提高模型的可靠性:通过识别和强化重要的信息流动路径,可以提高模型在面对复杂或模糊输入时的可靠性
如何理解模型行为
-
注意力头的作用:通过分析哪些注意力头在信息流路径中起关键作用,可以理解模型在处理特定类型的输入时依赖哪些信息。
-
信息流动模式:观察信息在模型内部如何流动,可以帮助我们理解模型是如何处理和整合不同部分的信息来做出预测的。
-
模型的泛化能力:通过分析信息流路径,可以评估模型在不同任务或不同领域中的泛化能力。
-
模型的脆弱性:识别信息流路径中的脆弱环节,可以帮助我们理解模型可能在哪些情况下失效,并采取措施进行改进。
-
模型的自我修复能力:通过比较信息流路径在正常和干预(如激活补丁)情况下的差异,可以研究模型的自我修复能力。
参数解释
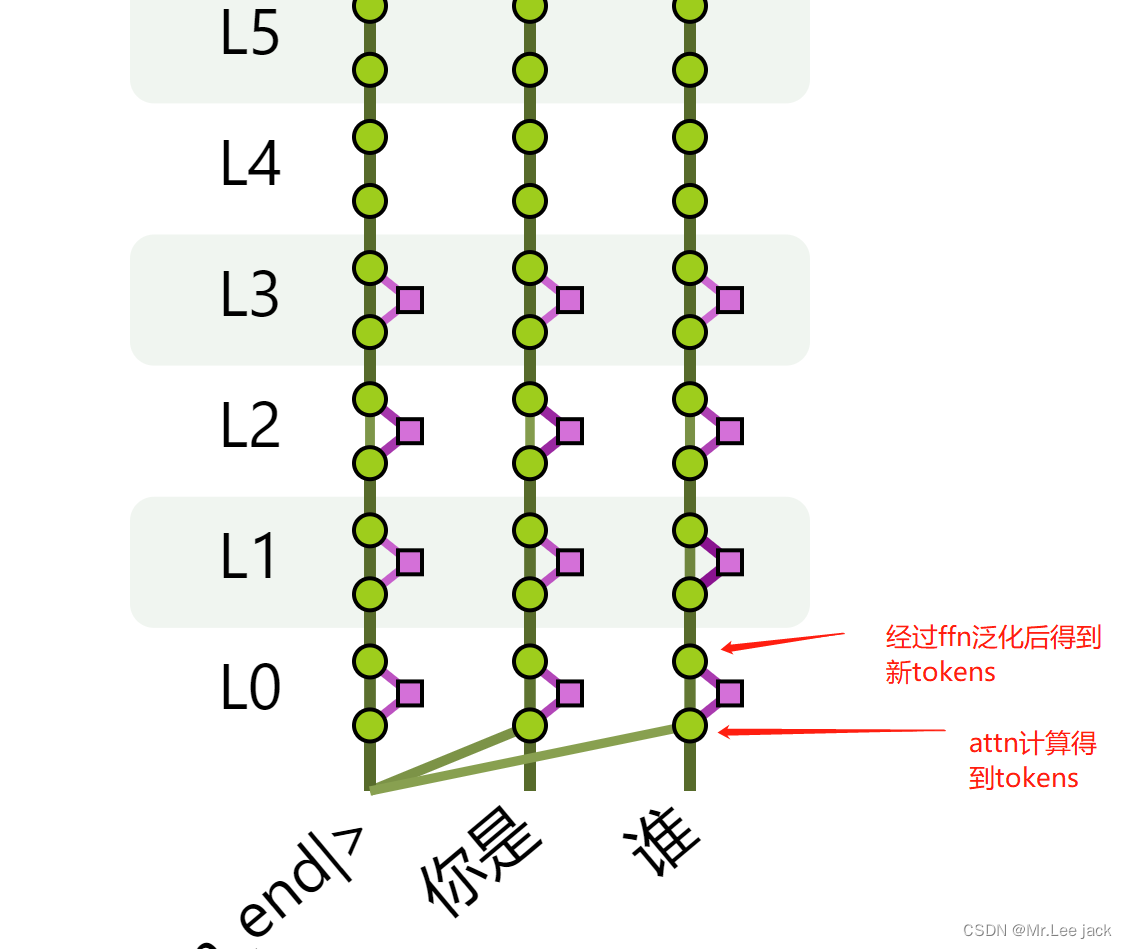
- y轴表示 模型层
- 横轴表示对应得token
- 每次计算从L0依次向上计算,并经过attention计算在经过ffn泛化,每次都得到最重要得 top k个token
怎么理解Promoted Tokens
L39 ffn
-
在Transformer架构中,"l39 ffn"通常指的是位于模型第39层(layer 39)的前馈网络(feed-forward network,简称FFN)。以下是对"l39 ffn"的详细解释:
-
Layer(层):在深度学习模型中,尤其是Transformer模型,信息会通过多个层次(layers)进行处理。每一层都会对输入数据进行一些变换,以提取特征或进行抽象表示。
-
Feed-Forward Network(前馈网络):FFN是Transformer模型中的一种组件,通常位于每个注意力(attention)层之后。它由两个线性变换组成,中间夹着一个非线性激活函数(如ReLU)。FFN的作用是对注意力层的输出进行进一步的非线性变换,增加模型的表达能力。
-
Layer 39(第39层):在某些大型语言模型中,可能会有数十层的深度结构。"l39"指的是模型中的第39层,这意味着信息已经通过了前38层的处理,并且在第39层中进一步被变换和抽象。
-
FFN的作用:在第39层的FFN中,模型会对从第38层传递来的信息进行处理。这个过程包括:
- 一个线性变换,将输入映射到一个更高或更低维度的空间。
应用一个非线性激活函数,通常是ReLU,以引入非线性特性,帮助模型学习复杂的模式。 - 另一个线性变换,将激活后的结果映射回原始维度或另一个特定的维度。
- 一个线性变换,将输入映射到一个更高或更低维度的空间。
-
理解FFN的重要性:FFN是Transformer模型中不可或缺的一部分,它允许模型在每个层级上进行更复杂的特征转换。通过这种方式,模型可以学习到更加抽象和高级的语言特征,这对于处理复杂的语言任务至关重要。
-
在模型解释性中的作用:在论文中提到的信息流路径提取方法中,FFN的重要性也可能被评估。研究者可能会分析第39层FFN对最终预测的贡献,以及它如何与同一层次的注意力机制协同工作。
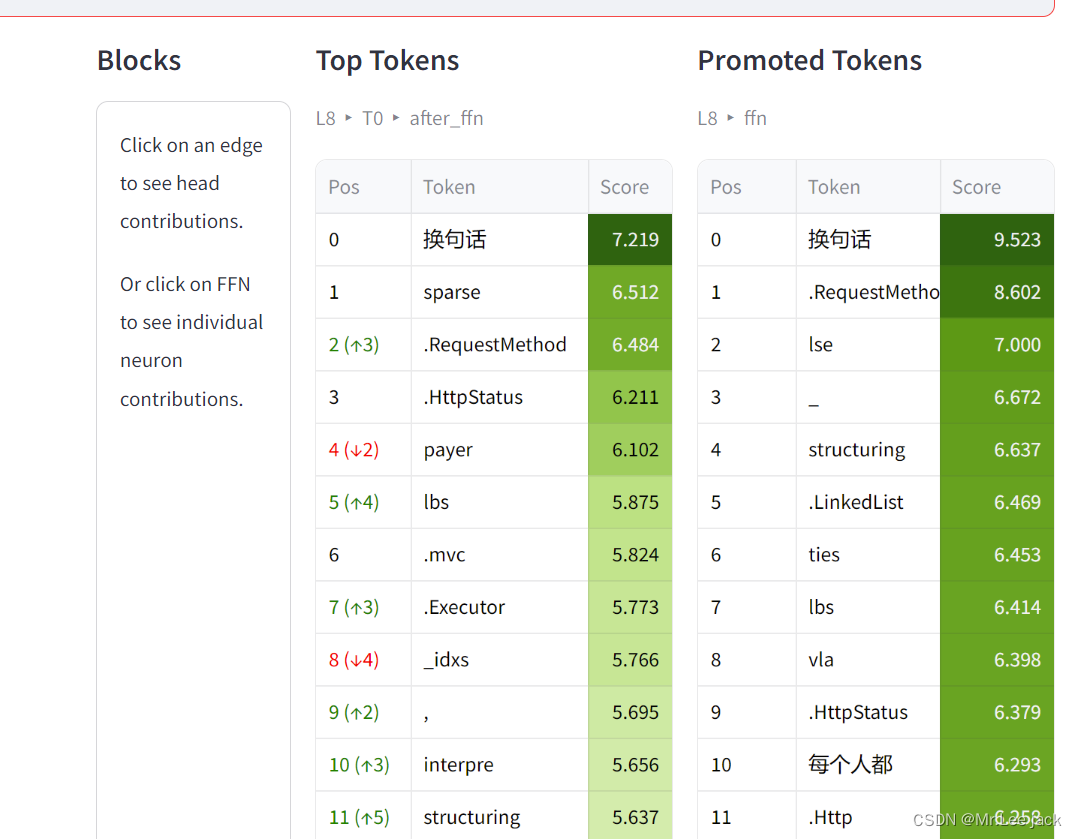
怎么理解Top Tokens
- L8 T0 after attn: 表示第8层经过attention 计算得到预测token
- L8 T0 after ffn:表示第8层经过ffn 泛化 计算得到预测token,使模型表达能力更强了
待继续…

---- 立方体绘制)

















