AASIST
论文
参考ASIST: Audio Anti-Spoofing using Integrated Spectro-Temporal Graph Attention Networks https://arxiv.org/pdf/2110.01200.pdf
模型结构
aasist是一种开源的音频反欺诈的模型,主要的模型结构如下所示:

算法原理
环境配置
Docker(方法一)
提供光源拉取的训练的docker镜像:
- 推理镜像:
docker pull image.sourcefind.cn:5000/dcu/admin/base/custom:aasist-main
docker run -it -v /path/your_code_data/:/path/your_code_data/ --shm-size=32G --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name docker_name imageID bash- 激活镜像环境:
source /root/env_disc.sh
cd /root/aasist;sh run.sh
- python依赖安装:
pip3 install -r requirements.txt
数据集
脚本下载方式:
python ./download_dataset.py
手动下载方式:
ASVspoof2019 dataset: https://datashare.ed.ac.uk/handle/10283/3336
下载LA.zip文件,unzip解压
LA├── ASVspoof2019_LA_asv_protocols├── ASVspoof2019_LA_asv_scores├──ASVspoof2019.LA.asv.dev.gi.trl.scores.txt├──ASVspoof2019.LA.asv.eval.gi.trl.scores.txt...├── ASVspoof2019_LA_cm_protocols├── ASVspoof2019_LA_dev├── ASVspoof2019_LA_eval├── ASVspoof2019_LA_train
推理
To evaluate AASIST [1]:
export TORCH_MHLO_OP_WHITE_LIST="aten::max;aten::batch_norm;aten::abs,aten::selu;prim::NumToTensor;aten::zeros_like;aten::size;aten::narrow;aten::cat;aten::selu_"python3 main.py --eval --config ./config/AASIST.conf
python3 main_opt.py --eval --config ./config/AASIST.conf
To evaluate AASIST-L [1]:
export TORCH_MHLO_OP_WHITE_LIST="aten::max;aten::batch_norm;aten::abs,aten::selu;prim::NumToTensor;aten::zeros_like;aten::size;aten::narrow;aten::cat;aten::selu_"python3 main.py --eval --config ./config/AASIST-L.conf
python3 main_opt.py --eval --config ./config/AASIST-L.conf
测试命令:
bash run.sh
result
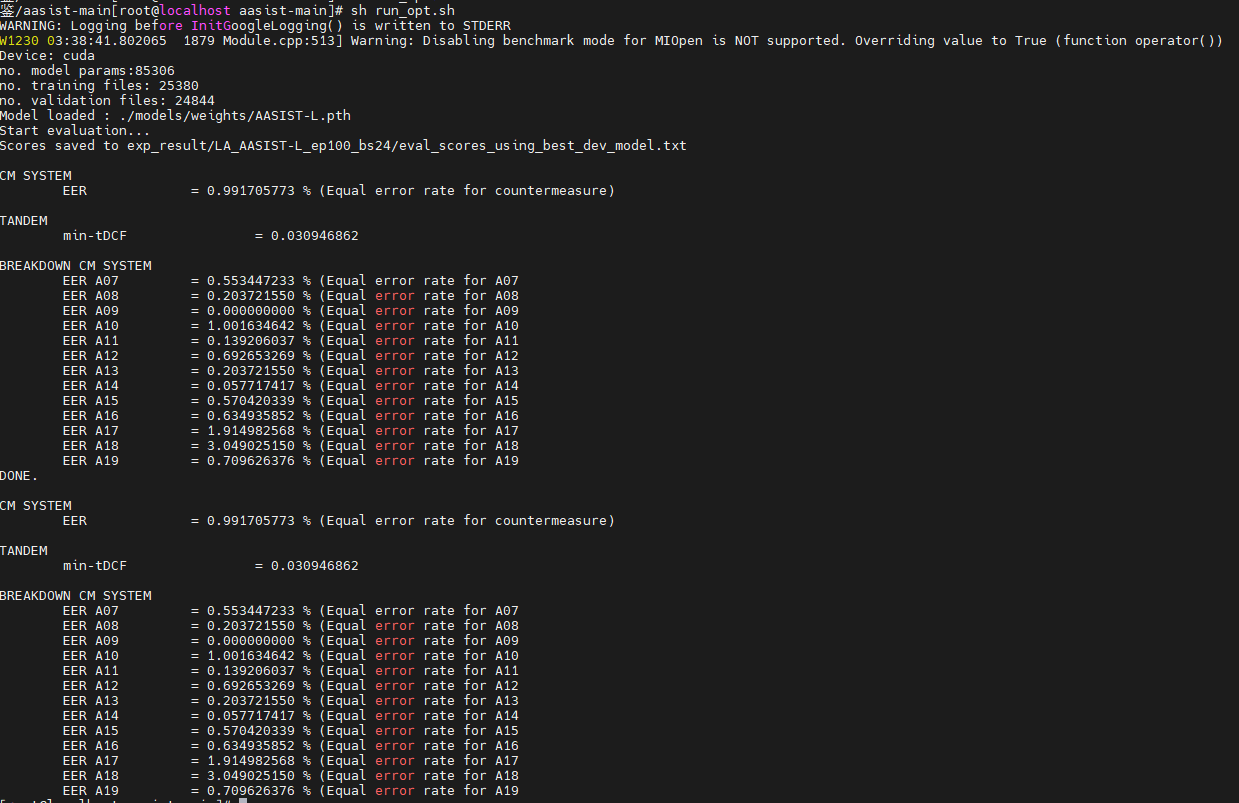
精度
使用Blade DISC优化后的精度与未使用Blade DISC优化后的精度保持一致
应用场景
算法类别
语音识别
热点应用行业
金融,交通,教育
源码仓库及问题反馈
ModelZoo / AASIST_bladedisc · GitLab
参考资料
GitHub - clovaai/aasist: Official PyTorch implementation of "AASIST: Audio Anti-Spoofing using Integrated Spectro-Temporal Graph Attention Networks"


)
)



)








云使能技术)

)
