DeepVisionary 每日深度学习前沿科技推送&顶会论文分享,与你一起了解前沿深度学习信息!
引言:探索视觉变换器在对象重识别中的全局与局部特征
在对象重识别(Re-ID)的研究领域中,如何有效地从不同时间和地点捕获的图像中识别和检索特定对象一直是一个挑战。最近,随着视觉变换器(Vision Transformers,简称ViT)的发展,对象重识别取得了显著的进展。然而,对于对象重识别,全局与局部特征的相互关系和作用尚未被充分探索。
在本研究中,我们首先探讨了ViT中全局和局部特征的影响,然后进一步提出了一种新颖的全局-局部变换器(Global-Local Transformer,简称GLTrans)以实现高性能的对象重识别。我们发现,ViT的最后几层已经具有很强的表征能力,全局和局部信息可以相互增强。基于这一发现,我们提出了全局聚合编码器(Global Aggregation Encoder,简称GAE),有效地利用最后几层变换器的类别标记来学习全面的全局特征。同时,我们提出了局部多层融合(Local Multi-layer Fusion,简称LMF),它利用GAE的全局线索和多层补丁标记来探索具有辨别力的局部表征。
通过在四个大规模对象重识别基准上的广泛实验,我们的方法展示了优于大多数最先进方法的性能。
- 论文标题:Other Tokens Matter: Exploring Global and Local Features of Vision Transformers for Object Re-Identification
- 机构:Dalian University of Technology
- 论文链接:https://arxiv.org/pdf/2404.14985.pdf
对象重识别的挑战与现状
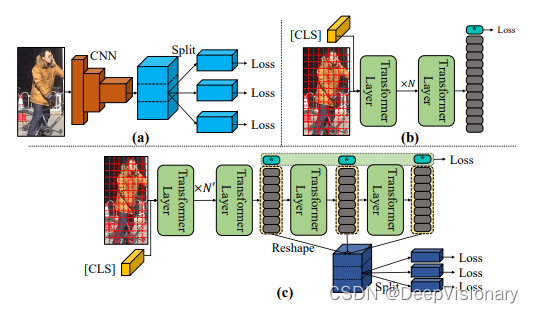
1. CNNs在对象重识别中的应用与局限
在过去的二十年中,基于卷积神经网络(CNNs)的方法主导了对象重识别(Re-ID)领域。这些方法通过分割特征图来获取细粒度线索,例如将特征图水平分割以学习区分性的局部特征。尽管这些方法取得了卓越的表现,但它们受限于卷积操作的全局表示能力较弱,这可能导致过拟合并忽略全局重要信息。
2. Transformers引入对象重识别的新视角
Transformers由于其全局建模能力,在自然语言处理(NLP)领域已成为主流模型。近年来,研究者们开始将Transformers引入到视觉任务中,例如Vision Transformer(ViT)。这些方法通常使用类标记来代表整个图像,但常常忽略了patch标记中丰富的细粒度线索。为了解决这一问题,一些研究通过将patch标记划分为多个独立区域来挖掘局部区分性线索,但这种方法可能会遗漏结构信息。
GLTrans方法介绍:结合全局与局部的视觉变换器
1. Vision Transformer (ViT)的基本工作原理
Vision Transformer(ViT)通过将图像分解为重叠的图像块,并将每个块线性投影到一个高维空间,从而获得一系列的向量。这些向量通过多头自注意力机制进行信息聚合,使模型能够关注长距离依赖,从而捕捉全局信息。
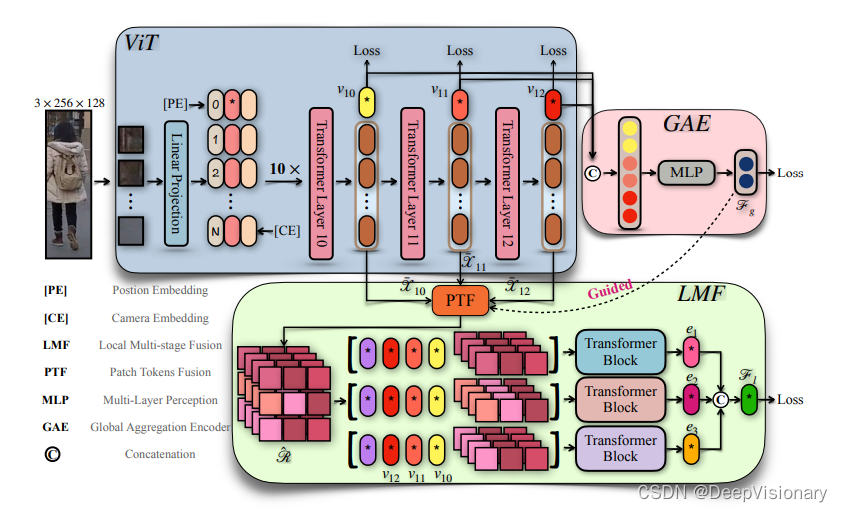
2. 全局聚合编码器(GAE)的设计与功能
全局聚合编码器(GAE)利用从ViT的最后几层获得的类标记,通过一个全连接层和GeLU激活函数生成一个综合的全局特征表示。这种方法不仅考虑了最后一层的类标记,还结合了前几层的类标记,以获得更全面的全局特征。
3. 局部多层融合(LMF)的策略与实现
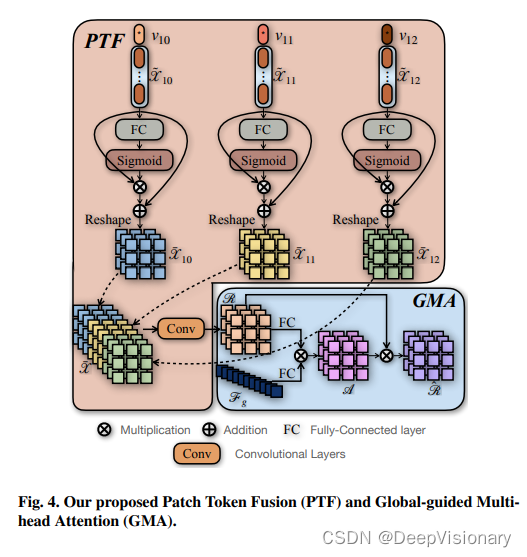
局部多层融合(LMF)模块包括Patch Token Fusion(PTF)、Global-guided Multi-head Attention(GMA)和Part-based Transformer Layers(PTL)。PTF通过聚合多层的patch标记并增强它们之间的空间关系来获取紧凑的局部表示。GMA进一步通过全局特征引导增强patch标记的区分性表示。PTL则利用分割后的patch标记和全局类标记,通过多头自注意力层和前馈网络,提取区分性的局部特征。
实验设置与数据集描述
在本研究中,我们采用了四个大规模的对象重识别(Re-ID)基准数据集,包括Market1501、DukeMTMC-ReID、MSMT17和VeRi-776。这些数据集广泛用于评估Re-ID算法的性能。Market1501和DukeMTMC-ReID主要用于行人重识别,而MSMT17和VeRi-776则包括更多场景和更复杂的环境条件。
我们的实验框架基于Vision Transformer (ViT)模型,结合了全局聚合编码器(Global Aggregation Encoder, GAE)和局部多层融合(Local Multi-layer Fusion, LMF)模块。我们首先从ViT获取多层的类标记和补丁标记,然后通过GAE和LMF生成更具辨别力的全局和局部特征。此外,我们还引入了多头自注意力机制来增强补丁标记的判别表示。
与现有技术的比较
1. 在Market1501和DukeMTMC-ReID数据集上的表现
在Market1501数据集上,尽管我们的模型在Rank1得分方面略低于一些比较方法,例如ISP和HAT,但在平均精度(mAP)方面表现非常竞争。在DukeMTMC-ReID数据集上,我们的GLTrans方法在mAP得分上超过了TransReID、AAformer和PFD,显示了通过探索补充的局部和全局信息,我们的方法能够获得更鲁棒的表示。
2. 在MSMT17和VeRi-776数据集上的优势分析
在MSMT17数据集上,我们的模型在mAP和Rank1上均实现了最佳性能。这表明,通过全局线索引导的多层特征融合可以获得互补和细粒度的特征表示。此外,在VeRi-776数据集上,我们的GLTrans模型在mAP和Rank1上也表现最佳。这一结果强调了在车辆Re-ID中识别局部信息的重要性,我们的方法通过考虑局部和全局线索,实现了卓越的性能。
总体而言,这些实验结果验证了我们提出的GLTrans框架在处理多种复杂场景下的对象Re-ID任务时的有效性和优越性。
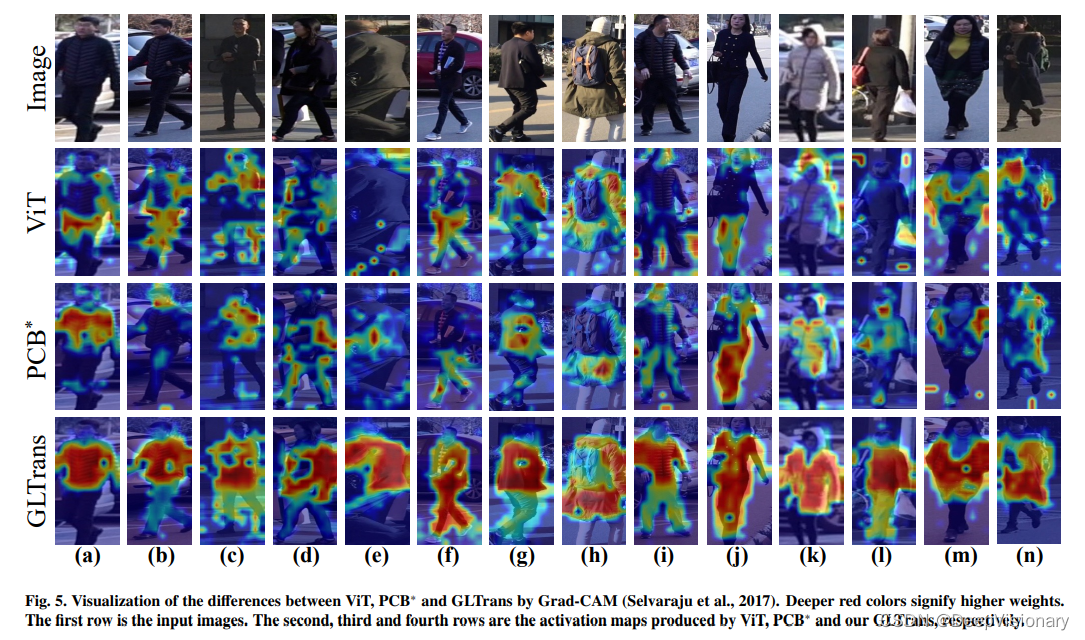
深入分析:局部与全局特征融合的影响
1. 不同组件的性能比较
在GLTrans方法中,局部多层融合(LMF)和全局聚合编码器(GAE)是两个关键组件。LMF通过融合多层的patch tokens来增强局部特征的表达能力,而GAE则聚合多层的class tokens以提取更全面的全局特征。实验结果表明,这两种策略的结合显著提高了对象重识别的性能,尤其是在处理复杂场景和多样化的视觉信息时。
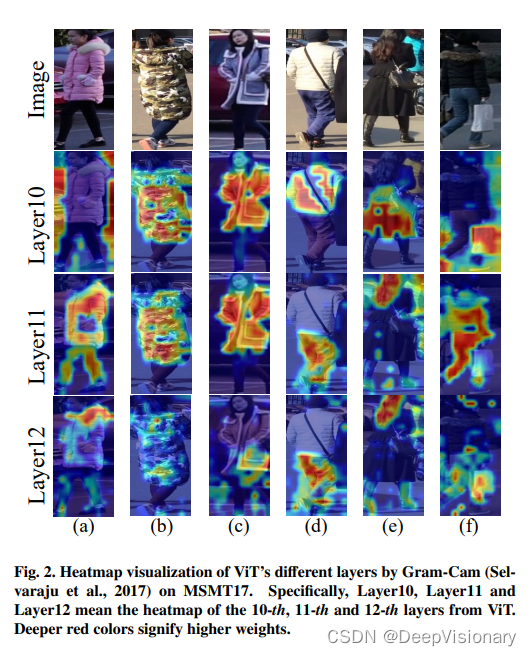
2. 不同层聚合的效果分析
通过对比不同层级的特征聚合,发现最后几层的ViT特征包含了丰富的语义信息,这些信息对于提高模型的判别能力至关重要。然而,单一层次的特征往往无法全面表达对象的复杂性,因此GLTrans采用了多层特征聚合策略,以获得更加全面和鲁棒的特征表示。
3. 不同聚合策略的影响
在全局聚合编码器(GAE)中,采用了多层class tokens的聚合,而在局部多层融合(LMF)中,则是通过patch token fusion、全局引导的多头注意力(GMA)和部分感知的Transformer层(PTL)来实现局部特征的增强。这种局部与全局的聚合策略有效地提升了模型对于细节的捕捉能力,使得模型在多个重识别基准测试中取得了优异的性能。
总结与未来展望
1. GLTrans方法的主要贡献与创新点
GLTrans方法的主要创新在于它有效地融合了局部和全局特征,通过全局聚合编码器(GAE)和局部多层融合(LMF)两大组件,优化了特征的表达能力。此外,该方法还引入了多头注意力机制来进一步增强模型对复杂场景的适应性和鲁棒性。
2. 对象重识别领域的未来研究方向
未来的研究可以在以下几个方向进行深入:首先,探索更高效的特征融合技术,以进一步提升模型的性能和效率;其次,研究跨模态和跨领域的对象重识别问题,以应对更加多样化的应用场景;最后,考虑到隐私和安全的问题,研究如何在保护个人隐私的前提下进行有效的对象重识别。
关注DeepVisionary 了解更多深度学习前沿科技信息&顶会论文分享!

 的地位再一次被挑战 !!!)

)





)




函数的详解)


NoSQL与分布式对象调用)
)
