记录一种可以识别局部单调的系数
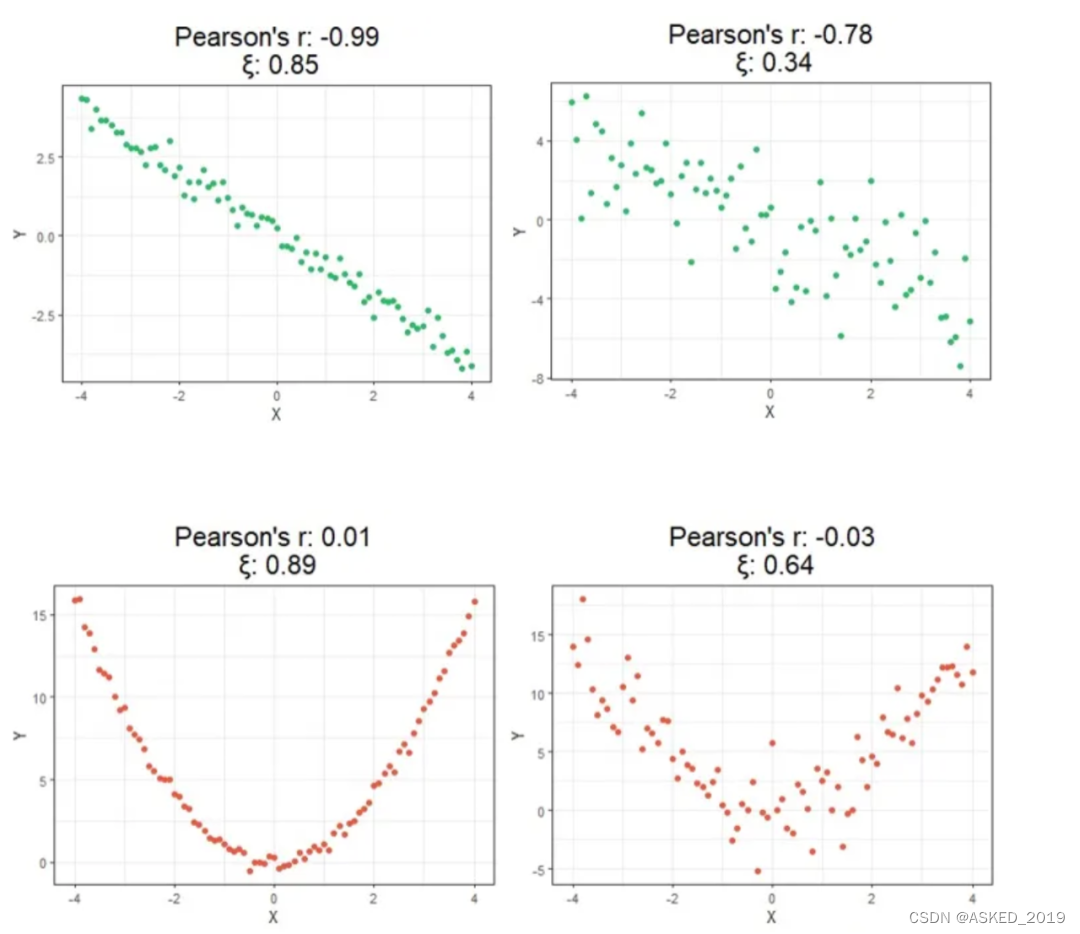
pearson和kendall等系数再识别单调的时候,更多是关注整体情况,很多时候,变量和因变量之间非简单的单调关系,局部单调ξ识别
假设我们正在测量变量X和Y之间的关系。传统的相关性测量方法通常假定X与Y之间的关系是线性的,即X和Y之间的相关性是对称的。然而,新方法的目标是测量Y作为X的函数的程度,因此ξ(X, Y)不一定等于ξ(Y, X)。
为了计算ξ,我们首先需要对数据进行排序,使得X的值按从小到大的顺序排列。然后,我们需要计算Y值的秩。根据数据中是否存在重复值,我们有两种不同的公式:
如果数据中不存在重复值
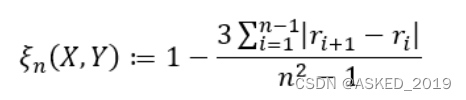
如果存在重复值:
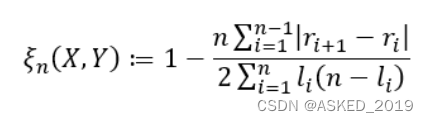
代码实现:
import numpy as np
import randomdef xicor(X, Y, ties=True):"""ties是否存在相同值,如果存在则为True"""n = len(X)order = np.array([i[0] for i in sorted(enumerate(X), key=lambda x: x[1])])if ties:l = np.array([sum(y >= Y[order]) for y in Y[order]])r = l.copy()for j in range(n):if sum([r[j] == r[i] for i in range(n)]) > 1:tie_index = np.array([r[j] == r[i] for i in range(n)])r[tie_index] = random.sample(list(r[tie_index] - np.arange(0, sum(tie_index))), sum(tie_index))return 1 - n * np.sum(np.abs(r[1:] - r[:n-1])) / (2 * np.sum(l * (n - l)))else:r = np.array([sum(y >= Y[order]) for y in Y[order]])return 1 - 3 * np.sum(np.abs(r[1:] - r[:n-1])) / (n**2 - 1)# pyspark实现
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, rank, abs as spark_abs, sum as spark_sum, lit, monotonically_increasing_id
from pyspark.sql.window import Window# 初始化 SparkSession
spark = SparkSession.builder.appName("XiCorrelation").getOrCreate()# 样本数据
data = [(1, 0), (2, 0), (3, 1), (4, 1), (5, 1), (6, 0), (7, 0), (8, 1), (9, 1), (10, 0)]
columns = ["X", "Y"]
df = spark.createDataFrame(data, columns)# 计算 Xi 相关系数函数
def xicor(df, x_col, y_col, ties=True):n = df.count()# 排序和排名window = Window.orderBy(x_col)df = df.withColumn("rank", rank().over(window))if ties:# 处理 ties 的情况order = Window.orderBy(monotonically_increasing_id())df = df.withColumn("order_id", rank().over(order))df = df.withColumn("rank_Y", rank().over(Window.orderBy(y_col)))df = df.withColumn("l", spark_sum(col("rank_Y")).over(Window.partitionBy("rank_Y").orderBy("order_id")))def tie_adjustment(df, l_col):df = df.withColumn("r", col(l_col))for i in range(n):count = df.filter(col("r") == i).count()if count > 1:indices = df.filter(col("r") == i).select("order_id").rdd.flatMap(lambda x: x).collect()adjustments = np.random.permutation(np.arange(count))for j, idx in enumerate(indices):df = df.withColumn("r", when(col("order_id") == idx, col("r") - adjustments[j]).otherwise(col("r")))return dfdf = tie_adjustment(df, "l")else:# 不处理 ties 的情况df = df.withColumn("r", rank().over(Window.orderBy(y_col)))df = df.withColumn("diff", spark_abs(col("r") - col("rank")))if ties:xi = 1 - n * df.select(spark_sum(col("diff"))).first()[0] / (2 * df.select(spark_sum(col("l") * (n - col("l")))).first()[0])else:xi = 1 - 3 * df.select(spark_sum(col("diff"))).first()[0] / (n**2 - 1)return xi
需要注意的是这个系数本质上还是去识别单调,比pearson之类的提升也仅限于局部单调的识别。
如果一个数据是对于特定区间内存在聚集现象的二值化数据,
相关系数可能无法有效识别这种关系.
主要来源








)










