本文来源公众号“集智书童”,仅用于学术分享,侵权删,干货满满。
原文链接:YOLOv10开源|清华用端到端YOLOv10在速度精度上都生吃YOLOv8和YOLOv9

在过去几年中,YOLO系列模型已成为实时目标检测领域的主导范式,这得益于它们在计算成本和检测性能之间的有效平衡。研究行人探索了YOLOs的架构设计、优化目标、数据增强策略等,取得了显著的进展。然而,对非最大值抑制(NMS)的后处理依赖阻碍了YOLOs的端到端部署,并不利影响推理延迟。此外,YOLOs中各种组件的设计缺乏全面彻底的检查,导致明显的计算冗余并限制了模型的能力。这导致了次优的效率,同时存在相当大的性能提升潜力。在这项工作中,作者从后处理和模型架构两方面进一步推进了YOLOs的性能效率边界。
为此,作者首先提出了无需NMS训练的YOLOs的一致性双重分配,这同时带来了有竞争力的性能和低推理延迟。此外,作者引入了针对YOLOs的整体效率精度驱动模型设计策略。作者从效率和精度角度全面优化了YOLOs的各种组件,大大减少了计算开销并增强了能力。作者努力的成果是新一代的实时端到端目标检测YOLO系列模型,命名为YOLOv10。广泛的实验表明,YOLOv10在各种模型规模上均实现了最先进的性能和效率。例如,YOLOv10-S在COCO上的类似AP下比RT-DETR-R18快1.8倍,同时享受2.8倍更少的参数和FLOPs。与YOLOv9-C相比,YOLOv10-B在相同性能下延迟减少了46%,参数减少了25%。
代码:https://github.com/THU-MIG/yolov10。
1. 引言
实时目标检测一直是计算机视觉研究领域的一个重点,旨在在低延迟下准确预测图像中物体的类别和位置。它被广泛应用于各种实际应用中,包括自动驾驶,机器人导航,物体跟踪等。近年来,研究行人一直致力于设计基于CNN的目标检测器以实现实时检测。其中,YOLOs因其性能和效率之间的巧妙平衡而越来越受欢迎。YOLOs的检测流程包括两部分:模型前向过程和NMS后处理。然而,这两者仍存在不足,导致次优的准确度-延迟边界。
具体来说,YOLO通常在训练过程中采用一对多的标签分配策略,其中一个 GT 物体对应于多个阳性样本。尽管这种方法取得了优越的性能,但它需要在推理过程中使用NMS来选择最佳的阳性预测。这降低了推理速度,并使性能对NMS的超参数敏感,从而阻碍了YOLO实现最优的端到端部署。解决这个问题的一条途径是采用最近引入的端到端DETR架构。例如,RT-DETR提出了一种有效的混合编码器和非确定性最小 Query 选择,将DETR推向了实时应用领域。然而,部署DETR的固有复杂性阻碍了它在准确性和速度之间达到最优平衡的能力。另一条途径是探索基于CNN的检测器的端到端检测,这通常利用一对一的分配策略来抑制冗余预测。然而,它们通常引入额外的推理开销或达到次优性能。
此外,模型架构设计对于YOLO来说仍然是一个基本挑战,它在准确性和速度上表现出重要影响。为了实现更高效和有效的模型架构,研究行人探索了不同的设计策略。为加强特征提取能力,提出了各种主要计算单元作为主干,包括DarkNet,CSPNet,EfficientRep和ELAN等。对于特征融合部分,研究了PAN,BiC,GD和RepGFPN等,以增强多尺度特征融合。此外,还研究了模型缩放策略和重参化技术。尽管这些努力取得了显著的进展,但从效率和准确性的角度来看,对YOLO中各个组件的全面检查仍然缺乏。因此,YOLO中仍然存在相当大的计算冗余,导致参数使用效率低下和次优效率。此外,由此产生的受限模型能力也导致了性能不佳,为准确性的提升留下了很大的空间。
在这项工作中,作者旨在解决这些问题,并进一步推进YOLO在准确性与速度边界上的发展。作者针对检测流程中的后处理和模型架构。为此,作者首先通过提出一种一致的二元分配策略来解决后处理中的冗余预测问题,该策略用于无需NMS的YOLO,具有双重标签分配和一致匹配度量。它允许模型在训练期间享受丰富且和谐的监督,同时在推理过程中省去NMS,以实现高效竞争力。其次,作者提出了一个整体效率-准确性驱动的模型设计策略,通过对YOLO中各个组件的全面检查来实现模型架构。为了提高效率,作者提出了轻量级分类头、空间通道解耦降采样和排名引导的块设计,以减少表现出的计算冗余并实现更高效的架构。对于准确性,作者探索了大型核卷积,并提出了有效的部分自注意力模块来增强模型能力,在低成本下挖掘性能提升的潜力。
基于这些方法,作者成功实现了一系列不同模型规模的实时端到端检测器的新家族,即YOLOv10-N / S / M / B / L / X。在标准的目标检测基准测试上的大量实验,例如COCO,证明了YOLOv10可以在各种模型规模上显著超越之前的最佳模型,在计算精度权衡方面表现出色。
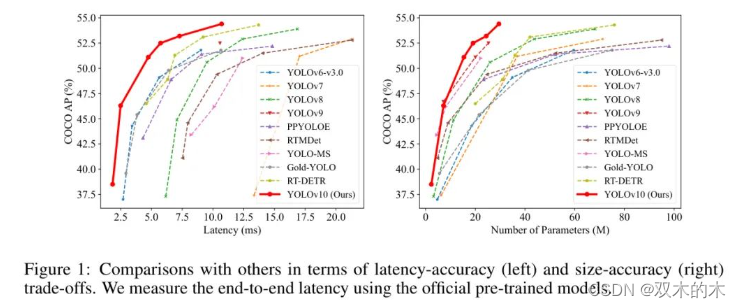
如图1所示,在相似性能下,YOLOv10-S / X分别比RT-DETR-R18 / R101快1.8倍 / 1.3倍。与YOLOv9-C相比,YOLOv10-B在相同性能下延迟降低了46%。此外,YOLOv10显示出高效的参数利用率。YOLOv10-L / X比YOLOv8-L / X分别高出0.3 AP和0.5 AP,而参数数量则分别减少了1.8倍和2.3倍。YOLOv10-M与YOLOv9-M / YOLO-MS相比,实现了相似的AP,但参数数量分别减少了23% / 31%。作者希望作者的工作能够启发该领域的进一步研究和进步。
2. Methodology
2.1 Consistent Dual Assignments for NMS-free Training
在训练过程中,YOLO系列方法通常利用TAL为每个实例分配多个正样本。采用一对一多分配产生了丰富的监督信号,促进了优化并实现了卓越的性能。然而,这需要YOLO依赖于NMS后处理,这导致了部署时次优的推理效率。尽管之前的工作探索了一对一匹配以抑制冗余预测,但它们通常引入了额外的推理开销或导致次优性能。在本工作中,作者提出了一种无需NMS的YOLO训练策略,采用双重标签分配和一致的匹配度量,实现了高效率和有竞争力的性能。
双重标签分配
与一对一多分配不同,一对一匹配只为每个地面真相分配一个预测,避免了NMS后处理。然而,这导致了较弱的监督,导致次优的准确性和收敛速度。幸运的是,这种缺陷可以通过一对一多分配来弥补。为此,作者为YOLO引入了双重标签分配,以结合两种策略的优点。

具体来说,如图2.(a)所示,作者在YOLO中增加了一个一对一的 Head 。它与原始一对一多分支保持相同的结构和采用相同的优化目标,但利用一对一匹配来获得标签分配。在训练过程中,两个 Head 与模型联合优化,使得主干和 Neck 能够享受到一对一多分配提供的丰富监督。
在推理过程中,作者丢弃一对一多 Head ,并利用一对一 Head 进行预测。这使得YOLO能够端到端部署,而不会产生任何额外的推理成本。此外,在一对一匹配中,作者采用顶部选择,其性能与匈牙利匹配[4]相同,但额外的训练时间更少。
一致的匹配度量


2.2. Holistic Efficiency-Accuracy Driven Model Design
除了后处理之外,YOLOs的模型架构也对效率-准确度权衡提出了重大挑战[45; 7; 27]。尽管以前的工作探索了各种设计策略,但对YOLOs中各种组件的全面检查仍然缺乏。因此,模型架构展现出不可忽视的计算冗余和受限的能力,这阻碍了其实现高效率和性能的潜力。在这里,作者从效率和准确度两个方面全面进行YOLOs的模型设计。
以效率为导向的模型设计
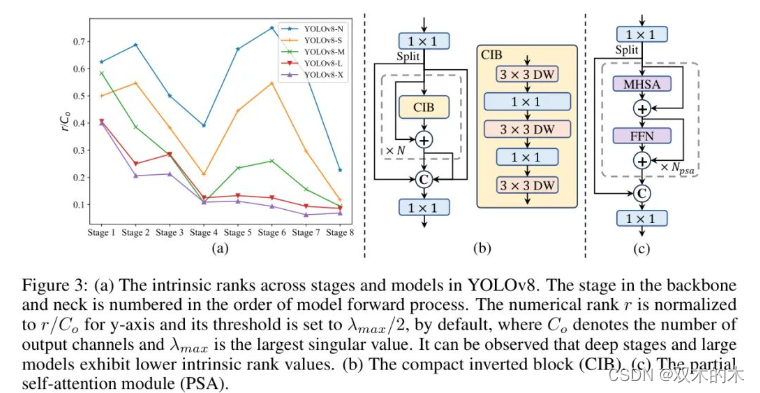
YOLO中的组件包括Stem、下采样层、带有基本构建块的阶段和 Head 。Stem产生的计算成本很少,因此作者仅对其他三个部分进行以效率为导向的模型设计。

-
为了解决这个问题,作者提出了一种秩引导的块设计方案,旨在通过紧凑型架构设计减少被显示为冗余的阶段的复杂性。作者首先提出了一个紧凑型倒置块(CIB)结构,它采用廉价的深度卷积进行空间混合和高效的一维卷积进行通道混合,如图3(b)所示。它可以作为高效的基本构建块,例如嵌入ELAN结构[58; 20](图3(b))。然后,作者提倡一种秩引导的块分配策略,在保持竞争力的同时实现最佳效率。
具体来说,对于给定的模型,作者根据它们的内在秩将所有阶段升序排序。作者进一步检查用CIB替换领先阶段的基本块时性能的变化。如果没有与给定模型相比的性能退化,作者就继续替换下一个阶段,否则停止该过程。因此,作者可以在不同阶段和模型规模上实现自适应紧凑块设计,提高效率而不损害性能。由于篇幅限制,作者在附录中提供算法的细节。
准确度驱动的模型设计。作者进一步探索了大核卷积和自注意力用于准确度驱动的模型设计,旨在以最小的成本提升性能。

3. Experiments
3.1. Implementation Details
作者选择YOLOv8作为 Baseline 模型,因为它在延迟和准确度之间取得了令人称赞的平衡,并且有多种模型尺寸可供选择。作者采用了持续的二元分配以实现无需NMS的训练,并基于此进行了整体效率与准确度驱动的模型设计,从而推出了YOLOv10模型。YOLOv10与YOLOv8具有相同的变体,即N/S/M/L/X。
此外,作者通过简单增加YOLOv10-M的宽度扩展因子,导出了一个新变体YOLOv10-B。作者在与[20; 59; 56]相同的从头开始训练的设置下,在COCO数据集上验证了所提出的检测器。此外,所有模型的延迟都在T4 GPU上使用TensorRT FP16进行测试,遵循[71]的方法。
3.2 Comparison with state-of-the-arts

如表1所示,YOLOv10在各种模型规模上均取得了最先进的性能和端到端延迟。作者首先将YOLOv10与作者的 Baseline 模型进行比较,即YOLOv8。在N / S / M / L / X五个变体上,YOLOv10实现了1.2% / 1.4% / 0.5% / 0.3% / 0.5%的AP提升,参数减少了28% / 36% / 41% / 44% / 57%,计算量减少了23% / 24% / 25% / 27% / 38%,延迟降低了70% / 65% / 50% / 41% / 37%。
与其他YOLO模型相比,YOLOv10在准确性和计算成本之间也显示出优越的权衡。特别是对于轻量和小型模型,YOLOv10-N / S比YOLOv6-3.0-N / S分别高出1.5 AP和2.0AP,参数减少了51% / 61%,计算量分别减少了41% / 52%。对于中型模型,与YOLOv9-C / YOLO-MS相比,YOLOv10-B / M在相同或更好的性能下,延迟分别降低了46% / 62%。
对于大型模型,与Gold-YOLO-L相比,YOLOv10-L具有68%的更少参数和32%的更低延迟,同时AP显著提高了1.4%。此外,与RT-DETR相比,YOLOv10在性能和延迟上均取得了显著提升。值得注意的是,在类似性能下,YOLOv10-S / X的推理速度分别是RT-DETR-R18 / R101的1.8x和1.3x。这些结果充分证明了YOLOv10作为实时端到端检测器的优越性。
作者还使用原始的一对多训练方法将YOLOv10与其他YOLO模型进行了比较。在这种情况下,作者考虑了模型的向前过程性能和延迟(Latency),遵循[56, 20, 54]。如表1所示,YOLOv10在不同模型规模上也展示了最先进的性能和效率,这表明了作者的架构设计是有效的。
3.3 Model Analyses
消融研究

作者在表2中基于YOLOv10-S和YOLOv10-M展示了消融实验结果。可以观察到,作者的无需NMS的训练与一致的双重分配显著降低了YOLOv10-S的端到端延迟4.63ms,同时保持了44.3% AP的竞争力表现。
此外,作者以效率为导向的模型设计导致YOLOv10-M减少了1180万参数和20.8 GFIOPs,延迟减少了0.65ms,充分展示了其有效性。进一步地,作者以准确率为导向的模型设计为YOLOv10-S和YOLOv10-M分别实现了1.8 AP和0.7 AP的显著改进,仅增加了0.18ms和0.17ms的延迟开销,充分证明了其优越性。
对无需NMS训练的分析

针对效率驱动的模型设计分析
作者基于YOLOv10-S/M进行了实验,逐步融入效率驱动的的设计元素。作者的 Baseline 模型是未采用效率-精度驱动的模型设计YOLOv10-S/M,即表2中的#2/#6。如表5所示,包括轻量级分类头、空间-通道解耦下采样和排序引导的块设计在内的每个设计组件都有助于减少参数数量、FLOPs和延迟。重要的是,这些改进是在保持竞争力性能的同时实现的。



-
如表9所示,当作者逐步在每个阶段用高效的CIB替换瓶颈块时,从第7阶段开始观察到性能退化。在内在排序较低且冗余更多的第8和第4阶段,作者可以采用高效的块设计而不牺牲性能。这些结果表明,排序引导的块设计可以作为提高模型效率的有效策略。
针对准确度驱动的模型设计分析
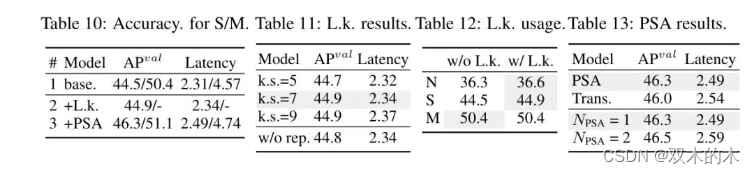
作者基于YOLOv10-S/M逐步集成准确度驱动设计元素的结果。作者的 Baseline 模型是融入了效率驱动设计的YOLOv10-S/M模型,即表2中的#3/#7。如表10所示,采用大核卷积和PSA模块使得YOLOv10-S的模型性能显著提升,分别提高了0.4% AP和1.4% AP,而延迟的增加最小,分别为0.03ms和0.15ms。需要注意的是,对于YOLOv10-M(见表12),作者没有采用大核卷积。

4 Implementation Details


此外,作者将YOLOv10-M的宽度扩展因子增加到1.0以获得YOLOv10-B。对于PSA,作者在SPPF模块之后采用,并为FFN采用扩展因子为2。对于CIB,作者还为倒置瓶颈块结构采用2的扩展比率。[59, 56]在COCO数据集上报告了不同目标尺度和IoU阈值的标准平均精度(AP)。
此外,作者遵循[71]建立端到端的速度基准。由于NMS的执行时间受输入影响,因此作者在COCO验证集上测量延迟,与[71]一样。作者在验证期间采用了与检测器相同的NMS超参数。在后期处理中附加了TensorRT efficientNMSPlugin,并且省略了I/O开销。作者报告了所有图像的平均延迟。
5. 连贯匹配度量的详细推导

进一步地,证明可以通过一致的匹配度量来实现最小的监督差距。

6. Details of Rank-Guided Block Design

7 More Results on COCO

8 More Analyses for Holistic Efficiency-Accuracy Driven Model Design
作者注意到,由于模型规模较小,降低YOLOv10-S(表2中第2个)的延迟尤为具有挑战性。然而,如表2所示,作者以效率为导向的模型设计仍然在不过度牺牲性能的情况下实现了5.3%的延迟降低。这为进一步的以准确度为导向的模型设计提供了有力支持。采用作者整体效率-准确度驱动的模型设计,YOLOv10-S在仅有0.05ms延迟开销的情况下,实现了更好的延迟-准确度权衡,显示出2.0%的AP提升。
此外,对于规模更大、冗余性更多的YOLOv10-M(表2中第6个),作者的效率驱动模型设计如表2所示,实现了相当可观的12.5%的延迟降低。当与准确度驱动的模型设计结合时,作者观察到YOLOv10-M的AP显著提升了0.8%,同时延迟也减少了0.48ms。这些结果充分证明了作者设计策略在不同模型规模上的有效性。
9 Visualization Results
图4展示了作者YOLOv10在复杂且具有挑战性的场景下的可视化结果。可以看出,YOLOv10在各种困难条件下都能实现精确检测,例如低光照、旋转等。它还展示了在检测多种且密集排列的物体(如瓶子、杯子和人)方面的强大能力。这些结果表明其性能卓越。

10 Contribution, Limitation, and Broader Impact
贡献。 总的来说,作者的贡献主要体现在以下三个方面:
-
作者提出了一种新颖的一致性双重分配策略,用于无需NMS的YOLO。设计了一种双重标签分配方法,通过一对多分支在训练过程中提供丰富的监督信息,以及通过一对一分支在推理过程中实现高效率。此外,为了确保两个分支之间的和谐监督,作者创新性地提出了连贯匹配度量,这可以很好地减少理论上的监督差距,并带来性能的提升。
-
作者提出了一种整体效率-精度驱动的模型设计策略,用于YOLO的模型架构。作者展示了新型轻量级分类头、空间-通道解耦降采样和排名引导的块设计,这些设计大大减少了计算冗余并实现了高效率。作者进一步引入了大核卷积和创新的部分自注意力模块,这些模块在低成本的条件下有效地提升了性能。
-
基于上述方法,作者推出了YOLOv10,这是一个新的实时端到端目标检测器。广泛的实验表明,YOLOv10与其他先进检测器相比,在性能和效率权衡方面达到了最先进水平。局限性。 由于计算资源的限制,作者没有在大规模数据集上进行YOLOv10的预训练,例如Objects365 [47]。此外,尽管作者在无需NMS的训练下使用一对一 Head 可以获得具有竞争力的端到端性能,但与使用NMS的一对多训练相比,仍然存在性能差距,特别是在小型模型中更为明显。例如,在YOLOv10-N和YOLOv10-S中,使用NMS的一对多训练的性能比无需NMS的训练分别高出1.0% AP和0.5% AP。作者将在未来的工作中探索进一步缩小差距并实现更高性能的方法。
11 Conclusion
在本文中,作者针对YOLO系列检测 Pipeline 中的后处理和模型架构进行了研究。对于后处理,作者提出了持续的双重分配以实现无需NMS的训练,从而实现高效的端到端检测。对于模型架构,作者引入了整体效率-精度驱动的模型设计策略,改进了性能与效率之间的权衡。这些改进带来了YOLOv10,这是一个新的实时端到端目标检测器。大量实验表明,与其它先进检测器相比,YOLOv10在性能和延迟方面均达到了最先进水平,充分展示了其优越性。
参考
[1].YOLOv10: Real-Time End-to-End Object Detection
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。














)




