根据报表的需求,很多报表中的指标数据需要进行预处理,以满足快速抽取和展示的需要。对于帆软报表类似的产品,一般通过建立视图、合并数据表,形成直接应用于模板设计的数据集,报表直接和数据集进行交互、关联。当用户发起报表请求时,一般根据报表查询条件,按照数据集定义即时从数据库中获取数据,然后填充到模板中生成报表返回。也就是报表都是模板和数据集即时关联的产物,至于数据集是数据来源的定义,直接关联数据库,在生成报表时执行查询功能。

而针对生产过程数据,对于月度统计、年度统计指标,一个标签点的数据动辄几百万、上千万的数据统计,则必需进行预处理,预处理方式一般采用序列化和提前调度等方式。
对于生产数据的这种情况,帆软报表需要提前进行专用接口程序进行数据预处理,并将结果写入指定数据库表中,形成报表需要的数据集,报表展示时与结果数据集进行交互,该情况下,导致实时数据源、专用接口程序、数据集及报表展示等环节的松耦合程度大大降低,后台程序根据配置提前完成指标统计,而报表展示则与后台程序脱节,直接管理结果数据库,对于数据排错、数据源追溯、计算过程分析及后续维护都带来工作量的增加,其扩展性收到严重制约。
对于行列视报表而言,实时数据库的数据预处理则显得更加专业,数据源的定义,它通过界面单元格与实时数据源之间通过函数方式直接建立计算关系,其数据获取来源、统计方式、计算方式、关联参数等都在单元格中体现,最终用户可以直接进行交互。关于报表定义好后,何时进行数据处理则需要根据用户的设置采用不同的执行方式。如果用户采用定时调度,则报表单元格中的取数定义在指定时间执行,调度完成后报表则直接打开包含数据的报表,无论数据多少,报表展示时间可以忽略不计,瞬间打开。如果用户采用在打开报表的时候执行,则在系统第一个用户浏览报表时,后台调度即时按照单元格中的定义从数据源获取数据,获取完数据后,结果在报表页面中展示,该方式在首次打开报表时,根据指标数量和取值周期长短,会有一定的时间延迟,但在后续的报表展示时,则不会再有延迟,这是由于在该方式下类似第一次打开该报表时执行了报表取数行为,同时系统进行了缓存,后续报表展示直接从缓存中读取,以此提升用户体验。如果由于模板调整,需要报表重新执行取数行为,只需要在报表界面上执行“重算”功能,则该报表就类似第一次打开时的情景,重新调度和缓存。
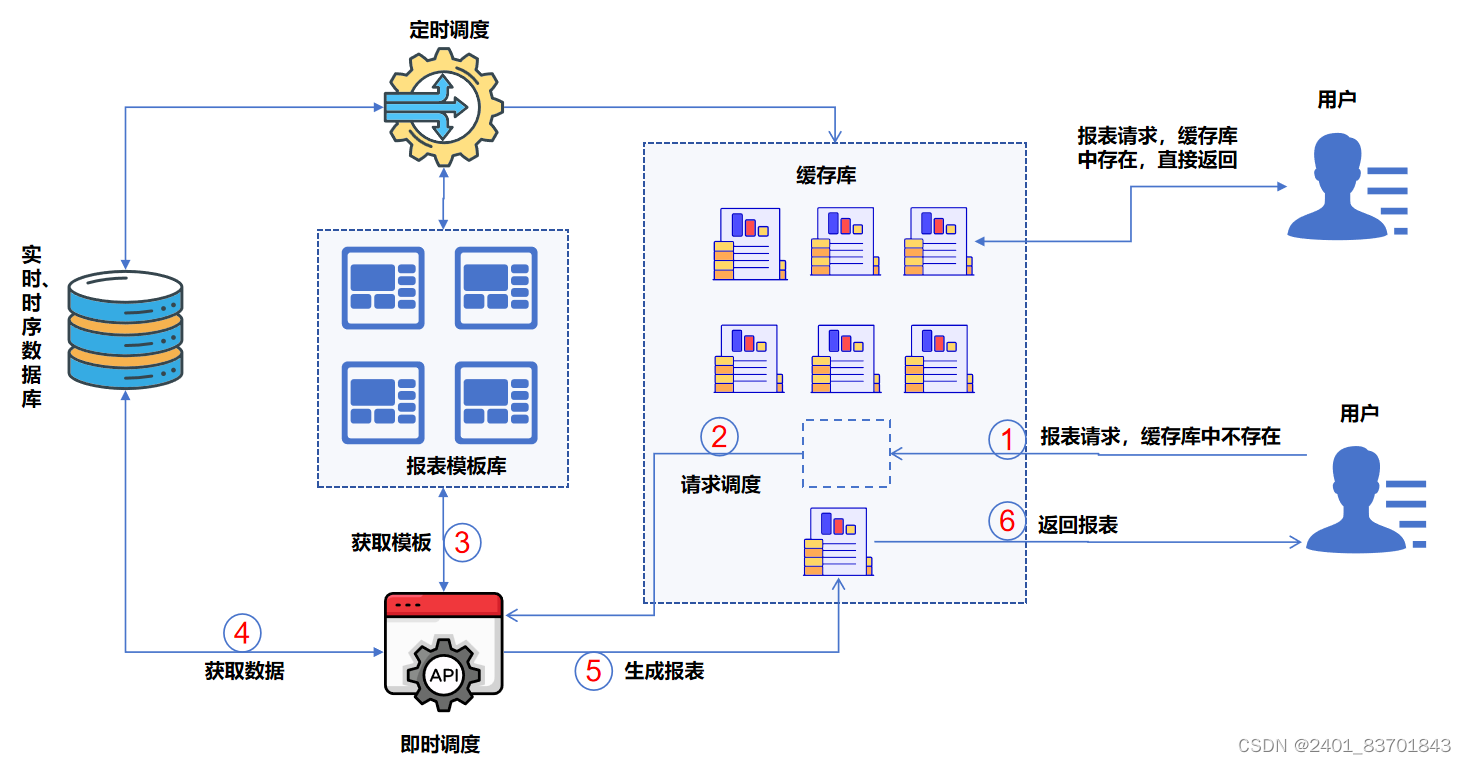
注:行列视生成的报表,在系统中会将报表结果分别存储模板、带数据的报表页面、报表中的数据三个内容分别存储并应用于不同场景,报表模板用于记录报表生成时的指标来源、计算关系和报表中指标的组织方式,带数据的报表页面用于快速展示,提升用户体验,报表中的数据独立存储,方便后续使用,由此可以看出,行列视每个报表生成后会与后台数据源解耦,在界面上进行的任何操作都不会影响数据源,此种情况可以让结果报表适应数据修正、管理审批、外部填报等多种应用场景。






)







)




