
ALOHA YAY 演示视频-智能佳
斯坦福的ALOHA家务机器人团队,发布了最新研究成果—Yell At Your Robot(简称YAY),有了它,机器人的“翻车”动作,只要喊句话就能纠正了!

而且机器人可以随着人类的喊话动态提升动作水平、即时调整策略,并根据反馈持续自我改进。
比如在这个场景中,机器人没能完成系统设定的“把海绵放入袋子”的任务。
这时研究者直接朝它喊话,“用海绵把袋子撑得再开一些”,之后就一下子成功了。而且,这些纠正的指令还会被系统记录下来,成为训练数据,用于进一步提高机器人的后续表现。


YAYRobot“呀呀机器人”和Aloha系列机器人一样,也开源了!感恩!
了解更多资讯请参阅项目网站:
项目地址:Yell At Your Robot 🗣️ Improving On-the-Fly from Language Corrections
论文地址:https://arxiv.org/abs/2403.12910
开源代码地址:GitHub - yay-robot/yay_robot: PyTorch implementation of YAY Robot
智能佳机器人知识社区:智能佳机器人知识社区_北京智能佳科技有限公司
那么,用喊话调整的机器人,都能实现什么样的动作呢?
喊话就能发号施令:
利用YAY技术调教后,机器人以更高的成功率挑战了物品装袋、水果混合和洗盘子这三项复杂任务。
这三种任务的特点是都需要两只手分别完成不同的动作,其中一只手要稳定地拿住容器并根据需要调整姿态,另一只手则需要准确定位目标位置并完成指令,而且过程中还涉及海绵这种软性物体,拿捏的力度也是一门学问。
以物品装袋这个任务为例,机器人在全自主执行的过程中会遇到各种各样的困难,但通过喊话就能见招拆招。
只见机器人在将装袋的过程中不小心把海绵掉落了下来,然后便无法再次捡起。
这时,开发者直接朝它喊话,口令就是简单的“往我这边挪一挪,然后往左”。
当按照指令做出动作后,第一次还是没成功,但机器人记住了“往左”这个指令,再次左移之后便成功把海绵捡起来了。

但紧接着就出现了新的困难—袋子的口被卡住了。
这时只要告诉它再把袋子打开一点点,机器人就“心领神会”,调整出了一系列后续动作,并最终成功完成任务。

而且不只是能纠正错误,任务的细节也能通过喊话实时调整,比如在装糖的任务中,开发者觉得机器人拿的糖有点多了,只要喊出“少一点”,机器人就会将一部分糖果倒回盒子。
ALOHA YAY糖果混合包装-智能佳

进一步地,人类发出的这些指令还会被系统记录并用作微调,以提高机器人的后续表现。
比如在刷盘子这项任务中,经过微调之后的机器人清洁力度更强,范围也变大了。
ALOHA YAY盘子清洁-智能佳

统计数据表明,机器人在经历这种微调之后,平均任务成功率提高了20%,如果继续加入喊话指令还能继续提高。
 而且这样的微调指令过程可以迭代进行,每迭代一次机器人的表现都能有所提升。
而且这样的微调指令过程可以迭代进行,每迭代一次机器人的表现都能有所提升。

那么,YAY具体是如何实现的呢?
人类教诲“铭记在心”
架构上,整个YAY系统主要由高级策略和低级策略这两个部分组成。
其中高级策略负责生成指导低级策略的语言指令,低级策略则用于执行具体动作。

具体来说,高级策略将摄像头捕捉到的视觉信息编码,与相关知识结合,然后由Transformer生成包含当前动作描述、未来动作预测等内容的指令。
而低级策略接收到语言指令后,会解析这些指令中的关键词,并映射到机器人关节的目标位置或运动轨迹。
同时,YAY系统引入了实时的语言纠正机制,人类的口头命令优先级最高,经识别后,直接传递给低级策略用于执行。
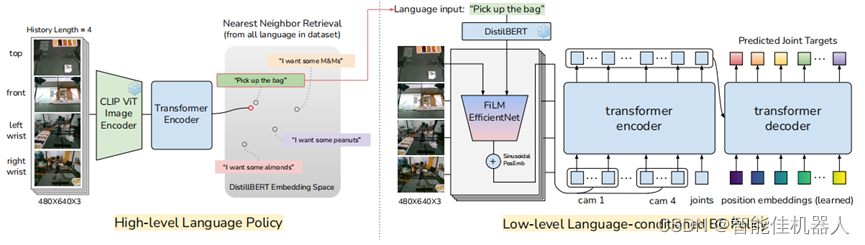
且在这个过程中命令会被系统记录并用于微调高级策略,通过学习人类提供的纠正性反馈,逐渐减少对即时口头纠正的依赖,从而提高长期任务的自主成功率。
在完成基础训练并已经在真实环境中部署后,系统仍然可以继续收集指令信息,不断地从反馈中学习并进行自我改进。
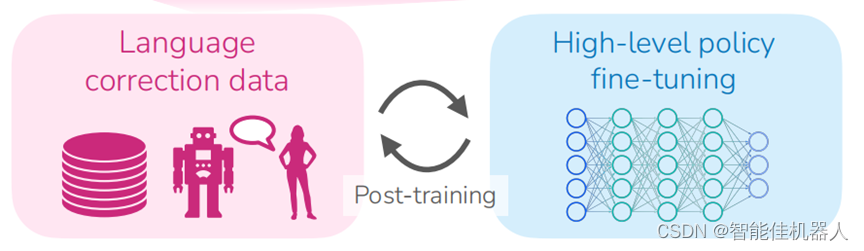
一句话介绍:
对于真实的长序列操作任务,该工作提出了YAYRobot方案,该方案可以使机器人能够(a)实时融入语言矫正,(b)并根据这些反馈持续改进规划策略,以实现在真机任务中的持续改进,大幅提高最终任务成功率。
一段话总结:
面对真实世界中,长期操作任务仍然会面临高失败率的挑战。比如说,让一只机械臂夹住很薄的速封袋,另外一只机械臂协助打开这个袋子,然后再让这只机械臂去夹住一个小铲子,去盒子里取一堆坚果,并将坚果转运到速封袋中,根据不同的指令去多次转运不同的坚果。这种任务光描述就得好几行,如果让机器人去学习,虽然听起来挺难的,实际上做起来更难了~
对于这样的任务,该系统提供了一个有意思的解决方案:YAYRobot(呀呀Robot)。该方案本质上是一个分层策略,上层策略根据观测obs的连续四帧图片,输出一个语言目标L_H;然后底层策略根据这个四帧图片+目标L_H,输出底层的动作(关节目标)。
网络的训练都是有监督训练的模仿学习,但是在实际部署时,如果机器人操作失败了,可以有人在旁边提供语言指导,这时候会把高层策略的目标L_H屏蔽掉,直接采用人的目标L_user。最后,把矫正过的osb->L_H数据对加入矫正数据集中,混合原始数据集,后训练高层策略,当高层策略在线更新后,自主成功率会有显著提升(这个值很奇怪,论文的intro和conclusion举的例子都不一样)。
和之前方案的区别:
LLM+技能库:用LLM的in-context learning和推理能力,输入当前任务+技能库+示例,输出当前任务下,该调用什么技能,实现“组合泛化”。这类方案在23年3月到8月,应该都比较流行,但现在基本上都过时了。因为LLM或者VLM并不能对当前构型的机器人和技能库的实际效果有先验知识,它的组合只能是现有示例的组合泛化。
语言矫正+LLM+Robot:这个方案也不是本文最早提出来的,23年的朱玉可团队提出的OLAF方法,用口语矫正+GPT4事后标记+数据合成+网络后训练。其实这两篇工作挺相似的,都有Dagger的范式(dagger,指的是数据集聚合,边模仿,边交互,边更新。具体可以看海洋:模仿学习:DAgger(Dataset Aggregation))。和OLAF,RT-H的主要区别应该是yay输入输出更灵活,更加实时。
Aloha:基于示教的模仿学习,算法是ACT,50个左右的轨迹样本,就能学会一个技能,但也只有单技能。
方案细节介绍

这是文章的主图,可以看看右上角的细节。机器人先自己用高层策略产生语言目标,然后在4200步的时候,人给了一个矫正,然后继续执行。这些矫正数据+原始数据后训练高层策略,成功率可以从原始的20%不断提升,三次迭代能提升到65%。

上图YAY Robot系统概述,我们在一个分层设置中运作,高层策略生成语言指令,供低层策略执行相应的技能。在部署过程中,人类可以通过纠正性语言命令进行干预,临时覆盖高层策略,并直接影响低层策略以进行即时适应然后利用这些干预来微调高层策略,改善其未来的性能。
这张图主要是看输入输出关系:高层的输入是图片连续帧,输出是语言;底层输入是图+语言+机器人本体状态,输出是目标关节。而人在外部的干涉,是直接替代高层语言目标。
关于三次更新,都是有监督的模仿学习。
对于这种长时序任务,强化不好建模么?明明已经建立好了MDP了,但却没有给Reward,RLer表示很可惜~
不用RL,就没法用次优数据,所以作者过滤掉了那些不好的样本,才能更好的进行模仿学习。
数据采集细节:
数据采集的代价,是影响整个方案落地价值的关键中的关键。
作者在正文中,默认采集了对应任务中全空间的动作轨迹。为了让语言目标和底层动作对应,先让示教者先对着麦克风,说出下一步该做什么,然后用Whisper转成文本,再示教,这样目标和控制就能对应起来了。
在附录中,作者详细贴出了训练数据:
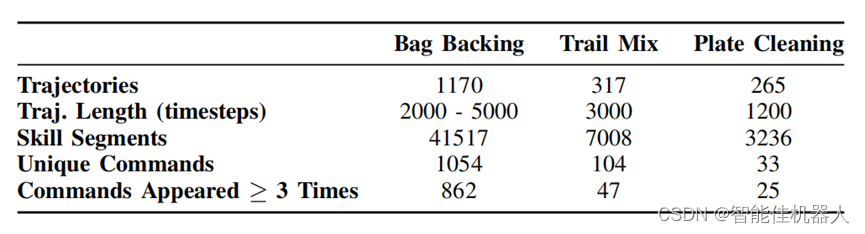
概述了不同任务中轨迹数量、轨迹长度、语言注释技能段数以及语言命令指标。“UniqueCommands”表示数据集中独特语言字符串的数量。
研究人员在论文中称,为了提高机器人操作任务的性能,YAY Robot系统每次要进行 20 次试验,还对子任务的成功率进行测量。“我们的代码实现了采集数据与处理这一过程的自动化,并且已经开源。”
在线微调数据:
Post-Training Dataset:对于高级策略微调,我们使用上述USB麦克风设备收集仅包含语言干预数据在Table IV中,我们描述了在进行2-3次后训练迭代后收集的聚合数据集。与基础数据集相比,后训练数据集具有显著较少的技能段落
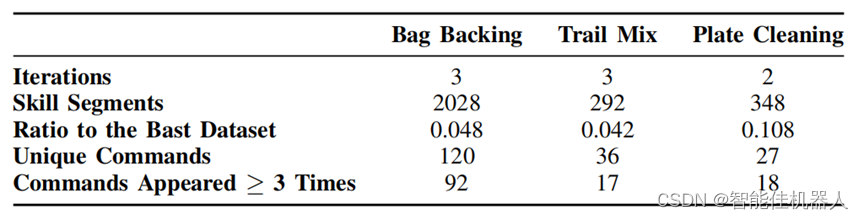
每个任务的训练后数据集中技能段和语言命令数量的总结。训练后数据集明显小于基础数据集--技能段的数量为基础数据集的4%-11%。
更令我好奇的是,真机矫正的时候,需要喊多少次。
好奇点:
如果有了原本数据集+矫正数据集,重新完整训练,而不是采用dagger范式的post-training,性能会不会有区别?
在自主交互中,高层策略的输入是连续帧图片,它真的能映射出准确的goal么?如果不指定一个最终目标的话。我很好奇,那一堆奇奇怪怪的图片,高层策略真的能给出合理的goal。如果能拟合,应该也是只能针对特定任务。
如果用的不是LCBC,而是LCRL,会不会样本效率更高?
论文里说,GPT4V处理类似任务时,会犯一些错误,但我自己没有细看。我个人感觉,模型训练的代价比较高,调api可能更加适合我这种个人玩家。
总结:
这是一篇非常有意思的工作,将人的语言矫正很好的嵌入到了机器人的长序列任务决策中,并且实现了持续学习,效果提升比较明显,对于机器人落地有显著的意义。
我认为语言矫正是一条合理的路,我也希望做一个“听话”的机器人。但是,我个人认为,这种语言矫正的频次不能太高,超过三次的矫正,基本上就会让人失去耐心,超过十次看不到提高,人就会觉得这个机器人脑子不行。
所以我现在非常好奇,具体需要多少样本数据。
最后,基础技能+通用大模型+语言矫正+在线交互+少样本持续学习+多任务,应该是一个值得探索的路。
让我们期待有更多的开发者在ALOHA基础上实现新的突破!!!
资讯参考资料:
斯坦福团队新作:喊话就能指导机器人,任务成功率暴增,网友:特斯拉搞快点
斯坦福大学ALOHA家务机器人团队发布了最新研究成果:语言交互式操作-CSDN博客
百度安全验证
Aloha团队新作-YAYRobot(呀呀Robot)-Yell At Your Robot-对你的机器人大喊大叫:通过语言在线纠正动作 - 知乎
智能佳Mobile ALOHA2 机械臂 完整套装 斯坦福ALOHA 深度学习 家政服务ROS开源实验平台 高端复合机器人 ALOHA 2机械臂
https://item.jd.com/10097978503518.html?sdx=ehi-lLxFuZiE6JnIaIRVi84lsDOUCQMrsmpMs6hCZZH7cJjRK5xe4H3hrEDlUQ
)










)


)



