引言
「语音」作为人工智能的「启蒙钥匙」,不仅率先踏出实验室大门,步入寻常百姓家,也成为了人类与AI初次触电的「桥接技术」。初期,智能语音技术的研究重心落在了语音识别领域,致力于使机器具备理解人类语言的能力。
回溯历史,AT&T贝尔实验室推出的Audrey系统,作为电子计算机领域的先驱,成功辨识了10个英文数字,开启了这一征程。1988年,李开复博士突破性地构建了首个运用隐马尔可夫模型的大词汇量语音识别系统Sphinx。1997年,Dragon NaturallySpeaking的问世,标志着全球首个供消费者使用的连续语音输入系统的商业化。而至2009年,微软Windows 7操作系统内置的语音功能,进一步普及了该技术。
转捩点发生在2011年,iPhone 4S携Siri登场,智能语音技术由此迈入**「互动」**新纪元。同年,谷歌内部启动了Google语音搜索的测试,预告着这一功能即将登上Google的舞台。
从单纯识别到实现互动,这一跨越为人机交互的繁盛奠定了坚实基础。时至今日,语音交互技术已渗透至智能家居、智能驾驶乃至机器人领域,在AI技术迭代的推动下愈发流畅,应用生态呈现多样化。技术层面,各大云服务提供商通过API形式对外开放其AI语音服务,极大促进了开发者基于此的创新应用开发。
近年来,随着大规模预训练模型的兴起,直接在模型层面上的开放与定制化调整日益受到瞩目。开发者能够通过模型训练与微调,深度优化模型性能,进而提升其在特定应用场景下的部署效能,为语音技术的广泛应用开辟了新的路径。
GPT-SoVITS作为一个标志性的语音合成框架,已经为行业树立了高质量语音生成的标准。它通过深度学习模型,尤其是基于WaveNet和Transformer架构的创新,实现了语音自然度和真实感的显著提升,为用户带来了接近真人的听觉体验,在上线后便获得极高热度,仅需提供 5 秒语音样本,便可收获相似度达到 80%~95% 的克隆语音。
然而,随着技术的不断迭代与需求的日益多元化,ChatTTS作为后起之秀,在继承SoVITS等前辈优点的同时,进一步聚焦于对话场景的优化与个性化表达,能实现更加流畅、连贯及富含情感色彩的语音输出,甚至包括语气词、笑声。
下面就让我们从部署开始,深入分析ChatTTS在实际应用中的场景和特点。
腾讯云高性能应用服务 HAI
本次用到的产品是腾讯云高性能应用服务 HAI,这里也稍微介绍一下。
高性能应用服务(Hyper Application Inventor,HAI)是一款面向AI、科学计算的GPU应用服务产品,提供即插即用的澎湃算力与常见环境。助力中小企业及开发者快速部署LLM、AI作画、数据科学等高性能应用,原生集成配套的开发工具与组件,大幅提高应用层的开发生产效率。
其实一开始,我以为这个只是普通的GPU服务器而已,但是看完我才发现,高性能应用服务HAI远不止于此。它不仅仅是一个配备了强大GPU硬件的基础资源平台,更是集成了诸多高级功能和服务的一站式解决方案。它内置了多样化人工智能工具和服务,如深度学习框架、模型训练与优化套件、以及一键式模型部署能力,极大降低了技术门槛,让即便是AI初学者也能迅速上手,将创意转化为现实。
现临近618特惠,领券后即可低价畅享25小时的GPU基础型算力,实话实说,我真冲了,活动入口也放在这里,有兴趣的小伙伴可以尝试一下:https://mc.tencent.com/uMv5GPOh,也可以点击我的链接获取更多优惠内容。
基于腾讯云高性能应用服务 HAI部署ChatTTS
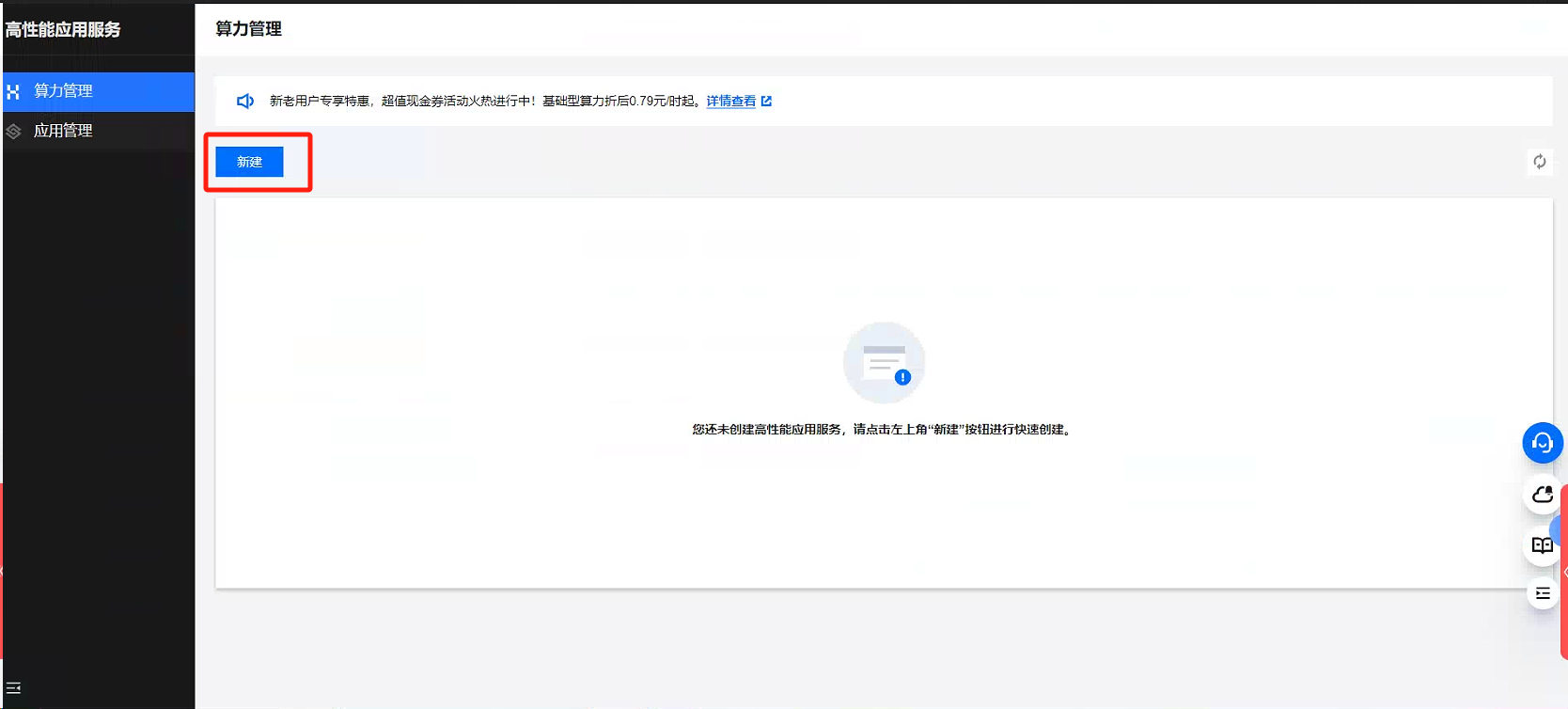
在购买HAI后,点击进入控制台,新建应用。
此处分别选择【基础环境】,地域为【上海】,算力方案为GPU【基础型】。
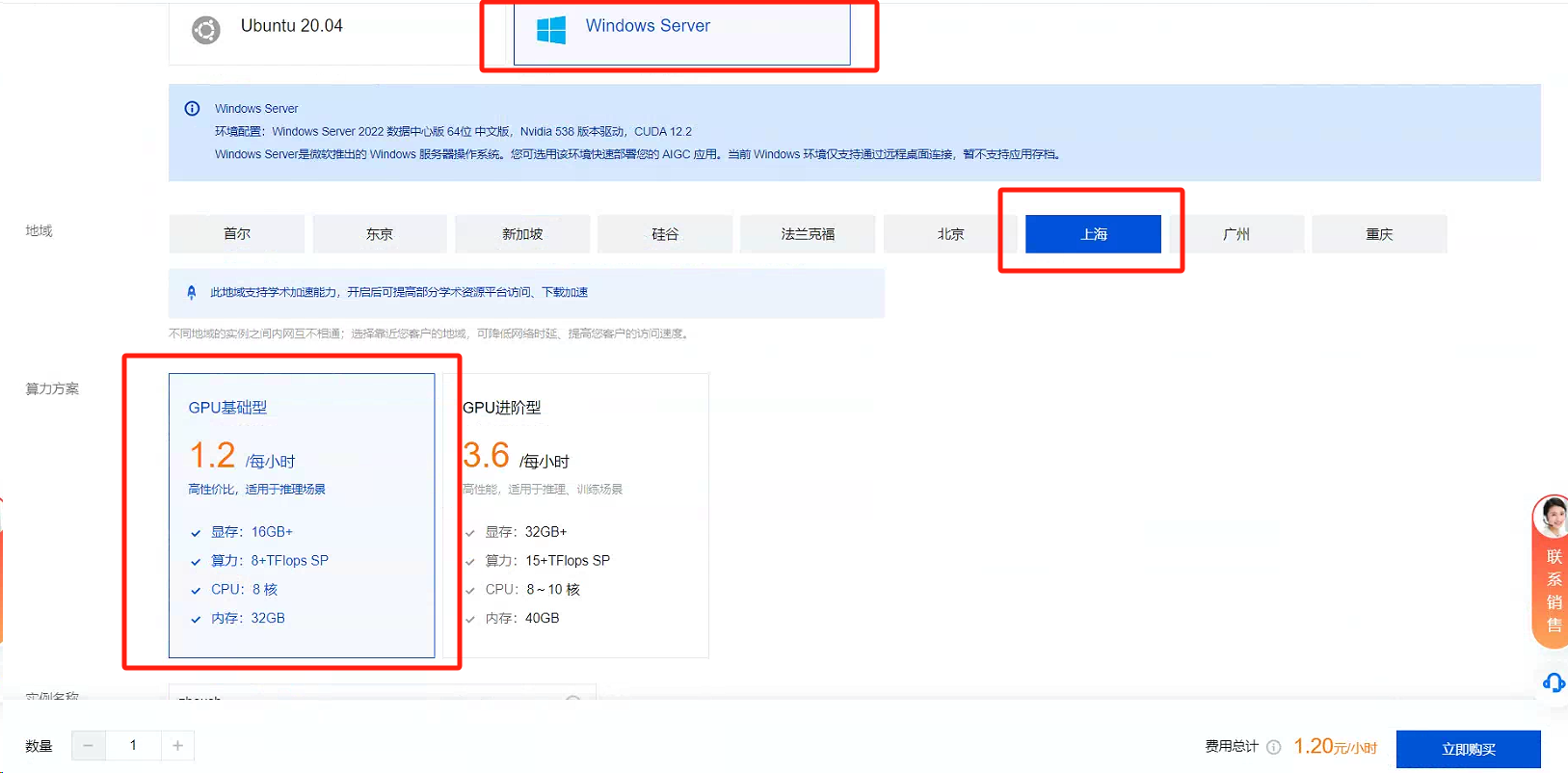
设置合适的实例名,勾选协议,点击提交即可。
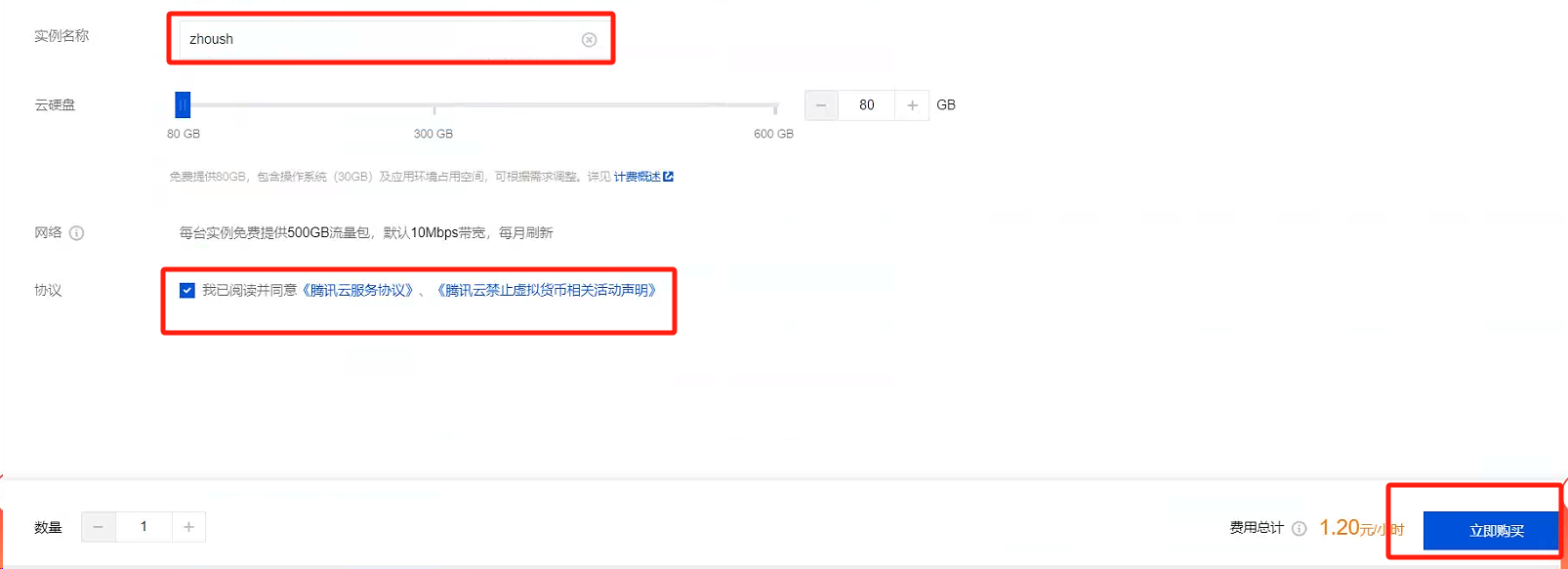
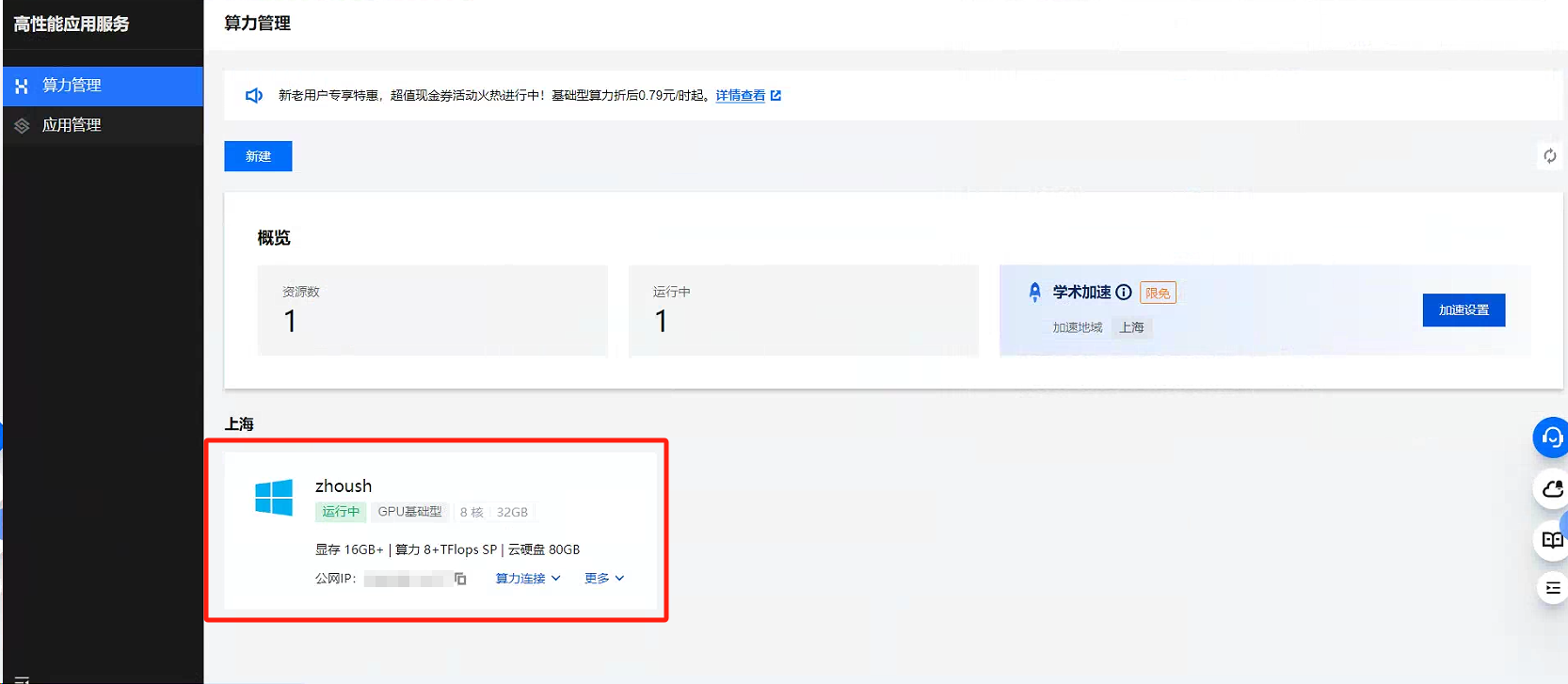
等待几分钟,可以看到服务器已经创建完毕了。
点击算力链接—远程链接,或者直接win+R,输入mstsc,链接该服务器。
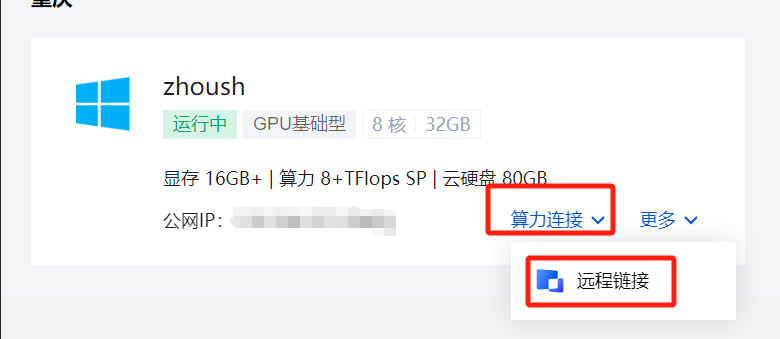
账号密码需要到站内信中获取。
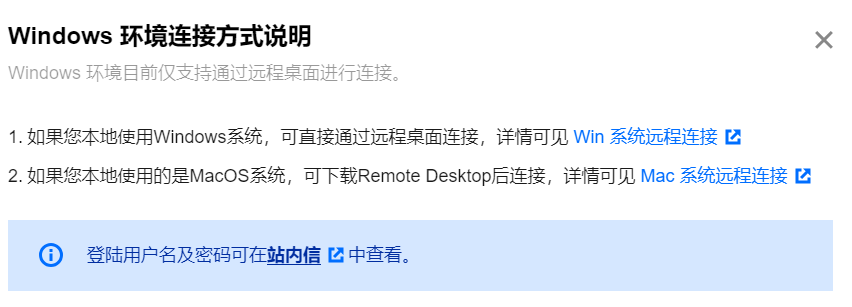
下面我们就正式开始ChatTTS的安装部署了,这里周周也准备了一键包,部署嫌麻烦的可以直接下载一键包使用。
链接:https://pan.baidu.com/s/1yVtXY3uOYDUUuIL_OcjAHg
提取码:f07u
首先是准备安装Python 和 git环境,python需要 3.9+ 版本,大家进入官网选择对应版本即可。
然后安装下载git环境。
当以上两个安装完成以后,下载chatTTS-ui
解压之后在根目录下输入CMD进入终端,然后依次执行下面的安装命令:
创建虚拟环境
python -m venv venv
激活创建好的Python虚拟环境,如需关闭可运行 deactivate 命令
.\venv\scripts\activate
开始安装所有指定的软件包及其版本
pip install -r requirements.txt
下载完成后,这里我们检查一下HAI中的CUDA驱动是否开启。在cmd中执行如下命令:
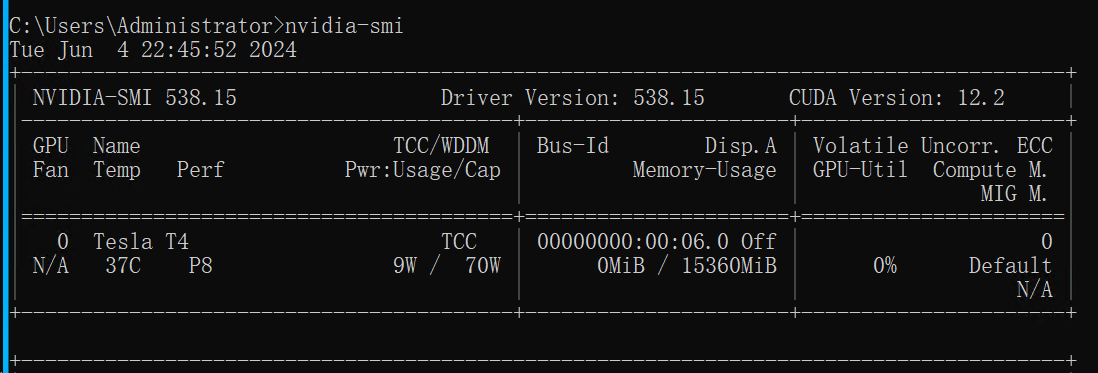
nvidia-smi
看到类似以下结果,则说明已成功安装 NVIDIA 驱动程序,所以在HAI里面其实是默认开启的,无需关心驱动问题。
最后执行 python app.py 启动,默认从 modelscope 魔塔下载模型,将自动打开浏览器窗口。
python app.py

这里需要注意的是,源码部署启动后,会先从 modelscope下载模型,但modelscope缺少 spk_stat.pt ,会报错,需要自己手动下载后将该文件复制到 项目目录/models/pzc163/chatTTS/asset/ 文件夹内 。点击下载
之后访问生成的地址就可以了。
而对于离线包的部署就简单很多,打开我上面分享的链接,可以看到如下两个安装包:

其中,上面的为魔改后的强化版本,下面为基础版本。
我们这边先下载基础版本,解压密码为harryai,解压后如下图所示:
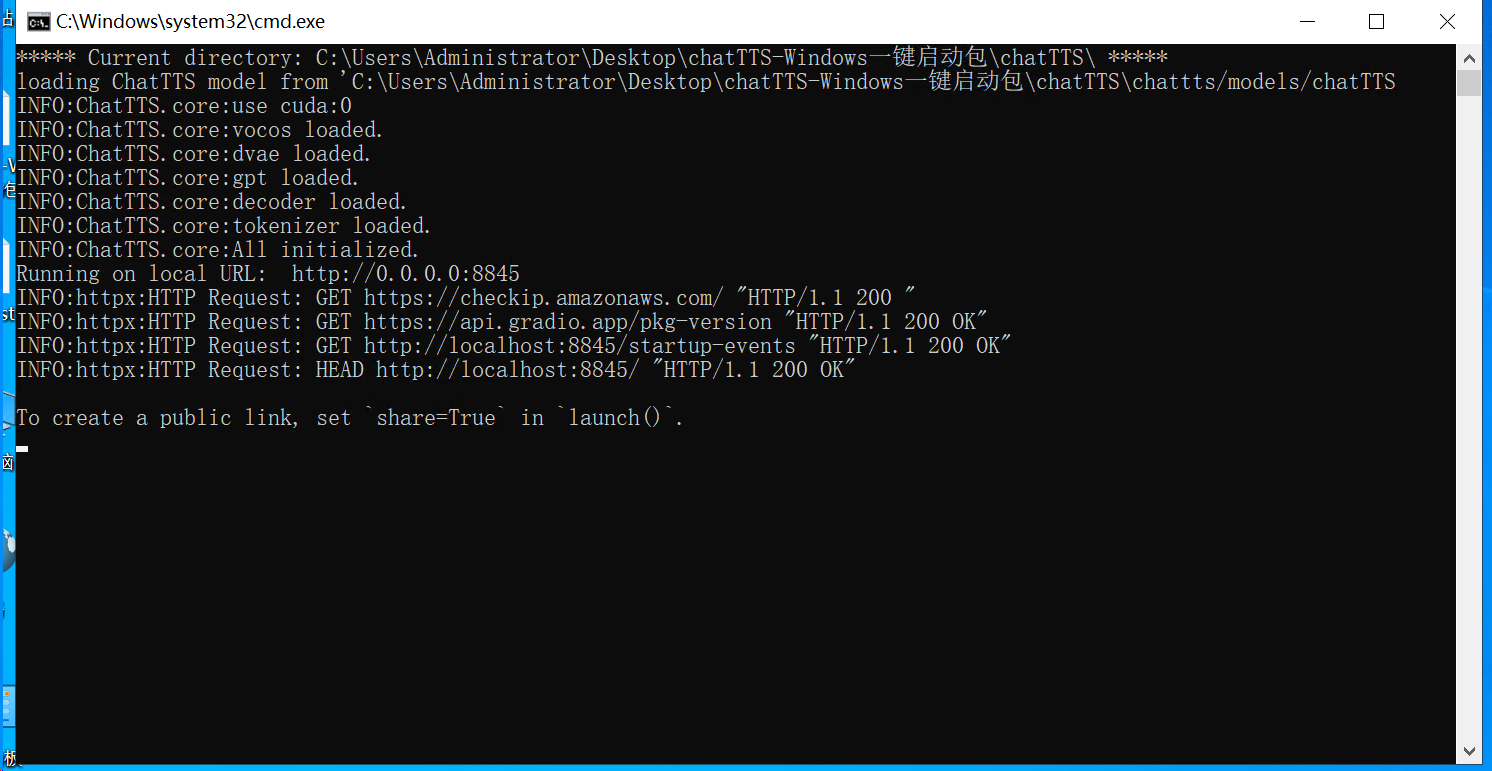
点击启动服务,开始执行:
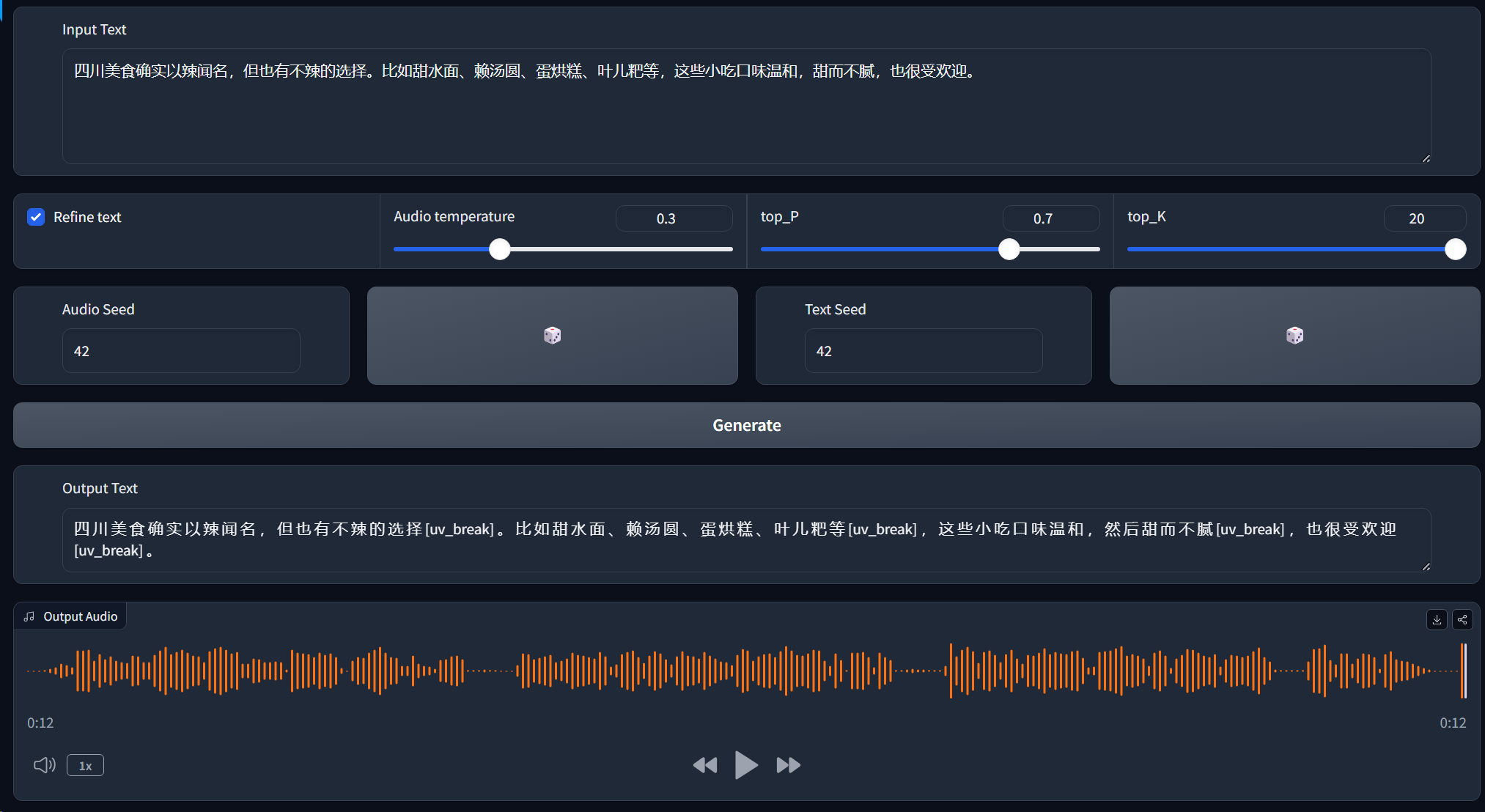
随后会自动打开网页如下:
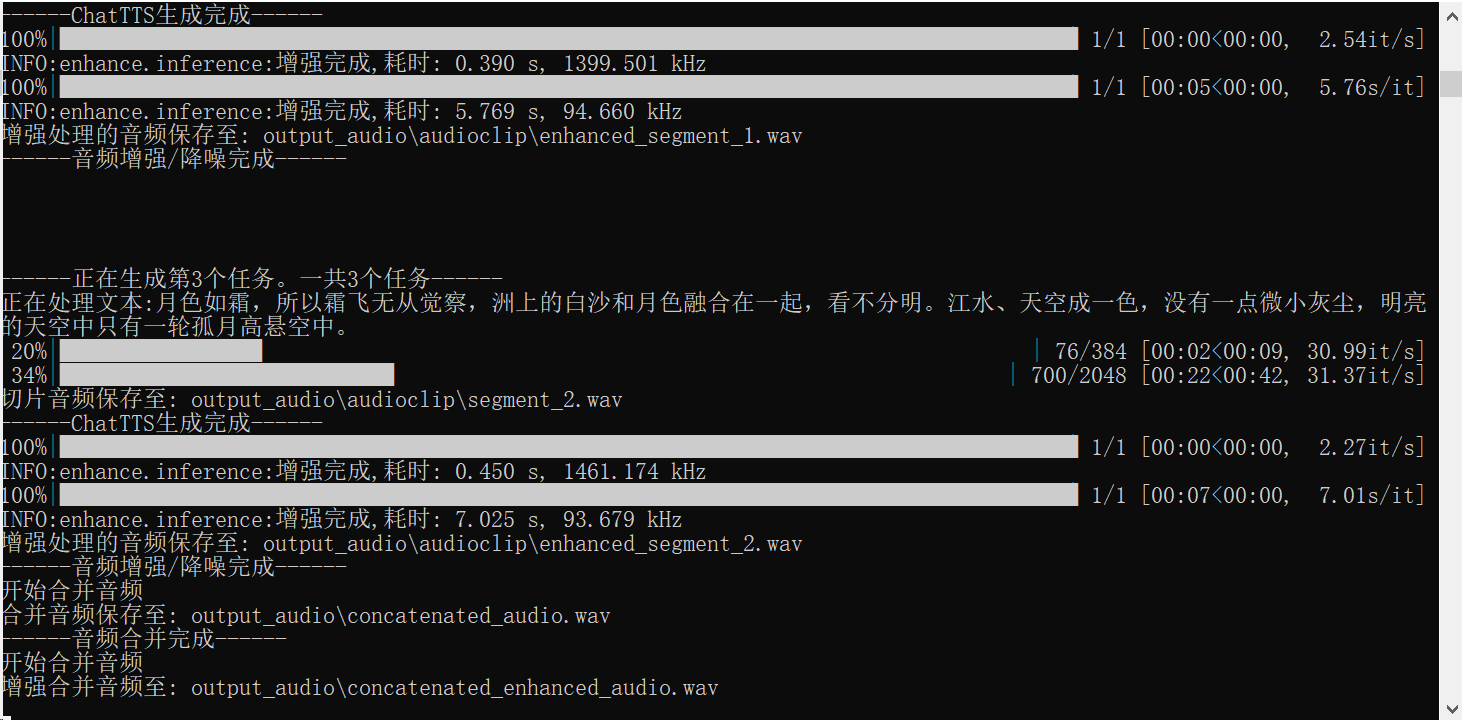
在生成时,我们也可以在命令栏查看进度。
【注意】:此处需要把HAI中的windows声音打开才可听到效果。
对比GPT-SoVITS ,ChatTTS的语义连续性和个人情感明显表现的更加出色。
但是同时,基础版的一些缺点也进而暴露出来,尤其是在追求极致体验的项目中,音质偶尔的不清晰以及长时间语音合成后音色的不稳定性,成为了不容忽视的短板。
因此,开源大佬们又整出了这个增强版!在对chatTTS生成的音质增强的同时进一步降噪,并且增加了批量txt处理和长文本处理能力。
解压后如下所示:
点击启动器后稍等一段时间,默认打开如下界面:
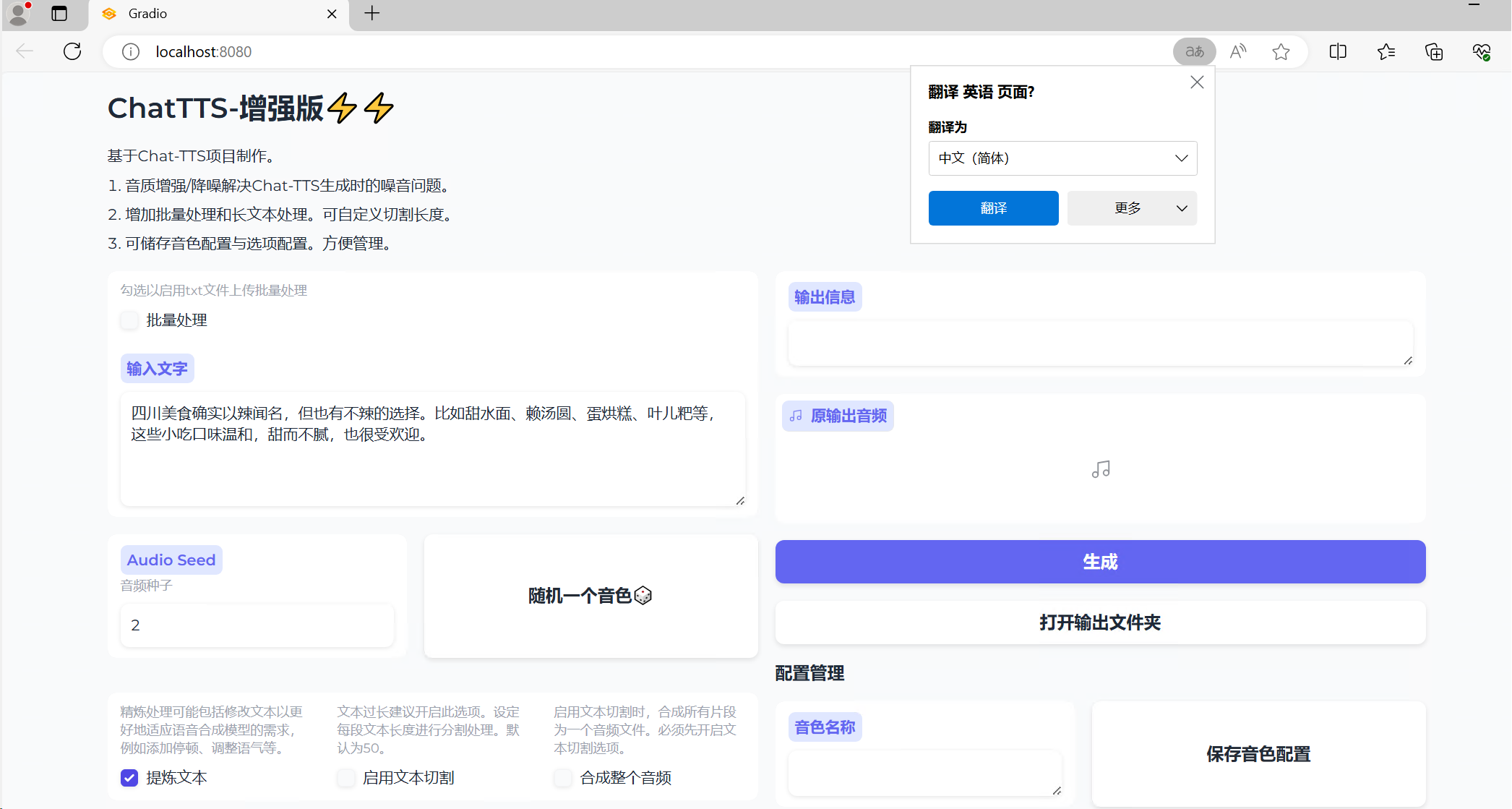
对比普通版本,增强版的优势也是比较明显的。比如我在基础版中输入的春江花月夜,由于字数较长,其语音生成到最后有一些汉字已经无法正常发音了,但在增强版中,我们可以选择文本切割。
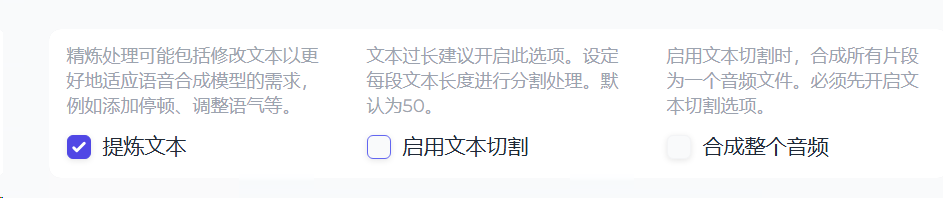
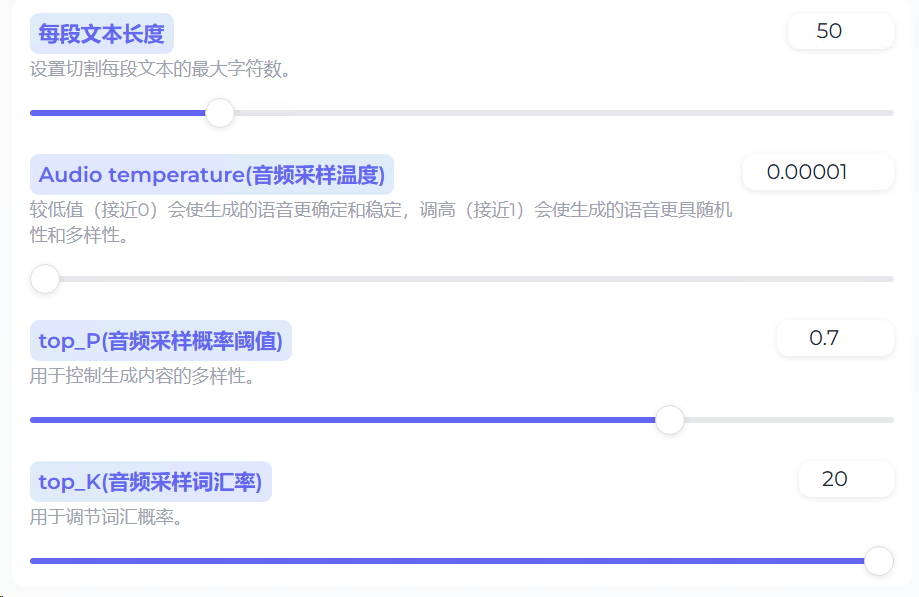
下面可以设定对每段文本分割的字数。
同时勾选分割文本和合成语音后,点击生成。
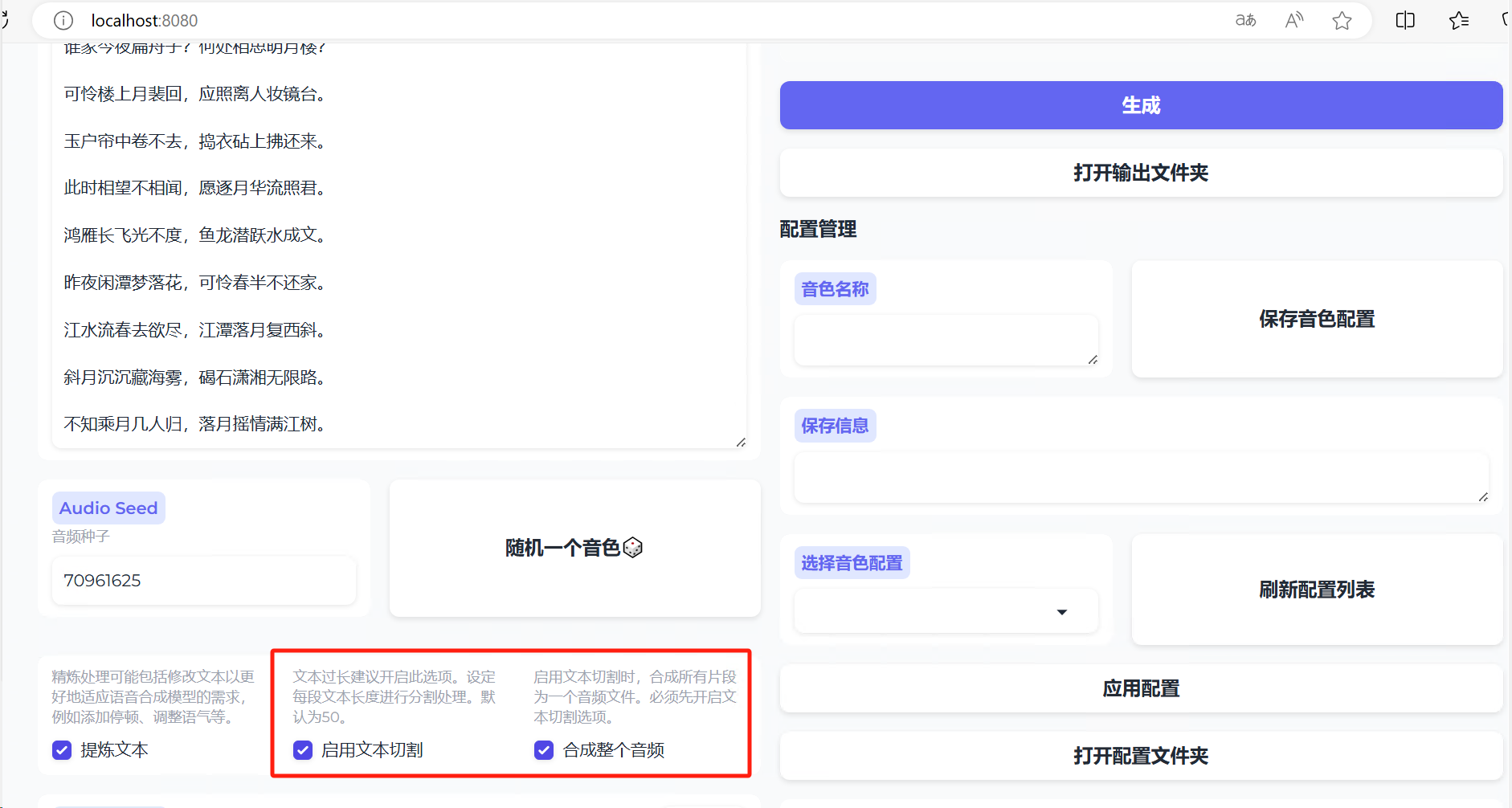
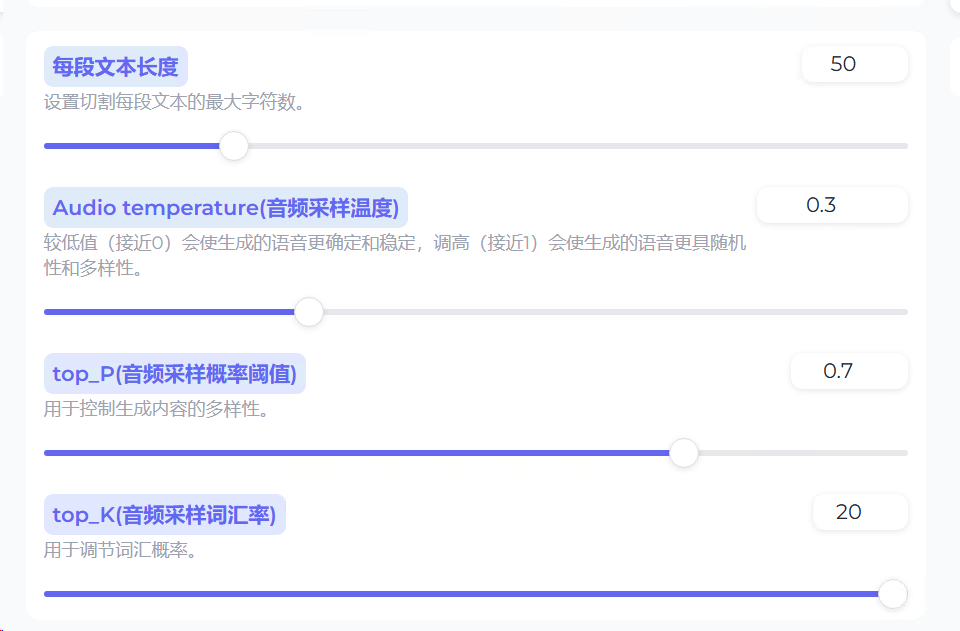
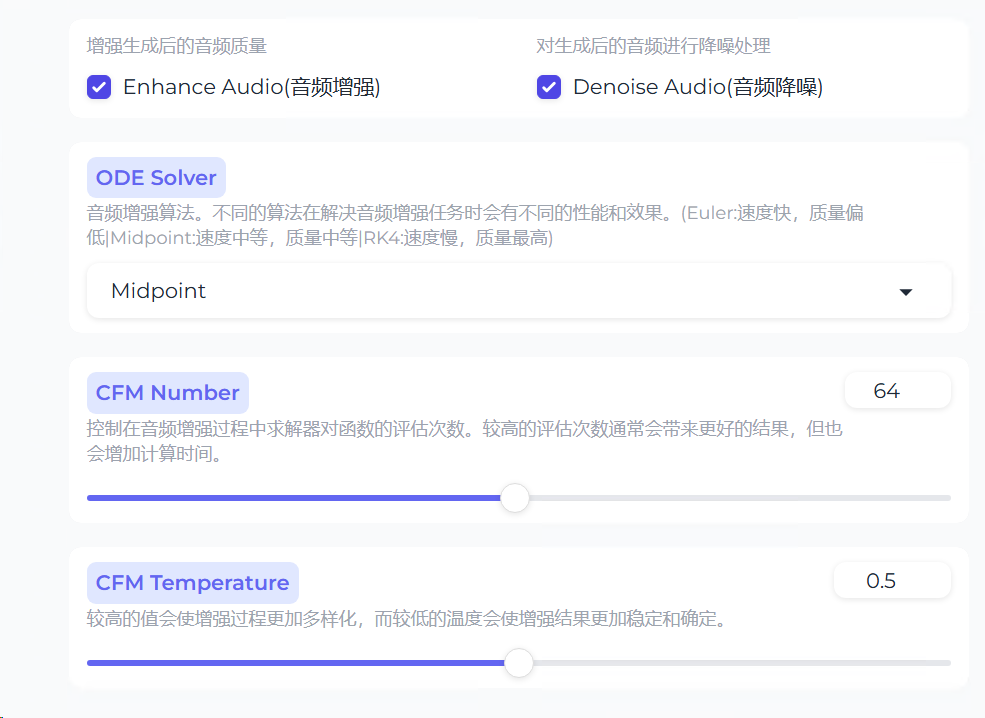
此时的效果就比基础版好一些了,但是还是会出现音色变化的情况。所以这时,我们将音频采样温度调整为最小,让其生成的语音音色更加稳定。同时,开启下面的增强和降噪算法。
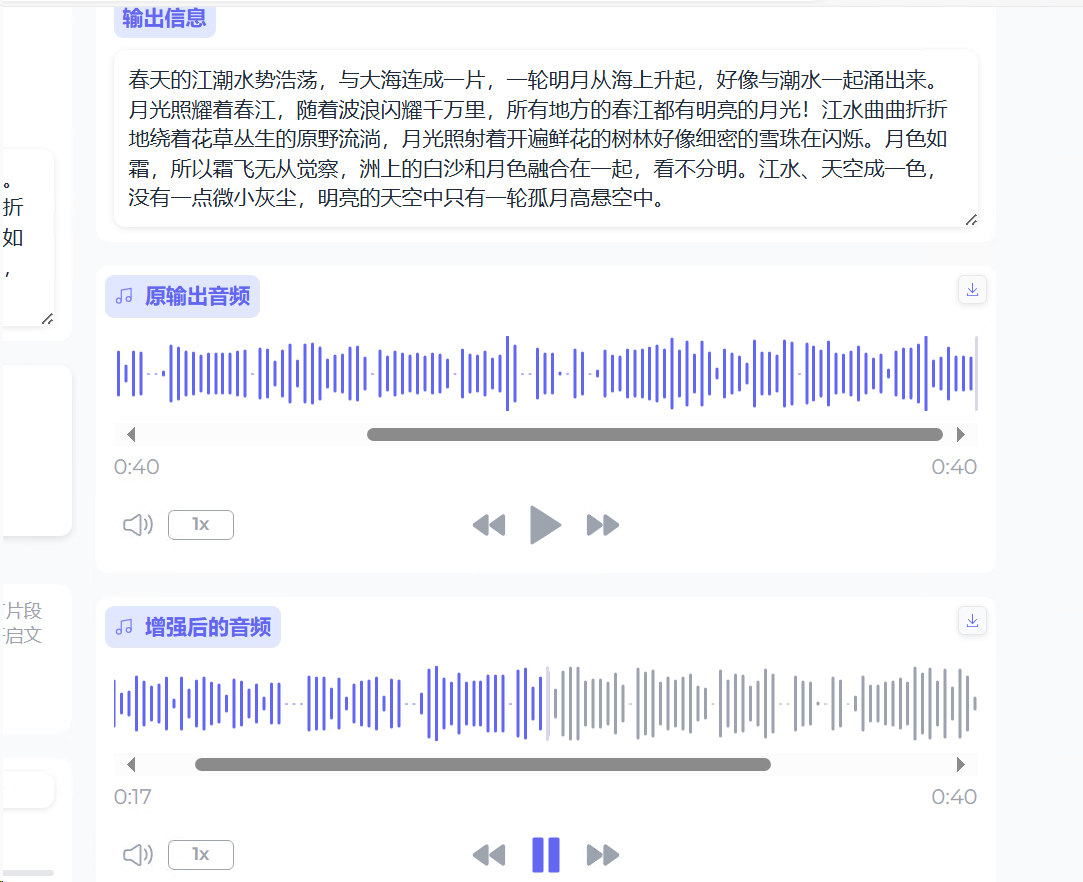
大概等待4分钟,此时聆听效果,会极其接近真人的朗诵发音。(这里又换了一个素材,之前的诗句确实还是太长了,杂音很大)
具体视频效果如下:
腾讯云HAI部署chatTTS增强版效果
那么至此,基于腾讯云高性能应用服务 HAI部署ChatTTS的步骤就结束了。按照目前来看,其实GPT-SoVITS和**ChatTTS,**也还是各有所长的,利用GPT-SoVITS可以训练和生成更加满足个人需求的语音,比如克隆自己的声音,然后用自己的声音唱歌;而ChatTTS的优势则在于其生成的语音极其真实,适合承担如虚拟助理、在线客服、语音聊天机器人这类的职责。
目前ChatTTS其实也没有开源很久,在未来还会做更多优化的,这方面还是可以期待一下。
结尾
站在技术发展的十字路口,ChatTTS与GPT-SoVITS不仅是独立存在的技术创新,更是相互启发、共同推动语音合成领域进步的重要力量。ChatTTS的持续优化和未来的开放性增强,预示着更多的可能性和更广泛的应用空间。
展望未来,我们有理由相信,随着人工智能技术的不断成熟,特别是深度学习模型的进一步优化,以及云计算能力的提升,ChatTTS将在个性化定制、多语言支持、实时交互体验等方面实现质的飞跃。它不仅能够更好地服务于现有的应用场景,还将解锁更多前所未有的使用场景,如沉浸式虚拟现实体验、跨文化交流辅助工具、甚至是残障人士的无障碍沟通解决方案等。
此外,开源精神的核心在于共享与协作,ChatTTS的开源之路无疑将汇聚全球智慧,加速技术创新周期。这不仅仅是技术层面的进步,更是对社会生活方式和工作效率带来深远影响的一场变革。让我们一同期待,在不远的将来,ChatTTS能够携手GPT-SoVITS以及其他同类技术,共同开启一个语音合成技术更加辉煌的新时代,让人工智能的声音温暖并丰富每一个人的生活。