文章目录
- 前言
- 一、模型结构
前言
Transformer 模型是由谷歌在 2017 年提出并首先应用于机器翻译的神经网络模型结构。机器翻译的目标是从源语言(Source Language)转换到目标语言(Target Language)。Transformer 结构完全通过注意力机制完成对源语言序列和目标语言序列全局依赖的建模。
一、模型结构
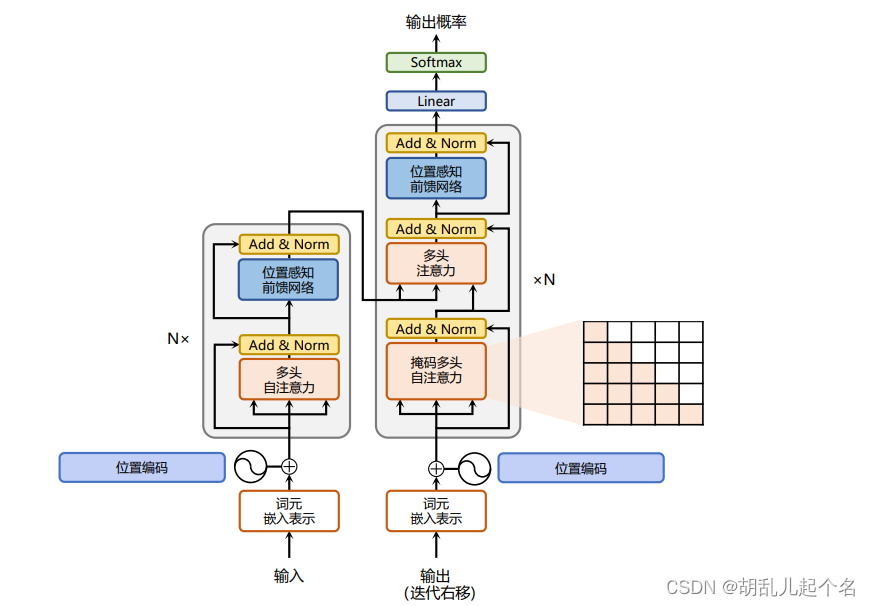
- 注意力层:使用多头注意力(Multi-HeadAttention)机制整合上下文语义,它使得序列中任意两个单词之间的依赖关系可以直接被建模而不基于传统的循环结构,从而更好地解决文本的长程依赖。
- 位置感知前馈层(Position-wise FFN):通过全连接层对输入文本序列中的每个单词表示进行更复杂的变换。
- 残差连接:对应图中的 Add部分。它是一条分别作用在上述两个子层当中的直连通路,被用于连接它们的输入与输出。从而使得信息流动更加高效,有利于模型的优化。
- 层归一化:对应图中的 Norm 部分。作用于上述两个子层的输出表示序列中,对表示序列进行层归一化操作,同样起到稳定优化的作用。






挑战2024)






)


![[链表专题]力扣141, 142](http://pic.xiahunao.cn/[链表专题]力扣141, 142)


