PDF文档公众号回复关键字:20240621

2022 CSP-J 选择题
单项选择题(共15题,每题2分,共计30分:每题有且仅有一个正确选项)
3.运行以下代码片段的行为是 ( )
int x = 101;
int y = 201;
int * p =&x;
int * q =&y;
p=q;
A. 将x的值赋为 201
B. 将y的值赋为101
C. 将q指向x的地址
D. 将p指向y的地址
4.链表和数组的区别包括( )
A. 数组不能排序,链表可以
B. 链表比数组能存储更多的信息
C. 数组大小固定,链表大小可动态调整
D. 以上均正确
10.以下对数据结构的表述不恰当的一项为 ( )
A. 图的深度优先遍历算法常使用的数据结构为栈
B. 栈的访问原则为后进先出,队列的访问原则为先进先出
C. 队列常常被用于广度优先搜索
D. 栈与队列存在本质不同,无法用栈实现队列
13.八进制数32.1对应的十进制数是
A. 24.125
B. 24.250
C. 26.125
D. 26.250
15.以下对递归方法的描述中,正确的是( )
A. 递归是允许使用多组参数调用函数的编程技术
B. 递归是通过调用自身求解问题的编程技术
C. 递归是面向对象和数据而不说功能和逻辑的编程语言模型
D. 递归是将用某种高级语言转换为机器代码的编程技术
2 相关知识点
1) 指针
指针是 C++语言中广泛使用的一种数据类型,指针是一个变量,其值为另一个变量的地址,即,内存位置的直接地址
int *ip; /* 一个整型的指针 */
float *fp; /* 一个浮点型的指针 */
char *ch; /* 一个字符型的指针 */
指针指向的是变量的地址
#include <iostream>
using namespace std;
int main (){int a = 20; // 实际变量的声明int *ip; // 指针变量的声明ip = &a; // 在指针变量中存储 a 的地址cout << "a变量的值: ";cout << a << endl;// 输出在指针变量中存储的地址cout << "指针变量的值,指针指向的变量的地址: ";cout << ip << endl;// 访问指针中地址的值cout << "指针指向地址对应变量的值(a的值): ";cout << *ip << endl;return 0;
}
2) 数组/链表
数组是一种线性数据结构,它将具有相同类型的元素存储在连续的内存空间中。数组中每个元素通过其索引进行访问,索引从0开始
常规数组的长度是固定的,特殊数组长度不固定,例如vector数组
链表也是一种线性数据结构,但是它将元素存储在非连续的内存空间中,链表中的每个元素包含两部分:该元素的数据和指向下一个元素的指针
链表长度不固定
3) R进制转10进制
按权展开,但要注意各个位的权,最低位(最右边)的权是0次方,权值为1
(11010110)2=1×2^7+1×2^6+0×2^5+1×2^4+0×2^3+1×2^2+1×2^1+0×2^0=(214)10
包括小数
(1011.01)2=(1*2^3+1*2^1+1*2^0+1*2^(-2))=8+2+1+0.25=11.25
4) 递归
递归是一种解决问题的方法,它通过将问题分解为更小的子问题来解决。
一个递归函数会在其定义中直接或间接地调用自身
递归通常包括两个部分:基本情况(Base case)和递归步骤(Recursive step)。
基本情况是指当问题规模变得足够小时,可以直接得到解决方案的情况。
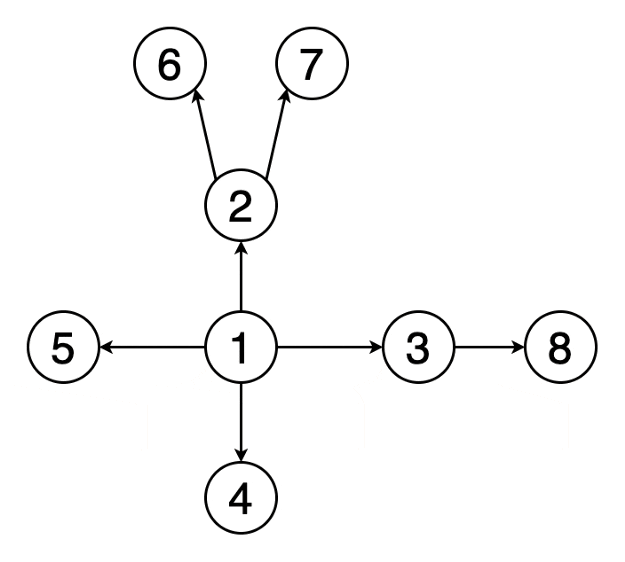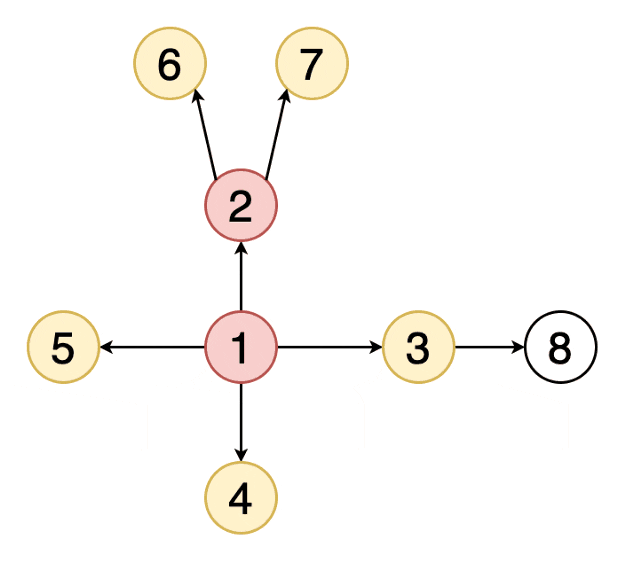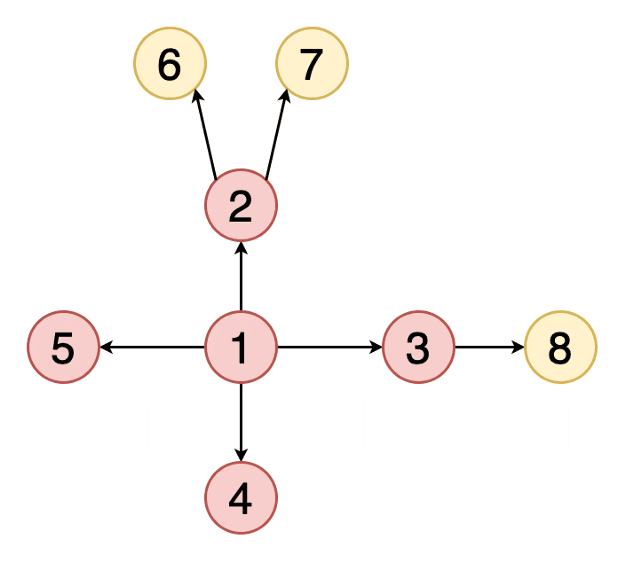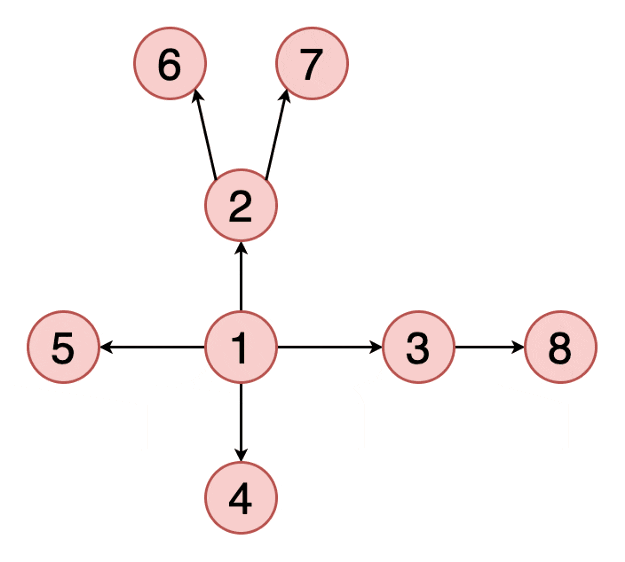
5)宽度优先遍历(BFS)
(BFS, Breadth First Search)是一个针对图和树的遍历算法。发明于上世纪50年代末60年代初,最初用于解决迷宫最短路径和网络路由等问题
是从根结点开始沿着树的宽度搜索遍历,将离根节点最近的节点先遍历出来,在继续深入遍历
实现DFS时,通常使用队列数据结构实现
6) 深度优先遍历(DFS)
从某个特定顶点开始,沿着每个分支尽可能搜索。DFS中,还需跟踪访问过的顶点。
实现DFS时,通常使用堆栈数据结构来实现
7) 2栈实现1队列
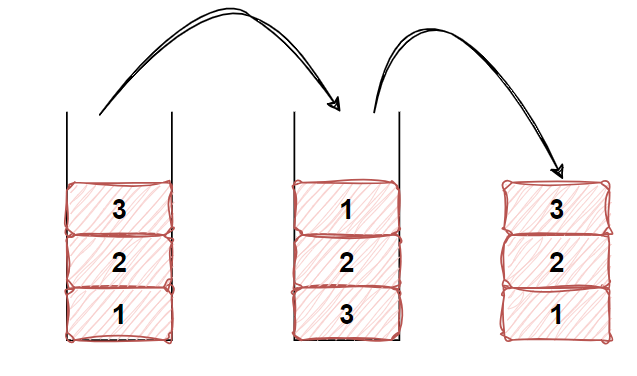
主要思路
存储元素到栈1
取出时把栈1中元素取出放入另外栈2(栈2的栈顶对应栈1的栈底),从栈2取做到了先进先出
#include<bits/stdc++.h>
using namespace std;
/*双栈转队列 主要思路存储元素到栈1取出时把栈1中元素取出放入另外栈2(栈2的栈顶对应栈1的栈底),从栈2取做到了先进先出
*/
class Queue {private:stack<int> s1;//push存入 stack<int> s2;//把push存入s1的元素对口push到s2,再出栈 public:void push(int num){//push到栈s1 s1.push(num);}/*1 把栈s1中的元素逐一取出 放入s22 取出第1个元素 3 把栈s2中的元素逐一取出 放入s1 4 上述1 2 3操作后,取出了s1最下面元素后剩余元素又恢复了对应位置 */int pop(){int temp;while (!s1.empty()){s2.push(s1.top());s1.pop();}temp = s2.top();s2.pop();while (!s2.empty()){s1.push(s2.top());s2.pop();}return temp;}/*top和pop类似top只是返回最上面一个元素,不取出此元素 */ int top(){int temp;while (!s1.empty()){s2.push(s1.top());s1.pop();}temp = s2.top();while (!s2.empty()){s1.push(s2.top());s2.pop();}return temp;}/*判空 2个队列都为空 */ bool empty(){return s1.empty() && s2.empty();}
};
int main(){Queue queue;//放入3个元素 queue.push(1);queue.push(2);queue.push(3);//按先进先出的顺序输出 cout << queue.pop() << endl;cout << queue.pop() << endl;
}
3 思路分析
3.运行以下代码片段的行为是 ( D )
int x = 101;
int y = 201;
int * p =&x;
int * q =&y;
p=q;
A. 将x的值赋为 201
B. 将y的值赋为101
C. 将q指向x的地址
D. 将p指向y的地址
分析
1 x 和 y 变量赋值,x为101,y为201 所以A和B不对
2 int * q =&y; //可知q指向y的地址,所以C不对
3 p=q;//q赋值为p (q指向y的地址) 所以p之星y的地址 所以D正确
4.链表和数组的区别包括( C )
A. 数组不能排序,链表可以
B. 链表比数组能存储更多的信息
C. 数组大小固定,链表大小可动态调整
D. 以上均正确
分析
1 数组可以排序,所以A不正确
2 没有任何约束,链表和数组存储信息无法比较 所以B不正确
3 数组大小是固定的,动态数组除外,一般提到数组就是普通数组,所以C是正确的
10.以下对数据结构的表述不恰当的一项为 ( D )
A. 图的深度优先遍历算法常使用的数据结构为栈
B. 栈的访问原则为后进先出,队列的访问原则为先进先出
C. 队列常常被用于广度优先搜索
D. 栈与队列存在本质不同,无法用栈实现队列
分析
1 深度优先遍历常用数据结构为栈,因为栈是后进先出,逐层深入遍历的子节点 A正确
2 栈的访问原则是后进先出,队列的访问原则是先进先出 B正确
3 队列常用作广度优先搜索,队列是先进先出,紧跟着的节点先进队列,先被遍历, C正确
4 栈和队列顺序相反,可以使用2个栈实现1个队列,参考相关知识点7)
13.八进制数32.1对应的十进制数是( C )
A. 24.125
B. 24.250
C. 26.125
D. 26.250
分析
R进制转10进制 -权展开,但要注意各个位的权,最低位(最右边)的权是0次方,权值为1
(32.1)8=(3*8^1+2*8^0+1*8(-1))10=(24+2+0.125)10=26.125
所以选C
15.以下对递归方法的描述中,正确的是( B )
A. 递归是允许使用多组参数调用函数的编程技术
B. 递归是通过调用自身求解问题的编程技术
C. 递归是面向对象和数据而不是功能和逻辑的编程语言模型
D. 递归是将用某种高级语言转换为机器代码的编程技术
分析
1 递归主要是函数可以自己调用自己,所以选B
2 多组参数调用是参数传递和递归无关,所以A不对
3 递归和面向对象无关,也没说明自己调用自己 所以C不对
4 将高级语言转换为机器码是编译器的作用,和递归无关 所以D不对









)









