一、场景要素语义分割部分的文献阅读笔记
1.1 PointNet
PointNet网络模型开创性地实现了直接将点云数据作为输入的高效深度学习方法(端到端学习)。最大池化层、全局信息聚合结构以及联合对齐结构是该网络模型的三大关键模块,最大池化层解决了点云的无序性问题,全局信息聚合结构实现了点云不同层次特征信息和全局信息的融合,联合对齐结构保证了点云几何变换的语义不变性与特征空间的对齐。

1.2 PointNet++
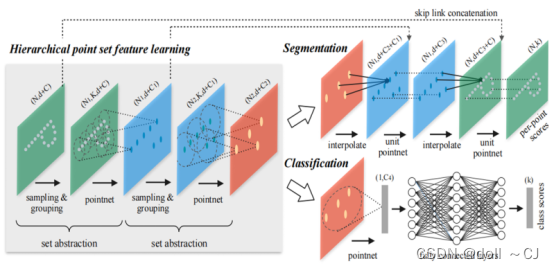
PointNet++网络模型的三大重要部分:
(1)多层次点集特征学习模块
多层次点集特征学习模块由多个点集抽象层堆叠组成,点集抽象层包含采样单元、分组单元和简化PointNet单元。点集抽象层的作用是将输入点云采样成多个点子集并提取对应的特征作为输入点云的局部特征,而堆叠多个点集抽象层是为了获得多层次高维特征。
点集抽象层,首先采用最远点采样算法(Farthest Point Sampling,FPS)完成局部区域中心点集的选择以保证中心点集能够基本覆盖局部区域范围并且特征提取计算高效。然后,基于中心点集依据设定的搜索半径逐点进行球邻域查询以对局部区域点云进行分组。最后,利用简化PointNet单元(不对输入数据进行联合对齐)抽象分组局部点云的整体性特征,计算获得对应特征向量。
(2)基于非均匀密度采样的稳定特征提取
点云在不同区域的密度不均匀现象十分常见。为减少点云密度不均匀对点集抽象层造成的影响,密度自适应PointNet层被应用于点集抽象层中,其方法分为多尺度组合(Multi-scale grouping,MSG)和多分辨率组合(Multi-resolution grouping,MRG)。多尺度组合,即设置不同的邻域搜索半径进行局部点云聚组,然后根据简化PointNet单元提取每个尺度的特征并串联拼接为特征向量;多分辨率组合,即首先直接对低层级点云利用点集抽象层提取特征,然后基于点集抽象层抽象出来的高层集点云再直接利用简化PointNet单元提取特征,继而将两者提取出来的特征进行串联拼接。
(3)语义分割任务的点特征传播模块
在语义分割任务中,需要获得所有原始点云的特征,然而在多层次点集特征学习模块的作用下点云被抽象成了多个中心点集,因此需要将点云恢复为原始数量。点特征传播模块采用反距离权重法插值出当前层采样前的所有点的分层特征。另外,为了减少采样和插值过程中的细节损失,使用跨层跳跃链接操作将当前插值得到的特征与对应的点集抽象层进行融合。再者,为减少运算量并增强网络的非线性拟合能力,需要通过简化PointNet单元降低特征维度。反距离权重法插值和简化PointNet单元需要组合使用至恢复点云原始数量。
二、Pytorch深度学习框架/Numpy使用记录
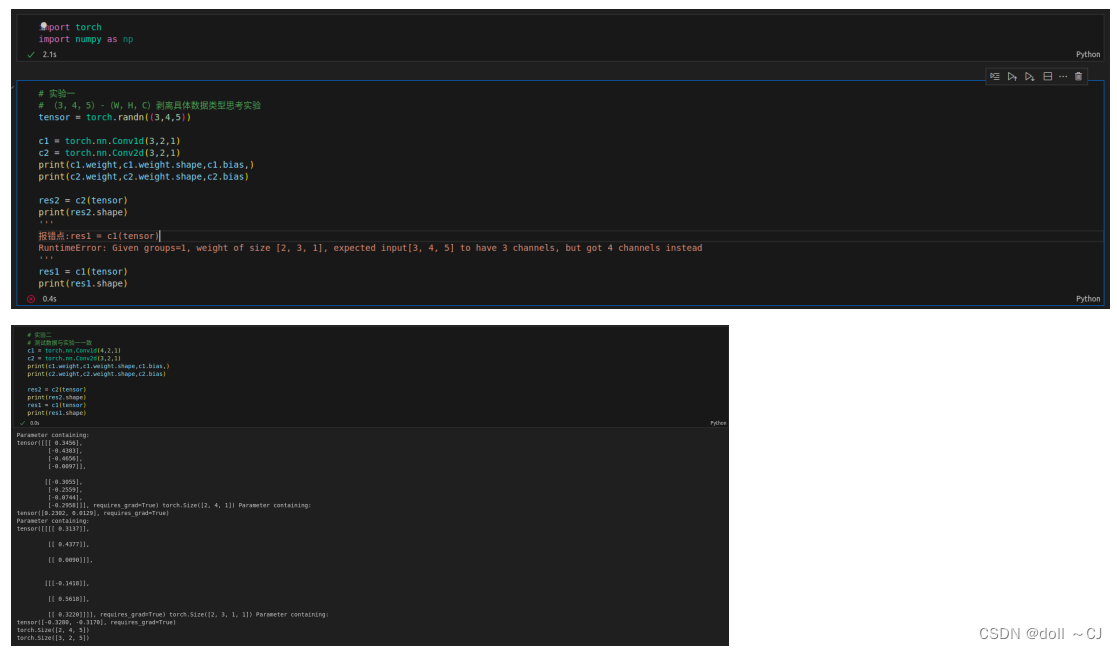
2.1 探索torch.nn.Conv1d与torch.nn.Conv2d的区别
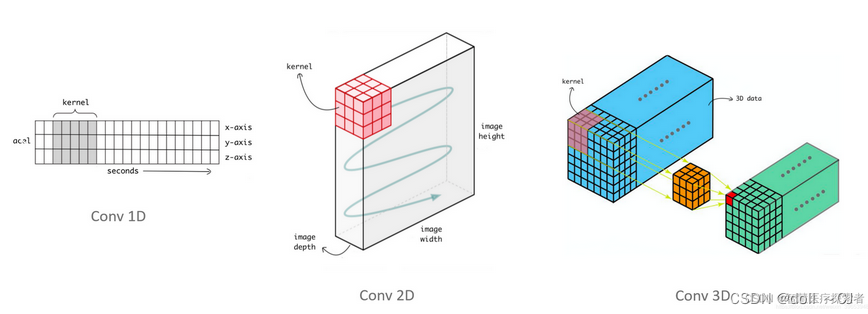
由图三和图四可知,二者In_Channels/out_Channels均为比卷积维度高一维度的通道数值。torch.nn.Conv2d常配合Tensor.permute使用完成对邻域点集的特征提取。当使用Tensor.permute将特征维C(或D)交换到第三维度的时候,即可利用torch.nn.Conv2d提取邻域点集特征。
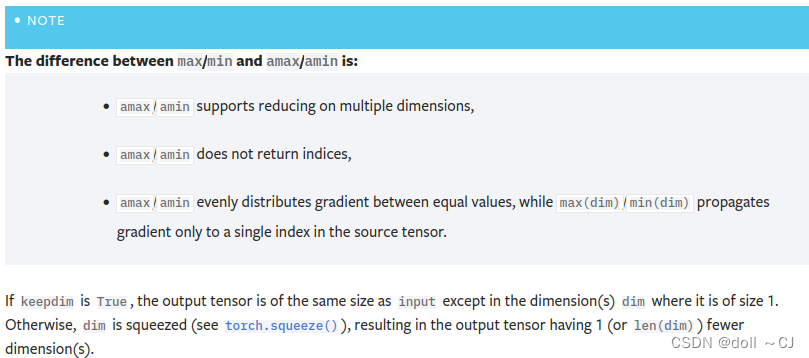
2.2 探索torch.max与torch.amax的区别
由图五和图六可知,两函数参数dim=-1(等同dim=矩阵最大维度数-1)意味着以矩阵的行为比较单位提取最大值。对于两函数的主要区别在于,torch.max的返回值包含对应最大值(返回值[0])与位置索引(返回值[1]),而torch.amax仅返回对应最大值。

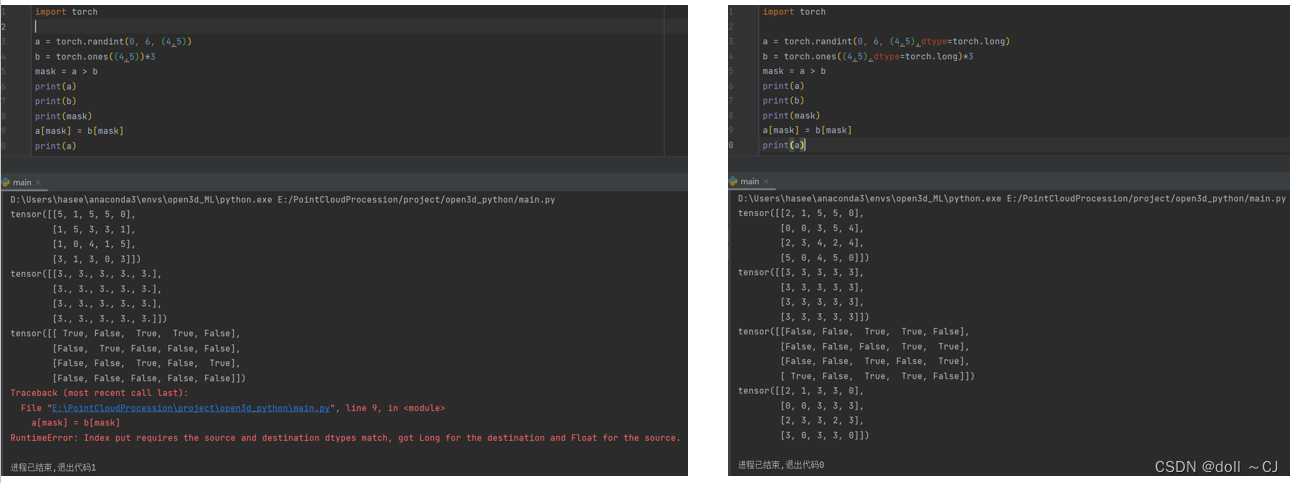
2.3 探索Tensor广播机制特性
由图七可知,在运用Tensor广播机制特性之对应元素赋值的时候,需要传入与被操作Tensor同样形状的布尔Tensor。值得注意的是,Tensor间的赋值需要保证Tensor的dtype(数据类型)一致。
2.4 探索Tensor.reshape 与Tensor.view的区别
通常两函数用于调整Tensor的形状以满足广播计算要求、数据维度调整等。详见参考资料[9],该博客讲述十分详细深入。
2.5 探索Tensor的高级索引方式和切片
绝大多数操作并不修改Tensor的数据,只是修改了Tensor的头信息。这种做法更节省内存,同时提升了处理速度。此外,有些操作(如view等)会导致Tensor不连续,这时需调用Tensor.contiguous方法将它们变成连续的数据,该方法复制数据到新的内存,不再与原来的数据共享storage。一般来讲,高级索引(花式、整形数组等索引)不共享storage,而普通索引共享storage[11-12]。
关于Tensor存储头属性的查阅可以参考torch.Tensor — PyTorch 2.2 documentation,共享内存Tensor头文件可参考图八,针对Tensor连续性的基础理解可参考从 Pytorch tensor 存储空间的连续性 (contiguous) 说到 4D tensor 的存储格式 (memory_format)_pytorch修改tensor的memoryformat-CSDN博客。
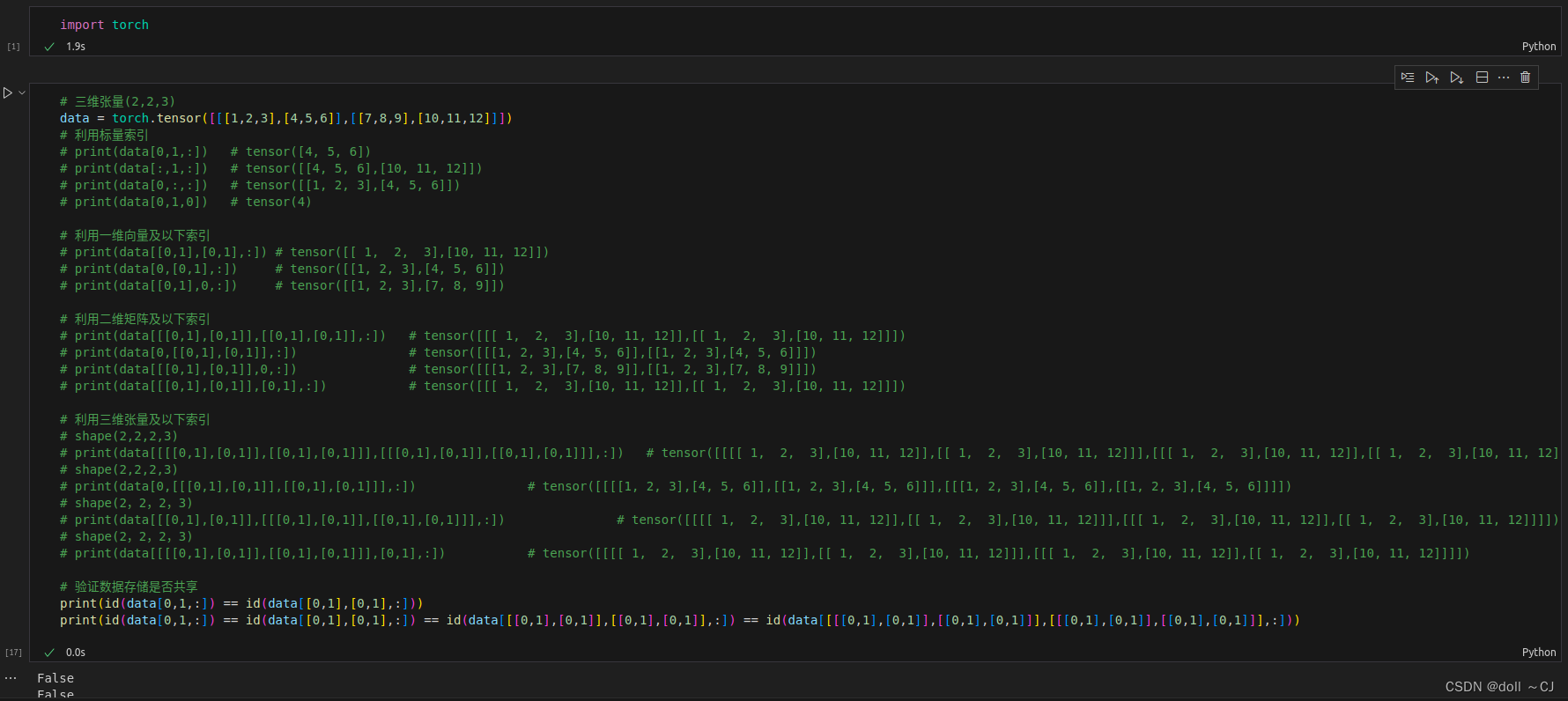
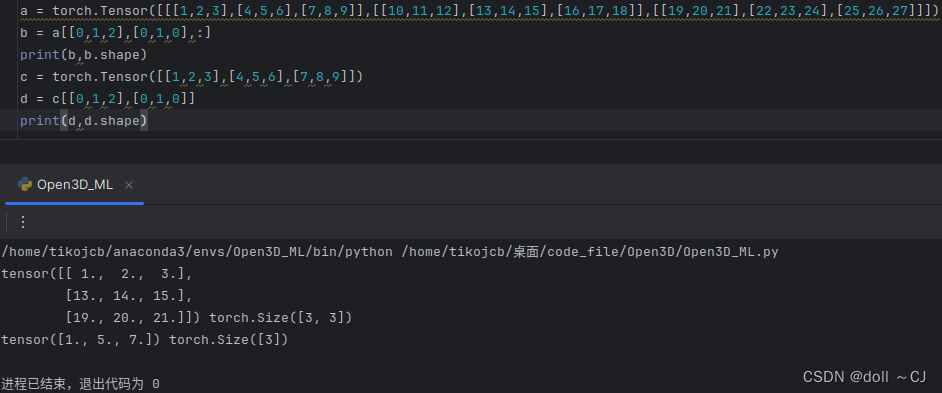
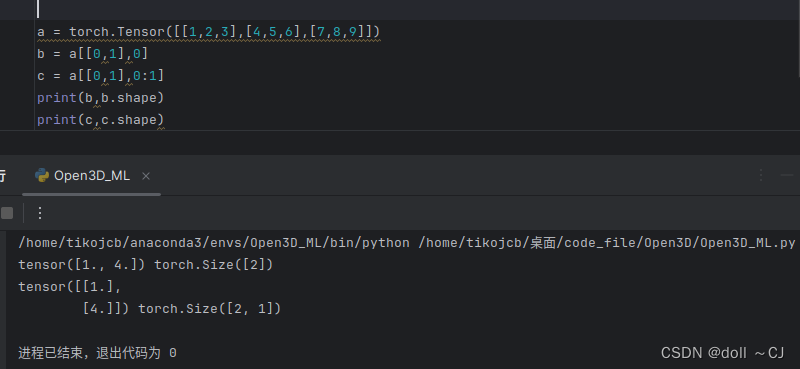
由图九、图十以及图十一可知,Tensor的高级索引,若以单独索引号取值,则会破坏Tensor原始维度数量(丢失一个维度),若以分割表达(n:n+1),则维度数量与原始Tensor一致。
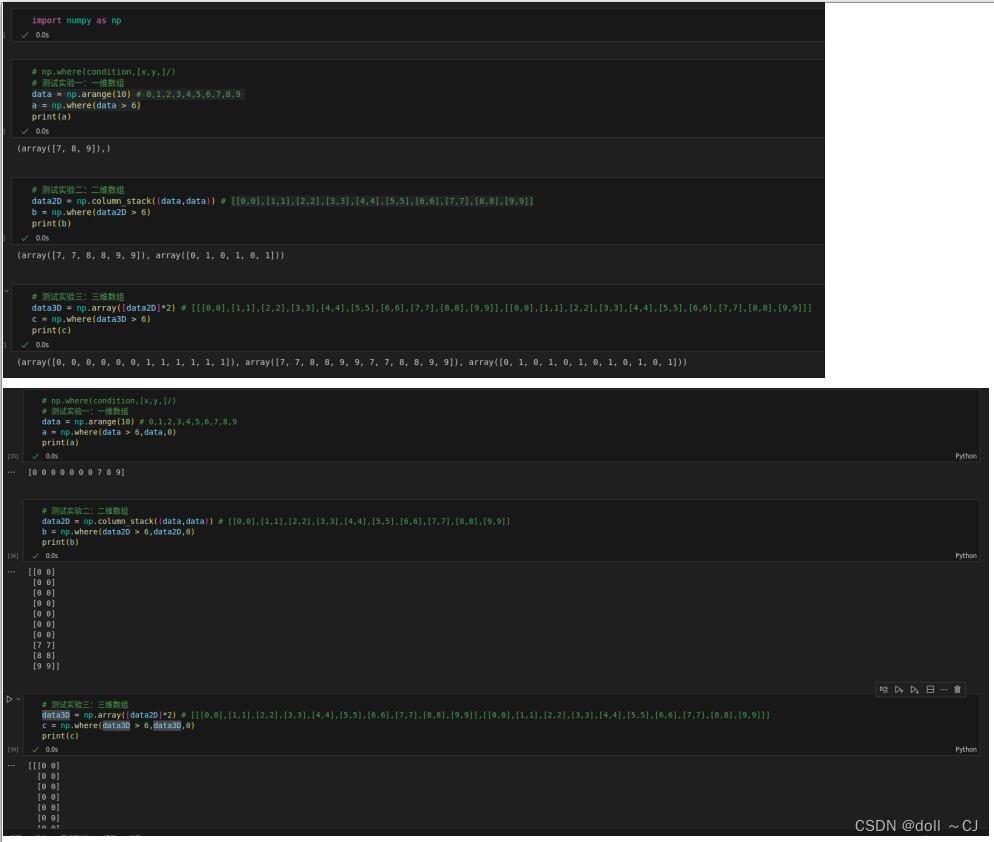
2.6 探索np.where的使用方法
通过图十二可知,若np.where()函数仅传入实参condition,则函数返回condition_array符合条件的元素索引(一维返回一维索引向量,二维返回二维索引矩阵,三维返回三维索引张量);若需要返回符合条件的所有元素值,则需要传入三个参数(condition、array、不符合条件的修正值(对应修正向量/矩阵/张量))。
可以利用&(按位与)、|(按位或)位运算进行多条件判断,需保证多个condition_array的形状一致。
#Pytorch深度学习框架
torch.transpose(input,dim0,dim1)——>Tensor
# 转置Tensor指定的两个维度
Tensor.permute(*dims)——>Tensor
torch.permute(input,dims)——>Tensor
# 返回原始张量输入的视图,并对其维度进行转置。这里返回视图指的是一个新的tensor对象,但新旧tensor对象内的数据共享存储(即数据元素是相同的),返回的新对象可能会变得不连续,这样就无法对新对象使用view方法
class torch.nn.Conv1d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None)
# 1D卷积主要用于文本/语音数据[8],仅对W维进行卷积(Input:(N,C,D,H,W))
class torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None)
# 2D卷积常用于图像数据[8],对H维、W维同时卷积(Input:(N,C,D,H,W))
class torch.nn.Conv3d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None)
# 3D卷积常用于医学影像图像分割、视频中的动作检测[8]以及序列时序检测等,对D维、H维、W维同时卷积(Input:(N,C,D,H,W))
torch.amax(input, dim, keepdim=False, *, out=None) → Tensor
# 返回对应dim维比较的最大值values
torch.max(input, dim, keepdim=False, *, out=None) → Tensor
# 返回对应dim维比较的最大值和最大值位置索引(values,indices)
Tensor.reshape(*shape) → Tensor
Tensor.view(*shape) → Tensor
# 返回一个特定形状、数据内容相同的张量[9]。由于Tensor.view函数无法使用于不连续的Tensor,因此,在编码时尽可能使用Tensor.reshape(*shape)
Tensor.repeat(*sizes) ——> Tensor
sizes(torch.Size or int)
# 对张量进行重复扩充,sizes参数个数必须大于等于输入张量维度个数[10]。值得注意的是,sizes参数的重复维度顺序从高维向低维(从左到右)
torch.sort(input,dim=-1,descending=False,stable=False,*,out=None)
# A namedtuple of (values, indices) is returned, where the values are the sorted values and indices are the indices of the elements in the original input tensor.
Tensor.contiguous(memory_format=torch.contiguous_format)—>Tensor
# Returns a contiguous in memory tensor containing the same data as self tensor. If
selftensor is already in the specified memory format, this function returns the self tensor.# Numpy
np.save(file, arr, allow_pickle=True, fix_imports=True)
np.load(file, mmap_mode=None, allow_pickle=False, fix_imports=True, encoding=‘ASCII’)
# 写读磁盘多维数组数据的两个主要函数,默认情况下,数组是以未压缩的原始二进制格式保存在拓展名为.npy的文件中[10]
np.savetxt(fname, X, fmt=’%.18e’, delimiter=’ ‘, newline=’\n’, header=’’, footer=’’, comments=’# ‘, encoding=None)
np.loadtxt(fname, dtype=<class ‘float’>, comments=’#’, delimiter=None, converters=None, skiprows=0, usecols=None, unpack=False, ndmin=0, encoding=‘bytes’, max_rows=None)
# 写读一维/二维数组的文本文件,同时可以指定各种分割符、针对特定列的转换器函数、需要跳过的行数等(可用于.txt及.csv文件)
np.where(condition,[x,y,]/)
condition:array_like,bool;x,y:array_like
# 返回符合特定条件的元素与修改不符合条件的元素值(单独condition条件则返回对应索引)
三、PointNet / PointNet++点云语义分割项目代码逐行解析
百度网盘链接:
https://pan.baidu.com/s/1XDQ6qkdm8Hg9r6mUwIKJ3w
模型测试结果可视化:

电力廊道场景应用下的文件结构说明:
① 电力档段激光点云数据存储格式
电力档段激光点云数据文件存储格式为.txt,每个激光点包含七个属性,分别为三维空间坐标XYZ、颜色RGB和要素类别标签,其中属性间利用空格隔开。电力档段激光点云不包含地面点。
② 电力档段要素类别划分
电力档段要素类别划分为七类,分别为电力铁塔、导线、分裂线、绝缘子、跳线、建筑物和植被。通常类别标签定义从0开始连续递增,如[0,6]。
③ Pointnet_Pointnet2_pytorch\data_utils\meta
该文件夹包含anno_paths和class_names两个.txt文件,用于要素类别标签赋值。其中,anno_paths.txt存储电力档段区域的各要素点云集合文件夹名(如Area_0/Annotations),class_names.txt存储电力档段的语义分割要素类别名称。
④ Pointnet_Pointnet2_pytorch\data\GD_Parts\parts
该文件夹存放所有.txt格式电力档段点云数据和由DP_txtDatasetCreator.py生成的S3DIS Dataset文件树的电力档段点云数据。
⑤ Pointnet_Pointnet2_pytorch\data\GD_Parts3D
该文件夹存放由collect_indoor3d_data.py预处理生成的.npy格式的电力档段点云数据。目的在于numpy库的.npy格式数据读取效率高。
⑥ Pointnet_Pointnet2_pytorch\log\sem_seg\日志名\visual
该文件夹存储.txt格式的预测点云数据的类别标签列以及.obj格式的点云数据,.obj格式点云可以利用MeshLab软件可视化。其中,日志名若未设定,则默认为时间戳(如2024-04-06_17-28)。
⑦ Pointnet_Pointnet2_pytorch\log\sem_seg\日志名\checkpoints
该文件夹存放最佳训练模型权重参数,文件后缀名为.pth。
⑧ Pointnet_Pointnet2_pytorch\log\sem_seg\日志名\logs
该文件夹存放训练日志,包含每一个Epoch训练后对验证集数据的精度评价结果等。
⑨Pointnet_Pointnet2_pytorch\TXTpreds
该文件夹存放由predTxtCreator.py生成的类别标签预测后的.txt点云数据,包含三维空间坐标XYZ、颜色RGB和预测类别标签。
注意事项:
1、本百度网盘不包含任何点云数据,仅为项目代码;
2、电力档段激光点云数据文件依照S3DIS Dataset文件树结构转换构建(该过程非必要),目的在于可以直接根据GitHub原项目流程进行训练。若直接对电力档段激光点云数据进行.npy格式转化,考虑要素类别标签的对应即可;
3、对于PointNet / PointNet++语义分割模型应用于大规模、大范围场景的瓶颈,可以通过场景分块或依据场景点云密度和范围大小调节训练超参数(如采样区域大小block_size、球查询半径radius、测试采样网格区域滑动步长stride)以进行训练。
参考资料:
[1] GitHub - yanx27/Pointnet_Pointnet2_pytorch: PointNet and PointNet++ implemented by pytorch (pure python) and on ModelNet, ShapeNet and S3DIS.
[2] PointNet与PointNet++ · 语雀
[3] 基于PyTorch实现PointNet++ - 知乎
[4] 第三章_Pointnet++项目实战 1-项目文件概述_哔哩哔哩_bilibili
[5] PointNet代码详解_pointnet代码解读-CSDN博客
[6] 4 PointNet++点云处理原理_哔哩哔哩_bilibili
[7] 最全PointNet和PointNet++要点梳理总结-CSDN博客
[8] pytorch中Conv1d、Conv2d与Conv3d详解-CSDN博客
[9] PyTorch:view() 与 reshape() 区别详解_pytorch view reshape-CSDN博客
[10] Pytorch中torch.repeat()函数解析-CSDN博客
[11] PyTorch 笔记(11)— Tensor内部存储结构(头信息区 Tensor,存储区 Storage)_tensor.untyped_storage()-CSDN博客
[12] 2.4 Tensor的存储_用tensor存储采集的数据-CSDN博客
PointNet系列发表论文
/*1*/ PointNet
https://arxiv.org/abs/1612.00593
/*2*/ PointNet++
https://proceedings.neurips.cc/paper_files/paper/2017/file/d8bf84be3800d12f74d8b05e9b89836f-Paper.pdf
S3DIS Dataset—实验测试数据
Large Scale Parsing
深度学习点云场景语义分割项目工程化外部库
/**1**/ Argparse 教學 — Python 3.12.2 說明文件(命令行剖析)
/**2**/ 如何使用 Logging 模組 — Python 3.12.2 說明文件(日志记录,检查运行过程中是否有特定的事件发生)
/**3**/ tqdm · PyPI(快速、可拓展的进度条设计)
/**4**/ shutil — 高階檔案操作 — Python 3.12.2 說明文件(对文件和文件集合的高阶操作)
/**5**/ numpy.load — NumPy v1.26 Manual(大数据量运算快速存储读取)
/**6**/ API reference — pandas 2.2.1 documentation (对表格数据的快速读取及清洗处理)
/**7**/ torch — PyTorch 2.2 documentation(Pytorch深度学习框架使用文档)
/**8**/ https://github.com/INTERMT/Awesome-PyTorch-Chinese?tab=readme-ov-file(Pytorch实战教程)









面试)




—— JSON 函数)


)
)
